A Lightweight Self-Supervised Learning Framework for Multivariate Time Series using Hierarchical-JEPA on ECG Data
Pith reviewed 2026-07-02 15:24 UTC · model grok-4.3
The pith
ER-JEPA uses a two-stage hierarchical structure of concatenated JEPAs to reach state-of-the-art ECG performance after pretraining on 180000 recordings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the structural concatenation of two JEPAs into a Hierarchical JEPA encodes multiple levels of abstract representations for enhanced prediction performance on complex ECG tasks, as demonstrated by state-of-the-art downstream performance on the ST-MEM benchmark after pretraining on approximately 180000 10-second recordings.
What carries the argument
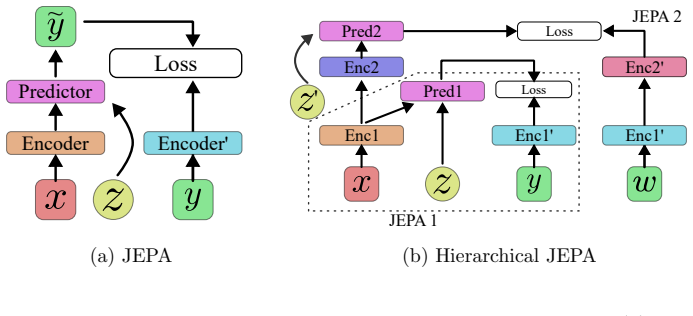
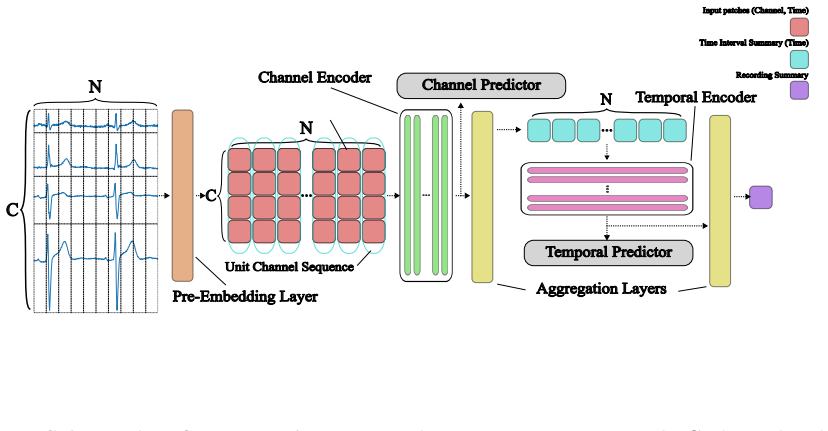
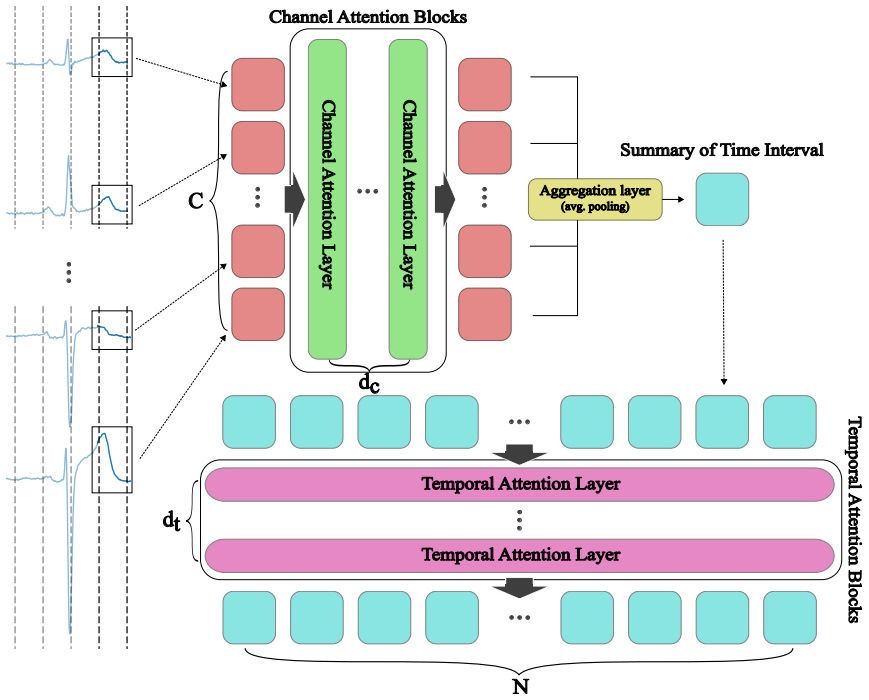
The Hierarchical JEPA (H-JEPA) formed by concatenating two Joint-Embedding Predictive Architectures in a two-stage structure that first builds interval representations and then processes them as a univariate time series.
If this is right
- The model achieves state-of-the-art downstream performance on the ST-MEM benchmark.
- Pretraining on large unlabeled ECG datasets enables strong results despite limited labeled target data.
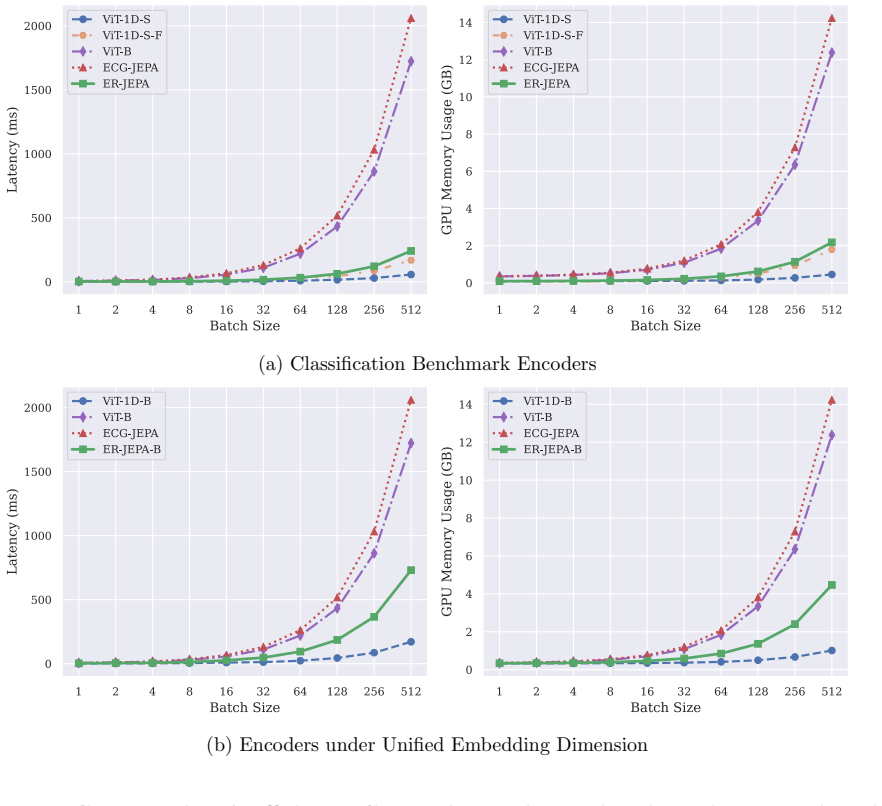
- The approach requires only rapid computation and minimal resource usage.
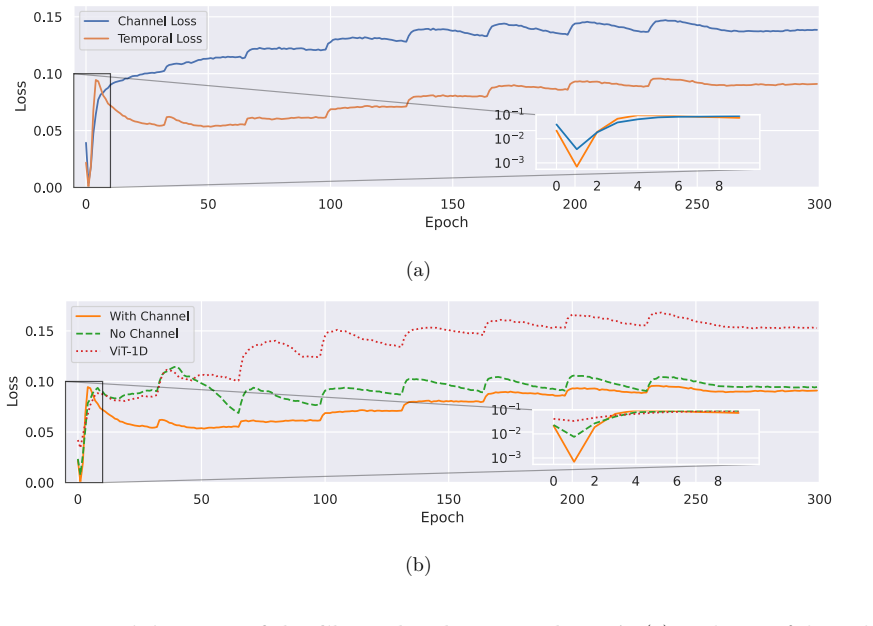
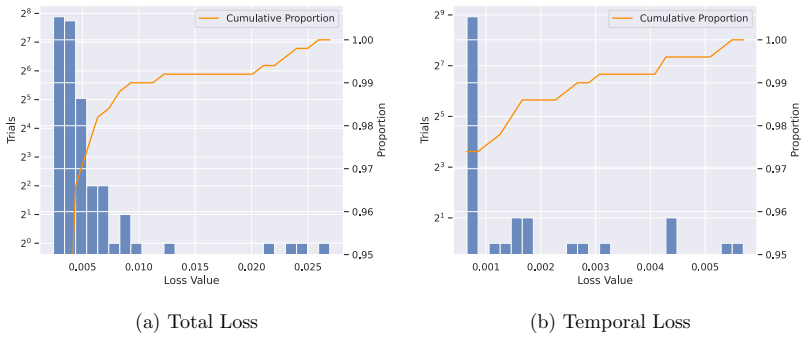
- Sensitivity analysis of hierarchical representations during pretraining reveals design choices for multi-level encoding.
Where Pith is reading between the lines
- The two-stage interval-to-series design could transfer to other multivariate signals such as EEG or industrial sensor streams.
- Low resource demands suggest feasibility for continuous monitoring on portable medical devices.
- The observed sensitivity of hierarchical levels may inform scaling decisions in related self-supervised time-series models.
Load-bearing premise
The two-fold hierarchical structure that concatenates two JEPAs will encode multiple levels of abstract representations and thereby produce enhanced prediction performance on complex ECG tasks.
What would settle it
A controlled experiment in which a single non-hierarchical JEPA matches or exceeds the ST-MEM benchmark scores after identical pretraining on the same 180000 recordings would falsify the necessity of the two-fold structure.
Figures
read the original abstract
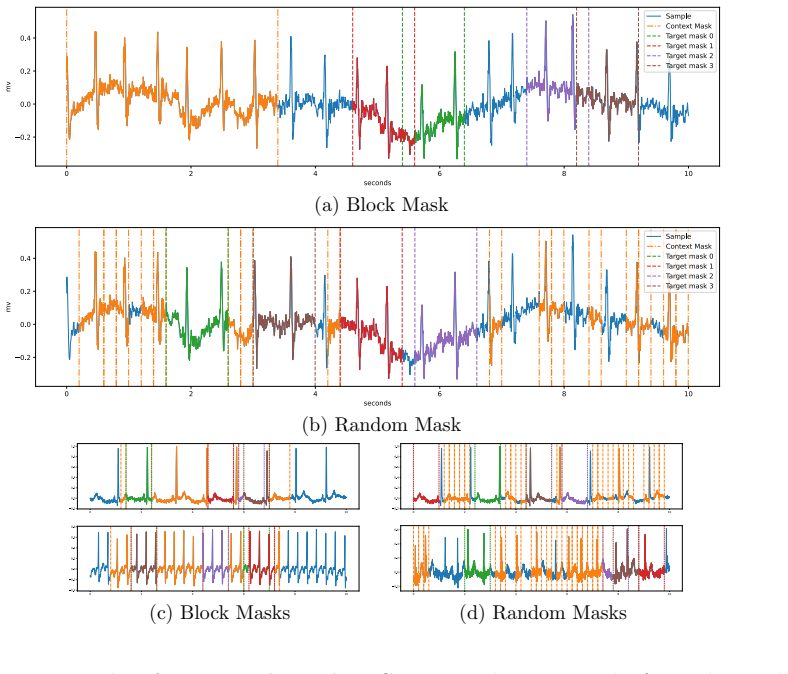
Data analysis in the medical domain often encounters scenarios involving a limited target dataset and a large, unannotated dataset with a general distribution. Under such circumstances, self-supervised learning (SSL) methods are highly effective for utilizing large datasets, making them a popular choice for electrocardiogram (ECG) analysis. This work presents the Event Reconstruction Joint-Embedding Predictive Architecture (ER-JEPA), a lightweight SSL framework for multivariate time series, whose name and two-fold hierarchical structure are inspired by the diagnostic approach of cardiologists. At its core, ER-JEPA features: (1) a two-stage structure that constructs representations for each time interval and subsequently processes these representations as a univariate time series, (2) the hierarchical integration of two Joint-Embedding Predictive Architectures (JEPAs), and (3) a Vision Transformer (ViT) backbone. The structural concatenation of two JEPAs categorizes the model as a Hierarchical JEPA (H-JEPA), designed to encode multiple levels of abstract representations for enhanced prediction on complex tasks. This study reports a successful application of H-JEPA to 12-lead ECG data as a multivariate time series alongside an analysis of the sensitivity of hierarchical representation during the pretraining stage. Pretrained on approximately 180,000 10-second recordings, the model achieves state-of-the-art downstream performance on the ST-MEM benchmark, with rapid computation and minimal resource usage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ER-JEPA (Event Reconstruction Joint-Embedding Predictive Architecture), a lightweight self-supervised learning framework for multivariate time series on 12-lead ECG data. It employs a two-stage hierarchical structure that first builds representations for time-interval patches and then processes them as a univariate series via concatenated JEPAs with a ViT backbone. Pretrained on ~180k 10-second recordings, the model reports state-of-the-art results on the ST-MEM benchmark together with a sensitivity analysis of the hierarchy and claims of low computational cost.
Significance. If the empirical results hold, the work supplies a coherent, resource-efficient SSL method for ECG analysis that exploits large unlabeled corpora. The explicit sensitivity analysis of the hierarchical component and the reported resource metrics constitute concrete strengths for a methods contribution in this domain.
minor comments (2)
- [Abstract] Abstract: the relationship between the proper name ER-JEPA and the category label H-JEPA is introduced but not fully disambiguated; a single sentence clarifying that ER-JEPA is an instance of H-JEPA would remove ambiguity.
- [Abstract] The abstract states that the hierarchy encodes 'multiple levels of abstract representations'; the sensitivity analysis mentioned in the abstract should be cross-referenced to the specific figure or table that quantifies this contribution.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and positive recommendation for minor revision. We are pleased that the significance of the empirical results, the sensitivity analysis of the hierarchical component, and the reported resource efficiency were recognized as strengths of the work.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces ER-JEPA/H-JEPA as a two-stage hierarchical concatenation of JEPAs on a ViT backbone, motivated by cardiologist diagnostic analogy and applied to 12-lead ECG as multivariate time series. Pretraining occurs on ~180k recordings, with downstream SOTA reported on ST-MEM plus sensitivity analysis of the hierarchy. No equations or claims reduce the benchmark performance to fitted parameters by construction; the hierarchy is presented as an architectural extension whose contribution is tested experimentally rather than assumed tautologically. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work appear as load-bearing steps. The reported results therefore stand as independent empirical outcomes of the described pretraining procedure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision Transformer backbone is appropriate for ECG time-series patches
invented entities (2)
-
ER-JEPA
no independent evidence
-
H-JEPA
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A simple frame- work for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple frame- work for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
2020
-
[2]
Bootstrap your own latent: A new approach to self-supervised learning,
Jean-Bastien Grill, Florian Strub, Florent Altch´ e, Corentin Tallec, Pierre H Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Moham- mad Gheshlaghi Azar, et al. Bootstrap your own latent: A new approach to self-supervised learning.arXiv preprint arXiv:2006.07733, 2020
-
[3]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
2020
-
[4]
Masked Autoencoders Are Scalable Vision Learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ ar, and Ross Girshick. Masked autoencoders are scalable vision learners.arXiv:2111.06377, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
BEiT: BERT Pre-Training of Image Transformers
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. Beit: Bert pre-training of image transformers.arXiv preprint arXiv:2106.08254, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Simmim: A simple framework for masked image modeling
Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han Hu. Simmim: A simple framework for masked image modeling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9653–9663, 2022. 21
2022
-
[7]
Lippincott Williams & Wilkins, 2021
Malcolm S Thaler.The only EKG book you’ll ever need. Lippincott Williams & Wilkins, 2021
2021
-
[8]
Yeongyeon Na, Minje Park, Yunwon Tae, and Sunghoon Joo. Guiding masked representa- tion learning to capture spatio-temporal relationship of electrocardiogram.arXiv preprint arXiv:2402.09450, 2024
-
[9]
Foundation model of ecg diagnosis: Diagnostics and explanations of any form and rhythm on ecg.Cell Reports Medicine, 5(12), 2024
Yuanyuan Tian, Zhiyuan Li, Yanrui Jin, Mengxiao Wang, Xiaoyang Wei, Liqun Zhao, Yun- qing Liu, Jinlei Liu, and Chengliang Liu. Foundation model of ecg diagnosis: Diagnostics and explanations of any form and rhythm on ecg.Cell Reports Medicine, 5(12), 2024
2024
-
[10]
Ecg-fm: An open electrocardiogram foundation model.Jamia Open, 8(5):ooaf122, 2025
Kaden McKeen, Sameer Masood, Augustin Toma, Barry Rubin, and Bo Wang. Ecg-fm: An open electrocardiogram foundation model.Jamia Open, 8(5):ooaf122, 2025
2025
-
[11]
Self-supervised pre-training with joint-embedding predictive architecture boosts ecg classification performance.Computers in Biology and Medicine, 196:110809, 2025
Kuba Weimann and Tim OF Conrad. Self-supervised pre-training with joint-embedding predictive architecture boosts ecg classification performance.Computers in Biology and Medicine, 196:110809, 2025
2025
-
[12]
Sehun Kim. Learning general representation of 12-lead electrocardiogram with a joint- embedding predictive architecture.arXiv preprint arXiv:2410.08559, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[14]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[15]
A path towards autonomous machine intelligence version 0.9
Yann LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022- 06-27.Open Review, 62(1):1–62, 2022
2022
-
[16]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619–15629, 2023
2023
-
[17]
David Ha and J¨ urgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Ptb-xl, a large publicly available electrocardiog- raphy dataset.Scientific data, 7(1):154, 2020
Patrick Wagner, Nils Strodthoff, Ralf-Dieter Bousseljot, Dieter Kreiseler, Fatima I Lunze, Wojciech Samek, and Tobias Schaeffter. Ptb-xl, a large publicly available electrocardiog- raphy dataset.Scientific data, 7(1):154, 2020
2020
-
[19]
Feifei Liu, Chengyu Liu, Lina Zhao, Xiangyu Zhang, Xiaoling Wu, Xiaoyan Xu, Yulin Liu, Caiyun Ma, Shoushui Wei, Zhiqiang He, et al. An open access database for evaluating the algorithms of electrocardiogram rhythm and morphology abnormality detection.Journal of Medical Imaging and Health Informatics, 8(7):1368–1373, 2018
2018
-
[20]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[21]
A tutorial on energy-based learning.Predicting structured data, 1(0), 2006
Yann LeCun, Sumit Chopra, Raia Hadsell, M Ranzato, Fujie Huang, et al. A tutorial on energy-based learning.Predicting structured data, 1(0), 2006. 22
2006
-
[22]
A large scale 12-lead electrocardiogram database for arrhythmia study (version 1.0
Jianwei Zheng, Hangyuan Guo, and Huimin Chu. A large scale 12-lead electrocardiogram database for arrhythmia study (version 1.0. 0).PhysioNet 2022Available online httpphys- ionet orgcontentecg arrhythmia10 0accessed on, 23:7, 2022
2022
-
[23]
Code-15%: A large scale annotated dataset of 12-lead ecgs.Zenodo, Jun, 9:10–5281, 2021
Antˆ onio H Ribeiro, GM Paixao, Emilly M Lima, M Horta Ribeiro, Marcelo M Pinto Filho, Paulo R Gomes, Derick M Oliveira, Wagner Meira Jr, Th¨ omas B Schon, and Antonio Luiz P Ribeiro. Code-15%: A large scale annotated dataset of 12-lead ecgs.Zenodo, Jun, 9:10–5281, 2021
2021
-
[24]
Tele-electrocardiography and bigdata: the code (clinical outcomes in digital electrocardiography) study.Journal of electrocardiology, 57:S75–S78, 2019
Antonio Luiz P Ribeiro, Gabriela MM Paixao, Paulo R Gomes, Manoel Horta Ribeiro, An- tonio H Ribeiro, Jessica A Canazart, Derick M Oliveira, Milton P Ferreira, Emilly M Lima, Jermana Lopes de Moraes, et al. Tele-electrocardiography and bigdata: the code (clinical outcomes in digital electrocardiography) study.Journal of electrocardiology, 57:S75–S78, 2019
2019
-
[25]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[27]
arXiv preprint arXiv:2202.03555 (2022)
Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. Data2vec: A general framework for self-supervised learning in speech, vision and language. arXiv preprint arXiv:2202.03555, 2022
-
[28]
Exploring simple siamese representation learning.arXiv preprint arXiv:2011.10566, 2020
Xinlei Chen and Kaiming He. Exploring simple siamese representation learning.arXiv preprint arXiv:2011.10566, 2020
-
[29]
Improving neural networks by preventing co-adaptation of feature detectors
Geoffrey E Hinton, Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, and Ruslan R Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detec- tors.arXiv preprint arXiv:1207.0580, 2012. 23 A Hyperparameters In this appendix, we provide the detailed hyperparameters used for the pretraining, linear evaluation, and fine-tuning pha...
work page internal anchor Pith review Pith/arXiv arXiv 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.