Hierarchical Clustering As a Novel Solution to the Notorious Multicollinearity Problem in Observational Causal Inference
Pith reviewed 2026-07-01 01:40 UTC · model grok-4.3
The pith
Hierarchical clustering of geographic units on marketing spend correlations, after normalization and demeaning, allows separate identification of channel effects in a Bayesian marketing mix model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
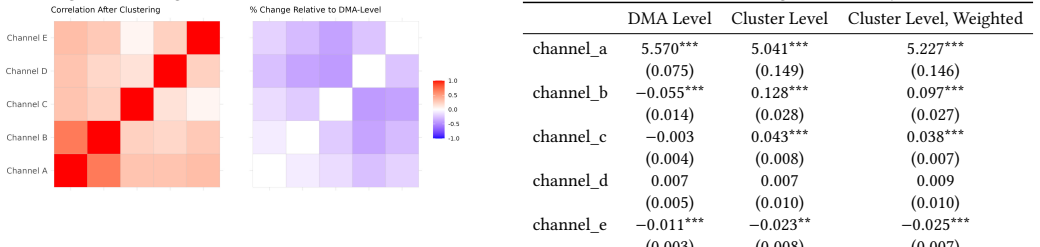
By hierarchically clustering geographic units based on marketing spend correlation after normalization and demeaning, and fitting a Bayesian Marketing Mix Model at the cluster level, the approach mitigates collinearity and facilitates the separate identification of the impact of different marketing channels.
What carries the argument
Hierarchical clustering on pairwise distances of normalized and demeaned marketing spend data between geographic units.
If this is right
- The clustering effectively mitigates collinearity in the aggregated data.
- It enables separate identification of impacts from different marketing channels.
- The two-step process of normalization, demeaning, then clustering on correlation is key to the method.
- This solution is generally applicable to causal problems featuring multicollinearity.
Where Pith is reading between the lines
- Applying this clustering in other fields with correlated predictors, such as economic policy analysis, could yield similar benefits.
- Comparing results from clustered models to those from regularized regressions on the same data would test robustness.
- Exploring different linkage methods in the hierarchical clustering could optimize the balance between collinearity reduction and data granularity.
Load-bearing premise
That clustering geographic units solely based on observed spend correlations will preserve the underlying causal relationships without introducing aggregation bias that alters individual channel effect identification.
What would settle it
Observing that the variance inflation factors remain high or that channel coefficient estimates change substantially when using different clustering cutoffs would indicate the method does not reliably mitigate the problem.
Figures




read the original abstract
Multicollinearity is a long lasting challenge in observational causal inference, especially in regressions -- highly correlated independent variables make it hard to isolate their individual impacts on outcomes of interest. While common solutions such as shrinkage estimators and principal component regressions are helpful in prediction problems, a crucial limitation hinders their applicability to causal inference problems -- they cannot provide the original causal relationships. To fill the gap, we present an innovative and intuitive solution, by employing hierarchical clustering to aggregate data in a way that effectively alleviates collinearity. This method is generally applicable to causal problems featuring multicollinearity. We use a marketing application to demonstrate how and why it works. Expenditures on different advertising channels often exhibit correlations, making it exceedingly difficult to separately measure their impact. Many previous studies proposed to leverage granular cross-sectional data for better identification but, to our knowledge, none explicitly addressed multicollinearity, which undermines causal identification even with granular data. We propose to hierarchically cluster geographic units based on marketing spend correlation to reduce collinearity, and to implement a Bayesian Marketing Mix Model with cluster-level data. Such clustering happens in two steps -- we first normalize and demean geo-level data to establish a common scale and to eliminate the common trends; we then calculate pairwise distance to summarize marketing spend correlation between geos and cluster the ones with moderate to strong correlation. Both descriptive evidence and regression analysis affirm that such hierarchical clustering effectively mitigates collinearity and facilitates the separate identification of the impact of different marketing channels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hierarchical clustering of geographic units, performed after normalizing and demeaning geo-level marketing spend data and using pairwise correlations as distance, reduces multicollinearity sufficiently to allow separate identification of individual advertising channel effects when a Bayesian Marketing Mix Model is estimated at the resulting cluster level. It asserts that both descriptive evidence and regression analysis confirm the mitigation and improved identification, positioning the method as a general solution for multicollinearity in observational causal inference that preserves interpretability of the original variables.
Significance. If the central claim holds after proper validation, the approach would supply a practical, interpretable preprocessing step for causal regression problems featuring correlated regressors, particularly in marketing-mix and similar applied settings where shrinkage or principal-component methods are undesirable because they obscure the original causal parameters.
major comments (2)
- [Abstract] Abstract: the assertion that 'both descriptive evidence and regression analysis affirm' mitigation of collinearity supplies no quantitative metrics, error bars, baseline comparisons, or cluster-validation statistics, leaving the central empirical claim without measurable support.
- [Abstract] Abstract: the method implicitly assumes that clustering on observed spend correlations (after demeaning) and subsequent aggregation will recover channel-specific causal effects without ecological bias; no simulation recovering known heterogeneous parameters or formal condition guaranteeing zero aggregation bias is provided, which is load-bearing for the identification claim.
minor comments (1)
- [Abstract] Abstract: the phrase 'moderate to strong correlation' is used to define the clustering threshold but is never quantified, leaving the procedure incompletely specified.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of our empirical claims and identification strategy. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'both descriptive evidence and regression analysis affirm' mitigation of collinearity supplies no quantitative metrics, error bars, baseline comparisons, or cluster-validation statistics, leaving the central empirical claim without measurable support.
Authors: The abstract serves as a concise summary; the full manuscript presents the supporting evidence through pre- and post-clustering correlation matrices, variance inflation factor comparisons, and regression diagnostics. To address the concern directly in the abstract, we will revise it to report specific quantitative metrics such as the reduction in average pairwise correlations and VIF values relative to the unclustered baseline, along with cluster validation statistics. revision: yes
-
Referee: [Abstract] Abstract: the method implicitly assumes that clustering on observed spend correlations (after demeaning) and subsequent aggregation will recover channel-specific causal effects without ecological bias; no simulation recovering known heterogeneous parameters or formal condition guaranteeing zero aggregation bias is provided, which is load-bearing for the identification claim.
Authors: Clustering is performed on demeaned and normalized spend data to group geos with similar relative patterns, thereby reducing multicollinearity while retaining the original channel variables at the cluster level. The manuscript motivates this via the marketing application and discusses the underlying assumptions. We agree that ecological bias under heterogeneity is a relevant concern not addressed via simulation in the current version. In revision we will expand the discussion of identification assumptions and potential aggregation bias, though a dedicated simulation study is not feasible within the scope of this revision. revision: partial
Circularity Check
No significant circularity; method is a preprocessing recipe verified empirically
full rationale
The paper proposes hierarchical clustering of geos on normalized/demeaned spend correlations as a preprocessing step before fitting a Bayesian MMM at the cluster level. It reports that this reduces collinearity via descriptive evidence and regression analysis, but presents no algebraic derivation, fitted parameter renamed as prediction, or self-citation chain that reduces the central claim to its inputs by construction. The clustering criterion and aggregation are external to the identification claim and are checked against data rather than assumed tautologically. This is a standard methodological proposal with independent empirical support.
Axiom & Free-Parameter Ledger
free parameters (1)
- correlation threshold for 'moderate to strong'
axioms (1)
- domain assumption Normalization and demeaning remove common trends without distorting relative channel effects
Reference graph
Works this paper leans on
-
[1]
Ron Berman. 2018. Beyond the last touch: Attribution in online advertising. Marketing Science37, 5 (2018), 771–792
2018
-
[2]
Thomas Blake, Chris Nosko, and Steven Tadelis. 2015. Consumer heterogeneity and paid search effectiveness: A large-scale field experiment.Econometrica83, 1 (2015), 155–174
2015
-
[3]
David Chan and Mike Perry. 2017. Challenges and opportunities in media mix modeling. (2017)
2017
-
[4]
Hao Chen, Minguang Zhang, Lanshan Han, and Alvin Lim. 2021. Hierarchical marketing mix models with sign constraints.Journal of Applied Statistics48, 13-15 (2021), 2944–2960
2021
-
[5]
Jamal I Daoud. 2017. Multicollinearity and regression analysis. InJournal of Physics: Conference Series, Vol. 949. IOP Publishing, 012009
2017
-
[6]
Ruihuan Du, Yu Zhong, Harikesh Nair, Bo Cui, and Ruyang Shou. 2019. Causally driven incremental multi touch attribution using a recurrent neural network. arXiv preprint arXiv:1902.00215(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[7]
2000.Partially linear models
Wolfgang Härdle, Hua Liang, and Jiti Gao. 2000.Partially linear models. Springer Science & Business Media
2000
-
[8]
Arthur E Hoerl and Robert W Kennard. 1970. Ridge regression: applications to nonorthogonal problems.Technometrics12, 1 (1970), 69–82
1970
-
[9]
Guido W. Imbens and Donald B. Rubin. 2015.Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction. Cambridge University Press. https://doi.org/10.1017/CBO9781139025751
-
[10]
Yuxue Jin, Yueqing Wang, Yunting Sun, David Chan, and Jim Koehler. 2017. Bayesian methods for media mix modeling with carryover and shape effects. (2017)
2017
-
[11]
Fionn Murtagh and Pedro Contreras. 2012. Algorithms for hierarchical cluster- ing: an overview.Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery2, 1 (2012), 86–97
2012
-
[12]
2014.Position effects in search advertis- ing: A regression discontinuity approach
Sridhar Narayanan and Kirthi Kalyanam. 2014.Position effects in search advertis- ing: A regression discontinuity approach. Technical Report. Working paper
2014
- [13]
-
[14]
Chandan K Reddy and Bhanukiran Vinzamuri. 2018. A survey of partitional and hierarchical clustering algorithms. InData clustering. Chapman and Hall/CRC, 87–110
2018
-
[15]
Michael Thomas. 2020. Spillovers from mass advertising: An identification strategy.Marketing Science39, 4 (2020), 807–826
2020
-
[16]
Jon Vaver and Stephanie Shin-Hui Zhang. 2017. Introduction to the Aggregate Marketing System Simulator. (2017)
2017
-
[17]
Yueqing Wang, Yuxue Jin, Yunting Sun, David Chan, and Jim Koehler. 2017. A hierarchical Bayesian approach to improve media mix models using category data. (2017)
2017
-
[18]
Michael J Wolfe Sr and John C Crotts. 2011. Marketing mix modeling for the tourism industry: A best practices approach.International Journal of Tourism Sciences11, 1 (2011), 1–15
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.