How Much Coordination Gain Is Real? A Paired Noise-Floor Protocol for Multi-Agent LLM Benchmarks
Pith reviewed 2026-06-27 02:45 UTC · model grok-4.3
The pith
Paired inert protocols on the same model produce gaps up to 18pp that exceed most published multi-agent coordination effects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
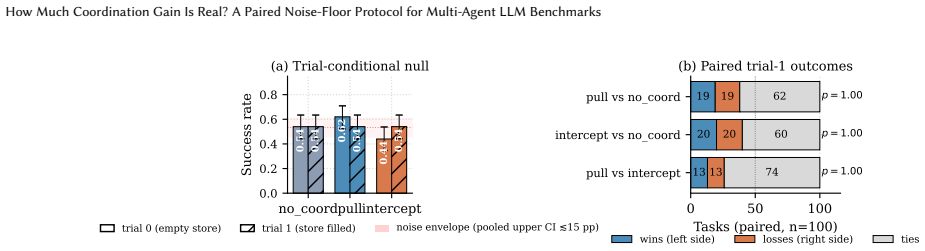
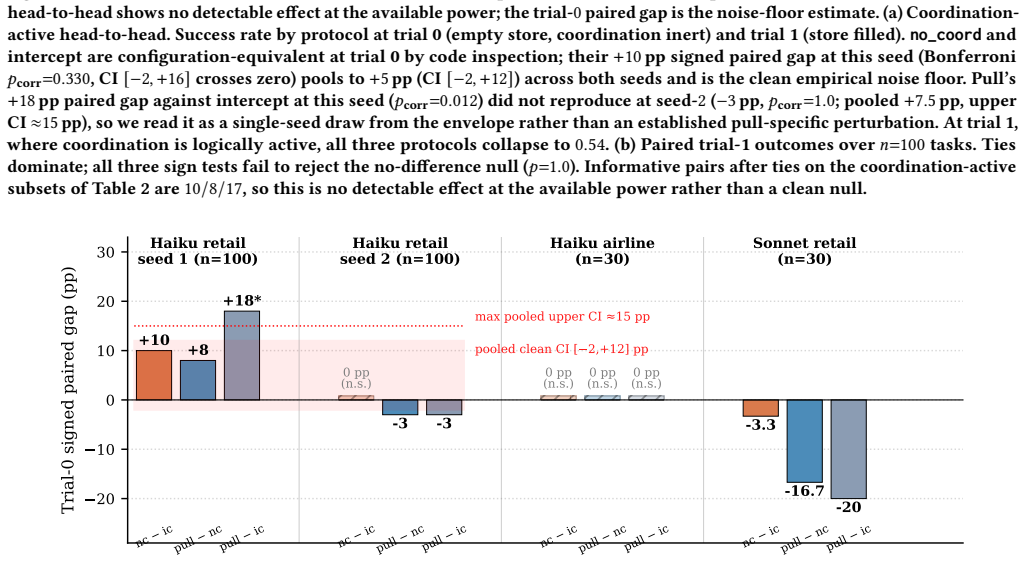
On Claude Haiku 4.5 against tau^2-bench retail, the clean configuration-equivalent contrast between no_coord and intercept, both inert at trial 0, produces signed paired gaps of +10pp and 0pp across two n=100 seeds; pooled across both, +5pp with Wilson CI [-2,+12], not significant. The envelope of observed paired gaps spans [-3,+18]pp across two seeds, with pooled upper Wilson CI ~15pp. Seven of ten recent multi-agent coordination architectures report headline effects below this local floor, and one more sits inside the envelope.
What carries the argument
The configuration-equivalent contrast between two inert protocols (no_coord and intercept) under code inspection plus SHA-256 byte audit of API inputs, which sets the paired noise floor for coordination claims.
If this is right
- Headline effects below the observed 15pp upper bound cannot be distinguished from paired noise in this input-matched setting.
- Any coordination claim must report coordination-active pass^k restricted to trials where the mechanism is logically active.
- Sample-size targets and runtime hooks become required to place reported deltas outside the local envelope.
- The same-model paired replication protocol is needed to test survival of original headline effects.
Where Pith is reading between the lines
- If the noise envelope varies by model size or benchmark domain, the minimum credible effect size would need to be remeasured for each new setting.
- Extending the protocol to active coordination mechanisms might raise the observed floor when those mechanisms introduce additional input variation.
- The lack of improvement from candidate readers on trial-1 recovery points to sources of variation beyond the configuration match itself.
Load-bearing premise
That the clean configuration-equivalent contrast between no_coord and intercept on Claude Haiku 4.5 against tau^2-bench retail accurately represents the noise floor that would apply to active coordination mechanisms under the same input-matching protocol.
What would settle it
Running the identical paired inert contrast on a different model or benchmark and consistently observing gaps above 18pp would show that the local floor measured here does not generalize.
Figures
read the original abstract
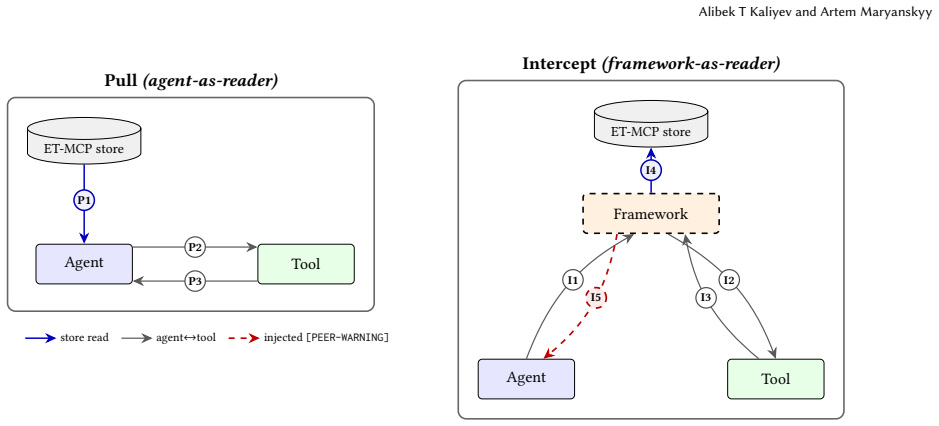
Multi-agent LLM coordination papers report small benchmark deltas as evidence that one architecture beats another. A prior question: how much paired trial-0 disagreement do two protocols produce on the same model and benchmark when their API inputs are configuration-equivalent (matched by code inspection plus a SHA-256 byte audit), short of full identity-replay? On Claude Haiku 4.5 against tau^2-bench retail, the clean configuration-equivalent contrast (no_coord vs. intercept, both inert at trial 0) gives signed paired gaps of +10pp and 0pp across two n=100 seeds; pooled across both, +5pp with Wilson CI [-2,+12], not significant. The largest single-seed contrast (+18pp pull-vs-intercept, p_corr=0.012) did not reproduce at the second seed (-3pp, p_corr=1.0); no trial-0 contrast is significant after Bonferroni at either seed or pooled. The envelope of observed paired gaps spans [-3,+18]pp across two seeds, with pooled upper Wilson CI ~15pp. Seven of ten recent multi-agent coordination architectures report headline effects below this local floor, and one more sits inside the envelope; whether they survive a same-model paired replication is, by construction, untested in their original settings. We define coordination-active pass^k, pass^k restricted to trials where the coordination mechanism is logically active, as the minimum reporting protocol, with sample-size targets and runtime hooks in the body. Measurements run on ET-MCP, a task-scoped negative-knowledge store conformant with MCP 2026-07-28, used as a substrate to isolate reader-side choices, not as a contribution. On Haiku 4.5 the candidate readers (pull, intercept) do not improve trial-1 recovery; we give a preliminary diagnosis of failure modes with refinements on existing production hook surfaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a paired noise-floor protocol using two configuration-equivalent inert protocols (no_coord vs. intercept) at trial 0 on Claude Haiku 4.5 and tau^2-bench retail yields observed signed gaps with envelope [-3,+18]pp and pooled upper Wilson CI ~15pp; no contrast is significant after Bonferroni correction. It reports that seven of ten recent multi-agent coordination papers have headline effects below this local floor (with one inside the envelope) and defines a minimum reporting protocol using coordination-active pass^k.
Significance. If the local inert gap measurement is reproducible and the protocol is adopted more broadly, the work would be significant for establishing empirical baselines against which small coordination deltas can be evaluated, encouraging same-model paired replications. Strengths include the use of SHA-256 byte audit for input equivalence, Wilson intervals, Bonferroni correction, and explicit distinction of coordination-active subsets.
major comments (2)
- [Abstract] Abstract: the reported statistical results (n=100 seeds per contrast, specific gaps of +10pp/0pp, pooled +5pp with Wilson CI [-2,+12], non-reproduction of the +18pp contrast, and Bonferroni-adjusted non-significance) cannot be verified because the manuscript supplies no full methods, data tables, or code; this directly affects the soundness of the noise-floor envelope.
- [Abstract] Abstract: the central claim that seven of ten papers fall below the local floor treats the inert no_coord/intercept gap on Haiku 4.5 + tau^2-bench retail as representative of the relevant variability for active coordination mechanisms; the manuscript provides neither cross-model/cross-benchmark replications nor an argument that prompt complexity or decision branching under active mechanisms would not inflate variance beyond the inert baseline.
minor comments (1)
- The definition of coordination-active pass^k and the role of the ET-MCP substrate as a negative-knowledge store would benefit from an expanded methods subsection with concrete examples of how reader-side choices are isolated.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported statistical results (n=100 seeds per contrast, specific gaps of +10pp/0pp, pooled +5pp with Wilson CI [-2,+12], non-reproduction of the +18pp contrast, and Bonferroni-adjusted non-significance) cannot be verified because the manuscript supplies no full methods, data tables, or code; this directly affects the soundness of the noise-floor envelope.
Authors: We agree that the absence of full methods, data tables, and code in the current manuscript version prevents independent verification of the reported statistics. In the revised manuscript we will add a dedicated methods section describing the paired protocol, SHA-256 audit procedure, seed handling, and statistical corrections; we will also include the complete data tables for both n=100 seeds and provide a permanent link to the open code repository containing the exact scripts used. revision: yes
-
Referee: [Abstract] Abstract: the central claim that seven of ten papers fall below the local floor treats the inert no_coord/intercept gap on Haiku 4.5 + tau^2-bench retail as representative of the relevant variability for active coordination mechanisms; the manuscript provides neither cross-model/cross-benchmark replications nor an argument that prompt complexity or decision branching under active mechanisms would not inflate variance beyond the inert baseline.
Authors: The manuscript presents the measured gap explicitly as a local noise floor for this specific model-benchmark pair and inert protocols, not as a universal representative. The core argument is that any coordination claim should be evaluated against a same-model paired baseline on the authors' own setup. We will add a clarifying paragraph in the discussion that (a) acknowledges active mechanisms may increase variance due to prompt complexity and branching, (b) positions the inert envelope as a conservative minimum reporting threshold rather than an upper bound, and (c) reiterates the recommendation for same-model paired replications. Cross-model and cross-benchmark replications are outside the scope of the present work. revision: partial
- The manuscript does not contain cross-model or cross-benchmark replications of the inert gap measurement.
Circularity Check
No circularity; empirical measurements compared to external reports
full rationale
The manuscript reports direct experimental measurements of paired gaps between configuration-equivalent inert protocols (no_coord vs. intercept) on a fixed model and benchmark, then compares the resulting envelope to headline deltas from ten other papers. No equations, fitted parameters, self-definitional relations, or load-bearing self-citations appear in the derivation chain; the noise-floor envelope is an observed quantity, not one that reduces to the inputs it is used to bound. The generalization concern raised in the skeptic note is an external-validity question, not a circularity reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Wilson score interval is the appropriate confidence interval for the observed paired success-rate gaps
- standard math Bonferroni correction adequately controls family-wise error for the set of contrasts tested across seeds
Reference graph
Works this paper leans on
-
[1]
Amazon Web Services. 2025. Amazon Bedrock AgentCore Policy: Real-Time Tool-Call Boundary Enforcement. Product announcement. https://aws.amazon.com/about-aws/whats-new/2025/12/amazon-bedrock- agentcore-policy-evaluations-preview/
2025
-
[2]
Amazon Web Services. 2025. Strands Agents SDK: Hooks API for Agent Lifecycle Interception. Open-source SDK documentation. https://strandsagents.com/ docs/user-guide/concepts/agents/hooks/
2025
-
[3]
Anthropic Engineering. 2026. Quantifying Infrastructure Noise in Agentic Cod- ing Evals. Engineering blog post. https://www.anthropic.com/engineering/ infrastructure-noise
2026
-
[4]
Victor Barres, Honghua Dong, Soham Ray, Xujie Jia, and Shunyu Yao. 2025. 𝜏2-bench: Evaluating Conversational Agents in a Dual-Control Environment. arXiv:2506.07982 [cs.CL] https://arxiv.org/abs/2506.07982
Pith/arXiv arXiv 2025
- [5]
-
[6]
BerriAI litellm community. 2025. Anthropic message history validation error after consecutive tool calls. GitHub issue. https://github.com/BerriAI/litellm/ issues/15322
2025
-
[7]
BerriAI litellm community. 2025. Anthropic provider produces malformed tool_use/tool_result sequences on multi-turn tool calls. GitHub issue. https://github.com/BerriAI/litellm/issues/12404
2025
-
[8]
Bjarni Haukur Bjarnason, André Silva, and Martin Monperrus. 2026. On Random- ness in Agentic Evals. arXiv:2602.07150 [cs.AI] https://arxiv.org/abs/2602.07150
arXiv 2026
-
[9]
Mert Cemri et al. 2025. MAST: A Taxonomy of Multi-Agent System Failures from 1,600+ Production Traces. InAdvances in Neural Information Processing Systems (NeurIPS). 8 How Much Coordination Gain Is Real? A Paired Noise-Floor Protocol for Multi-Agent LLM Benchmarks
2025
-
[10]
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chen-Ming Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, Yujia Qin, Xin Cong, Ruobing Xie, Zhiyuan Liu, Maosong Sun, and Jie Zhou. 2024. AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors. In ICLR. arXiv:2308.10848 [cs.CL] https://arxiv.org/abs/2308.10848
Pith/arXiv arXiv 2024
-
[11]
Alejandro Cuadron and Amazon AGI. 2025. 𝜏2-Bench-Verified: Corrected Task Definitions for Tool-Agent Evaluation. GitHub release. https://github.com/ amazon-agi/tau2-bench-verified
2025
-
[12]
Tianxiang Fei, Cheng Chen, Yue Pan, Mao Zheng, and Mingyang Song. 2026. CodeDelegator: Mitigating Context Pollution via Role Separation in Code-as- Action Agents. arXiv:2601.14914 [cs.CL] https://arxiv.org/abs/2601.14914
arXiv 2026
-
[13]
Aayush Gupta. 2026. ReliabilityBench: Evaluating LLM Agent Reliability Under Production-Like Stress Conditions. arXiv:2601.06112 [cs.AI] https://arxiv.org/ abs/2601.06112
arXiv 2026
-
[14]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, et al. 2024. MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework. InICLR. arXiv:2308.00352 [cs.AI] https://arxiv.org/abs/2308.00352
Pith/arXiv arXiv 2024
-
[15]
Meenakshi Amulya Jayanti and X. Y. Han. 2026. Enhancing Model Context Pro- tocol (MCP) with Context-Aware Server Collaboration. arXiv:2601.11595 [cs.DC] https://arxiv.org/abs/2601.11595
arXiv 2026
-
[16]
LangChain Team. 2026. LangChain Middleware: wrap_tool_call and after_modelHooks. Framework documentation. https://docs.langchain.com/ oss/python/langchain/middleware/custom
2026
-
[17]
Alexandre Cristóvão Maiorano. 2026. Automated Self-Testing as a Qual- ity Gate: Evidence-Driven Release Management for LLM Applications. arXiv:2603.15676 [cs.SE] https://arxiv.org/abs/2603.15676
Pith/arXiv arXiv 2026
-
[18]
Microsoft. 2026. Microsoft Agent Framework: Function Middleware with Shared State. Framework documentation. https://learn.microsoft.com/en-us/agent- framework/agents/middleware/shared-state
2026
-
[19]
Microsoft Research. 2026. STATE-Bench: A Memory-Agnostic Bench- mark for Stateful Agent Evaluation. Project page and blog post. https://opensource.microsoft.com/blog/2026/05/19/introducing-state-bench-a- benchmark-for-ai-agent-memory/
2026
-
[20]
Model Context Protocol Working Group. 2026. Model Context Protocol Spec- ification, Release Candidate 2026-07-28. https://modelcontextprotocol.io/ specification/2026-07-28/
2026
-
[21]
Zairah Mustahsan, Abel Lim, Megna Anand, Saahil Jain, and Bryan McCann. 2025. Stochasticity in Agentic Evaluations: Quantifying Inconsistency with Intraclass Correlation. arXiv:2512.06710 [cs.LG] https://arxiv.org/abs/2512.06710
arXiv 2025
-
[22]
Mason Nakamura, Abhinav Kumar, Saaduddin Mahmud, Sahar Abdelnabi, Shlomo Zilberstein, and Eugene Bagdasarian. 2025. Terrarium: Revisit- ing the Blackboard for Multi-Agent Safety, Privacy, and Security Studies. arXiv:2510.14312 [cs.MA] https://arxiv.org/abs/2510.14312
arXiv 2025
-
[23]
David Nigenda, Zohar Karnin, Muhammad Bilal Zafar, Raghu Ramesha, Alan Tan, Michele Donini, and Krishnaram Kenthapadi. 2022. Amazon SageMaker Model Monitor: A System for Real-Time Insights into Deployed Machine Learning Models. InKDD. https://www.amazon.science/publications/amazon- sagemaker-model-monitor-a-system-for-real-time-insights-into-deployed- mac...
2022
-
[24]
Long Ou, Saujas Vaduguru, and Daniel Fried. 2025. Analyzing Information Sharing and Coordination in Multi-Agent Planning. arXiv:2508.12981 [cs.CL] https://arxiv.org/abs/2508.12981
arXiv 2025
-
[25]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. 2024. MemGPT: Towards LLMs as Operating Systems. InCOLM
2024
-
[26]
Kaiyang Qian, Xinmin Fang, and Zhengxiong Li. 2026. MPAC: A Multi- Principal Agent Coordination Protocol for Interoperable Multi-Agent Collabora- tion. arXiv:2604.09744 [cs.MA] https://arxiv.org/abs/2604.09744
Pith/arXiv arXiv 2026
-
[27]
Stephan Rabanser, Sayash Kapoor, Peter Kirgis, Kangheng Liu, Saiteja Utpala, and Arvind Narayanan. 2026. Towards a Science of AI Agent Reliability. arXiv:2602.16666 [cs.LG] https://arxiv.org/abs/2602.16666
Pith/arXiv arXiv 2026
-
[28]
Abhishek Rath. 2026. Agent Drift: Quantifying Behavioral Degradation in Multi- Agent LLM Systems Over Extended Interactions. arXiv:2601.04170 [cs.MA] https://arxiv.org/abs/2601.04170
arXiv 2026
-
[29]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language Agents with Verbal Reinforcement Learning. InAdvances in Neural Information Processing Systems (NeurIPS). arXiv:2303.11366 [cs.AI] https://arxiv.org/abs/2303.11366
Pith/arXiv arXiv 2023
-
[30]
Ruipeng Wang, Yuxin Chen, Yukai Wang, Chang Wu, Junfeng Fang, Xiaodong Cai, Qi Gu, Hui Su, An Zhang, Xiang Wang, Xunliang Cai, and Tat-Seng Chua
-
[31]
arXiv:2602.11348 [cs.AI] https://arxiv.org/abs/2602
AgentNoiseBench: Benchmarking Robustness of Tool-Using LLM Agents Under Noisy Condition. arXiv:2602.11348 [cs.AI] https://arxiv.org/abs/2602. 11348
-
[32]
Zhaohui Geoffrey Wang. 2026. AgentTrace: Causal Graph Tracing for Root Cause Analysis in Deployed Multi-Agent Systems. InICLR 2026 Workshop on Agents in the Wild. arXiv:2603.14688 [cs.MA]
arXiv 2026
-
[33]
White, Doug Burger, and Chi Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Jiale Liu, Ahmed Awadallah, Ryen W. White, Doug Burger, and Chi Wang. 2023. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation Framework. InICLR 2024 LLM Agents Workshop. arXiv:2308.08155 [cs.AI] https://arxiv.org/abs/2308.08155
Pith/arXiv arXiv 2023
-
[34]
Zhongming Yu, Naicheng Yu, Hejia Zhang, Wentao Ni, Mingrui Yin, Jiaying Yang, Yujie Zhao, and Jishen Zhao. 2026. Multi-Agent Memory from a Computer Ar- chitecture Perspective: Visions and Challenges Ahead. arXiv:2603.10062 [cs.AR] https://arxiv.org/abs/2603.10062
arXiv 2026
-
[35]
Guibin Zhang, Muxin Fu, Guancheng Wan, Miao Yu, Kun Wang, and Shuicheng Yan. 2025. G-Memory: Tracing Hierarchical Memory for Multi-Agent Systems. arXiv:2506.07398 [cs.MA] https://arxiv.org/abs/2506.07398
arXiv 2025
-
[36]
Yuzhe Zhang, Feiran Liu, Yi Shan, Xinyi Huang, Xin Yang, Yueqi Zhu, Xuxin Cheng, Cao Liu, Ke Zeng, Terry Jingchen Zhang, and Wenyuan Jiang. 2026. Silo- Bench: A Scalable Environment for Evaluating Distributed Coordination in Multi- Agent LLM Systems. arXiv:2603.01045 [cs.MA] https://arxiv.org/abs/2603.01045
Pith/arXiv arXiv 2026
-
[37]
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. 2024. ExpeL: LLM Agents Are Experiential Learners. InAAAI Conference on Artificial Intelligence. arXiv:2308.10144 [cs.AI] https://arxiv.org/abs/2308. 10144 9
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.