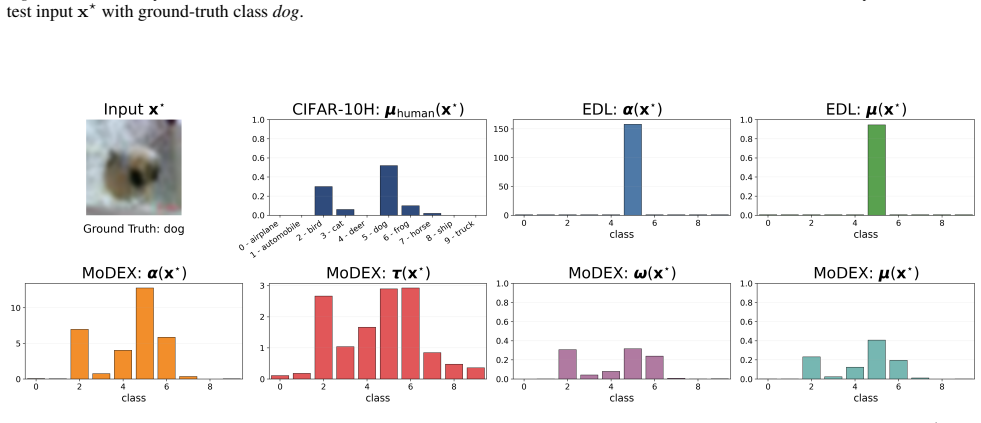
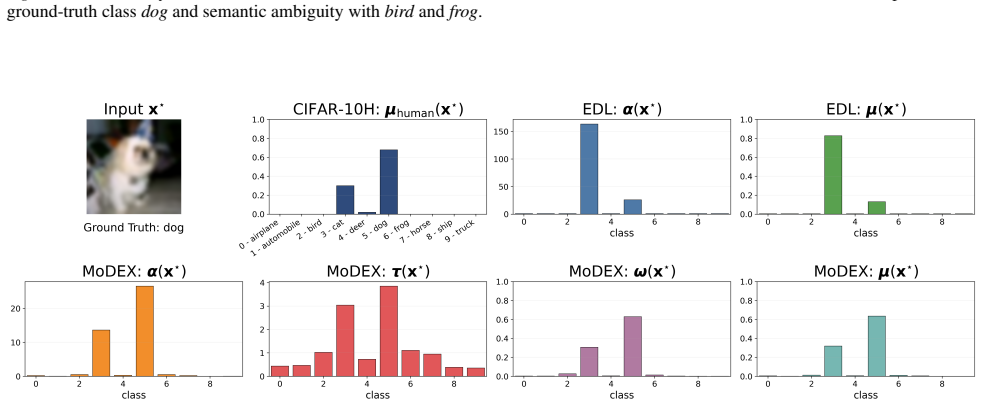
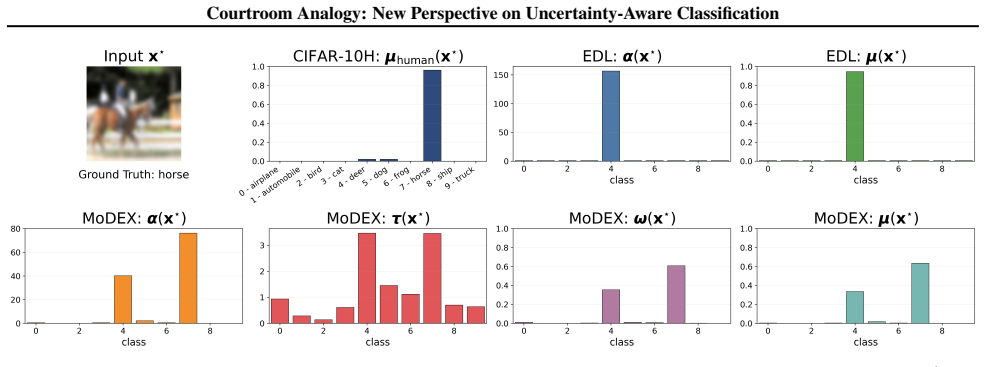
Courtroom Analogy: New Perspective on Uncertainty-Aware Classification
Pith reviewed 2026-06-29 23:03 UTC · model grok-4.3
The pith
Uncertainty-aware classification can be viewed as a debate among class-specific advocates whose opinions are aggregated by input-dependent plausibility weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce the courtroom analogy, which conceptualizes uncertainty-aware classification as a structured debate among class-specific advocates. Each advocate forms a probabilistic opinion, and a final verdict is reached by aggregating these opinions using input-dependent plausibility weights. In this framework, each advocate's opinion is modeled as a Dirichlet distribution whose concentration parameter is decomposed into shared evidence and class-specific advocacy. This yields a structured mixture of Dirichlet distributions with semantically interpretable parameters. To instantiate this formulation, we propose Mixture of Dirichlet EXperts (MoDEX), a single-pass neural architecture that pred
What carries the argument
The courtroom analogy, which treats each class as an advocate whose Dirichlet opinion is decomposed into shared evidence and class-specific advocacy before aggregation by input-dependent plausibility weights.
If this is right
- MoDEX supplies a single-pass neural network that outputs the full set of courtroom parameters for efficient uncertainty quantification.
- The resulting uncertainty estimates carry explicit semantic roles for shared evidence versus per-class advocacy.
- The model attains state-of-the-art performance on diverse classification benchmarks for uncertainty quantification.
- The formulation admits strong theoretical properties tied to the mixture-of-Dirichlets structure.
- Uncertainty aggregation is made explicit through the plausibility weights rather than remaining implicit inside the network.
Where Pith is reading between the lines
- Examining the plausibility weights at inference time could reveal which classes are actively competing for the final verdict on a given input.
- The same decomposition might be tested on tasks with label hierarchies, where advocates for parent and child classes interact through the shared evidence term.
- If the advocacy components prove stable across datasets, they could serve as a lightweight way to transfer uncertainty structure between related classification problems.
Load-bearing premise
That splitting Dirichlet concentration parameters into shared evidence and class-specific advocacy components, then weighting the resulting opinions by input plausibility, produces both better uncertainty estimates and genuinely meaningful parameter interpretations rather than simply renaming standard Dirichlet outputs.
What would settle it
Training MoDEX on the same benchmarks used for prior Dirichlet-based UQ methods and observing no gain in standard uncertainty metrics such as expected calibration error or negative log-likelihood, or finding that the learned advocacy and evidence parameters show no consistent alignment with intuitive class evidence patterns on held-out examples.
Figures
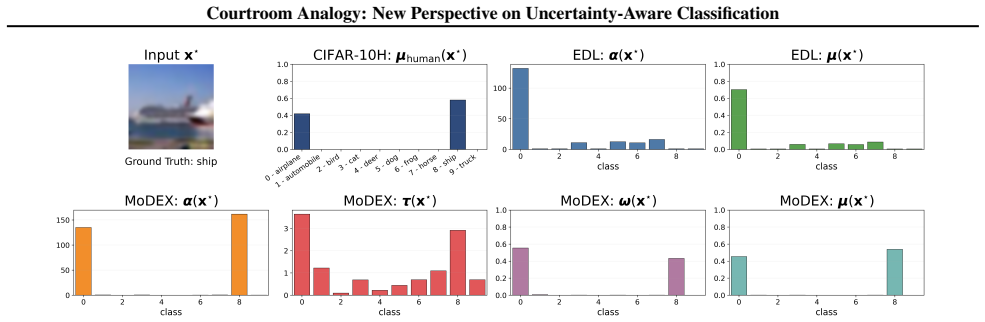
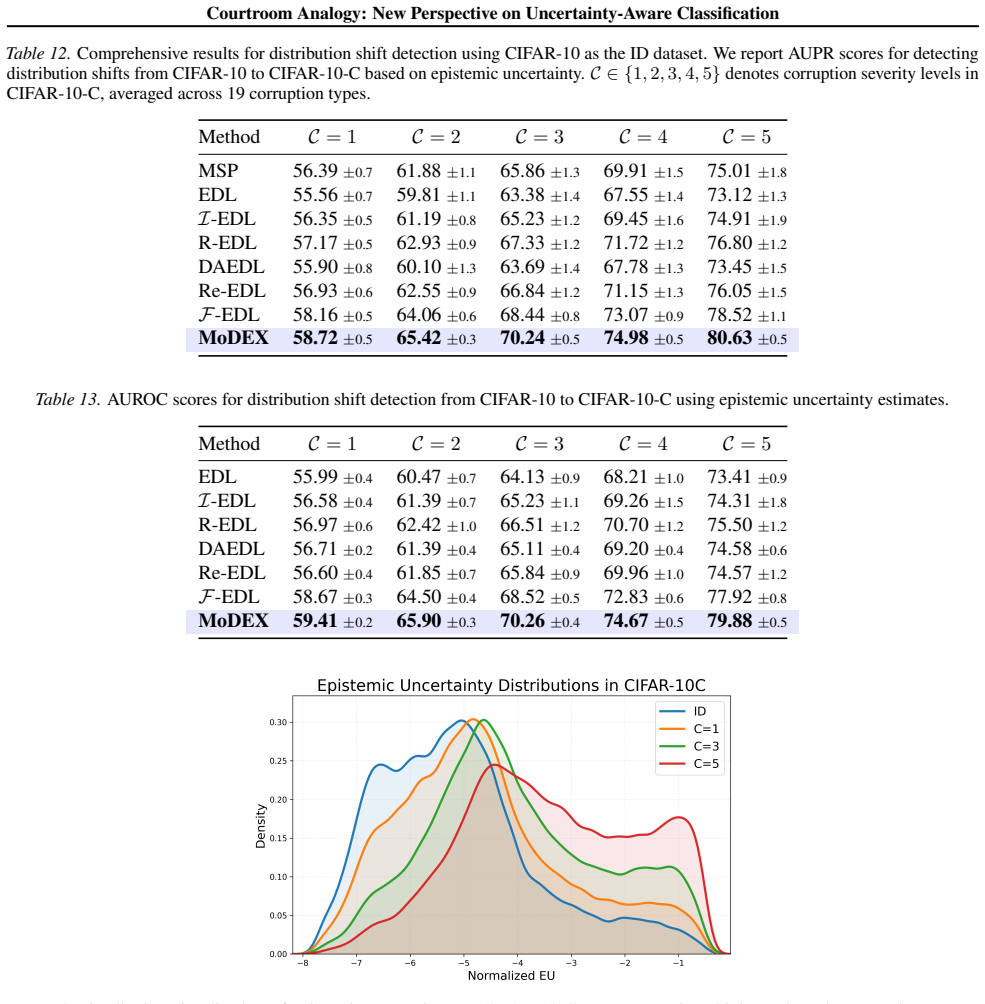
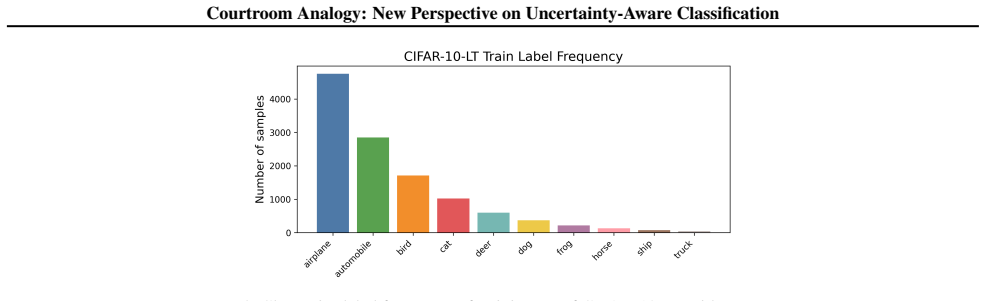
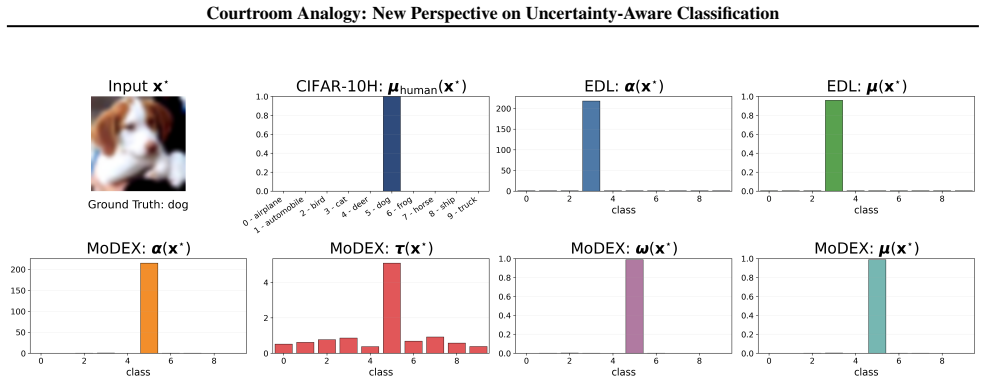
read the original abstract
Single-pass uncertainty quantification (UQ) methods for classification represent uncertainty by predicting a tractable distribution over the class probability vector. While existing approaches primarily focus on enhancing the expressiveness of this distribution, they often provide limited insight into how predictive uncertainty is structured and aggregated, resulting in weak interpretability. We introduce the courtroom analogy, which conceptualizes uncertainty-aware classification as a structured debate among class-specific advocates. Each advocate forms a probabilistic opinion, and a final verdict is reached by aggregating these opinions using input-dependent plausibility weights. In this framework, each advocate's opinion is modeled as a Dirichlet distribution whose concentration parameter is decomposed into shared evidence and class-specific advocacy. This yields a structured mixture of Dirichlet distributions with semantically interpretable parameters. To instantiate this formulation, we propose Mixture of Dirichlet EXperts (MoDEX), a single-pass neural architecture that predicts the courtroom parameters, enabling efficient and expressive UQ while explicitly modeling uncertainty aggregation. We demonstrate that MoDEX enjoys strong theoretical properties and achieves state-of-the-art UQ performance across diverse benchmarks, yielding interpretable uncertainty estimates with meaningful semantics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a 'courtroom analogy' for single-pass uncertainty-aware classification, modeling the task as a debate among class-specific advocates. Each advocate outputs a Dirichlet distribution whose concentration is decomposed into shared evidence and class-specific advocacy; these opinions are aggregated via input-dependent plausibility weights to produce a structured mixture of Dirichlets. The authors instantiate this as the MoDEX neural architecture and claim it possesses strong theoretical properties while achieving state-of-the-art UQ performance on diverse benchmarks together with semantically meaningful, interpretable uncertainty estimates.
Significance. If the decomposition truly yields parameters whose semantics cannot be recovered from a conventional Dirichlet network and if the reported performance gains are robust, the framework would supply a structured, interpretable account of how uncertainty is aggregated that goes beyond existing Dirichlet-based UQ methods.
major comments (2)
- [Abstract] Abstract: the central claim that the courtroom decomposition produces both SOTA UQ performance and genuinely interpretable semantics (distinct from reparameterized standard Dirichlet outputs) cannot be evaluated, because the abstract supplies no equations, derivations, ablation studies, or quantitative results.
- [Abstract] Abstract: without an explicit derivation or proof, it is impossible to determine whether the claimed mixture of Dirichlets is equivalent (up to reparameterization) to an ordinary Dirichlet whose concentration vector is simply split and re-weighted by learned coefficients; this directly affects the interpretability and novelty assertions.
Simulated Author's Rebuttal
We thank the referee for these comments on the abstract. The abstract is intentionally high-level to convey the core idea; all derivations, proofs of non-equivalence to standard Dirichlet models, and quantitative results appear in the main text. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the courtroom decomposition produces both SOTA UQ performance and genuinely interpretable semantics (distinct from reparameterized standard Dirichlet outputs) cannot be evaluated, because the abstract supplies no equations, derivations, ablation studies, or quantitative results.
Authors: Abstracts are designed to be concise overviews rather than technical expositions. The courtroom decomposition, the explicit concentration split into shared evidence and class-specific advocacy, the resulting mixture of Dirichlets, all theoretical properties, ablation studies, and benchmark results (including SOTA UQ metrics) are fully derived and reported in Sections 3–5. Readers are expected to consult the body for evaluation of the claims. revision: no
-
Referee: [Abstract] Abstract: without an explicit derivation or proof, it is impossible to determine whether the claimed mixture of Dirichlets is equivalent (up to reparameterization) to an ordinary Dirichlet whose concentration vector is simply split and re-weighted by learned coefficients; this directly affects the interpretability and novelty assertions.
Authors: Section 3.2 derives the decomposition: each advocate’s concentration α_k = α_shared + α_advocacy_k, with input-dependent plausibility weights w(x) used to form the aggregated opinion as a structured mixture Σ w_k Dir(α_k). This is not equivalent to a single Dirichlet whose parameters are merely re-weighted, because the per-advocate decomposition and the mixture structure preserve distinct semantic roles (shared evidence vs. class-specific advocacy) that cannot be recovered from a conventional Dirichlet output. The manuscript therefore maintains the claimed interpretability and novelty; a short clarifying sentence could be added to the abstract if the editor prefers. revision: partial
Circularity Check
No circularity: modeling choice presented as independent framework
full rationale
The provided abstract and text introduce the courtroom analogy and MoDEX as a new conceptual decomposition of Dirichlet concentration parameters into shared evidence plus class-specific advocacy, aggregated by input-dependent weights. No equations, derivations, or self-citations are quoted that would allow any quantity to be shown reducing to its own inputs by construction. The interpretability and performance claims are asserted as consequences of the proposed architecture rather than tautological reparameterizations or fitted inputs renamed as predictions. The derivation chain is therefore self-contained as a modeling perspective on existing Dirichlet-based UQ methods.
Axiom & Free-Parameter Ledger
invented entities (2)
-
class-specific advocates
no independent evidence
-
input-dependent plausibility weights
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Courtroom Analogy: New Perspective on Uncertainty-Aware Classification
PMLR, 2020. Krizhevsky, A., Hinton, G., et al. Learning multiple layers of features from tiny images. 2009. 10 Courtroom Analogy: New Perspective on Uncertainty-Aware Classification Lakshminarayanan, B., Pritzel, A., and Blundell, C. Simple and scalable predictive uncertainty estimation using deep ensembles.Advances in neural information processing system...
-
[2]
Further reduction to EDL.Assume additionally thatτ(x ⋆) = 1andω(x ⋆) =α(x ⋆)/∥α(x⋆)∥1
distribution. Further reduction to EDL.Assume additionally thatτ(x ⋆) = 1andω(x ⋆) =α(x ⋆)/∥α(x⋆)∥1. By Theorem 4.3 of the Yoon & Kim (2026) and its proof, substituting these conditions into theF-EDL predictive distribution yields: ˆp(π⋆ |x ⋆) = Dir(π⋆ |α(x ⋆)) = ˆpEDL(π⋆ |x ⋆). This completes the proof. D.2. Proof of Theorem 5.2 Proof. We show that the p...
2026
-
[3]
Fix- ω” fixes ω(x⋆) to a uniform vector, i.e., ω(x⋆) =1/K; “Fix-τ
as the backbone architecture when CIFAR-10 or CIFAR-10-LT serves as the ID dataset. For CIFAR-100, we adopt ResNet-18 (He et al., 2016) as the backbone. For DMNIST-LT, we employ a straightforward convolutional neural network (ConvNet) consisting of three convolutional layers followed by three fully connected layers. MLP Heads.We implement the MLP heads as...
2016
-
[4]
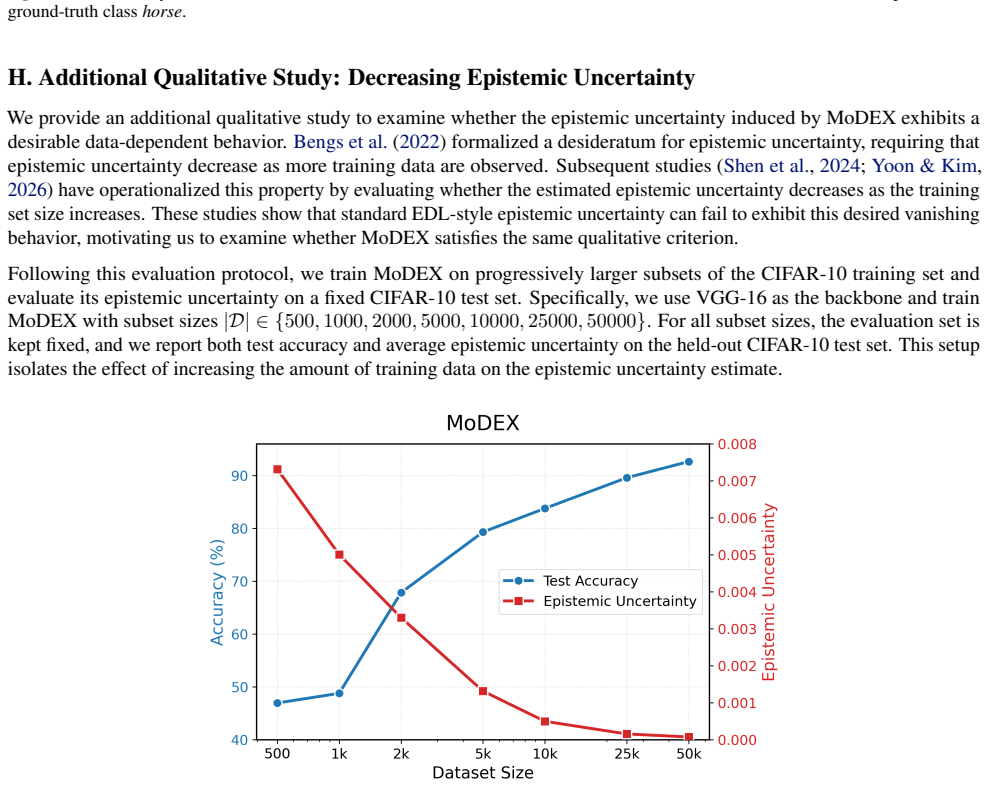
have operationalized this property by evaluating whether the estimated epistemic uncertainty decreases as the training set size increases. These studies show that standard EDL-style epistemic uncertainty can fail to exhibit this desired vanishing behavior, motivating us to examine whether MoDEX satisfies the same qualitative criterion. Following this eval...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.