Learning to Evolve Scenes: Reasoning about Human Activities with Scene Graphs
Pith reviewed 2026-07-03 15:04 UTC · model grok-4.3
The pith
Spatio-temporal scene graphs let models forecast how human actions reshape the environment over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
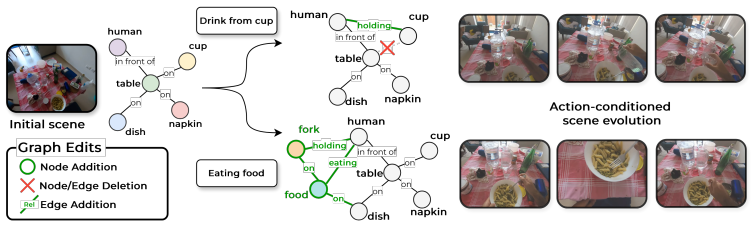
Spatio-temporal scene graphs supply an explicit, compositional representation of scene state that evolves with human activities. GLEN processes sequences of these graphs to align them with textual actions and to forecast sequences of graph edits conditioned on those actions, delivering competitive performance on EgoMCQ, EgoCVR, EXPLORE-Bench, and the introduced A-GEF task while supporting controllable predictions of scene change.
What carries the argument
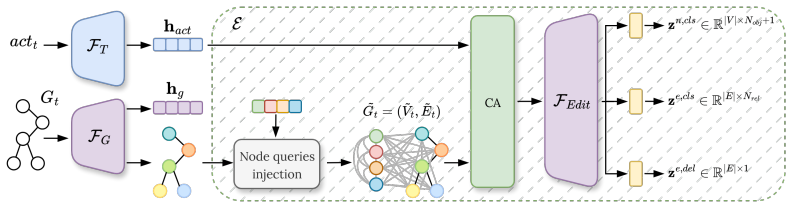
GLEN, a graph-based model that operates over scene graph sequences to align them with textual actions and model their temporal evolution, paired with the activity-driven graph-edit forecasting (A-GEF) formulation that casts scene dynamics as structured transformations.
If this is right
- Scene changes can be expressed and predicted as explicit sequences of graph transformations rather than implicit visual features.
- Activity understanding gains an interpretable intermediate representation that supports editing and conditioning on specific actions.
- Reasoning benchmarks that usually require multimodal language models become addressable with lighter graph-based architectures.
- First-person video tasks gain access to compositional tracking of object relations across time.
Where Pith is reading between the lines
- If scene-graph sequences prove sufficient for activity reasoning, embodied systems could simulate future states by editing graphs instead of rendering full video.
- The same forecasting approach could transfer to other time-varying domains such as traffic scenes or multi-agent environments.
- Combining the graph representation with language models might yield hybrid systems that retain both structure and open-ended generation.
Load-bearing premise
Spatio-temporal scene graphs can be accurately and consistently annotated from ego-centric video and preserve the essential information needed for activity reasoning without substantial loss compared to raw visual input.
What would settle it
Demonstrating that a raw-video model achieves higher accuracy than GLEN on the A-GEF forecasting task or on EXPLORE-Bench would undermine the claimed advantage of the scene-graph representation.
Figures

read the original abstract
Understanding human behavior while interacting with the surrounding world is crucial for many applications of embodied AI. First-person videos are particularly informative for this problem, as they well capture how activities reshape the scene over time. However, existing approaches often rely on implicit visual or language-aligned representations, disregarding structured reasoning over the scene dynamic. We argue that explicit, compositional and editable representations of human-environment interactions can play a crucial role for rich grounded activity understanding. To this end, we introduce SG-Ego, a large scale annotation set extending Ego4D with spatio-temporal scene graphs, where relations triplets are consolidated over time into explicit time-evolving descriptions of the scene state. To reason over this representation, we propose GLEN, a graph-based model that operates over scene graph sequences to both align them with textual actions and model their temporal evolution. In addition, we formulate the activity-driven graph-edit forecasting (A-GEF) problem, a novel task that casts scene dynamics as a sequence of structured transformations conditioned on ongoing actions, enabling explicit reasoning about how scenes change over time. We validate our approach across multiple downstream tasks, spanning retrieval benchmarks as EgoMCQ and EgoCVR, as well as long-horizon reasoning benchmarks as EXPLORE-Bench and the newly introduced A-GEF. GLEN achieves strong results compared to raw video baselines and it excels in reasoning settings, typically addressed only with MLLMs, while enabling controllable and structured predictions of scene dynamics driven by human activities. We believe our results establish spatio-temporal scene graphs, together with models that reason over them, as strong compositional and interpretable representations for video understanding and potentially beyond.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SG-Ego, a large-scale extension of Ego4D with spatio-temporal scene graphs in which relation triplets are consolidated over time into explicit evolving scene-state descriptions. It proposes GLEN, a graph-based model that operates on scene-graph sequences to align them with textual actions and to model temporal evolution, and formulates the activity-driven graph-edit forecasting (A-GEF) task. Experiments on EgoMCQ, EgoCVR, EXPLORE-Bench and the new A-GEF benchmark report that GLEN outperforms raw-video baselines and matches or exceeds MLLMs on reasoning tasks while enabling controllable, structured predictions of scene dynamics.
Significance. If the central empirical claims hold after verification of scene-graph fidelity, the work would establish explicit, compositional spatio-temporal scene graphs as a viable alternative to implicit visual or language-aligned representations for grounded activity understanding in ego-centric video, with direct benefits for interpretability and controllability in embodied AI.
major comments (2)
- [§3 and §5] §3 (Dataset) and §5 (Experiments): The central claim that GLEN’s gains over raw-video baselines demonstrate the superiority of the scene-graph representation rests on the untested premise that the consolidated SG-Ego annotations retain all activity-critical visual cues (fine-grained appearance, occlusion, motion). No quantitative measure of information loss—such as human agreement rates on graph vs. video sufficiency or controlled ablations that remove specific relation types—is reported; this directly affects interpretation of the EgoMCQ/EgoCVR and A-GEF results.
- [§4.2 and Table 2] §4.2 (GLEN architecture) and Table 2: The model is described as operating over scene-graph sequences, yet the precise mechanism for temporal consolidation of relations and for conditioning graph edits on action tokens is not accompanied by an ablation that isolates the contribution of the consolidation step versus the raw per-frame graphs; without this, it is unclear whether the reported improvements on EXPLORE-Bench are attributable to the representation or to the particular consolidation heuristic.
minor comments (2)
- [Figure 3] Figure 3: The legend and axis labels for the A-GEF edit-distance curves are too small to read at print size; please enlarge or split the figure.
- [§2] §2 (Related Work): The discussion of prior scene-graph video work omits recent ego-centric graph datasets (e.g., Ego4D scene-graph extensions published after 2023); a brief comparison paragraph would help situate SG-Ego.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that strengthen the empirical grounding of our claims.
read point-by-point responses
-
Referee: [§3 and §5] §3 (Dataset) and §5 (Experiments): The central claim that GLEN’s gains over raw-video baselines demonstrate the superiority of the scene-graph representation rests on the untested premise that the consolidated SG-Ego annotations retain all activity-critical visual cues (fine-grained appearance, occlusion, motion). No quantitative measure of information loss—such as human agreement rates on graph vs. video sufficiency or controlled ablations that remove specific relation types—is reported; this directly affects interpretation of the EgoMCQ/EgoCVR and A-GEF results.
Authors: We agree that direct quantification of information loss would strengthen interpretation of the results. The performance gains on EgoMCQ, EgoCVR and A-GEF indicate that the consolidated graphs retain the relational and state information required for these tasks, yet we acknowledge the absence of explicit verification. In the revision we will add (i) a human study reporting agreement rates on task sufficiency using graphs versus video and (ii) controlled ablations that remove specific relation categories, with results reported in §5. revision: yes
-
Referee: [§4.2 and Table 2] §4.2 (GLEN architecture) and Table 2: The model is described as operating over scene-graph sequences, yet the precise mechanism for temporal consolidation of relations and for conditioning graph edits on action tokens is not accompanied by an ablation that isolates the contribution of the consolidation step versus the raw per-frame graphs; without this, it is unclear whether the reported improvements on EXPLORE-Bench are attributable to the representation or to the particular consolidation heuristic.
Authors: The consolidation procedure is integral to producing the time-evolving scene states that define SG-Ego. We will expand §4.2 with a precise description of the consolidation algorithm and the conditioning of edits on action tokens. We will also add an ablation (new row in Table 2 or supplementary table) that compares GLEN trained on consolidated sequences versus raw per-frame graphs on EXPLORE-Bench, thereby isolating the contribution of the consolidation step. revision: yes
Circularity Check
No circularity; empirical claims rest on new annotations and benchmarks
full rationale
The paper introduces SG-Ego annotations, the GLEN model, and the A-GEF task as novel contributions, then reports empirical results on EgoMCQ, EgoCVR, EXPLORE-Bench and A-GEF. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or described chain. All performance claims are externally falsifiable via the new dataset and standard benchmarks rather than reducing to the model's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Remembr: Building and reasoning over long-horizon spatio-temporal memory for robot navigation
Abrar Anwar, John Welsh, Joydeep Biswas, Soha Pouya, and Yan Chang. Remembr: Building and reasoning over long-horizon spatio-temporal memory for robot navigation. InICRA, 2025
2025
-
[2]
Embodied videoagent: Persistent memory from egocentric videos and embodied sensors enables dynamic scene understanding
Yue Fan, Xiaojian Ma, Rongpeng Su, Jun Guo, Rujie Wu, Xi Chen, and Qing Li. Embodied videoagent: Persistent memory from egocentric videos and embodied sensors enables dynamic scene understanding. In ICCV, 2025
2025
-
[3]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. InCVPR, 2022
2022
-
[4]
Egotaskqa: Understanding human tasks in egocentric videos
Baoxiong Jia, Ting Lei, Song-Chun Zhu, and Siyuan Huang. Egotaskqa: Understanding human tasks in egocentric videos. InNeurIPS, 2022
2022
-
[5]
Egocentric video-language pretraining
Kevin Qinghong Lin, Jinpeng Wang, Mattia Soldan, Michael Wray, Rui Yan, Eric Z XU, Difei Gao, Rong-Cheng Tu, Wenzhe Zhao, Weijie Kong, et al. Egocentric video-language pretraining. InNIPS, 2022
2022
-
[6]
Egovlpv2: Egocentric video-language pre-training with fusion in the backbone
Shraman Pramanick, Yale Song, Sayan Nag, Kevin Qinghong Lin, Hardik Shah, Mike Zheng Shou, Rama Chellappa, and Pengchuan Zhang. Egovlpv2: Egocentric video-language pre-training with fusion in the backbone. InICCV, 2023
2023
-
[7]
Egoschema: A diagnostic benchmark for very long-form video language understanding
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding. InNeurIPS, 2023
2023
-
[8]
Action genome: Actions as compositions of spatio-temporal scene graphs
Jingwei Ji, Ranjay Krishna, Li Fei-Fei, and Juan Carlos Niebles. Action genome: Actions as compositions of spatio-temporal scene graphs. InCVPR, 2020
2020
-
[9]
Spatial- temporal transformer for dynamic scene graph generation
Yuren Cong, Wentong Liao, Hanno Ackermann, Bodo Rosenhahn, and Michael Ying Yang. Spatial- temporal transformer for dynamic scene graph generation. InICCV, 2021
2021
-
[10]
Panoptic video scene graph generation
Jingkang Yang, Wenxuan Peng, Xiangtai Li, Zujin Guo, Liangyu Chen, Bo Li, Zheng Ma, Kaiyang Zhou, Wayne Zhang, Chen Change Loy, et al. Panoptic video scene graph generation. InCVPR, 2023
2023
-
[11]
Hyperglm: Hypergraph for video scene graph generation and anticipation
Trong-Thuan Nguyen, Pha Nguyen, Jackson Cothren, Alper Yilmaz, and Khoa Luu. Hyperglm: Hypergraph for video scene graph generation and anticipation. InCVPR, 2025
2025
-
[12]
Towards scene graph anticipation
Rohith Peddi, Saksham Singh, Saurabh, Parag Singla, and Vibhav Gogate. Towards scene graph anticipation. InECCV, 2024
2024
-
[13]
Antonio Alliegro, Francesca Pistilli, Tatiana Tommasi, and Giuseppe Averta. Forescene: Forecasting human activity via latent scene graphs diffusion.arXiv preprint arXiv:2503.06182, 2025. 10
-
[14]
Egocvr: An egocentric benchmark for fine-grained composed video retrieval
Thomas Hummel, Shyamgopal Karthik, Mariana-Iuliana Georgescu, and Zeynep Akata. Egocvr: An egocentric benchmark for fine-grained composed video retrieval. InECCV, 2024
2024
-
[15]
EXPLORE-Bench: Egocentric Scene Prediction with Long-Horizon Reasoning
Chengjun Yu, Xuhan Zhu, Chaoqun Du, Pengfei Yu, Wei Zhai, Yang Cao, and Zheng-Jun Zha. Explore- bench: Egocentric scene prediction with long-horizon reasoning.arXiv preprint arXiv:2603.09731, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Sgtr: End-to-end scene graph generation with transformer
Rongjie Li, Songyang Zhang, and Xuming He. Sgtr: End-to-end scene graph generation with transformer. InCVPR, 2022
2022
-
[17]
Egtr: Extracting graph from transformer for scene graph generation
Jinbae Im, JeongYeon Nam, Nokyung Park, Hyungmin Lee, and Seunghyun Park. Egtr: Extracting graph from transformer for scene graph generation. InCVPR, 2024
2024
-
[18]
More knowledge, less bias: Unbiasing scene graph generation with explicit ontological adjustment
Zhanwen Chen, Saed Rezayi, and Sheng Li. More knowledge, less bias: Unbiasing scene graph generation with explicit ontological adjustment. InWACV, 2023
2023
-
[19]
Synthetic visual genome
Jae Sung Park, Zixian Ma, Linjie Li, Chenhao Zheng, Cheng-Yu Hsieh, Ximing Lu, Khyathi Chandu, Quan Kong, Norimasa Kobori, Ali Farhadi, et al. Synthetic visual genome. InCVPR, 2025
2025
-
[20]
Ziqi Gao, Jieyu Zhang, Wisdom Oluchi Ikezogwo, Jae Sung Park, Tario G You, Daniel Ogbu, Chenhao Zheng, Weikai Huang, Yinuo Yang, Winson Han, et al. Synthetic visual genome 2: Extracting large-scale spatio-temporal scene graphs from videos.arXiv preprint arXiv:2602.23543, 2026
-
[21]
Llm4sgg: Large language models for weakly supervised scene graph generation
Kibum Kim, Kanghoon Yoon, Jaehyeong Jeon, Yeonjun In, Jinyoung Moon, Donghyun Kim, and Chany- oung Park. Llm4sgg: Large language models for weakly supervised scene graph generation. InCVPR, 2024
2024
-
[22]
Unbiased scene graph generation in videos
Sayak Nag, Kyle Min, Subarna Tripathi, and Amit K Roy-Chowdhury. Unbiased scene graph generation in videos. InCVPR, 2023
2023
-
[23]
Hig: Hierarchical interlacement graph approach to scene graph generation in video understanding
Trong-Thuan Nguyen, Pha Nguyen, and Khoa Luu. Hig: Hierarchical interlacement graph approach to scene graph generation in video understanding. InCVPR, 2024
2024
-
[24]
Dynamic multistep reasoning based on video scene graph for video question answering
Jianguo Mao, Wenbin Jiang, Xiangdong Wang, Zhifan Feng, Yajuan Lyu, Hong Liu, and Yong Zhu. Dynamic multistep reasoning based on video scene graph for video question answering. InHLT-NAACL, 2022
2022
-
[25]
Action scene graphs for long-form understanding of egocentric videos
Ivan Rodin, Antonino Furnari, Kyle Min, Subarna Tripathi, and Giovanni Maria Farinella. Action scene graphs for long-form understanding of egocentric videos. InCVPR, 2024
2024
-
[26]
Step: Enhancing video-llms’ compositional reasoning by spatio- temporal graph-guided self-training
Haiyi Qiu, Minghe Gao, Long Qian, Kaihang Pan, Qifan Yu, Juncheng Li, Wenjie Wang, Siliang Tang, Yueting Zhuang, and Tat-Seng Chua. Step: Enhancing video-llms’ compositional reasoning by spatio- temporal graph-guided self-training. InCVPR, 2025
2025
-
[27]
Structuring video semantics with temporal triplets for zero-shot video question answering
Linlin Zong, Xinyu Zhai, Xinyue Liu, Wenxin Liang, Xianchao Zhang, and Bo Xu. Structuring video semantics with temporal triplets for zero-shot video question answering. InCIKM, 2025
2025
-
[28]
Dygenc: Encoding a sequence of textual scene graphs to reason and answer questions in dynamic scenes.Technologies, 2026
Sergey Linok, Vadim Semenov, Anastasia Trunova, Oleg Bulichev, and Dmitry Yudin. Dygenc: Encoding a sequence of textual scene graphs to reason and answer questions in dynamic scenes.Technologies, 2026
2026
-
[29]
Tatiana Zemskova, Solomon Andryushenko, Ilya Obrubov, Viktoriia Khoruzhaia, Ekaterina Eroshenko, Ekaterina Derevyanka, and Dmitry Yudin. Focusgraph: Graph-structured frame selection for embodied long video question answering.arXiv preprint arXiv:2603.04349, 2026
-
[30]
A distance measure between attributed relational graphs for pattern recognition.IEEE Transactions on Systems, Man, and Cybernetics, 1983
Alberto Sanfeliu and King-Sun Fu. A distance measure between attributed relational graphs for pattern recognition.IEEE Transactions on Systems, Man, and Cybernetics, 1983
1983
-
[31]
Fast suboptimal algorithms for the computation of graph edit distance
Michel Neuhaus, Kaspar Riesen, and Horst Bunke. Fast suboptimal algorithms for the computation of graph edit distance. InJoint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR), 2006
2006
-
[32]
Speeding up graph edit distance computation with a bipartite heuristic
Kaspar Riesen, Stefan Fankhauser, and Horst Bunke. Speeding up graph edit distance computation with a bipartite heuristic. InMLG, 2007
2007
-
[33]
Approximate graph edit distance computation by means of bipartite graph matching.Image and Vision computing, 2009
Kaspar Riesen and Horst Bunke. Approximate graph edit distance computation by means of bipartite graph matching.Image and Vision computing, 2009
2009
-
[34]
Fast computation of bipartite graph matching.Pattern Recognition Letters, 2014
Francesc Serratosa. Fast computation of bipartite graph matching.Pattern Recognition Letters, 2014. 11
2014
-
[35]
Simgnn: A neural network approach to fast graph similarity computation
Yunsheng Bai, Hao Ding, Song Bian, Ting Chen, Yizhou Sun, and Wei Wang. Simgnn: A neural network approach to fast graph similarity computation. InProceedings of the twelfth ACM international conference on web search and data mining, 2019
2019
-
[36]
Graph matching networks for learning the similarity of graph structured objects
Yujia Li, Chenjie Gu, Thomas Dullien, Oriol Vinyals, and Pushmeet Kohli. Graph matching networks for learning the similarity of graph structured objects. InICML, 2019
2019
-
[37]
Graph edit networks
Benjamin Paassen, Daniele Grattarola, Daniele Zambon, Cesare Alippi, and Barbara Hammer. Graph edit networks. InICLR, 2021
2021
-
[38]
URLhttps://qwen.ai/blog?id=qwen3.5
Qwen3.5: Towards native multimodal agents, 2026. URLhttps://qwen.ai/blog?id=qwen3.5
2026
-
[39]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InECCV, 2024
2024
-
[40]
arXiv preprint arXiv:2502.16427 (2025)
Sanghyeok Chu, Seonguk Seo, and Bohyung Han. Fine-grained captioning of long videos through scene graph consolidation.arXiv preprint arXiv:2502.16427, 2025
-
[41]
SAM 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollar, and Christoph Feichtenhofer. SAM 2: Segment anything in images and videos. InICLR, 2025
2025
-
[42]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick L...
2024
-
[43]
Learning 3D Semantic Scene Graphs from 3D Indoor Reconstructions
Johanna Wald, Helisa Dhamo, Nassir Navab, and Federico Tombari. Learning 3D Semantic Scene Graphs from 3D Indoor Reconstructions. InCVPR, 2020
2020
-
[44]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InICML, 2023
2023
-
[45]
Composed video retrieval via enriched context and discriminative embeddings
Omkar Thawakar, Muzammal Naseer, Rao Muhammad Anwer, Salman Khan, Michael Felsberg, Mubarak Shah, and Fahad Shahbaz Khan. Composed video retrieval via enriched context and discriminative embeddings. InCVPR, 2024
2024
-
[46]
Perception encoder: The best visual embeddings are not at the output of the network
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Abdul Rasheed, Junke Wang, Marco Monteiro, Hu Xu, Shiyu Dong, Nikhila Ravi, Shang-Wen Li, Piotr Dollar, and Christoph Feichtenhofer. Perception encoder: The best visual embeddings are not at the output of the network. InNIPS, 2025
2025
-
[47]
Minilmv2: Multi-head self- attention relation distillation for compressing pretrained transformers
Wenhui Wang, Hangbo Bao, Shaohan Huang, Li Dong, and Furu Wei. Minilmv2: Multi-head self- attention relation distillation for compressing pretrained transformers. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 2021
2021
-
[48]
Baoqi Pei, Yifei Huang, Jilan Xu, Yuping He, Guo Chen, Fei Wu, Yu Qiao, and Jiangmiao Pang. Egothinker: Unveiling egocentric reasoning with spatio-temporal cot.arXiv preprint arXiv:2510.23569, 2025
-
[49]
Hiervl: Learning hierarchical video-language embeddings
Kumar Ashutosh, Rohit Girdhar, Lorenzo Torresani, and Kristen Grauman. Hiervl: Learning hierarchical video-language embeddings. InCVPR, 2023
2023
-
[50]
Hiero: understanding the hierarchy of human behavior enhances reasoning on egocentric videos
Simone Alberto Peirone, Francesca Pistilli, and Giuseppe Averta. Hiero: understanding the hierarchy of human behavior enhances reasoning on egocentric videos. InICCV, 2025
2025
-
[51]
CoVR: Learning composed video retrieval from web video captions
Lucas Ventura, Antoine Yang, Cordelia Schmid, and Gül Varol. CoVR: Learning composed video retrieval from web video captions. InAAAI, 2024
2024
-
[52]
Vision-by-language for training-free compositional image retrieval
Shyamgopal Karthik, Karsten Roth, Massimiliano Mancini, and Zeynep Akata. Vision-by-language for training-free compositional image retrieval. InICLR, 2024
2024
-
[53]
main actor
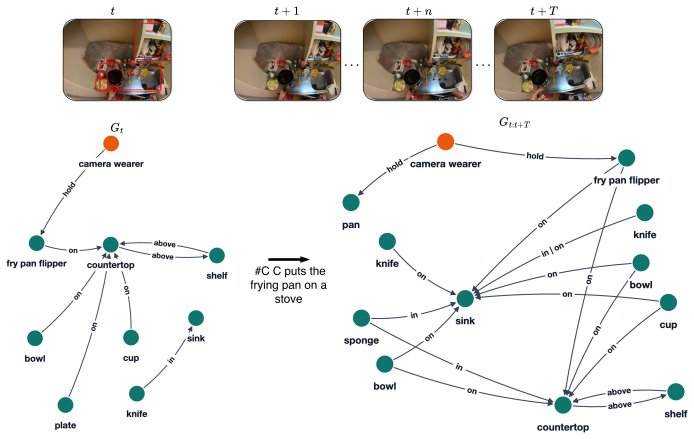
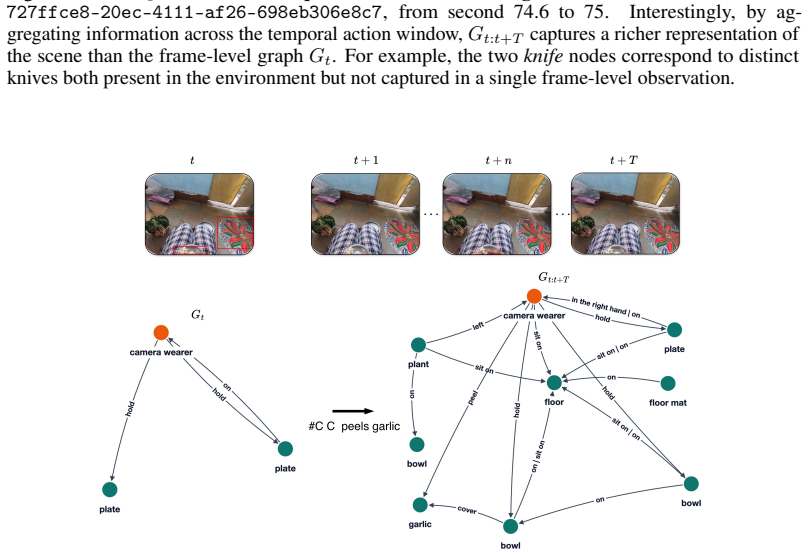
Omkar Thawakar, Dmitry Demidov, Ritesh Thawkar, Rao Muhammad Anwer, Mubarak Shah, Fahad Shah- baz Khan, and Salman Khan. Beyond simple edits: Composed video retrieval with dense modifications. In ICCV, 2025. 12 Appendix A The SG-Ego dataset SG-Ego Examples.We show some examples from our dataset in Figure 3, Figure 4 and Figure 5, reporting the spatial sce...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.