Weighted Conformal Clustering
Pith reviewed 2026-06-28 20:56 UTC · model grok-4.3
The pith
Weighted conformal clustering constructs valid confidence sets for cluster labels by correcting the mismatch between synthetic and latent labels using estimated probabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that conformal clustering can be recast as a conditional label-distribution shift problem; an oracle weighted procedure then attains finite-sample marginal coverage, while the implementable version that plugs in estimated conditional label probabilities and uses augmented calibration has coverage whose shortfall from the nominal level is bounded explicitly by the estimation error of those probabilities.
What carries the argument
Weighted conformal prediction under conditional label shift between synthetic clustering labels and latent target labels, with augmented calibration for the estimated-weight case
If this is right
- The oracle procedure attains finite-sample marginal coverage for the cluster labels.
- The estimated-weight procedure's coverage loss is bounded explicitly by the quality of the conditional probability estimator.
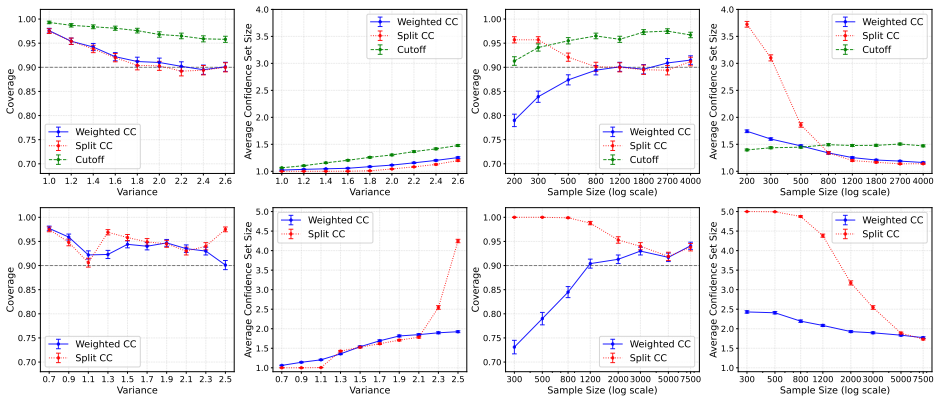
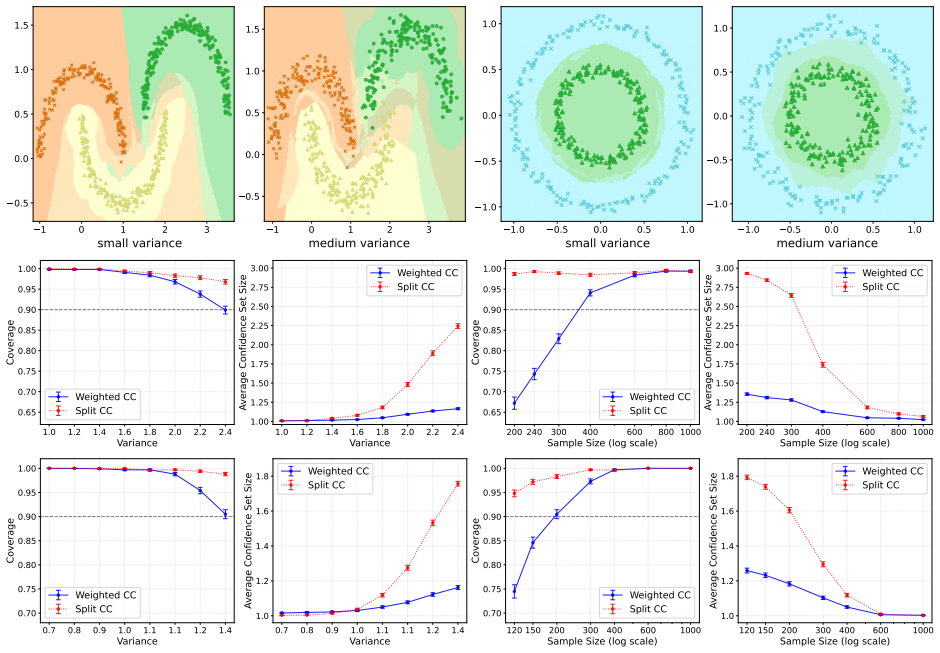
- The weighted method produces smaller, more informative confidence sets than split conformal clustering, particularly for nonlinear and high-dimensional data.
- The coverage guarantee holds for any clustering algorithm that produces the synthetic labels.
Where Pith is reading between the lines
- If the conditional probability estimator becomes consistent as sample size grows, the coverage of the estimated procedure approaches the nominal level.
- The same weighting idea could be applied to other unsupervised tasks that rely on data-dependent synthetic labels, such as community detection in networks.
- The bound on coverage loss supplies a practical diagnostic: poor coverage would indicate that the probability estimator needs improvement rather than that the conformal framework itself failed.
Load-bearing premise
Weights computed from estimated conditional label probabilities are sufficient to correct the mismatch between synthetic cluster labels and the latent target labels, and the resulting coverage shortfall remains bounded by the estimator's error.
What would settle it
A dataset or simulation in which the observed coverage deviates from the nominal level by more than the explicit bound supplied by the estimation error of the conditional label probabilities.
Figures
read the original abstract
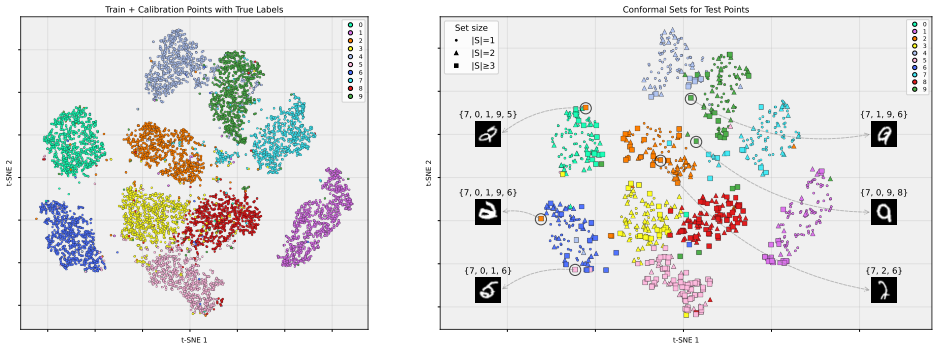
Clustering is a central tool for discovering latent structure in unlabeled data; yet modern clustering pipelines often end with a hard assignment of each observation to a cluster without rigorous measures of assignment uncertainty. We propose a novel weighted conformal approach for constructing valid confidence sets for cluster labels. The key difficulty is that the labels available for calibration are not observed ground-truth labels, but synthetic labels produced by a data-dependent clustering algorithm. Our method develops a conformal inference algorithm that corrects the resulting mismatch with the latent target labels through weights by formulating conformal clustering as a conditional label-distribution shift problem. We first derive an oracle procedure that attains finite-sample marginal coverage and then develop a computationally tractable and implementable version using estimated conditional label probabilities and novel augmented calibration. We show that the coverage of the estimated-weight procedure depends on the estimator, giving an explicit bound on the loss relative to the nominal level. Empirical studies demonstrate that the proposed weighted approach offers improvements over the recently proposed split conformal clustering procedure in terms of informative confidence set size, especially in nonlinear and high-dimensional clustering applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a weighted conformal inference procedure for constructing valid confidence sets around cluster labels. It formulates the problem as a conditional label-distribution shift between synthetic labels produced by a clustering algorithm and latent target labels, derives an oracle weighted procedure that attains finite-sample marginal coverage, and then provides a tractable estimated-weight version whose coverage loss relative to the nominal level is bounded explicitly in terms of the quality of the estimated conditional label probabilities. Empirical comparisons to split conformal clustering are reported on synthetic and real data, with emphasis on nonlinear and high-dimensional settings.
Significance. If the finite-sample coverage claims and the explicit loss bound hold, the work supplies a principled uncertainty quantification tool for clustering that directly addresses the synthetic-label mismatch; the oracle-to-estimated transition with a quantifiable degradation is a useful technical contribution in the conformal-prediction literature for unsupervised tasks.
minor comments (2)
- [Section 3 or 4 (estimated-weight procedure)] The abstract states that the estimated-weight coverage 'depends on the estimator, giving an explicit bound'; the main text should include the precise statement of this bound (including any constants or assumptions on the estimator) in a numbered theorem or proposition so that readers can verify the dependence without ambiguity.
- [Section 4] The description of the 'novel augmented calibration' step is mentioned only at a high level; a short algorithmic box or pseudocode would clarify how the augmentation interacts with the weighted nonconformity scores.
Simulated Author's Rebuttal
We thank the referee for their positive summary, recognition of the significance of the finite-sample coverage guarantees and explicit loss bound, and recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The described derivation begins with an oracle procedure attaining finite-sample marginal coverage under a formulated conditional label-distribution shift, then constructs an estimated-weight version whose coverage loss is bounded explicitly in terms of the quality of an external conditional label probability estimator. This structure treats the estimator as an independent input rather than a fitted quantity internal to the coverage claim itself. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided abstract or methodology outline. The central claims remain self-contained against external benchmarks of estimator accuracy.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Theoretical Foundations of Conformal Prediction
Anastasios N Angelopoulos, Rina Foygel Barber, and Stephen Bates. Theoretical foundations of conformal prediction.arXiv:2411.11824, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Testing for outliers with conformal p-values.The Annals of Statistics, 51(1):149–178, 2023
Stephen Bates, Emmanuel Cand` es, Lihua Lei, Yaniv Romano, and Matteo Sesia. Testing for outliers with conformal p-values.The Annals of Statistics, 51(1):149–178, 2023
2023
-
[3]
Deep clustering for unsupervised learning of visual features
Mathilde Caron, Piotr Bojanowski, Armand Joulin, and Matthijs Douze. Deep clustering for unsupervised learning of visual features. InProceedings of the European Conference on Computer Vision, 2018
2018
-
[4]
Selective inference for k-means clustering.Journal of Machine Learning Research, 24(152):1–41, 2023
Yiqun T Chen and Daniela M Witten. Selective inference for k-means clustering.Journal of Machine Learning Research, 24(152):1–41, 2023
2023
-
[5]
Conformal clustering and its application to botnet traffic
Giovanni Cherubin, Ilia Nouretdinov, Alexander Gammerman, Roberto Jordaney, Zhi Wang, Davide Papini, and Lorenzo Cavallaro. Conformal clustering and its application to botnet traffic. InInternational Symposium on Statistical Learning and Data Sciences, 2015
2015
-
[6]
Search algorithms and loss functions for Bayesian clustering.Journal of Computational and Graphical Statistics, 31(4):1189–1201, 2022
David B Dahl, Devin J Johnson, and Peter M¨ uller. Search algorithms and loss functions for Bayesian clustering.Journal of Computational and Graphical Statistics, 31(4):1189–1201, 2022
2022
-
[7]
Community detection in graphs.Physics Reports, 486(3-5):75–174, 2010
Santo Fortunato. Community detection in graphs.Physics Reports, 486(3-5):75–174, 2010
2010
-
[8]
Selective inference for hierarchical clustering
Lucy L Gao, Jacob Bien, and Daniela Witten. Selective inference for hierarchical clustering. Journal of the American Statistical Association, 119(545):332–342, 2024
2024
-
[9]
On the added value of bootstrap analysis for K-means clustering.Journal of Classification, 32(2):268–284, 2015
Joeri Hofmans, Eva Ceulemans, Douglas Steinley, and Iven Van Mechelen. On the added value of bootstrap analysis for K-means clustering.Journal of Classification, 32(2):268–284, 2015
2015
-
[10]
Statistical significance of clustering using soft thresholding.Journal of Computational and Graphical Statistics, 24(4):975–993, 2015
Hanwen Huang, Yufeng Liu, Ming Yuan, and JS Marron. Statistical significance of clustering using soft thresholding.Journal of Computational and Graphical Statistics, 24(4):975–993, 2015
2015
-
[11]
Inference for Clustering: Conformal Sets for Cluster Labels
YoonHaeng Hur, Anirban Nath, and Genevera Allen. Inference for clustering: Conformal sets for cluster labels.arXiv:2604.03488, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
M. K. Kerr and G. A. Churchill. Bootstrapping cluster analysis: Assessing the reliability of conclusions from microarray experiments.Proceedings of the National Academy of Sciences, 98(16):8961–8965, 2001
2001
-
[13]
A conformalized density-based clustering analysis of malicious traffic for botnet detection
Bahareh Mohammadi Kiani. A conformalized density-based clustering analysis of malicious traffic for botnet detection. InProceedings of the Ninth Symposium on Conformal and Proba- bilistic Prediction and Applications, 2020
2020
-
[14]
Statistical significance for hierarchical clustering.Biometrics, 73(3):811–821, 2017
Patrick K Kimes, Yufeng Liu, David Neil Hayes, and James Stephen Marron. Statistical significance for hierarchical clustering.Biometrics, 73(3):811–821, 2017. 12
2017
-
[15]
Challenges in unsupervised clustering of single-cell RNA-seq data.Nature Reviews Genetics, 20(5):273–282, 2019
Vladimir Yu Kiselev, Tallulah S Andrews, and Martin Hemberg. Challenges in unsupervised clustering of single-cell RNA-seq data.Nature Reviews Genetics, 20(5):273–282, 2019
2019
-
[16]
Full-conformal novelty detection
Junu Lee, Ilia Popov, and Zhimei Ren. Full-conformal novelty detection: A powerful and non-random approach.arXiv:2501.02703, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Classification with confidence.Biometrika, 101(4):755–769, 2014
Jing Lei. Classification with confidence.Biometrika, 101(4):755–769, 2014
2014
-
[18]
Distribution-free predictive inference for regression.Journal of the American Statistical Asso- ciation, 113(523):1094–1111, 2018
Jing Lei, Max G’Sell, Alessandro Rinaldo, Ryan J Tibshirani, and Larry Wasserman. Distribution-free predictive inference for regression.Journal of the American Statistical Asso- ciation, 113(523):1094–1111, 2018
2018
-
[19]
Ziyi Liang, Matteo Sesia, and Wenguang Sun. Integrative conformal p-values for out-of- distribution testing with labelled outliers.Journal of the Royal Statistical Society Series B: Statistical Methodology, 86(3):671–693, 2024
2024
-
[20]
Mechanisms to improve clustering un- certain data with UKmeans.Data & Knowledge Engineering, 116:1–18, 2018
Chuen-Ming Liu, Zhi-Ping Niu, and Kuan-Ting Liao. Mechanisms to improve clustering un- certain data with UKmeans.Data & Knowledge Engineering, 116:1–18, 2018
2018
-
[21]
Statistical sig- nificance of clustering for high-dimension, low-sample size data.Journal of the American Statistical Association, 103(483):1281–1293, 2008
Yufeng Liu, David Neil Hayes, Andrew Nobel, and James Stephen Marron. Statistical sig- nificance of clustering for high-dimension, low-sample size data.Journal of the American Statistical Association, 103(483):1281–1293, 2008
2008
-
[22]
Multi-level confor- mal clustering: A distribution-free technique for clustering and anomaly detection.Neurocom- puting, 397:279–291, 2020
Ilia Nouretdinov, James Gammerman, Matteo Fontana, and Daljit Rehal. Multi-level confor- mal clustering: A distribution-free technique for clustering and anomaly detection.Neurocom- puting, 397:279–291, 2020
2020
-
[23]
Distribution-free uncertainty quantification for classification under label shift
Aleksandr Podkopaev and Aaditya Ramdas. Distribution-free uncertainty quantification for classification under label shift. InUncertainty in Artificial Intelligence, 2021
2021
-
[24]
Cand` es
Yaniv Romano, Evan Patterson, and Emmanuel J. Cand` es. Conformalized quantile regression. InAdvances in Neural Information Processing Systems, 2019
2019
-
[25]
Classification with valid and adaptive coverage
Yaniv Romano, Matteo Sesia, and Emmanuel Cand` es. Classification with valid and adaptive coverage. InAdvances in Neural Information Processing Systems, 2020
2020
-
[26]
Least ambiguous set-valued classifiers with bounded error levels.Journal of the American Statistical Association, 114(525):223–234, 2019
Mauricio Sadinle, Jing Lei, and Larry Wasserman. Least ambiguous set-valued classifiers with bounded error levels.Journal of the American Statistical Association, 114(525):223–234, 2019
2019
-
[27]
Statistical significance of clustering with multi- dimensional scaling.Journal of Computational and Graphical Statistics, 33(1):219–230, 2024
Hui Shen, Shankar Bhamidi, and Yufeng Liu. Statistical significance of clustering with multi- dimensional scaling.Journal of Computational and Graphical Statistics, 33(1):219–230, 2024
2024
-
[28]
PAC prediction sets under label shift.arXiv:2310.12964, 2023
Wenwen Si, Sangdon Park, Insup Lee, Edgar Dobriban, and Osbert Bastani. PAC prediction sets under label shift.arXiv:2310.12964, 2023
-
[29]
Conformal prediction under covariate shift
Ryan J Tibshirani, Rina Foygel Barber, Emmanuel Cand` es, and Aaditya Ramdas. Conformal prediction under covariate shift. InAdvances in Neural Information Processing Systems, 2019
2019
-
[30]
Springer, 2005
Vladimir Vovk, Alexander Gammerman, and Glenn Shafer.Algorithmic Learning in a Random World. Springer, 2005
2005
-
[31]
Bayesian cluster analysis: Point estimation and credible balls (with discussion).Bayesian Analysis, 13(2):559–626, 2018
Sara Wade and Zoubin Ghahramani. Bayesian cluster analysis: Point estimation and credible balls (with discussion).Bayesian Analysis, 13(2):559–626, 2018. 13
2018
-
[32]
Unsupervised deep embedding for clustering analysis
Junyuan Xie, Ross Girshick, and Ali Farhadi. Unsupervised deep embedding for clustering analysis. InInternational Conference on Machine Learning, 2016
2016
-
[33]
Selective inference for clustering with unknown variance.Electronic Journal of Statistics, 17(2):1923–1946, 2023
Young-Joo Yun and Rina Foygel Barber. Selective inference for clustering with unknown variance.Electronic Journal of Statistics, 17(2):1923–1946, 2023
1923
-
[34]
A comprehensive survey on deep clustering: Taxonomy, challenges, and future directions.ACM Computing Surveys, 57(3):1–38, 2024
Sheng Zhou, Hongjia Xu, Zhuonan Zheng, Jiawei Chen, Zhao Li, Jiajun Bu, Jia Wu, Xin Wang, Wenwu Zhu, and Martin Ester. A comprehensive survey on deep clustering: Taxonomy, challenges, and future directions.ACM Computing Surveys, 57(3):1–38, 2024. A Theory of Weighted Conformal Prediction Definition 2.For any measureµonR, letQ τ(µ) be theτ-th quantile ofµd...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.