FlexMoE: One-for-All Nested Intra-Expert Pruning for MoE Language Models
Pith reviewed 2026-06-29 04:33 UTC · model grok-4.3
The pith
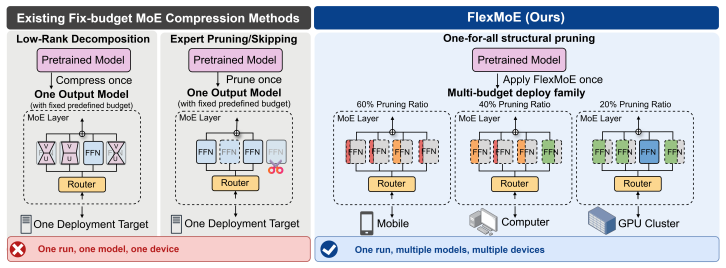
MoE models can be turned into nested subnetworks for any budget with one training run and one recovery fine-tune.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
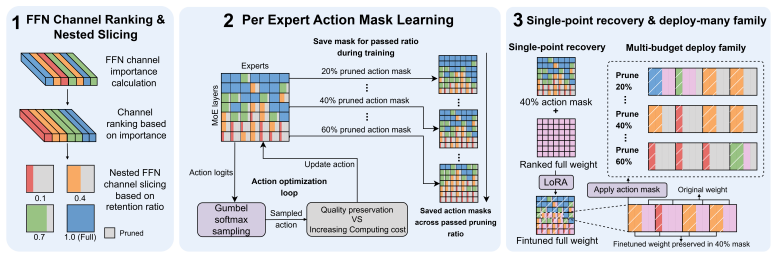
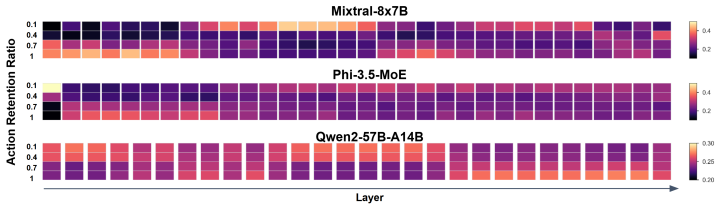
By ranking expert FFN channels by their importance, then letting each expert learn a discrete action to prune its channels, and by gradually increasing cost pressure, a single action-training run exports a series of action masks from high to low budgets, each of which identifies a reliable smaller subnetwork nested in the ranked base model. A single recovery fine-tune at a mid pruning budget recovers degraded model quality and transfers the recovered model to other unseen budgets.
What carries the argument
Nested intra-expert pruning masks generated by ranking FFN channels and training discrete pruning actions under rising cost pressure.
If this is right
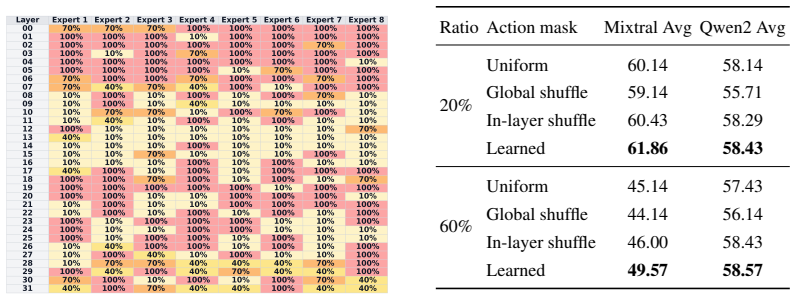
- Retains ~99.8% of base performance while pruning 50% of routed expert parameters even without fine-tuning.
- Pruned subnetworks deliver real memory reduction and throughput gains.
- Supports realtime online budget switching with kernel-level co-design.
- Surpasses recent fixed-budget MoE compression baselines.
Where Pith is reading between the lines
- The nested masks allow a single stored model to serve multiple device classes without separate compression runs.
- Recovery at one budget point may indicate that the main performance loss is driven by a small number of critical channels common across budgets.
- Kernel co-design for budget switching suggests the masks can be applied at inference time without full model reloads.
Load-bearing premise
Ranking expert FFN channels by importance and training discrete pruning actions under gradually increasing cost pressure will produce reliable nested masks whose performance can be recovered at one mid-budget point and then transferred to all other unseen budgets.
What would settle it
Compare accuracy of the single mid-budget recovered model at a 60 percent pruning level against accuracy of a model trained and recovered specifically for that same 60 percent level.
Figures



read the original abstract
Mixture-of-Experts (MoE) language models scale model ability with sparsely activated experts, making this architecture a standard recipe for modern large models. However, sparse activation does not remove the deployment burden of storing and serving all experts, and the available deployment budget can vary substantially across devices, users, and workloads. Existing MoE compression methods are still largely fixed-budget, typically optimizing one compressed endpoint at each chosen target budget. We study a different setting: converting a large pretrained MoE LLM into a nested family of deployable subnetworks across budgets. Our method first ranks expert FFN channels by their importance, then lets each expert learn a discrete action to prune its channels. By gradually increasing cost pressure, a single action-training run exports a series of action masks from high to low budgets, each of which identifies a reliable smaller subnetwork nested in the ranked base model. Moreover, we use a single recovery fine-tune at a mid pruning budget (40%) to recover degraded model quality and transfer the recovered model to other unseen budgets. Overall, our framework surpasses recent MoE compression baselines. Specifically, on Qwen2-57B-A14B, our method retains ~99.8% of base performance while pruning 50% of routed expert parameters even without fine-tuning. For deployment, our pruned subnetworks deliver real memory reduction and throughput gains, and further support realtime online budget switching with kernel-level co-design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FlexMoE, a method to convert a pretrained MoE LLM into a nested family of deployable subnetworks across varying budgets. It first ranks expert FFN channels by importance, then trains discrete per-expert pruning actions under gradually increasing cost pressure to export a series of nested action masks. A single recovery fine-tune is performed only at the 40% budget point, after which the recovered weights are asserted to transfer to all other budgets. On Qwen2-57B-A14B the method is claimed to retain ~99.8% of base performance at 50% routed-expert-parameter pruning even without fine-tuning, to outperform recent MoE compression baselines, and to deliver memory/throughput gains plus realtime online budget switching via kernel-level co-design.
Significance. If the nested-mask construction and single-point recovery transfer both hold, the result would be significant for practical deployment of large MoE models on heterogeneous hardware, because a single trained model could serve multiple operating budgets without per-budget retraining.
major comments (2)
- [Abstract] Abstract: the central 'one-for-all' claim rests on the assertion that a single recovery fine-tune at the 40% budget point corrects degradation at every other budget via the nested masks. No argument is supplied that the learned discrete actions produce strictly nested subnetworks whose relative degradation is sufficiently uniform for this transfer to hold without additional per-budget tuning.
- [Abstract] Abstract: the reported ~99.8% retention at 50% pruning (no fine-tuning) is presented as a measured outcome, yet the abstract supplies neither the experimental protocol, ablation results on the importance-ranking step, nor verification that the exported masks are indeed nested across the full budget range.
minor comments (1)
- [Abstract] Abstract: the phrase 'kernel-level co-design' for realtime budget switching is mentioned but not defined or referenced to any concrete implementation detail.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments on our manuscript. We address each of the major comments below, providing clarifications from the full paper and indicating where revisions will be made to the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central 'one-for-all' claim rests on the assertion that a single recovery fine-tune at the 40% budget point corrects degradation at every other budget via the nested masks. No argument is supplied that the learned discrete actions produce strictly nested subnetworks whose relative degradation is sufficiently uniform for this transfer to hold without additional per-budget tuning.
Authors: While the abstract is necessarily concise, the full manuscript in Sections 3.1-3.3 provides the argument: the channel importance ranking combined with discrete action learning under monotonically increasing cost constraints produces strictly nested masks by construction, as pruning decisions for lower budgets build upon those for higher budgets. The uniformity of relative degradation is supported by the consistent performance curves in our experiments (Section 4.3), where the single recovery fine-tune at 40% transfers to other budgets with minimal additional loss. We will revise the abstract to include a short phrase noting the nested construction and transfer property. revision: partial
-
Referee: [Abstract] Abstract: the reported ~99.8% retention at 50% pruning (no fine-tuning) is presented as a measured outcome, yet the abstract supplies neither the experimental protocol, ablation results on the importance-ranking step, nor verification that the exported masks are indeed nested across the full budget range.
Authors: The abstract summarizes the key result; the experimental protocol is fully detailed in Section 4, including the use of Qwen2-57B-A14B, zero-shot and few-shot evaluations, and the no-fine-tuning setting. Ablations on importance ranking appear in Section 4.4, and mask nesting is verified in Section 4.2 with explicit subset checks and performance consistency. We will update the abstract to reference these sections and briefly state that nesting was verified. revision: yes
Circularity Check
No circularity detected; empirical method with measured outcomes
full rationale
The paper presents an empirical compression technique for MoE LLMs that ranks channels, trains discrete pruning actions under increasing cost pressure, performs one recovery fine-tune at the 40% budget, and reports measured performance retention on held-out budgets. No equations, derivations, or first-principles results are supplied that could reduce to their own inputs by construction. Performance figures (e.g., ~99.8% retention at 50% pruning) are stated as experimental measurements rather than fitted quantities renamed as predictions. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the provided text. The central claims rest on observed results from training and evaluation, which remain externally falsifiable and independent of the method's own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Channel importance ranking within each expert FFN produces a stable ordering usable for pruning decisions.
- domain assumption A single recovery fine-tune at 40% pruning transfers performance recovery to other pruning budgets.
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone.arXiv preprint arXiv:2404.14219,
-
[2]
MathQA: Towards interpretable math word problem solving with operation-based formalisms
Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. MathQA: Towards interpretable math word problem solving with operation-based formalisms. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and ...
2019
-
[3]
Sikai Bai, Haoxi Li, Jie Zhang, Zicong Hong, and Song Guo
doi: 10.18653/v1/N19-1245. Sikai Bai, Haoxi Li, Jie Zhang, Zicong Hong, and Song Guo. DiEP: Adaptive mixture-of-experts compression through differentiable expert pruning. InAdvances in Neural Information Processing Systems,
-
[4]
I-Chun Chen, Hsu-Shen Liu, Wei-Fang Sun, Chen-Hao Chao, Yen-Chang Hsu, and Chun-Yi Lee. Retraining-free merging of sparse mixture-of-experts via hierarchical clustering.arXiv preprint arXiv:2410.08589,
-
[5]
Think you have solved question answering? try ARC, the AI2 reasoning challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge. arXiv preprint arXiv:1803.05457,
-
[6]
doi: 10.5555/3737916.3742377. Gongfan Fang, Hongxu Yin, Saurav Muralidharan, Greg Heinrich, Jeff Pool, Jan Kautz, Pavlo Molchanov, and Xinchao Wang. Maskllm: Learnable semi-structured sparsity for large language models. InAdvances in Neural Information Processing Systems,
-
[7]
Shouwei Gao, Junqi Yin, Feiyi Wang, and Wenqian Dong. Flying serving: On-the-fly parallelism switching for large language model serving.arXiv preprint arXiv:2602.22593,
-
[8]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088,
-
[9]
Pingzhi Li, Xiaolong Jin, Yu Cheng, and Tianlong Chen. Examining post-training quantization for mixture-of-experts: A benchmark.arXiv preprint arXiv:2406.08155,
-
[10]
doi: 10.18653/v1/2024.acl-long
-
[11]
Xinyue Ma, Heelim Hong, Taegeon Um, Jongseop Lee, Seoyeong Choy, Woo-Yeon Lee, and Myeongjae Jeon. Orbitflow: Slo-aware long-context llm serving with fine-grained kv cache reconfiguration.arXiv preprint arXiv:2601.10729,
-
[12]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2381–2391,
2018
-
[13]
Shangshu Qian, Kipling Liu, P. C. Sruthi, Lin Tan, and Yongle Zhang. Towards resiliency in large language model serving with kevlarflow.arXiv preprint arXiv:2601.22438,
-
[14]
Nurbek Tastan, Stefanos Laskaridis, Karthik Nandakumar, and Samuel Horvath. Mose: Mixture of slimmable experts for efficient and adaptive language models.arXiv preprint arXiv:2602.06154,
-
[15]
Zyda-2: a 5 trillion token high-quality dataset.arXiv preprint arXiv:2411.06068,
11 Yury Tokpanov, Paolo Glorioso, Quentin Anthony, and Beren Millidge. Zyda-2: a 5 trillion token high-quality dataset.arXiv preprint arXiv:2411.06068,
-
[16]
Yaoxiang Wang, Qingguo Hu, Yucheng Ding, Ruizhe Wang, Yeyun Gong, Jian Jiao, Yelong Shen, Peng Cheng, and Jinsong Su. Training matryoshka mixture-of-experts for elastic inference-time expert utilization.arXiv preprint arXiv:2509.26520,
-
[17]
URLhttps://openreview.net/forum?id=D9cnZNZfxX. An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2024a. Cheng Yang, Yang Sui, Jinqi Xiao, Lingyi Huang, Yu Gong, Yuanlin Duan, Wenqi Jia, Miao Yin, Yu Cheng, and Bo Yuan. MoE-...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.findings-emnlp 2024
-
[18]
doi: 10.18653/v1/P19-1472. Geng Zhang, Yuxuan Han, Yuxuan Lou, Wangbo Zhao, Yiqi Zhang, and Yang You. Mone: Replac- ing redundant experts with lightweight novices for structured pruning of moe.arXiv preprint arXiv:2507.00390,
-
[19]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. Sglang: Efficient execution of structured language model programs.arXiv preprint arXiv:2312.07104,
-
[20]
12 A Additional Experimental Details and Analysis A.1 Full Result Tables Table 4: Full cross-model results with all reported per-task accuracies. All numbers are zero-shot accuracy (%). Ratio Method ARC-c ARC-e HellaS OBQA PIQA WinoG MathQA Avg Mixtral-8x7B(8 experts per layer, top-2 activated per token) 0% Base model 57 84 65 36 82 76 43 63.29 20% NAEE 4...
arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.