ASTAD: Asymmetric Style Transfer for Synthetic-to-Real Adaptation in Autonomous Driving
Pith reviewed 2026-06-30 07:56 UTC · model grok-4.3
The pith
A training-free two-stage diffusion method transfers style from labeled synthetic driving images to unlabeled real references without semantic misalignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
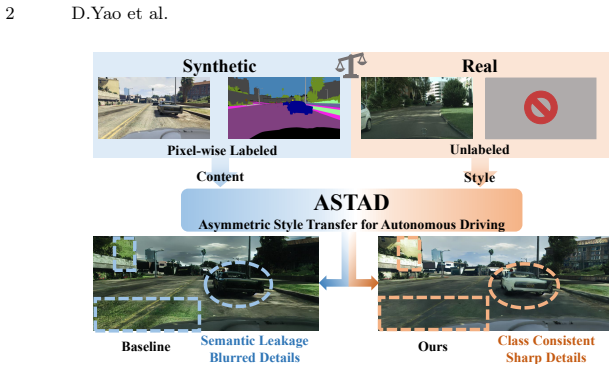
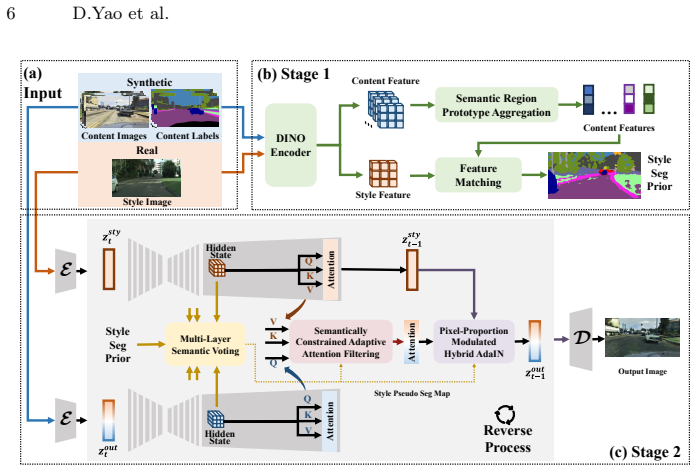
ASTModel performs semantically consistent style transfer under asymmetric constraints by extracting a coarse semantic prior from unlabeled real-world references and dynamically refining it during the denoising process for class-consistent style injection. This produces adapted images that improve downstream perception utility and structural fidelity over prior methods while delivering a 3.2 times inference speedup.
What carries the argument
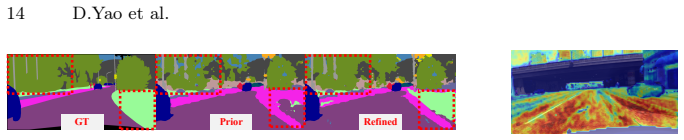
ASTModel, a training-free two-stage framework that extracts a coarse semantic prior from the unlabeled target domain and performs dynamic prior refinement plus class-consistent style injection inside the diffusion denoising steps.
If this is right
- Perception models trained on ASTModel-adapted synthetic data achieve higher accuracy on real-world test scenes.
- Pixel-perfect annotations from the synthetic source remain usable after transfer.
- No paired labeled real images or extra training are required for the adaptation step.
- The 3.2 times faster inference supports larger-scale or real-time deployment of the adapted data pipeline.
Where Pith is reading between the lines
- The same coarse-to-refined prior idea could be tested on other unpaired translation settings where one domain has labels and the other does not.
- If the refinement step proves stable across datasets, it may reduce the need for expensive real-world annotation campaigns in autonomous driving development.
- Combining the method with existing synthetic data generators could further lower the cost of creating large labeled training sets.
Load-bearing premise
A coarse semantic prior taken from unlabeled real-world references can be refined during denoising to keep style injection consistent with object classes and free of misalignment.
What would settle it
If the adapted images show visible class mixing or if models trained on them show no accuracy gain on real driving benchmarks relative to symmetric baselines or unadapted synthetic data.
Figures



read the original abstract
Synthetic data mitigates the data scarcity problem in autonomous driving perception. However, the synthetic-to-real gap leads to performance degradation, hindering real-world model generalization. Although current methods leverage diffusion models for photorealistic style transfer to bridge this gap, they critically ignore a practical asymmetry: while synthetic data possesses perfect pixel-level annotations, real-world style reference images generally lack corresponding labels. Consequently, existing methods relying on symmetric semantic guidance suffer from either prohibitive annotation costs or severe semantic misalignment. To address this dilemma, we formally propose a novel task: Asymmetric Style Transfer for Autonomous Driving (ASTAD), which requires semantically consistent transfer using only labeled synthetic content and unlabeled real-world references. We further introduce the ASTModel, a training-free two-stage framework designed to bridge this domain gap under asymmetric constraints. ASTModel first extracts a coarse semantic prior from the unlabeled target, followed by dynamic prior refinement and class-consistent style injection during the denoising process. Extensive experiments demonstrate that ASTModel significantly outperforms existing methods in downstream perception utility and structural fidelity, while offering a 3.2$\times$ inference speedup. This work aligns synthetic-to-real adaptation with practical constraints, holding the potential to accelerate the scalable deployment of robust autonomous driving systems. Code: https://github.com/Dingyi-Yao/ASTAD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript defines the ASTAD task for semantically consistent style transfer from labeled synthetic images to unlabeled real-world references in autonomous driving perception. It proposes ASTModel, a training-free two-stage diffusion framework that first extracts a coarse semantic prior from the unlabeled target domain and then performs dynamic prior refinement with class-consistent style injection during denoising. Experiments are reported to show gains in downstream perception utility and structural fidelity over prior methods, together with a 3.2× inference speedup.
Significance. If the central claims hold, the work is significant because it directly tackles the practical asymmetry of annotation availability that limits most existing symmetric semantic-guidance approaches in synthetic-to-real adaptation. The training-free design and reported speedup are concrete strengths that could improve deployability. The public code link is a positive factor for reproducibility.
major comments (2)
- [Method section (likely §3)] The central claim of class-consistent style injection without semantic misalignment rests on the dynamic refinement step during denoising. The manuscript provides no equations, pseudocode, or ablation results specifying how the coarse prior (extracted from unlabeled references) is updated across timesteps, what attention or logit mechanism is used, or which loss/regularizer prevents class drift. This mechanism is load-bearing for the reported downstream gains; without it, the outperformance could be attributable to the base diffusion model rather than the proposed asymmetry handling.
- [Experiments / Results] Table or figure reporting the 3.2× speedup and perception-utility metrics must include the exact inference settings, hardware, and comparison baselines (including whether the baselines also use the same diffusion backbone). The abstract claim is strong, but the absence of these controls in the visible description makes it impossible to verify that the speedup is not an artifact of implementation differences.
minor comments (1)
- [Abstract] The abstract states that ASTModel 'significantly outperforms existing methods' but does not name the specific baselines or report effect sizes; this should be clarified in the introduction or results summary.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which help us strengthen the clarity and reproducibility of the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Method section (likely §3)] The central claim of class-consistent style injection without semantic misalignment rests on the dynamic refinement step during denoising. The manuscript provides no equations, pseudocode, or ablation results specifying how the coarse prior (extracted from unlabeled references) is updated across timesteps, what attention or logit mechanism is used, or which loss/regularizer prevents class drift. This mechanism is load-bearing for the reported downstream gains; without it, the outperformance could be attributable to the base diffusion model rather than the proposed asymmetry handling.
Authors: We agree that the dynamic prior refinement mechanism is central to the ASTAD framework and that its description requires greater technical specificity. In the revised manuscript we will add (i) the full set of equations governing the timestep-wise update of the coarse semantic prior, (ii) pseudocode for the class-consistent attention and logit-based refinement steps, and (iii) an ablation study isolating the contribution of the refinement module. These additions will make explicit how semantic drift is prevented and will demonstrate that the reported gains arise from the proposed asymmetry handling rather than the base diffusion model alone. revision: yes
-
Referee: [Experiments / Results] Table or figure reporting the 3.2× speedup and perception-utility metrics must include the exact inference settings, hardware, and comparison baselines (including whether the baselines also use the same diffusion backbone). The abstract claim is strong, but the absence of these controls in the visible description makes it impossible to verify that the speedup is not an artifact of implementation differences.
Authors: We concur that precise experimental controls are necessary to substantiate the speedup claim. The revised manuscript will include an expanded table (or supplementary table) that reports: exact inference settings (denoising steps, scheduler, batch size), hardware platform (GPU model and memory), and confirmation that all diffusion-based baselines share the identical backbone and implementation environment. This will allow direct verification that the 3.2× factor is not due to implementation discrepancies. revision: yes
Circularity Check
No circularity detected; derivation self-contained
full rationale
The paper describes a training-free two-stage ASTModel that extracts a coarse semantic prior from unlabeled real references then performs dynamic refinement during diffusion denoising. No equations, fitted parameters, or self-citations are presented in the abstract or described process that reduce any claimed prediction or result to the inputs by construction. The central claims rest on the proposed mechanism's empirical performance rather than definitional equivalence or load-bearing self-reference. This is the normal case of an independent method proposal without the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: ACM SIGGRAPH 2024 conference papers
Alaluf, Y., Garibi, D., Patashnik, O., Averbuch-Elor, H., Cohen-Or, D.: Cross- image attention for zero-shot appearance transfer. In: ACM SIGGRAPH 2024 conference papers. pp. 1–12 (2024)
2024
-
[2]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
An, J., Huang, S., Song, Y., Dou, D., Liu, W., Luo, J.: Artflow: Unbiased im- age style transfer via reversible neural flows. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 862–871 (2021)
2021
-
[3]
In: Proceedings of the IEEE/CVF international conference on computer vision
Cheng, B., Liu, Z., Peng, Y., Lin, Y.: General image-to-image translation with one- shot image guidance. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 22736–22746 (2023)
2023
-
[4]
IEEE Transactions on Circuits and Systems for Video Technology (2024)
Cheng, B., Li, J., Shi, J., Fang, Y., Zhang, G., Chen, Y., Zeng, T., Li, Z.: Weafu: Weather-informed image blind restoration via multi-weather distribution diffusion. IEEE Transactions on Circuits and Systems for Video Technology (2024)
2024
-
[5]
Computer Vision and Image Un- derstanding p
Chigot, E., Wilson, D.G., Ghrib, M., Oberlin, T.: Style transfer with diffusion models for synthetic-to-real domain adaptation. Computer Vision and Image Un- derstanding p. 104445 (2025)
2025
-
[6]
In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition
Choi, Y., Choi, M., Kim, M., Ha, J.W., Kim, S., Choo, J.: Stargan: Unified gener- ative adversarial networks for multi-domain image-to-image translation. In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition. pp. 8789–8797 (2018)
2018
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Choi, Y., Uh, Y., Yoo, J., Ha, J.W.: Stargan v2: Diverse image synthesis for mul- tiple domains. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8188–8197 (2020)
2020
-
[8]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chung, J., Hyun, S., Heo, J.P.: Style injection in diffusion: A training-free approach for adapting large-scale diffusion models for style transfer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8795–8805 (2024)
2024
-
[9]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3213–3223 (2016)
2016
-
[10]
arXiv preprint arXiv:2311.16491 (2023)
Deng, Y., He, X., Tang, F., Dong, W.: Z∗: Zero-shot style transfer via attention rearrangement. arXiv preprint arXiv:2311.16491 (2023)
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deng, Y., Tang, F., Dong, W., Ma, C., Pan, X., Wang, L., Xu, C.: Stytr2: Image style transfer with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11326–11336 (2022)
2022
-
[12]
In: European Conference on Computer Vision
Frenkel, Y., Vinker, Y., Shamir, A., Cohen-Or, D.: Implicit style-content separation using b-lora. In: European Conference on Computer Vision. pp. 181–198. Springer (2024)
2024
-
[13]
IEEE Transactions on Cir- cuits and Systems for Video Technology34(7), 5641–5652 (2024)
Gao, M., Dong, Q.: Adaptive conditional denoising diffusion model with hybrid affinity regularizer for generalized zero-shot learning. IEEE Transactions on Cir- cuits and Systems for Video Technology34(7), 5641–5652 (2024)
2024
-
[14]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Gatys, L.A., Ecker, A.S., Bethge, M.: Image style transfer using convolutional neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2414–2423 (2016)
2016
-
[15]
Proceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision pp
Go, S., Choi, K., Shin, M., Uh, Y.: Eye-for-an-eye: Appearance transfer with dense semantic correspondence in diffusion models. Proceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision pp. 4641–4650 (2026) ASTAD 17
2026
-
[16]
In: International conference on machine learning
Hoffman, J., Tzeng, E., Park, T., Zhu, J.Y., Isola, P., Saenko, K., Efros, A., Dar- rell, T.: Cycada: Cycle-consistent adversarial domain adaptation. In: International conference on machine learning. pp. 1989–1998. Pmlr (2018)
1989
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hoyer, L., Dai, D., Van Gool, L.: Daformer: Improving network architectures and training strategies for domain-adaptive semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9924– 9935 (2022)
2022
-
[18]
In: Proceedings of the IEEE international conference on computer vision
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization. In: Proceedings of the IEEE international conference on computer vision. pp. 1501–1510 (2017)
2017
-
[19]
In: Proceedings of the European conference on computer vision (ECCV)
Huang, X., Liu, M.Y., Belongie, S., Kautz, J.: Multimodal unsupervised image-to- image translation. In: Proceedings of the European conference on computer vision (ECCV). pp. 172–189 (2018)
2018
-
[20]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with condi- tional adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1125–1134 (2017)
2017
-
[21]
In: European Conference on Computer Vision
Jia, Y., Hoyer, L., Huang, S., Wang, T., Van Gool, L., Schindler, K., Obukhov, A.: Dginstyle: Domain-generalizable semantic segmentation with image diffusion mod- els and stylized semantic control. In: European Conference on Computer Vision. pp. 91–109. Springer (2024)
2024
-
[22]
arXiv preprint arXiv:2209.15264 (2022)
Kwon, G., Ye, J.C.: Diffusion-based image translation using disentangled style and content representation. arXiv preprint arXiv:2209.15264 (2022)
-
[23]
In: Proceedings of the IEEE/CVF international conference on computer vision
Liu, S., Lin, T., He, D., Li, F., Wang, M., Li, X., Sun, Z., Li, Q., Ding, E.: Adaattn: Revisit attention mechanism in arbitrary neural style transfer. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 6649–6658 (2021)
2021
-
[24]
Transactions on Machine Learning Research Journal (2024)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. Transactions on Machine Learning Research Journal (2024)
2024
-
[25]
In: European conference on computer vision
Park, T., Efros, A.A., Zhang, R., Zhu, J.Y.: Contrastive learning for unpaired image-to-image translation. In: European conference on computer vision. pp. 319–
-
[26]
Advances in Neural Information Processing Systems33, 7198–7211 (2020)
Park, T., Zhu, J.Y., Wang, O., Lu, J., Shechtman, E., Efros, A., Zhang, R.: Swap- ping autoencoder for deep image manipulation. Advances in Neural Information Processing Systems33, 7198–7211 (2020)
2020
-
[27]
In: European conference on computer vision
Richter, S.R., Vineet, V., Roth, S., Koltun, V.: Playing for data: Ground truth from computer games. In: European conference on computer vision. pp. 102–118. Springer (2016)
2016
-
[28]
In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. pp. 10674–10685. IEEE (2022)
2022
-
[29]
In: International Conference on Medical image computing and computer-assisted intervention
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedi- cal image segmentation. In: International Conference on Medical image computing and computer-assisted intervention. pp. 234–241. Springer (2015)
2015
-
[30]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[31]
IEEE Transactions on Intelligent Vehicles9(1), 1847–1864 (2023) 18 D.Yao et al
Song, Z., He, Z., Li, X., Ma, Q., Ming, R., Mao, Z., Pei, H., Peng, L., Hu, J., Yao, D., et al.: Synthetic datasets for autonomous driving: A survey. IEEE Transactions on Intelligent Vehicles9(1), 1847–1864 (2023) 18 D.Yao et al
2023
-
[32]
arXiv preprint arXiv:2509.11273 (2025)
Song, Z., Yao, D., Ming, R., Peng, L., Yao, D., Zhang, Y.: Synthetic dataset evalua- tion based on generalized cross validation. arXiv preprint arXiv:2509.11273 (2025)
-
[33]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Tumanyan, N., Bar-Tal, O., Bagon, S., Dekel, T.: Splicing vit features for semantic appearance transfer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10748–10757 (2022)
2022
-
[34]
In: International Conference on Intelligent Computing
Wang, Z., Gao, H.a., Zhang, G., Zhao, H.: Weather-diff: Towards arbitrary adver- sarial weather generation with diffusion models. In: International Conference on Intelligent Computing. pp. 134–145. Springer (2025)
2025
-
[35]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wang, Z., Zhao, L., Xing, W.: Stylediffusion: Controllable disentangled style trans- fer via diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 7677–7689 (2023)
2023
-
[36]
Advances in neural information processing systems34, 12077–12090 (2021)
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J.M., Luo, P.: Segformer: Simple and efficient design for semantic segmentation with transformers. Advances in neural information processing systems34, 12077–12090 (2021)
2021
-
[37]
Yan, Q., Hu, T., Sun, Y., Tang, H., Zhu, Y., Dong, W., Van Gool, L., Zhang, Y.: Towardhigh-qualityhdrdeghostingwithconditionaldiffusionmodels.IEEETrans- actions on Circuits and Systems for Video Technology34(5), 4011–4026 (2023)
2023
-
[38]
Yan, Q., Hu, T., Wu, P., Dai, D., Gu, S., Dong, W., Zhang, Y.: Efficient image enhancementwithadiffusion-basedfrequencyprior.IEEETransactionsonCircuits and Systems for Video Technology (2025)
2025
-
[39]
arXiv preprint arXiv:2510.10203 (2025)
Yao, D., Han, X., Ming, R., Song, Z., Peng, L., Hu, J., Yao, D., Zhang, Y.: A style- based profiling framework for quantifying the synthetic-to-real gap in autonomous driving datasets. arXiv preprint arXiv:2510.10203 (2025)
-
[40]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[41]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Zhang, Y., Huang, N., Tang, F., Huang, H., Ma, C., Dong, W., Xu, C.: Inversion- based style transfer with diffusion models. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 10146–10156 (2023)
2023
-
[42]
In: European con- ference on computer vision
Zhao, Y., Zhong, Z., Zhao, N., Sebe, N., Lee, G.H.: Style-hallucinated dual consis- tency learning for domain generalized semantic segmentation. In: European con- ference on computer vision. pp. 535–552. Springer (2022)
2022
-
[43]
Advances in Neural Information Processing Systems37, 48838–48874 (2024)
Zhou, Y., Simon, M., Peng, Z., Mo, S., Zhu, H., Guo, M., Zhou, B.: Simgen: Simulator-conditioned driving scene generation. Advances in Neural Information Processing Systems37, 48838–48874 (2024)
2024
-
[44]
In: Proceedings of the IEEE interna- tional conference on computer vision
Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE interna- tional conference on computer vision. pp. 2223–2232 (2017)
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.