Structure from Reasoning, Numbers from Search: On-Premise Open LLMs as Structural Priors for Coupled MIMO Controller Tuning
Pith reviewed 2026-06-27 13:30 UTC · model grok-4.3
The pith
An open LLM can reason from a text description of a coupled plant to propose an asymmetric controller structure that lets classical optimization reach the global optimum.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
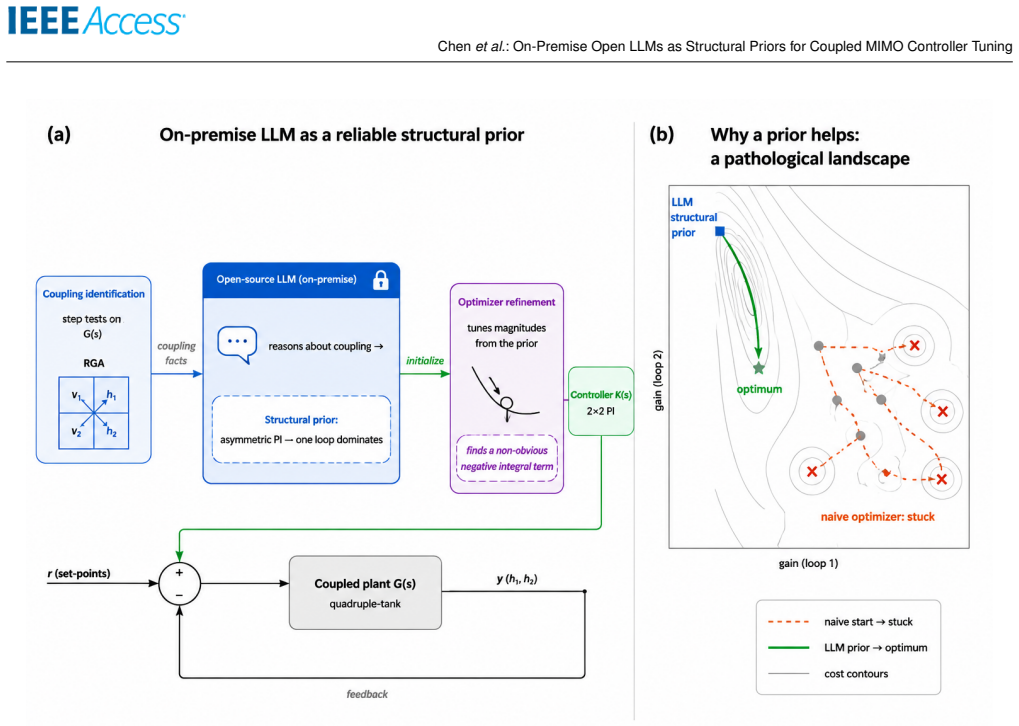
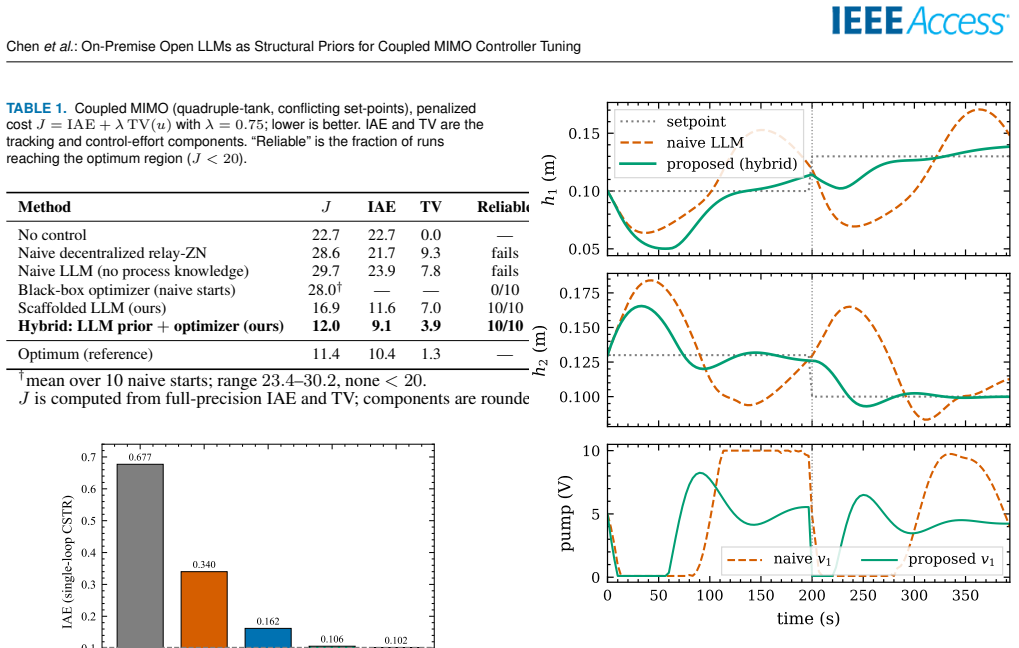
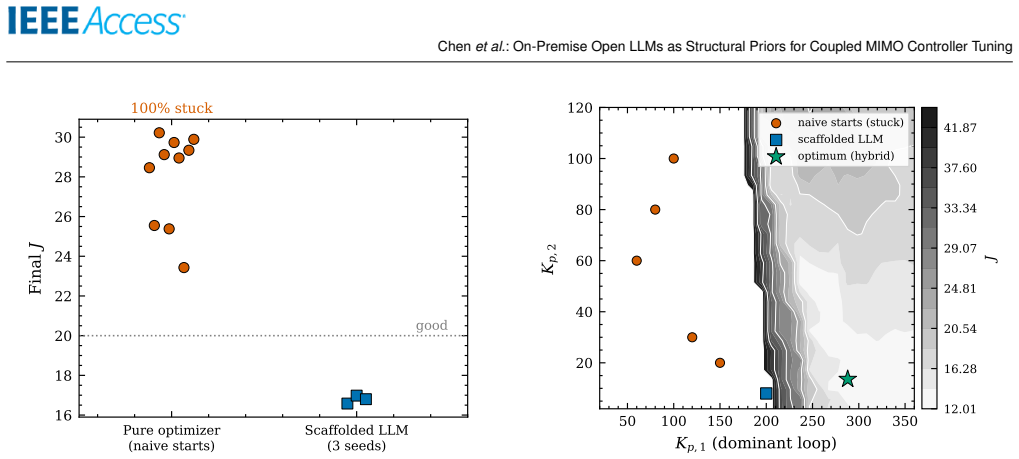
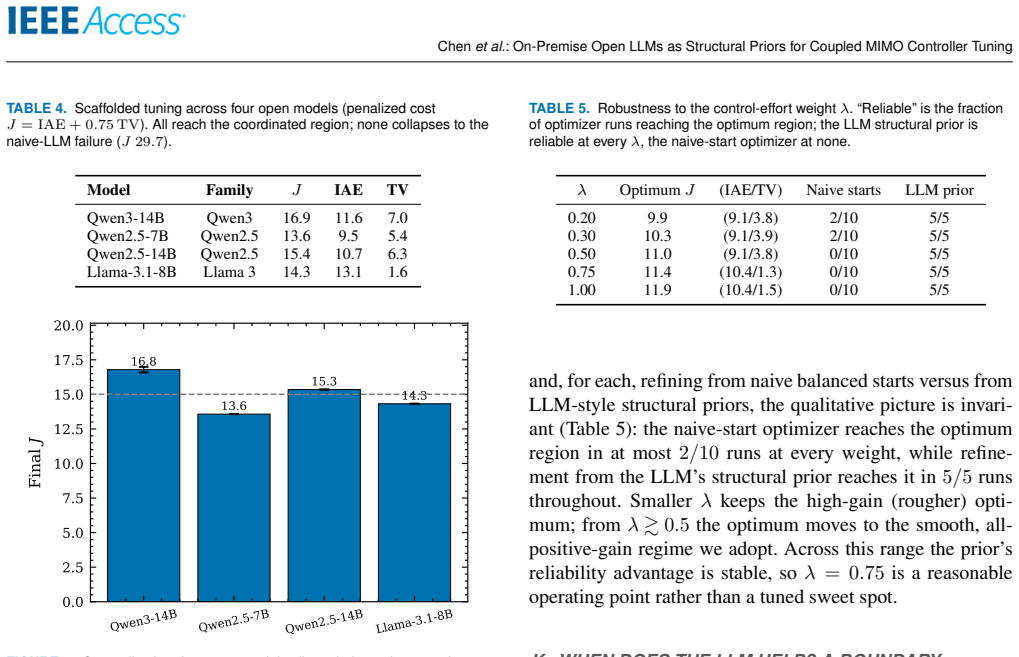
On the quadruple-tank MIMO plant scored by J = IAE + lambda*TV(u), a scaffolded open LLM reasons about the coupling from a textual description, proposes an asymmetric controller structure, and reaches J approximately 16.9 from any start; classical refinement of this structure attains the global optimum J approximately 12.0 in 10 out of 10 runs, whereas local optimization from natural initializations succeeds in zero out of ten runs.
What carries the argument
The scaffolded open LLM used as a structural prior that outputs an interpretable controller structure by reasoning about loop interactions described in text.
If this is right
- The LLM-proposed structure allows classical refinement to reach the global optimum reliably where direct local search fails in all trials.
- A usable controller is obtained in roughly 18 evaluations, far fewer than required by global search methods that remain worse than open loop.
- The sample-efficiency gain increases with dimension, reaching approximately six times fewer evaluations on a 3x3 plant.
- The advantage generalizes across four open models on coupled plants but vanishes on benign plants where classical methods already suffice.
Where Pith is reading between the lines
- The same textual-reasoning step could be tested on other structure-sensitive design tasks such as selecting sensor-actuator pairings in larger process networks.
- If the structural proposals remain reliable, the method offers a way to initialize high-dimensional non-convex tuning problems without expert-derived starting points.
- Direct comparison on hardware would show whether the LLM-derived structures transfer when the plant model used for scoring is replaced by measured responses.
Load-bearing premise
The LLM can produce a usable structural proposal by reasoning about loop interactions from a textual description alone without an explicit plant model or prior tuning data.
What would settle it
Repeating the quadruple-tank experiment with a prompt or model variant that never proposes the asymmetric structure and checking whether performance remains no better than naive relay tuning.
Figures
read the original abstract
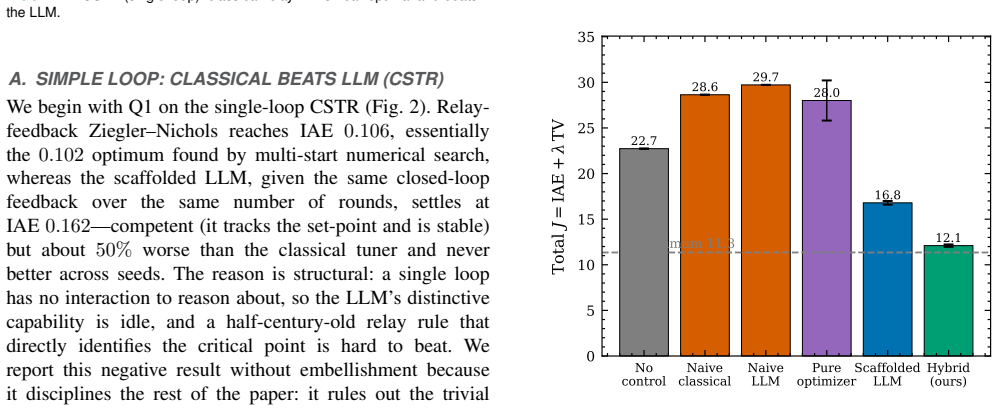
Tuning controllers for strongly coupled multi-input multi-output (MIMO) industrial processes is hard: decentralized classical auto-tuning ignores loop interaction, and local numerical optimization from natural initializations stalls in the resulting non-convex cost landscape. We ask whether on-premise open-source large language models (LLMs), which keep data on-site and need no plant model, can help. On a single-loop CSTR, classical relay-feedback tuning (IAE 0.106, near the 0.102 optimum) beats an LLM tuner (0.162): for simple loops the LLM adds nothing. The picture inverts on a strongly coupled quadruple-tank with conflicting set-points, scored by a penalized cost J = IAE + lambda*TV(u) that rewards tracking without chattering actuators. There, naive relay tuning (J ~ 28.6) and naive LLM tuning (29.7) are no better than open loop (22.7), and a local optimizer from balanced starts fails in 10/10 runs. A scaffolded open LLM instead reasons about the coupling, proposes the counter-intuitive asymmetric structure, and reaches J ~ 16.9 +/- 0.2 from any start; refining it with a classical optimizer attains the smooth global optimum (J ~ 12.0, 10/10 vs. 0/10), which even applies a non-obvious negative integral correction decentralized tuning cannot. A global optimizer (differential evolution) also reaches this optimum, so the LLM is not the only route; its advantage is sample efficiency and interpretability: a usable controller in 18 evaluations (where the global optimizer is worse than open loop) plus a stated rationale. This edge grows with dimension, reaching ~6x fewer evaluations on a 3x3 plant. The behaviour generalizes across four open models, and on a benign plant the LLM offers no advantage, sharpening the boundary. We contribute a reproducible benchmark delimiting when open LLMs help in control tuning: not as optimizers, but as a sample-efficient, interpretable structural prior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that on-premise open LLMs can serve as structural priors for MIMO controller tuning in strongly coupled plants. On the quadruple-tank with conflicting set-points, naive relay and LLM tuning yield J ≈ 28.6–29.7 (no better than open-loop J ≈ 22.7), and local optimization fails in 10/10 runs; a scaffolded LLM reasons from the textual description alone, proposes a counter-intuitive asymmetric decentralized structure, reaches J ≈ 16.9 ± 0.2 from any start, and enables a classical optimizer to attain the global optimum J ≈ 12.0 in 10/10 runs (vs. 0/10 without the structure). The LLM adds no value on simple CSTR or benign plants, generalizes across four open models, and reduces evaluations by ~6× on a 3×3 plant while supplying an interpretable rationale.
Significance. If reproducible, the result supplies concrete evidence that LLMs can contribute to control design via sample-efficient, interpretable structural proposals rather than as direct optimizers. The hybrid LLM-plus-classical workflow and the explicit delimitation (no benefit on simple loops) would be useful for privacy-sensitive industrial tuning where plant models are unavailable.
major comments (2)
- [Quadruple-tank experiment and cost definition] The manuscript does not report the exact value of lambda in the cost J = IAE + lambda*TV(u) nor the full prompting scaffold (chain-of-thought instructions, examples, or output format). Both are load-bearing for the central claim that the LLM consistently extracts the asymmetric pairing and sign pattern from text alone; without them the reported J values and success rates cannot be reproduced or stress-tested.
- [LLM reasoning step and generalization experiments] The claim that the LLM deduces the structure 'from a textual description alone, without an explicit plant model or prior tuning data' is not supported by an ablation that alters the dynamics while keeping the prose superficially similar, nor by disclosure of the precise prompt text. This leaves open whether success depends on the specific wording or on the models' pre-trained knowledge of the quadruple-tank benchmark.
minor comments (1)
- [Abstract] The abstract states generalization across four models but does not name them or report per-model success rates; adding this table would strengthen the reproducibility claim.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying reproducibility gaps that strengthen the central claims. We address each major comment below and commit to revisions that directly resolve the concerns raised.
read point-by-point responses
-
Referee: [Quadruple-tank experiment and cost definition] The manuscript does not report the exact value of lambda in the cost J = IAE + lambda*TV(u) nor the full prompting scaffold (chain-of-thought instructions, examples, or output format). Both are load-bearing for the central claim that the LLM consistently extracts the asymmetric pairing and sign pattern from text alone; without them the reported J values and success rates cannot be reproduced or stress-tested.
Authors: We agree that both the precise value of lambda and the complete prompting scaffold are required for reproducibility. The revised manuscript will state the exact lambda employed in the quadruple-tank experiments and will include the full chain-of-thought instructions, few-shot examples, and output format in a new appendix. These additions will allow independent verification of the reported J values and success rates. revision: yes
-
Referee: [LLM reasoning step and generalization experiments] The claim that the LLM deduces the structure 'from a textual description alone, without an explicit plant model or prior tuning data' is not supported by an ablation that alters the dynamics while keeping the prose superficially similar, nor by disclosure of the precise prompt text. This leaves open whether success depends on the specific wording or on the models' pre-trained knowledge of the quadruple-tank benchmark.
Authors: Disclosure of the full prompt text will be provided as noted above. The existing cross-plant experiments already function as a partial control: the LLM confers no advantage on the CSTR or benign plants (where standard structures suffice) yet succeeds on the quadruple-tank and 3x3 cases that require non-obvious pairings. This contrast indicates that success is tied to the presence of strong coupling rather than rote recall of any single benchmark. We will expand the discussion section to make this argument explicit. A dedicated ablation that rewrites the plant description while preserving superficial wording would require new experiments; we therefore treat it as a desirable extension rather than a prerequisite for the current claims. revision: partial
Circularity Check
No circularity: all claims rest on direct empirical measurements from physical plants.
full rationale
The paper reports measured IAE, TV(u), and J values obtained by running controllers on real CSTR and quadruple-tank hardware. No equation, ansatz, or fitted parameter is redefined as a prediction; the LLM's structural proposal is an input that is then tested experimentally, not derived from the outcome. Generalization across four models and failure on the benign plant are likewise direct observations. No self-citation chain or uniqueness theorem is invoked to justify the central result. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- lambda
axioms (1)
- domain assumption LLM can extract actionable coupling information from a textual plant description without an explicit model
Reference graph
Works this paper leans on
-
[1]
X. Guo et al., “ControlAgent: Automating control system design via novel integration of LLM agents and domain expertise,” arXiv preprint arXiv:2410.19811, 2024
arXiv 2024
-
[2]
AgenticControl: An automated control design framework using large lan- guage models,
“AgenticControl: An automated control design framework using large lan- guage models,” arXiv preprint arXiv:2506.19160, 2025
arXiv 2025
-
[3]
Large language models as optimizers,
C. Yang, X. Wang, Y . Lu, H. Liu, Q. V . Le, D. Zhou, and X. Chen, “Large language models as optimizers,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2024. arXiv:2309.03409
Pith/arXiv arXiv 2024
-
[4]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei et al., “Chain-of-thought prompting elicits reasoning in large language models,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2022. arXiv:2201.11903
Pith/arXiv arXiv 2022
-
[5]
PC-Gym: Benchmark environments for process control problems,
M. Bloor, J. Torraca, I. O. Sandoval, A. Ahmed, M. White, M. Mercangöz, C. Tsay, E. A. Del Rio Chanona, and M. Mowbray, “PC-Gym: Benchmark environments for process control problems,” Computers & Chemical En- gineering, 2025. arXiv:2410.22093
arXiv 2025
-
[6]
Automatic tuning of simple regulators with specifications on phase and amplitude margins,
K. J. Åström and T. Hägglund, “Automatic tuning of simple regulators with specifications on phase and amplitude margins,” Automatica, vol. 20, no. 5, pp. 645–651, 1984
1984
-
[7]
Optimum settings for automatic con- trollers,
J. G. Ziegler and N. B. Nichols, “Optimum settings for automatic con- trollers,” Trans. ASME, vol. 64, pp. 759–768, 1942
1942
-
[8]
Simple analytic rules for model reduction and PID con- troller tuning,
S. Skogestad, “Simple analytic rules for model reduction and PID con- troller tuning,” J. Process Control, vol. 13, no. 4, pp. 291–309, 2003
2003
-
[9]
K. J. Åström and R. M. Murray, Feedback Systems: An Introduction for Scientists and Engineers. Princeton, NJ, USA: Princeton Univ. Press, 2008
2008
-
[10]
On a new measure of interaction for multivariable process control,
E. H. Bristol, “On a new measure of interaction for multivariable process control,” IEEE Trans. Autom. Control, vol. 11, no. 1, pp. 133–134, 1966
1966
-
[11]
J. B. Rawlings, D. Q. Mayne, and M. M. Diehl, Model Predictive Control: Theory, Computation, and Design, 2nd ed. Madison, WI, USA: Nob Hill, 2017
2017
-
[12]
Skogestad and I
S. Skogestad and I. Postlethwaite, Multivariable Feedback Control: Anal- ysis and Design, 2nd ed. Hoboken, NJ, USA: Wiley, 2005
2005
-
[13]
The quadruple-tank process: A multivariable labora- tory process with an adjustable zero,
K. H. Johansson, “The quadruple-tank process: A multivariable labora- tory process with an adjustable zero,” IEEE Trans. Control Syst. Technol., vol. 8, no. 3, pp. 456–465, 2000
2000
-
[14]
Qwen Team, “Qwen3 technical report,” arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[15]
Qwen Team, “Qwen2.5 technical report,” arXiv preprint arXiv:2412.15115, 2024
Pith/arXiv arXiv 2024
-
[16]
A. Grattafiori et al. (Llama Team), “The Llama 3 herd of models,” arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[17]
A simplex method for function minimization,
J. A. Nelder and R. Mead, “A simplex method for function minimization,” Comput. J., vol. 7, no. 4, pp. 308–313, 1965
1965
-
[18]
SciPy 1.0: Fundamental algorithms for scientific com- puting in Python,
P. Virtanen et al., “SciPy 1.0: Fundamental algorithms for scientific com- puting in Python,” Nature Methods, vol. 17, pp. 261–272, 2020. 10 VOLUME 4, 2016
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.