Emergence of a Shared Canonical Object Frame from In-the-Wild Videos
Pith reviewed 2026-06-30 05:59 UTC · model grok-4.3
The pith
A shared canonical object frame emerges from self-supervised training on in-the-wild videos using only noisy SfM poses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
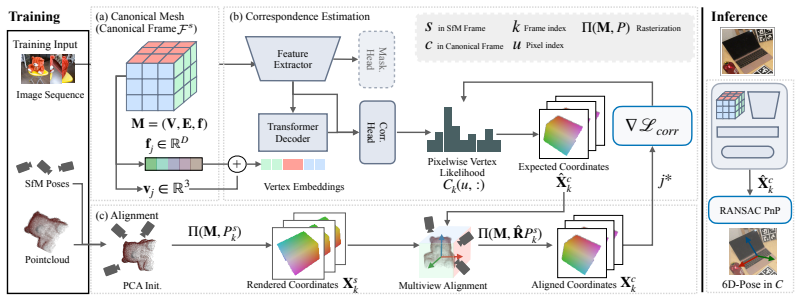
By routing every training sequence through a single coarse canonical mesh that carries no category detail and estimating per-sequence alignments from noisy SfM geometry, dense correspondences from image pixels to the mesh are learned in a self-supervised manner; the resulting common canonical frame emerges from multi-view consistency and the semantic priors of the feature extractor, allowing competitive accuracy on category-level pose estimation benchmarks after training on 160,000 in-the-wild object videos.
What carries the argument
The shared geometric bottleneck: a single coarse canonical mesh with no category-specific detail that all sequences must map onto through learned dense correspondences.
If this is right
- The approach achieves competitive accuracy on category-level pose estimation benchmarks without any canonical pose supervision.
- The same training procedure works across diverse object categories without requiring category conditioning.
- Only noisy camera poses from structure-from-motion are needed as geometric input.
- Training on 160,000 object-centric videos is sufficient for the frame to emerge.
Where Pith is reading between the lines
- The same bottleneck idea could be tested on other 3D reconstruction tasks where category labels are expensive.
- If the mesh is replaced by a learned implicit surface, the emergence effect might extend to non-rigid objects.
- The method suggests that large unlabeled video collections can substitute for pose annotations in downstream robotics applications.
Load-bearing premise
A single coarse canonical mesh together with noisy SfM geometry and existing semantic priors in the feature extractor are together enough to produce a usable shared frame across many different object categories.
What would settle it
Train the model and then measure whether the learned alignments produce consistent 3D pose predictions on a held-out set of videos whose ground-truth canonical poses have been independently annotated; large inconsistency or accuracy collapse would falsify the emergence claim.
Figures



read the original abstract
Comparing object orientations and positions across different instances requires their poses to be expressed in a shared canonical frame. Establishing such frames has traditionally required manual annotation, creating a scaling bottleneck that limits category and instance diversity. We show that a shared canonical frame can instead emerge from self-supervised training on object-centric videos captured in the wild, using only noisy camera poses from Structure-from-Motion. Our key idea is to route all training sequences through a shared geometric bottleneck: a coarse canonical mesh that carries no category-specific detail. By learning dense correspondences from image pixels to this mesh, and estimating per-sequence alignments from noisy SfM geometry, a common canonical frame emerges from multi-view consistency and the semantic priors of the feature extractor, without any canonical pose labels or category conditioning. Trained in a self-supervised manner on 160,000 in-the-wild object videos, our method achieves competitive accuracy on category-level pose estimation benchmarks compared to methods that rely on canonical pose supervision. The code and checkpoint is available on https://github.com/Fischer-Tom/Emergent-Canonical-Frame/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a shared canonical object frame can emerge from self-supervised training on object-centric videos captured in the wild, using only noisy camera poses from Structure-from-Motion, by routing all training sequences through a shared geometric bottleneck consisting of a coarse canonical mesh that carries no category-specific detail. By learning dense correspondences from image pixels to this mesh and estimating per-sequence alignments from noisy SfM geometry, a common canonical frame emerges from multi-view consistency and the semantic priors of the feature extractor, without any canonical pose labels or category conditioning. Trained on 160,000 in-the-wild object videos, the method achieves competitive accuracy on category-level pose estimation benchmarks.
Significance. If the result holds, this work would address the scaling bottleneck caused by manual annotation for canonical frames, allowing for greater category and instance diversity in object pose estimation. The public availability of the code and checkpoint is a notable strength that facilitates reproducibility and further research.
major comments (2)
- [geometric bottleneck (key idea)] The central claim depends on the sufficiency of a single coarse canonical mesh (no category detail) plus noisy SfM and feature priors to prevent per-category drift and produce a usable shared frame across diverse categories. However, no quantitative validation is provided for cases where SfM noise increases or object geometry differs sharply (e.g., rigid vs. articulated), leaving this premise as the least-secured point in the emergence argument.
- [Abstract] The abstract reports 'competitive accuracy' on benchmarks but supplies no quantitative numbers, error bars, ablation details, or dataset splits, which is load-bearing for verifying the central claim of emergence without supervision.
minor comments (1)
- [Abstract] Grammatical issue: 'The code and checkpoint is available' should read 'The code and checkpoint are available'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we respond point-by-point to the major comments, proposing targeted revisions that directly address the concerns while preserving the core contributions of the work.
read point-by-point responses
-
Referee: [geometric bottleneck (key idea)] The central claim depends on the sufficiency of a single coarse canonical mesh (no category detail) plus noisy SfM and feature priors to prevent per-category drift and produce a usable shared frame across diverse categories. However, no quantitative validation is provided for cases where SfM noise increases or object geometry differs sharply (e.g., rigid vs. articulated), leaving this premise as the least-secured point in the emergence argument.
Authors: We agree that explicit quantitative validation of the geometric bottleneck's robustness would strengthen the emergence argument. The existing results already operate on 160k in-the-wild videos that naturally contain both rigid and articulated objects together with typical SfM noise; the shared coarse mesh plus multi-view consistency is shown to produce a usable frame without category conditioning. Nevertheless, to directly secure this premise we will add controlled ablations in the revision: (i) synthetic SfM noise injection at multiple levels with resulting canonical-frame consistency and downstream pose accuracy, and (ii) separate quantitative breakdowns on rigid versus articulated object subsets. These additions will be reported with the same metrics used in the main experiments. revision: yes
-
Referee: [Abstract] The abstract reports 'competitive accuracy' on benchmarks but supplies no quantitative numbers, error bars, ablation details, or dataset splits, which is load-bearing for verifying the central claim of emergence without supervision.
Authors: We accept that the abstract would benefit from concrete numbers to make the central claim immediately verifiable. We will revise the abstract to include the key quantitative results (e.g., mean rotation/translation errors or accuracy@30° on the category-level benchmarks) and a brief statement of the training scale (160k videos). Full error bars, ablation tables, and exact dataset splits will continue to appear in the main text and supplement, as abstract length precludes exhaustive detail; the revised abstract will nonetheless supply the load-bearing numbers requested. revision: yes
Circularity Check
No significant circularity; empirical self-supervision against external benchmarks
full rationale
The paper presents a self-supervised method that routes sequences through a shared coarse mesh bottleneck and learns correspondences plus per-sequence alignments from noisy SfM. The canonical frame is claimed to emerge from multi-view consistency and feature priors during training on 160k videos, with no canonical labels used. Accuracy is measured on external category-level pose benchmarks. No equations, fitted parameters, or self-citations reduce the reported emergence or accuracy to the inputs by construction; the derivation remains self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Noisy SfM camera poses are sufficiently accurate to support per-sequence alignment to the shared mesh.
- domain assumption Semantic priors inside the feature extractor are adequate to resolve ambiguities across object categories.
invented entities (1)
-
coarse canonical mesh
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Monocular rgb 6d object pose estimation for augmented reality: a survey,
P. Aguirrezabal, I. Aguinaga, and A. Alvarez-Gila, “Monocular rgb 6d object pose estimation for augmented reality: a survey,”Virtual Reality, 2026
2026
-
[2]
Neural descriptor fields: Se (3)-equivariant object representations for manipulation,
A. Simeonov, Y . Du, A. Tagliasacchi, J. B. Tenenbaum, A. Rodriguez, P. Agrawal, and V . Sitz- mann, “Neural descriptor fields: Se (3)-equivariant object representations for manipulation,” in2022 International Conference on Robotics and Automation (ICRA), pp. 6394–6400, IEEE, 2022
2022
-
[3]
Omnimanip: Towards general robotic manipulation via object-centric interaction primitives as spatial constraints,
M. Pan, J. Zhang, T. Wu, Y . Zhao, W. Gao, and H. Dong, “Omnimanip: Towards general robotic manipulation via object-centric interaction primitives as spatial constraints,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 17359–17369, 2025
2025
-
[4]
Normalized object coordinate space for category-level 6d object pose and size estimation,
H. Wang, S. Sridhar, J. Huang, J. Valentin, S. Song, and L. J. Guibas, “Normalized object coordinate space for category-level 6d object pose and size estimation,” inCVPR, pp. 2642–2651, 2019
2019
-
[5]
A survey of content based 3d shape retrieval methods,
J. Tangelder and R. Veltkamp, “A survey of content based 3d shape retrieval methods,”Proceed- ings Shape Modeling Applications, 2004., pp. 145–156, 2004
2004
-
[6]
Orientation matters: Making 3d generative models orientation-aligned,
Y . Lu, Y . Tian, Z. Jiang, Y . Zhao, Y . Yang, H. Ouyang, H. Hu, H. Yu, Y . Shen, and Y . Liao, “Orientation matters: Making 3d generative models orientation-aligned,”arXiv preprint arXiv:2506.08640, 2025
-
[7]
Compass control: Multi object orientation control for text-to-image generation,
R. Parihar, V . Agrawal, S. VS, and V . B. Radhakrishnan, “Compass control: Multi object orientation control for text-to-image generation,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 2791–2801, 2025
2025
-
[8]
ShapeNet: An Information-Rich 3D Model Repository
A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su,et al., “Shapenet: An information-rich 3d model repository,”arXiv preprint arXiv:1512.03012, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[9]
Objaverse: A universe of annotated 3d objects,
M. Deitke, D. Schwenk, J. Salvador, L. Weihs, O. Michel, E. VanderBilt, L. Schmidt, K. Ehsani, A. Kembhavi, and A. Farhadi, “Objaverse: A universe of annotated 3d objects,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 13142–13153, 2023
2023
-
[10]
Omni6d: Large-vocabulary 3d object dataset for category-level 6d object pose estimation,
M. Zhang, T. Wu, T. Wang, T. Wang, Z. Liu, and D. Lin, “Omni6d: Large-vocabulary 3d object dataset for category-level 6d object pose estimation,” inEuropean Conference on Computer Vision, pp. 216–232, Springer, 2024
2024
-
[11]
Ov9d: Open-vocabulary category-level 9d object pose and size estimation,
J. Cai, Y . He, W. Yuan, S. Zhu, Z. Dong, L. Bo, and Q. Chen, “Ov9d: Open-vocabulary category-level 9d object pose and size estimation,”arXiv preprint arXiv:2403.12396, 2024
-
[12]
Beyond pascal: A benchmark for 3d object detection in the wild,
Y . Xiang, R. Mottaghi, and S. Savarese, “Beyond pascal: A benchmark for 3d object detection in the wild,” inIEEE winter conference on applications of computer vision, pp. 75–82, IEEE, 2014
2014
-
[13]
Imagenet3d: Towards general-purpose object-level 3d understanding,
W. Ma, G. Zhang, Q. Liu, G. Zeng, A. Kortylewski, Y . Liu, and A. Yuille, “Imagenet3d: Towards general-purpose object-level 3d understanding,”Advances in Neural Information Processing Systems, vol. 37, pp. 96127–96149, 2024
2024
-
[14]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 9650–9660, 2021
2021
-
[15]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark,et al., “Learning transferable visual models from natural language supervi- sion,” inInternational conference on machine learning, pp. 8748–8763, PmLR, 2021
2021
-
[16]
Least-squares estimation of transformation parameters between two point pat- terns,
S. Umeyama, “Least-squares estimation of transformation parameters between two point pat- terns,”IEEE Transactions on Pattern Analysis & Machine Intelligence, vol. 13, no. 04, pp. 376– 380, 1991
1991
-
[17]
Sgpa: Structure-guided prior adaptation for category-level 6d object pose estimation,
K. Chen and Q. Dou, “Sgpa: Structure-guided prior adaptation for category-level 6d object pose estimation,” inICCV, pp. 2773–2782, 2021
2021
-
[18]
Gpv-pose: Category- level object pose estimation via geometry-guided point-wise voting,
Y . Di, R. Zhang, Z. Lou, F. Manhardt, X. Ji, N. Navab, and F. Tombari, “Gpv-pose: Category- level object pose estimation via geometry-guided point-wise voting,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6781–6791, 2022. 10
2022
-
[19]
Category-level 6d object pose and size estimation using self-supervised deep prior deformation networks,
J. Lin, Z. Wei, C. Ding, and K. Jia, “Category-level 6d object pose and size estimation using self-supervised deep prior deformation networks,” inEuropean Conference on Computer Vision, pp. 19–34, Springer, 2022
2022
-
[20]
Ist-net: Prior-free category-level pose estimation with implicit space transformation,
J. Liu, Y . Chen, X. Ye, and X. Qi, “Ist-net: Prior-free category-level pose estimation with implicit space transformation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 13978–13988, 2023
2023
-
[21]
Secondpose: Se (3)-consistent dual-stream feature fusion for category-level pose estimation,
Y . Chen, Y . Di, G. Zhai, F. Manhardt, C. Zhang, R. Zhang, F. Tombari, N. Navab, and B. Busam, “Secondpose: Se (3)-consistent dual-stream feature fusion for category-level pose estimation,” inCVPR, pp. 9959–9969, 2024
2024
-
[22]
Object level depth reconstruction for category level 6d object pose estimation from monocular rgb image,
Z. Fan, Z. Song, J. Xu, Z. Wang, K. Wu, H. Liu, and J. He, “Object level depth reconstruction for category level 6d object pose estimation from monocular rgb image,” inEuropean Conference on Computer Vision, pp. 220–236, Springer, 2022
2022
-
[23]
Category-level metric scale object shape and pose estimation,
T. Lee, B.-U. Lee, M. Kim, and I. S. Kweon, “Category-level metric scale object shape and pose estimation,”IEEE Robotics and Automation Letters, vol. 6, no. 4, pp. 8575–8582, 2021
2021
-
[24]
Rgb-based category-level object pose estimation via decoupled metric scale recovery,
J. Wei, X. Song, W. Liu, L. Kneip, H. Li, and P. Ji, “Rgb-based category-level object pose estimation via decoupled metric scale recovery,” in2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 2036–2042, IEEE, 2024
2036
-
[25]
Unified category-level object detection and pose estimation from rgb images using 3d prototypes,
T. Fischer, X. Zhang, and E. Ilg, “Unified category-level object detection and pose estimation from rgb images using 3d prototypes,” inICCV, pp. 9790–9800, 2025
2025
-
[26]
Lapose: Laplacian mixture shape modeling for rgb-based category-level object pose estimation,
R. Zhang, Z. Huang, G. Wang, C. Zhang, Y . Di, X. Zuo, J. Tang, and X. Ji, “Lapose: Laplacian mixture shape modeling for rgb-based category-level object pose estimation,” inEuropean Conference on Computer Vision, pp. 467–484, Springer, 2024
2024
-
[27]
Nemo: Neural mesh models of contrastive features for robust 3d pose estimation,
W. Angtian, A. Kortylewski, and A. Yuille, “Nemo: Neural mesh models of contrastive features for robust 3d pose estimation,” inICLR, 2021
2021
-
[28]
inemo: Incremental neural mesh models for robust class-incremental learning,
T. Fischer, Y . Liu, A. Jesslen, N. Ahmed, P. Kaushik, A. Wang, A. Yuille, A. Kortylewski, and E. Ilg, “inemo: Incremental neural mesh models for robust class-incremental learning,” in ECCV, 2024
2024
-
[29]
Novum: Neural object volumes for robust object classification,
A. Jesslen, G. Zhang, A. Wang, W. Ma, A. Yuille, and A. Kortylewski, “Novum: Neural object volumes for robust object classification,” inEuropean Conference on Computer Vision, pp. 264–281, Springer, 2025
2025
-
[30]
Robust category-level 6d pose estimation with coarse-to-fine rendering of neural features,
W. Ma, A. Wang, A. Yuille, and A. Kortylewski, “Robust category-level 6d pose estimation with coarse-to-fine rendering of neural features,” inECCV, pp. 492–508, Springer, 2022
2022
-
[31]
Orient anything: Learning robust object orientation estimation from rendering 3d models,
Z. Wang, Z. Zhang, T. Pang, C. Du, H. Zhao, and Z. Zhao, “Orient anything: Learning robust object orientation estimation from rendering 3d models,”arXiv preprint arXiv:2412.18605, 2024
-
[32]
Orient anything v2: Unifying orientation and rotation understanding,
Z. Wang, Z. Zhang, J. Xu, J. Wang, T. Pang, C. Du, H. Zhao, and Z. Zhao, “Orient anything v2: Unifying orientation and rotation understanding,”arXiv preprint arXiv:2601.05573, 2026
-
[33]
Category-level 6d object pose estimation in the wild: A semi-supervised learning approach and a new dataset,
Y . Fu and X. Wang, “Category-level 6d object pose estimation in the wild: A semi-supervised learning approach and a new dataset,”Advances in Neural Information Processing Systems, vol. 35, pp. 27469–27483, 2022
2022
-
[34]
Housecat6d-a large-scale multi-modal category level 6d object perception dataset with household objects in realistic scenarios,
H. Jung, S.-C. Wu, P. Ruhkamp, G. Zhai, H. Schieber, G. Rizzoli, P. Wang, H. Zhao, L. Garat- toni, S. Meier,et al., “Housecat6d-a large-scale multi-modal category level 6d object perception dataset with household objects in realistic scenarios,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pp. 22498–22508, 2024
2024
-
[35]
Foundpose: Unseen object pose estimation with foundation features,
E. P. Örnek, Y . Labbé, B. Tekin, L. Ma, C. Keskin, C. Forster, and T. Hodan, “Foundpose: Unseen object pose estimation with foundation features,” inECCV, pp. 163–182, Springer, 2024
2024
-
[36]
Gigapose: Fast and robust novel object pose estimation via one correspondence,
V . N. Nguyen, T. Groueix, M. Salzmann, and V . Lepetit, “Gigapose: Fast and robust novel object pose estimation via one correspondence,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9903–9913, June 2024
2024
-
[37]
MegaPose: 6D pose estimation of novel objects via render & compare,
Y . Labbé, L. Manuelli, A. Mousavian, S. Tyree, S. Birchfield, J. Tremblay, J. Carpentier, M. Aubry, D. Fox, and J. Sivic, “Megapose: 6d pose estimation of novel objects via render & compare,”arXiv preprint arXiv:2212.06870, 2022. 11
-
[38]
Foundationpose: Unified 6d pose estimation and tracking of novel objects,
B. Wen, W. Yang, J. Kautz, and S. Birchfield, “Foundationpose: Unified 6d pose estimation and tracking of novel objects,” inCVPR, pp. 17868–17879, 2024
2024
-
[39]
Onepose: One-shot object pose estimation without cad models,
J. Sun, Z. Wang, S. Zhang, X. He, H. Zhao, G. Zhang, and X. Zhou, “Onepose: One-shot object pose estimation without cad models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6825–6834, 2022
2022
-
[40]
Onepose++: Keypoint-free one- shot object pose estimation without cad models,
X. He, J. Sun, Y . Wang, D. Huang, H. Bao, and X. Zhou, “Onepose++: Keypoint-free one- shot object pose estimation without cad models,”Advances in Neural Information Processing Systems, vol. 35, pp. 35103–35115, 2022
2022
-
[41]
Gen6d: Generalizable model-free 6-dof object pose estimation from rgb images,
Y . Liu, Y . Wen, S. Peng, C. Lin, X. Long, T. Komura, and W. Wang, “Gen6d: Generalizable model-free 6-dof object pose estimation from rgb images,” inEuropean Conference on Computer Vision, pp. 298–315, Springer, 2022
2022
-
[42]
Unopose: Unseen object pose estimation with an unposed rgb-d reference image,
X. Liu, G. Wang, R. Zhang, C. Zhang, F. Tombari, and X. Ji, “Unopose: Unseen object pose estimation with an unposed rgb-d reference image,” inCVPR, pp. 22023–22034, 2025
2025
-
[43]
One2any: One-reference 6d pose estimation for any object,
M. Liu, S. Li, A. Chhatkuli, P. Truong, L. Van Gool, and F. Tombari, “One2any: One-reference 6d pose estimation for any object,” inProceedings of the Computer Vision and Pattern Recogni- tion Conference, pp. 6457–6467, 2025
2025
-
[44]
ConceptPose: Training-Free Zero-Shot Object Pose Estimation using Concept Vectors
L. Kuang, Y . Velikova, M. Saleh, J.-N. Zaech, D. P. Paudel, and B. Busam, “Concept- pose: Training-free zero-shot object pose estimation using concept vectors,”arXiv preprint arXiv:2512.09056, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Any6d: Model-free 6d pose estimation of novel objects,
T. Lee, B. Wen, M. Kang, G. Kang, I. S. Kweon, and K.-J. Yoon, “Any6d: Model-free 6d pose estimation of novel objects,” inCVPR, pp. 11633–11643, 2025
2025
-
[46]
One view, many worlds: Single-image to 3d object meets generative domain randomization for one-shot 6d pose estimation,
Z. Geng, N. Wang, S. Xu, C. Ye, B. Li, Z. Chen, S. Peng, and H. Zhao, “One view, many worlds: Single-image to 3d object meets generative domain randomization for one-shot 6d pose estimation,” inConference on Robot Learning, pp. 168–197, PMLR, 2025
2025
-
[47]
Mfos: Model-free & one-shot object pose estimation,
J. Lee, Y . Cabon, R. Brégier, S. Yoo, and J. Revaud, “Mfos: Model-free & one-shot object pose estimation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 2911–2919, 2024
2024
-
[48]
Boxdreamer: Dreaming box corners for generalizable object pose estimation,
Y . Yu, X. He, C. Zhao, J. Yu, J. Yang, R. Hu, Y . Shen, X. Zhu, X. Zhou, and S. Peng, “Boxdreamer: Dreaming box corners for generalizable object pose estimation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9374–9384, 2025
2025
-
[49]
Shic: Shape-image correspondences with no keypoint supervision,
A. Shtedritski, C. Rupprecht, and A. Vedaldi, “Shic: Shape-image correspondences with no keypoint supervision,” inEuropean Conference on Computer Vision, pp. 129–145, Springer, 2024
2024
-
[50]
Unsupervised learning of category-level 3d pose from object-centric videos,
L. Sommer, A. Jesslen, E. Ilg, and A. Kortylewski, “Unsupervised learning of category-level 3d pose from object-centric videos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 22787–22796, 2024
2024
-
[51]
Common3d: Self-supervised learning of 3d morphable models for common objects in neural feature space,
L. Sommer, O. Dünkel, C. Theobalt, and A. Kortylewski, “Common3d: Self-supervised learning of 3d morphable models for common objects in neural feature space,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 6468–6479, 2025
2025
-
[52]
Leveraging se(3) equivariance for self-supervised category-level object pose estimation,
X. Li, Y . Weng, L. Yi, L. Guibas, A. L. Abbott, S. Song, and H. Wang, “Leveraging se(3) equivariance for self-supervised category-level object pose estimation,”Thirty-Fifth Conference on Neural Information Processing Systems, 2021
2021
-
[53]
Canon- ical capsules: Self-supervised capsules in canonical pose,
W. Sun, A. Tagliasacchi, B. Deng, S. Sabour, S. Yazdani, G. E. Hinton, and K. M. Yi, “Canon- ical capsules: Self-supervised capsules in canonical pose,”Advances in Neural information processing systems, vol. 34, pp. 24993–25005, 2021
2021
-
[54]
Multi-path learning for object pose estimation across domains,
M. Sundermeyer, M. Durner, E. Y . Puang, Z.-C. Marton, N. Vaskevicius, K. O. Arras, and R. Triebel, “Multi-path learning for object pose estimation across domains,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 13916–13925, 2020
2020
-
[55]
A tale of two features: Stable diffusion complements dino for zero-shot semantic correspondence,
J. Zhang, C. Herrmann, J. Hur, L. Polania Cabrera, V . Jampani, D. Sun, and M.-H. Yang, “A tale of two features: Stable diffusion complements dino for zero-shot semantic correspondence,” Advances in Neural Information Processing Systems, vol. 36, pp. 45533–45547, 2023
2023
-
[56]
Improving semantic correspondence with viewpoint- guided spherical maps,
O. Mariotti, O. Mac Aodha, and H. Bilen, “Improving semantic correspondence with viewpoint- guided spherical maps,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 19521–19530, 2024. 12
2024
-
[57]
Do it yourself: Learning semantic correspondence from pseudo-labels,
O. Dünkel, T. Wimmer, C. Theobalt, C. Rupprecht, and A. Kortylewski, “Do it yourself: Learning semantic correspondence from pseudo-labels,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 5834–5844, October 2025
2025
-
[58]
A least squares estimate of satellite attitude,
G. Wahba, “A least squares estimate of satellite attitude,”SIAM review, vol. 7, no. 3, pp. 409–409, 1965
1965
-
[59]
Epnp: An accurate o(n) solution to the pnp problem,
V . Lepetit, F. Moreno-Noguer, and P. Fua, “Epnp: An accurate o(n) solution to the pnp problem,” International journal of computer vision, vol. 81, pp. 155–166, 2009
2009
-
[60]
Givepose: Gradual intra-class variation elimination for rgb-based category-level object pose estimation,
Z. Huang, G. Wang, C. Zhang, R. Zhang, X. Li, and X. Ji, “Givepose: Gradual intra-class variation elimination for rgb-based category-level object pose estimation,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 22055–22066, 2025
2025
-
[61]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge,et al., “Qwen3-vl technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Uncommon objects in 3d,
X. Liu, P. Tayal, J. Wang, J. Zarzar, T. Monnier, K. Tertikas, J. Duan, A. Toisoul, J. Y . Zhang, N. Neverova,et al., “Uncommon objects in 3d,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14102–14113, 2025
2025
-
[63]
Omni6dpose: A benchmark and model for universal 6d object pose estimation and tracking,
J. Zhang, W. Huang, B. Peng, M. Wu, F. Hu, Z. Chen, B. Zhao, and H. Dong, “Omni6dpose: A benchmark and model for universal 6d object pose estimation and tracking,” inEuropean Conference on Computer Vision, pp. 199–216, Springer, 2024
2024
-
[64]
Objectron: A large scale dataset of object-centric videos in the wild with pose annotations,
A. Ahmadyan, L. Zhang, A. Ablavatski, J. Wei, and M. Grundmann, “Objectron: A large scale dataset of object-centric videos in the wild with pose annotations,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 7822–7831, 2021
2021
-
[65]
Objectnet3d: A large scale database for 3d object recognition,
Y . Xiang, W. Kim, W. Chen, J. Ji, C. Choy, H. Su, R. Mottaghi, L. Guibas, and S. Savarese, “Objectnet3d: A large scale database for 3d object recognition,” inEuropean conference on computer vision, pp. 160–176, Springer, 2016
2016
-
[66]
Zero-shot category-level object pose estima- tion,
W. Goodwin, S. Vaze, I. Havoutis, and I. Posner, “Zero-shot category-level object pose estima- tion,” inEuropean Conference on Computer Vision, pp. 516–532, Springer, 2022
2022
-
[67]
Rotation averaging,
R. Hartley, J. Trumpf, Y . Dai, and H. Li, “Rotation averaging,”International journal of computer vision, vol. 103, no. 3, pp. 267–305, 2013
2013
-
[68]
Modular primitives for high-performance differentiable rendering,
S. Laine, J. Hellsten, T. Karras, Y . Seol, J. Lehtinen, and T. Aila, “Modular primitives for high-performance differentiable rendering,”ACM Transactions on Graphics, vol. 39, no. 6, 2020
2020
-
[69]
O. Siméoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa,et al., “Dinov3,”arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Lora: Low-rank adaptation of large language models.,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen,et al., “Lora: Low-rank adaptation of large language models.,”Iclr, vol. 1, no. 2, p. 3, 2022
2022
-
[71]
Unified perceptual parsing for scene understand- ing,
T. Xiao, Y . Liu, B. Zhou, Y . Jiang, and J. Sun, “Unified perceptual parsing for scene understand- ing,” inProceedings of the European conference on computer vision (ECCV), pp. 418–434, 2018
2018
-
[72]
PoseLib - Minimal Solvers for Camera Pose Estimation,
V . Larsson and contributors, “PoseLib - Minimal Solvers for Camera Pose Estimation,” 2020. 13 A Overview This supplement provides additional details and analyses referenced in the main paper: • Implementation details and training hyperparameters (B) • Evaluation protocol, including symmetry-aware metrics and convention mapping (C) • Full symmetry-class b...
2020
-
[73]
We use AdamW with weight decay 0.05 and gradient clipping at norm 1.0
and mixed precision. We use AdamW with weight decay 0.05 and gradient clipping at norm 1.0. The learning rate is 10−4 for non-backbone parameters and 10−5 for LoRA parameters. The correspondence softmax temperature τ follows a three-stage cosine schedule: 0.20→0.17 over the first30%of training,0.17→0.13over the next50%, and0.13→0.10over the final 20%. B.6...
-
[74]
2.Class 1 (asymmetric): a unique identifiable front; full yaw determination is possible
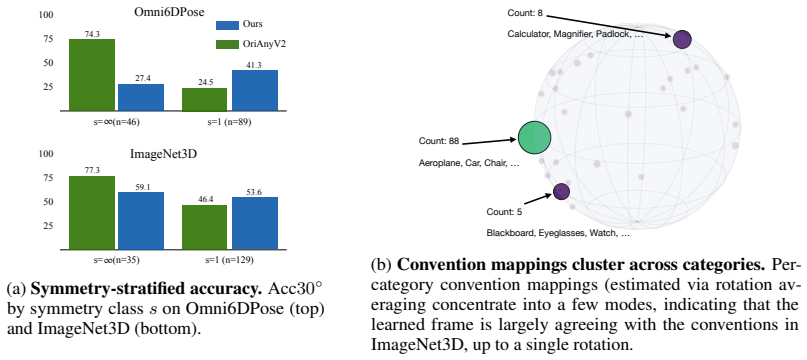
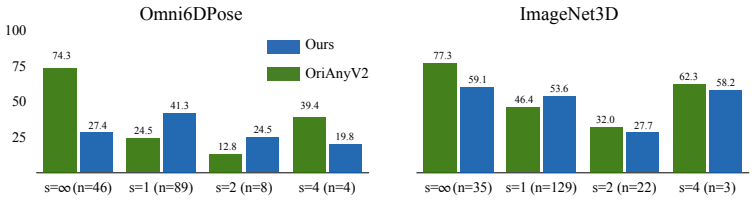
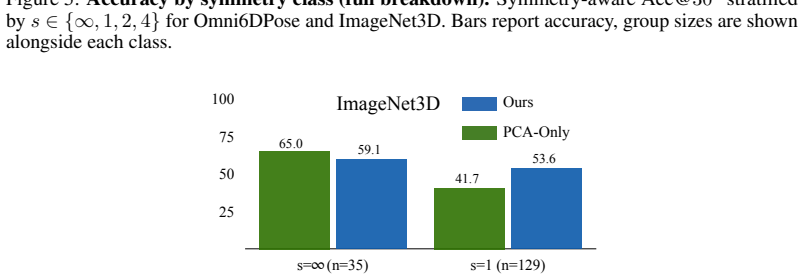
Class ∞ (continuous): rotationally symmetric about the vertical axis; yaw is unrecoverable. 2.Class 1 (asymmetric): a unique identifiable front; full yaw determination is possible. 3.Class 2 (180 ◦ ambiguity): front and back are indistinguishable but side views differ. 4.Class 4 (90 ◦ ambiguity): all four cardinal yaw orientations are indistinguishable. H...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.