Diversified Residual Symbolic Regression
Pith reviewed 2026-05-19 18:41 UTC · model grok-4.3
The pith
Symbolic regression now collects multiple expressions that differ in which observations they treat as outliers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DRSR collects multiple expressions that fit the data well but differ in how residuals are distributed, enabling post-search selection aligned with domain knowledge. On a synthetic mixture dataset, DRSR produces more diverse expressions than conventional SR while capturing multiple underlying relationships. On a real-world astronomical dataset, DRSR discovers multiple expressions consistent with known physical relationships.
What carries the argument
A Quality-Diversity archive that maintains expressions distinguished by the distribution of their residuals across the data points.
If this is right
- Users gain the ability to examine different residual patterns and select the expression consistent with their domain expertise.
- Symbolic regression becomes less sensitive to ambiguous outlier definitions without needing predefined thresholds.
- A single search run can surface multiple meaningful relationships present in the same dataset.
- Post-search selection replaces the need for upfront decisions on which observations to downweight.
Where Pith is reading between the lines
- The same residual-diversity idea could be applied to other regression or modeling tasks where outlier treatment is ambiguous.
- Interactive interfaces that let experts steer the archive during search might further improve relevance of the returned expressions.
- Testing whether the diversity of residuals correlates with diversity of downstream predictions or decisions would strengthen the method's utility.
Load-bearing premise
Diversity in residual patterns produced by the Quality-Diversity archive corresponds to distinct, meaningful underlying relationships that domain experts can reliably distinguish and select among.
What would settle it
Domain experts reviewing the archive expressions find that the different residual patterns do not map to substantively different physical or causal interpretations of the data.
Figures











read the original abstract
Symbolic regression (SR) aims to discover explicit mathematical expressions that explain observed data and is widely used in domains where interpretability is essential. Because interpretability requires expressions to reflect meaningful regularities, SR is sensitive to observations that deviate from the dominant relationship. Such irregular observations, or outliers, are common in real-world data and can hinder SR from identifying underlying regularities. Robust regression mitigates this by downweighting observations with large residuals. However, deciding which observations should be treated as outliers is often ambiguous and depends on user interpretation and domain knowledge, a perspective largely overlooked in existing SR studies. This motivates approaches that present multiple candidate expressions, allowing users to examine different residual patterns and choose expressions consistent with their expertise. We propose diversified residual symbolic regression (DRSR), which achieves high predictive accuracy while promoting diversity with respect to residual patterns based on the Quality-Diversity paradigm. DRSR collects multiple expressions that fit the data well but differ in how residuals are distributed, enabling post-search selection aligned with domain knowledge. On a synthetic mixture dataset, DRSR produces more diverse expressions than conventional SR while capturing multiple underlying relationships. On a real-world astronomical dataset, DRSR discovers multiple expressions consistent with known physical relationships.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Diversified Residual Symbolic Regression (DRSR), an algorithm that applies the Quality-Diversity (QD) paradigm to symbolic regression. It maintains an archive of expressions that achieve high predictive accuracy while differing in their residual patterns (via a residual descriptor and niching mechanism). The central claims are that DRSR yields more diverse expressions than standard SR on a synthetic mixture dataset, capturing multiple underlying relationships, and that it recovers multiple expressions consistent with known physical relationships on a real-world astronomical dataset.
Significance. If the central empirical claims hold with proper validation, the work would be moderately significant for the symbolic regression community. It directly addresses the practical problem of outlier ambiguity and multi-modal data by shifting from a single best-fit expression to a curated set of alternatives, which aligns with domain-expert selection. The use of QD for residual-pattern diversity is a novel algorithmic angle, though its impact depends on demonstrating that the produced diversity is semantically meaningful rather than artifactual.
major comments (3)
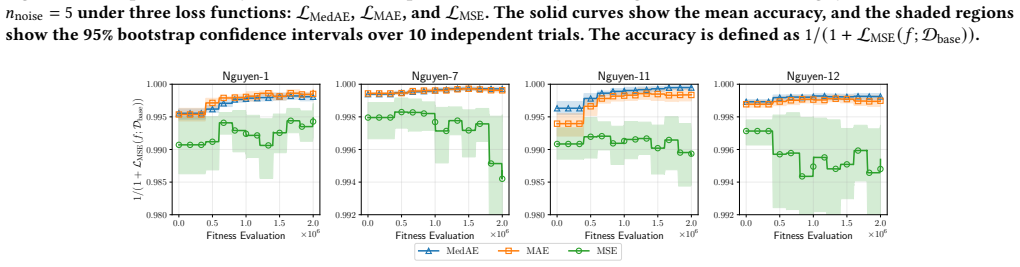
- [§4] §4 (Experiments on synthetic data): The claim that DRSR 'captures multiple underlying relationships' on the synthetic mixture dataset is load-bearing for the central contribution, yet the manuscript provides no quantitative recovery metrics (e.g., per-component R² on held-out subsets, symbolic equivalence checks against ground-truth components, or alignment between archive niches and generative processes). Without these, residual-pattern diversity cannot be confirmed to correspond to distinct relationships rather than fitting noise or equivalent rewrites.
- [§3.2] §3.2 (Residual descriptor and archive grid): The definition of the residual descriptor used for niching is central to the diversity claim, but the paper does not report sensitivity analysis or ablation on the choice of descriptor features and grid resolution. If the descriptor primarily captures magnitude rather than pattern shape, the QD archive may simply rediscover scaled variants of the same expression.
- [Results tables] Table 2 or equivalent results table: The reported diversity advantage over conventional SR lacks statistical tests (e.g., paired t-tests or Wilcoxon tests across multiple runs) and baseline comparisons against other multi-expression SR methods such as Pareto-front or ensemble SR approaches. This weakens the assertion that the QD mechanism is the source of improved diversity.
minor comments (3)
- [Abstract] The abstract states empirical outcomes but supplies no quantitative metrics, baseline comparisons, or implementation details; these should be summarized with effect sizes even in the abstract.
- [§3] Notation for the QD archive parameters (e.g., niche count, diversity metric weights) should be introduced with explicit symbols in §3 and used consistently in the experimental section.
- [Figures] Figure captions for the astronomical dataset results should explicitly state which physical relationships each discovered expression is claimed to recover, with reference to the relevant literature.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for strengthening the empirical validation and presentation of results. We have revised the manuscript accordingly by adding quantitative recovery metrics, sensitivity analyses, statistical tests, and additional baselines. Point-by-point responses follow.
read point-by-point responses
-
Referee: §4 (Experiments on synthetic data): The claim that DRSR 'captures multiple underlying relationships' on the synthetic mixture dataset is load-bearing for the central contribution, yet the manuscript provides no quantitative recovery metrics (e.g., per-component R² on held-out subsets, symbolic equivalence checks against ground-truth components, or alignment between archive niches and generative processes). Without these, residual-pattern diversity cannot be confirmed to correspond to distinct relationships rather than fitting noise or equivalent rewrites.
Authors: We agree that quantitative recovery metrics are necessary to substantiate the claim. In the revised manuscript, we have added per-component R² scores on held-out subsets for each generative component of the mixture, symbolic equivalence checks (via expression simplification and tree-edit distance) against the ground-truth expressions, and an explicit alignment between the QD archive niches and the underlying generative processes. These new results confirm that the observed residual diversity corresponds to distinct relationships. revision: yes
-
Referee: §3.2 (Residual descriptor and archive grid): The definition of the residual descriptor used for niching is central to the diversity claim, but the paper does not report sensitivity analysis or ablation on the choice of descriptor features and grid resolution. If the descriptor primarily captures magnitude rather than pattern shape, the QD archive may simply rediscover scaled variants of the same expression.
Authors: We acknowledge the value of validating the descriptor design. We have performed and now report sensitivity analyses on descriptor features (comparing raw moments, binned histograms, and normalized patterns) and multiple grid resolutions. The updated Section 3.2 and supplementary material show that the niching mechanism preserves diversity in residual shape even when magnitude is controlled, with the archive consistently separating expressions that differ in residual distribution rather than producing scaled variants of the same model. revision: yes
-
Referee: Table 2 or equivalent results table: The reported diversity advantage over conventional SR lacks statistical tests (e.g., paired t-tests or Wilcoxon tests across multiple runs) and baseline comparisons against other multi-expression SR methods such as Pareto-front or ensemble SR approaches. This weakens the assertion that the QD mechanism is the source of improved diversity.
Authors: We agree that statistical tests and broader baselines strengthen the comparison. The revised results table now includes Wilcoxon signed-rank tests across ten independent runs, confirming statistical significance of the diversity gains. We have also added direct comparisons to a Pareto-front multi-objective SR baseline and an ensemble SR method; these show that the residual-pattern QD approach yields distinct forms of diversity not captured by complexity-accuracy trade-offs or averaging ensembles. revision: yes
Circularity Check
No circularity; algorithmic proposal validated on external datasets
full rationale
The paper proposes DRSR as an algorithmic method that applies the Quality-Diversity paradigm to symbolic regression in order to collect expressions differing in residual patterns. Its central claims of greater diversity on synthetic mixtures and consistency with known physical relationships on astronomical data are presented as outcomes of empirical evaluation on those datasets, without any derivation, equation, or self-citation that reduces the reported diversity or predictive results to quantities defined by the same fitted parameters or archive metrics by construction. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Quality-Diversity archive parameters and diversity metric weights
axioms (1)
- domain assumption Quality-Diversity optimization can be applied to symbolic regression objectives to promote diversity in residual patterns
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose diversified residual symbolic regression (DRSR), which achieves high predictive accuracy while promoting diversity with respect to residual patterns based on the Quality-Diversity paradigm.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2014.Segmentation, Revenue Management, and Pricing Analytics
Tudor Bodea. 2014.Segmentation, Revenue Management, and Pricing Analytics. Routledge, Oxon
work page 2014
-
[2]
Jean-Philippe Bruneton. 2025. Enhancing Symbolic Regression with Quality- Diversity and Physics-Inspired Constraints. doi:10.48550/arXiv.2503.19043
-
[3]
Jean-Philippe Bruneton, Leo Cazenille, A. Douin, and V. Reverdy. 2019. Explo- ration and Exploitation in Symbolic Regression using Quality-Diversity and Evolutionary Strategies Algorithms. doi:10.48550/arXiv.1906.03959
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1906.03959 2019
-
[4]
Pedro Cardoso, Vasco V. Branco, Paulo A.V. Borges, José C. Carvalho, François Rigal, Rosalina Gabriel, Stefano Mammola, José Cascalho, and Luís Correia. 2020. Automated Discovery of Relationships, Models, and Principles in Ecology.Fron- tiers in Ecology and Evolution8 (11 Dec. 2020). doi:10.3389/fevo.2020.530135
-
[5]
Niels Johan Christensen, Samuel Demharter, Meera Machado, Lykke Pedersen, Marco Salvatore, Valdemar Stentoft-Hansen, and Miquel Tri- ana Iglesias. 2022. Identifying interactions in omics data for clinical biomarker discovery using symbolic regression.Bioinformatics38, 15 (06 2022), 3749–3758. arXiv:https://academic.oup.com/bioinformatics/article- pdf/38/1...
-
[6]
Oscar Claveria, Enric Monte, and Salvador Torra. 2016. Quantification of Survey Expectations by Means of Symbolic Regression via Genetic Programming to Estimate Economic Growth in Central and Eastern Eu- ropean Economies.Eastern European Economics54, 2 (2016), 171–189. arXiv:https://doi.org/10.1080/00128775.2015.1136564 doi:10.1080/00128775.2015. 1136564
-
[7]
Oscar Claveria, Enric Monte, and Salvador Torra. 2019. Evolutionary Computation for Macroeconomic Forecasting.Computational Economics53 (02 2019), 833–849. doi:10.1007/s10614-017-9767-4
-
[8]
Miles Cranmer. 2023. Interpretable Machine Learning for Science with PySR and SymbolicRegression.jl. doi:10.48550/arXiv.2305.01582
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.01582 2023
-
[9]
Antoine Cully and Yiannis Demiris. 2017. Quality and diversity optimization: A unifying modular framework.IEEE Transactions on Evolutionary Computation22, 2 (2017), 245–259
work page 2017
-
[10]
K. Deb, A. Pratap, S. Agarwal, and T. Meyarivan. 2002. A fast and elitist multiobjec- tive genetic algorithm: NSGA-II.IEEE Transactions on Evolutionary Computation 6, 2 (2002), 182–197. doi:10.1109/4235.996017
-
[11]
Z Eker, V Bakış, S Bilir, F Soydugan, I Steer, E Soydugan, H Bakış, F Aliçavuş, G Aslan, and M Alpsoy. 2018. Interrelated main-sequence mass–luminosity, mass–radius, and mass–effective temperature relations.Monthly Notices of the Royal Astronomical Society479, 4 (July 2018), 5491–5511. doi:10.1093/mnras/ sty1834
-
[12]
Martin A. Fischler and Robert C. Bolles. 1981. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Commun. ACM24, 6 (June 1981), 381–395. doi:10.1145/358669. 358692
-
[13]
Nikolaus Hansen, Sibylle D. Müller, and Petros Koumoutsakos. 2003. Reducing the Time Complexity of the Derandomized Evolution Strategy with Covariance Matrix Adaptation (CMA-ES).Evolutionary Computation11, 1 (2003), 1–18. doi:10.1162/106365603321828970
-
[14]
N. Hansen and A. Ostermeier. 1996. Adapting arbitrary normal mutation distri- butions in evolution strategies: the covariance matrix adaptation. InProceedings of IEEE International Conference on Evolutionary Computation (ICEC ’96). 312–317. doi:10.1109/ICEC.1996.542381
-
[15]
Peter J. Huber. 1992.Robust Estimation of a Location Parameter. Springer New York, New York, NY, 492–518. doi:10.1007/978-1-4612-4380-9_35
-
[16]
John R Koza. 1992. Evolution of subsumption using genetic programming. In Proceedings of the first European conference on artificial life. MIT Press Cambridge, MA, USA, 110–119
work page 1992
-
[17]
John R. Koza. 1992.Genetic programming: on the programming of computers by means of natural selection. MIT Press, Cambridge, MA, USA
work page 1992
-
[18]
Uriel López, Leonardo Trujillo, Yuliana Martinez, Pierrick Legrand, Enrique Naredo, and Sara Silva. 2017. RANSAC-GP: Dealing with Outliers in Symbolic Regression with Genetic Programming. InGenetic Programming, James McDer- mott, Mauro Castelli, Lukas Sekanina, Evert Haasdijk, and Pablo García-Sánchez (Eds.). Springer International Publishing, 114–130
work page 2017
- [19]
-
[20]
PeerJ Computer Science 3, e103 (Jan 2017).https://doi.org/10.7717/peerj-cs.103
Aaron Meurer, Christopher P. Smith, Mateusz Paprocki, Ondřej Čertík, Sergey B. Kirpichev, Matthew Rocklin, AMiT Kumar, Sergiu Ivanov, Jason K. Moore, Sar- taj Singh, Thilina Rathnayake, Sean Vig, Brian E. Granger, Richard P. Muller, Francesco Bonazzi, Harsh Gupta, Shivam Vats, Fredrik Johansson, Fabian Pe- dregosa, Matthew J. Curry, Andy R. Terrel, Štěpán...
-
[21]
2019.Fitting Redescending M-Estimators in Regression
Stephan Morgenthaler. 2019.Fitting Redescending M-Estimators in Regression. 105–128. doi:10.1201/9780203740538-5
-
[22]
Jean-Baptiste Mouret and Jeff Clune. 2015. Illuminating search spaces by mapping elites.ArXivabs/1504.04909 (2015). https://api.semanticscholar.org/CorpusID: 14759751
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[23]
Christine Müller. 2004. Redescending M-estimators in regression analysis, cluster analysis and image analysis.Discussiones Mathematicae. Probability and Statistics 24 (01 2004). doi:10.7151/dmps.1046
- [24]
-
[25]
Gloria Pietropolli, Federico Julian Camerota Verdù, Luca Manzoni, and Mauro Castelli. 2023. Parametrizing GP Trees for Better Symbolic Regression Perfor- mance through Gradient Descent. InProceedings of the Companion Conference on Genetic and Evolutionary Computation(Lisbon, Portugal)(GECCO ’23 Com- panion). Association for Computing Machinery, New York, ...
-
[26]
Peter Rousseeuw. 1984. Least Median of Squares Regression.Journal of The American Statistical Association - J AMER STATIST ASSN79 (12 1984), 871–880. doi:10.1080/01621459.1984.10477105
-
[27]
1987.Robust Regression and Outlier Detection
Peter Rousseeuw and Annick Leroy. 1987.Robust Regression and Outlier Detection. doi:10.2307/2289958
-
[28]
Michael Schmidt and Hod Lipson. 2009. Distilling Free-Form Nat- ural Laws from Experimental Data.Science324, 5923 (2009), 81–
work page 2009
-
[29]
arXiv:https://www.science.org/doi/pdf/10.1126/science.1165893 doi:10.1126/ science.1165893
-
[30]
Liron Simon Keren, Alex Liberzon, and Teddy Lazebnik. 2023. A computa- tional framework for physics-informed symbolic regression with straightfor- ward integration of domain knowledge.Scientific Reports13 (01 2023), 1249. doi:10.1038/s41598-023-28328-2
-
[31]
John Southworth. 2014. The DEBCat detached eclipsing binary catalogue. arXiv:1411.1219 [astro-ph.SR] https://arxiv.org/abs/1411.1219
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
Chenglu Sun, Shuo Shen, Wenzhi Tao, Deyi Xue, and Zixia Zhou. 2025. Noise- resilient symbolic regression with dynamic gating reinforcement learning. InProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelli- gence and Fifteenth Symposium on Educational Advanc...
-
[33]
Fayez Tarsha-Kurdi, Tania Landes, and Pierre Grussenmeyer. 2007. Hough- Transform and Extended RANSAC Algorithms for Automatic Detection of 3D Building Roof Planes from Lidar Data. https://api.semanticscholar.org/CorpusID: 893386
work page 2007
-
[34]
Nguyen Quang Uy, Nguyen Xuan Hoai, Michael O’Neill, R. I. McKay, and Edgar Galván-López. 2011. Semantically-based crossover in genetic programming: ap- plication to real-valued symbolic regression.Genetic Programming and Evolvable Machines12, 2 (2011), 91–119. doi:10.1007/s10710-010-9121-2
-
[35]
Changxin Wang, Yan Zhang, Cheng Wen, Mingli Yang, Turab Lookman, Yan- jing Su, and Tong-Yi Zhang. 2022. Symbolic regression in materials science via dimension-synchronous-computation.Journal of Materials Science and Technol- ogy122 (2022), 77–83. doi:10.1016/j.jmst.2021.12.052
-
[36]
Yiqun Wang, Nicholas Wagner, and James M. Rondinelli. 2019. Symbolic regression in materials science.MRS Communications9, 3 (2019), 793–805. doi:10.1557/mrc.2019.85
-
[37]
Shuwei Zhou, Bing Yang, Shou Xiao, Yang Guangwu, and Tao Zhu. 2023. Crack Growth Rate Model Derived from Domain Knowledge-Guided Symbolic Regres- sion.Chinese Journal of Mechanical Engineering36 (03 2023). doi:10.1186/s10033- 023-00876-8 GECCO ’26, July 13–17, 2026, San Jose, Costa Rica Ikeda et al. A Effectiveness of Robust Loss Functions against Outlier...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.