Exact and Deterministic Patch Descriptor Retrieval via Hierarchical Normalization
Pith reviewed 2026-06-26 05:35 UTC · model grok-4.3
The pith
Hierarchical normalization splits descriptors into major and minor parts so that major similarity plus alpha is a provably safe upper bound, enabling exact nearest-neighbor search while evaluating only 0.4 percent of the database in full.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hierarchical Normalization splits the pre-normalization feature vector into a K-dimensional major component (norm sqrt(1-alpha)) and a (128-K)-dimensional minor component (norm sqrt(alpha)). The minor inner product is therefore bounded above by alpha. The major similarity plus alpha consequently supplies a valid upper bound on the full similarity. The algorithm therefore scans every K-dimensional major vector, retains only those entries whose upper bound exceeds the current best full similarity, and performs the expensive 128-dimensional inner product solely on the retained candidates. The neighbor returned is identical to the result of exhaustive full-vector search.
What carries the argument
Hierarchical Normalization, the enforced split of each descriptor into major and minor components with prescribed Euclidean norms that lets Cauchy-Schwarz supply an upper bound on the minor inner product for pruning.
If this is right
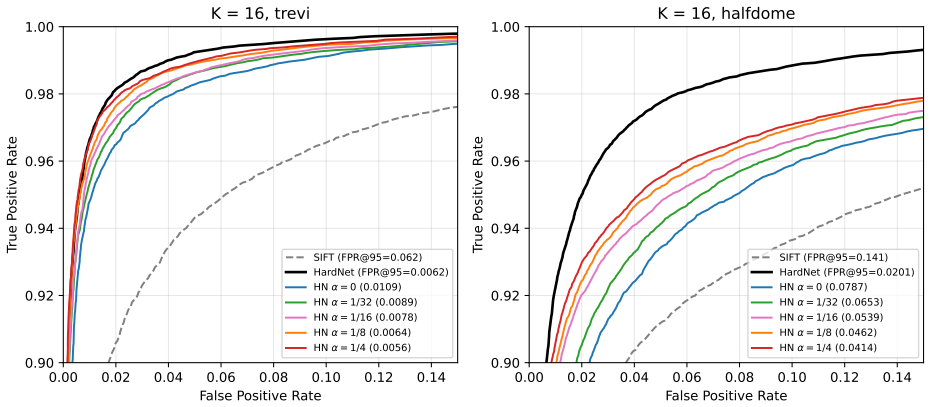
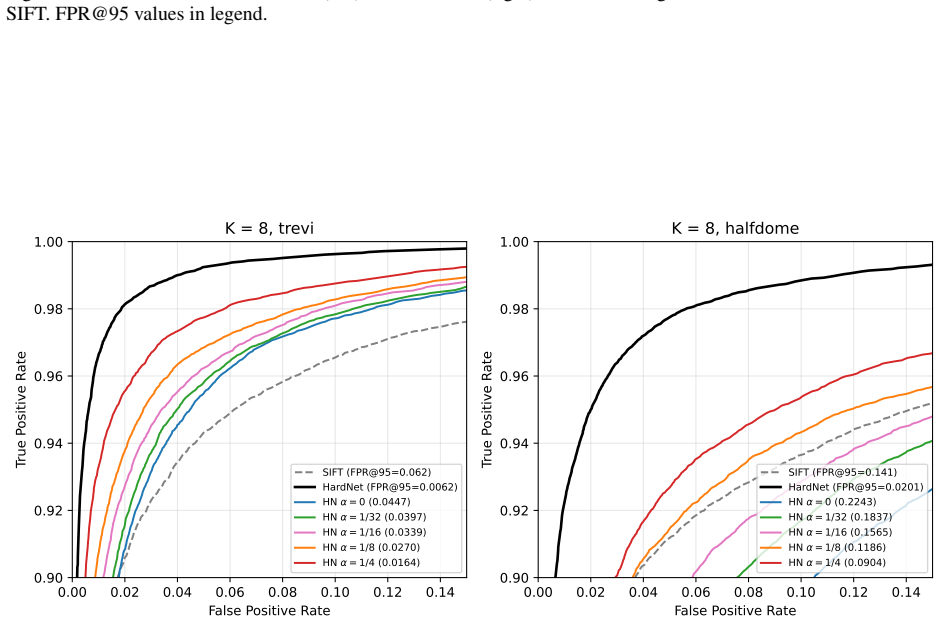
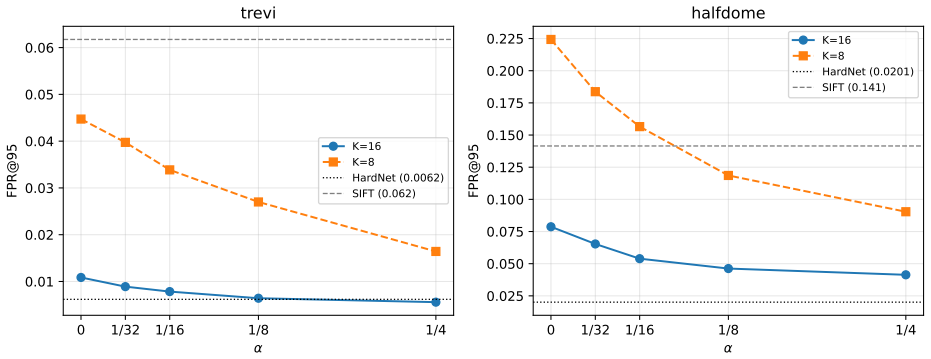
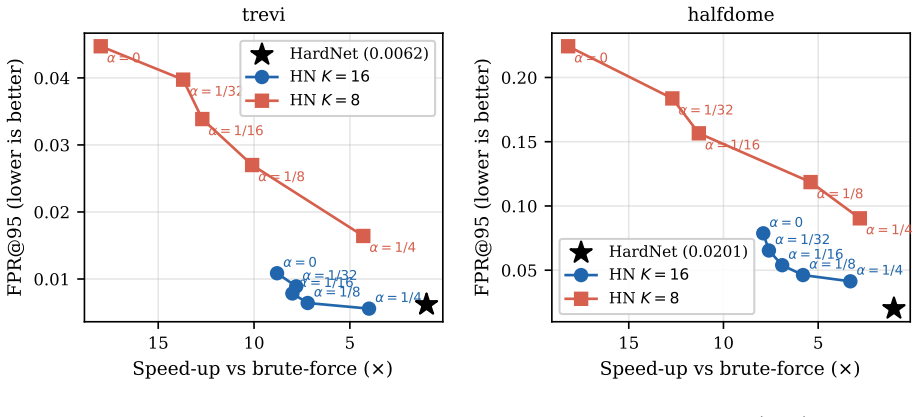
- With K=8 and alpha=1/32 the method evaluates the full vector on only 0.4 percent of entries and achieves 13.7x speedup on trevi and 12.7x on halfdome.
- At K=16 and alpha=1/8 the false-positive rate at 95 percent recall rises from 0.0062 to 0.0064 while still delivering 7.2x speedup and bypassing full evaluation for 98.8 percent of entries.
- The search is deterministic: identical (database, query) pairs always produce identical results independent of run order or hardware.
- The descriptors are obtained by training a norm-constrained variant of HardNet on the notredame split of the UBC patch dataset and evaluating on trevi and halfdome.
Where Pith is reading between the lines
- The same bounding construction could be tested on other embedding dimensions or descriptor families provided their training objective can be adapted to enforce the two separate norm targets.
- Because the procedure is both exact and deterministic it removes a source of non-reproducibility that is present in many approximate nearest-neighbor indexes.
- The fraction of entries that survive pruning depends on how concentrated the learned descriptors are in the major component; different choices of K and alpha therefore trade off scan cost against pruning rate.
- An open empirical question is whether the observed pruning rate remains high when the database contains descriptors drawn from multiple scenes rather than a single scene.
Load-bearing premise
The descriptors must be produced so that their major and minor components exactly meet the prescribed Euclidean-norm values; any deviation would invalidate the direct application of the Cauchy-Schwarz bound.
What would settle it
A single query on which the method returns a different nearest neighbor than brute-force 128-dimensional search on the same database would falsify the exactness claim.
Figures
read the original abstract
We present a patch descriptor retrieval method that returns the exact nearest neighbour -- provably identical to exhaustive full-vector search -- while evaluating only a small fraction of the database, and does so deterministically: the same (database, query) pair always produces the same result, independent of run order, thread count, or hardware. This contrasts with approximate nearest-neighbour (ANN) approaches such as HNSW and IVF-PQ, which trade exactness for speed and may return different results across runs. The enabling mechanism is Hierarchical Normalization (HN): a normalisation scheme that splits the pre-normalisation feature vector into a K-dim major component (norm sqrt(1-alpha)) and a (128-K)-dim minor component (norm sqrt(alpha)). Since the minor inner product is bounded by alpha (Cauchy-Schwarz on the prescribed norms), the major similarity plus alpha is an admissible upper bound on the full similarity: the search scans the K-dim major component for all entries, then applies full 128-dim evaluation only to entries that cannot be pruned -- a provably exact branch-and-bound scan. We train HN-modified HardNet on the notredame split of the UBC patch dataset and evaluate on trevi and halfdome. With a cache-optimised Structure-of-Arrays layout and K=8, alpha=1/32, the search achieves 13.7x (trevi) / 12.7x (halfdome) speed-up over brute-force 128-dim search, with only 0.4% of entries requiring full evaluation. At K=16, alpha=1/8, FPR@95 rises from 0.0062 to 0.0064 on trevi at 7.2x speed-up, with 98.8% of entries bypassing full evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims a method for exact, deterministic patch descriptor retrieval using Hierarchical Normalization (HN). HN splits each pre-normalization 128-dim descriptor into a K-dim major component (norm exactly sqrt(1-alpha)) and (128-K)-dim minor component (norm exactly sqrt(alpha)). By Cauchy-Schwarz the minor inner product is at most alpha, so major similarity + alpha is an admissible upper bound; a branch-and-bound scan over the K-dim major vectors prunes most entries and only evaluates the full 128-dim inner product on the remainder. The resulting search is provably identical to exhaustive search, independent of ordering or hardware. An HN-modified HardNet is trained on the notredame split of UBC and evaluated on trevi/halfdome; with K=8, alpha=1/32 the method reports 12.7-13.7x speedup over brute-force 128-dim search while evaluating only 0.4% of entries, and at K=16, alpha=1/8 the FPR@95 remains essentially unchanged (0.0062 to 0.0064) at 7.2x speedup.
Significance. If the exact-norm requirement holds, the work supplies a deterministic exact-NN baseline that is substantially faster than brute force yet never returns a different answer from exhaustive search. The mathematical construction (fixed-norm split plus admissible bound) is parameter-light once K and alpha are chosen and is supported by concrete speed-up and FPR numbers on standard patch datasets. This combination of provable exactness and practical acceleration is uncommon in the ANN literature and would be of direct use in retrieval pipelines that cannot tolerate approximation error.
major comments (1)
- [HN description and experimental setup (abstract and method)] The admissible upper bound (major similarity + alpha) is admissible only when every database descriptor and the query satisfy ||major|| = sqrt(1-alpha) and ||minor|| = sqrt(alpha) to machine precision. The manuscript states that HN rescales the two parts to these exact values, yet provides no verification (e.g., measured norm histograms, maximum deviation, or floating-point compliance) that the trained HN-modified HardNet actually produces descriptors obeying the constraints at inference time. Any systematic deviation would render the bound either invalid or non-admissible and would break the claim that no true nearest neighbor can be pruned. This verification is load-bearing for the central exactness guarantee.
Simulated Author's Rebuttal
Thank you for the careful review and for identifying the need to verify the norm constraints that underpin the exactness guarantee. We address the comment below and will revise the manuscript to include the requested verification.
read point-by-point responses
-
Referee: The admissible upper bound (major similarity + alpha) is admissible only when every database descriptor and the query satisfy ||major|| = sqrt(1-alpha) and ||minor|| = sqrt(alpha) to machine precision. The manuscript states that HN rescales the two parts to these exact values, yet provides no verification (e.g., measured norm histograms, maximum deviation, or floating-point compliance) that the trained HN-modified HardNet actually produces descriptors obeying the constraints at inference time. Any systematic deviation would render the bound either invalid or non-admissible and would break the claim that no true nearest neighbor can be pruned. This verification is load-bearing for the central exactness guarantee.
Authors: We agree that explicit empirical verification of the achieved norms is required to fully substantiate the exactness claim. The HN procedure performs an explicit rescaling of the major and minor components to the prescribed target norms after the split; in exact arithmetic this guarantees the conditions. To address floating-point effects at inference time, the revised manuscript will add a new paragraph (or short appendix) reporting measured statistics on the evaluation sets: maximum and mean absolute deviation of ||major|| from sqrt(1-alpha) and of ||minor|| from sqrt(alpha), for both database descriptors and queries. We will also include a brief histogram or quantile summary of the deviations, which we expect to be on the order of machine epsilon (≈1e-7 relative error). These measurements will confirm that the admissible bound remains valid in practice for the trained model. revision: yes
Circularity Check
No significant circularity; exactness follows from independent mathematical bound
full rationale
The derivation chain defines Hierarchical Normalization to enforce exact major/minor norms, then invokes Cauchy-Schwarz to obtain an admissible upper bound on full similarity. This bound is a direct consequence of the inner-product inequality and the prescribed norm values; it does not reduce to any fitted parameter, self-citation, or redefinition of the target result. The branch-and-bound procedure inherits exactness from the bound's admissibility, which holds by construction once the norms are satisfied. No load-bearing self-citation, ansatz smuggling, or renaming of known results appears. The method is self-contained against external benchmarks (the bound is parameter-free once norms are fixed).
Axiom & Free-Parameter Ledger
free parameters (2)
- K =
8 or 16
- alpha =
1/32 or 1/8
axioms (1)
- standard math Cauchy-Schwarz inequality
Reference graph
Works this paper leans on
-
[1]
Working hard to know your neighbor’s margins: Local descriptor learning loss,
A. Mishchuk, D. Mishkin, F. Radenovic, and J. Matas, “Working hard to know your neighbor’s margins: Local descriptor learning loss,” inNeurIPS, 2017
2017
-
[2]
Discriminative learning of local image descriptors,
M. Brown, G. Hua, and S. Winder, “Discriminative learning of local image descriptors,”IEEE TPAMI, vol. 33, no. 1, pp. 43–57, 2011
2011
-
[3]
Efficient and ro- bust approximate nearest neighbor search using hier- archical navigable small world graphs,
Y . A. Malkov and D. A. Yashunin, “Efficient and ro- bust approximate nearest neighbor search using hier- archical navigable small world graphs,”IEEE TPAMI, vol. 42, no. 4, pp. 824–836, 2020
2020
-
[4]
Product quan- tization for nearest neighbor search,
H. J ´egou, M. Douze, and C. Schmid, “Product quan- tization for nearest neighbor search,”IEEE TPAMI, vol. 33, no. 1, pp. 117–128, 2011
2011
-
[5]
Matryoshka representation learn- ing,
A. Kusupati et al., “Matryoshka representation learn- ing,” inNeurIPS, 2022
2022
-
[6]
Image descriptor network with improved hi- erarchical normalization,
K. Sato, “Image descriptor network with improved hi- erarchical normalization,” US Patent 11,797,603 B2, granted Oct. 24, 2023. Filed Jun. 24, 2020
2023
-
[7]
Distinctive image features from scale- invariant keypoints,
D. G. Lowe, “Distinctive image features from scale- invariant keypoints,”IJCV, vol. 60, no. 2, pp. 91–110, 2004
2004
-
[8]
ORB: An efficient alternative to SIFT or SURF,
E. Rublee, V . Rabaud, K. Konolige, and G. Bradski, “ORB: An efficient alternative to SIFT or SURF,” in ICCV, 2011
2011
-
[9]
Billion-scale similarity search with GPUs,
J. Johnson, M. Douze, and H. J ´egou, “Billion-scale similarity search with GPUs,”IEEE Trans. Big Data, vol. 7, no. 3, pp. 535–547, 2021
2021
-
[10]
Supervised hashing with kernels,
W. Liu, J. Wang, R. Ji, Y .-G. Jiang, and S.-F. Chang, “Supervised hashing with kernels,” inCVPR, 2012
2012
-
[11]
Accelerating large-scale inference with anisotropic vector quantization,
R. Guo et al., “Accelerating large-scale inference with anisotropic vector quantization,” inICML, 2020
2020
-
[12]
DiskANN: Fast accurate billion-point nearest neighbor search on a single node,
S. Jayaram Subramanya, F. Devvrit, H. V . Simhadri, R. Krishnaswamy, and R. Kadekodi, “DiskANN: Fast accurate billion-point nearest neighbor search on a single node,” inNeurIPS, 2019
2019
-
[13]
Practical and optimal LSH for an- gular distance,
A. Andoni, P. Indyk, T. Laarhoven, I. Razenshteyn, and L. Schmidt, “Practical and optimal LSH for an- gular distance,” inNeurIPS, 2015. 9
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.