An Open-Source Training Dataset for Foundation Models for Black-box Optimization
Pith reviewed 2026-05-25 04:52 UTC · model grok-4.3
The pith
Foundation models trained on a new open dataset of 500K optimization trajectories can imitate black-box optimization methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
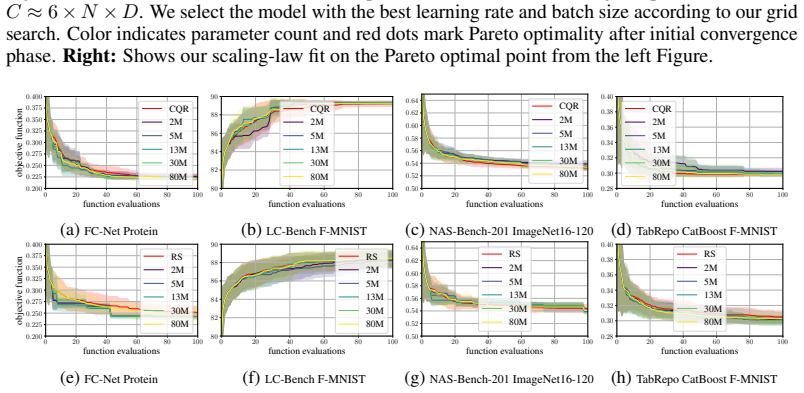
We introduce BBO-Pile, the first open-source dataset comprising over 500K optimization trajectories evaluated across 3095 different black-boxes for different optimizers, which represents by far the largest public dataset for this task. Using this dataset, we train a family of foundation models at multiple scales, ranging from 2M to 80M parameters and from 200M to 2B training tokens, and study their scaling behavior with respect to compute. Our results demonstrate that large-scale pre-training is a viable and effective approach to imitate black-box optimization methods, paving the way for future research in this direction.
What carries the argument
BBO-Pile, the dataset of optimization trajectories that serves as training data for scaling foundation models to imitate optimizers.
If this is right
- Large-scale pre-training on optimization trajectories produces models that imitate black-box methods.
- Scaling behavior can be studied as model size and token count increase up to 80M parameters and 2B tokens.
- The public release of the dataset enables reproducible research on foundation models for optimization.
- Models trained this way have the potential to generalize across different problem classes without manual hyperparameter tuning.
Where Pith is reading between the lines
- These models could be applied to new optimization domains where traditional methods require significant tuning.
- Future work might combine this dataset with synthetic data to further improve generalization.
- Performance on real-world black-box problems could be tested to validate transfer from the training distribution.
Load-bearing premise
The 500K trajectories from the 3095 black-boxes and chosen optimizers provide a representative sample allowing models to learn generalizable optimization principles that transfer to unseen problems.
What would settle it
Train the models on BBO-Pile and test them on a collection of black-box problems completely outside the dataset; if the models do not perform competitively with tuned traditional optimizers, the viability of the pre-training approach would be questioned.
Figures


















read the original abstract
Most black-box optimization methods require extensive hyperparameter tuning, often limiting their ability to generalize across different optimization domains. Foundation models for black-box optimization that learn optimization principles from a large collection of optimization trajectories offer a promising alternative, with the potential to outperform manually designed methods across diverse problem classes. However, prior work has either relied on non-public datasets or on purely synthetic data, limiting reproducibility and generalization to real-world problems. As a result, progress in this area has been constrained by the lack of large-scale, real-world, publicly available pre-training data. We introduce BBO-Pile, the first open-source dataset comprising over 500K optimization trajectories evaluated across 3095 different black-boxes for different optimizers, which represents by far the largest public dataset for this task. Using this dataset, we train a family of foundation models at multiple scales, ranging from 2M to 80M parameters and from 200M to 2B training tokens, and study their scaling behavior with respect to compute. Our results demonstrate that large-scale pre-training is a viable and effective approach to imitate black-box optimization methods, paving the way for future research in this direction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BBO-Pile, an open-source dataset containing over 500K optimization trajectories collected from 3095 black-box functions using multiple optimizers. It trains a family of foundation models (2M–80M parameters, 200M–2B tokens) on this data, analyzes scaling behavior with respect to compute, and concludes that large-scale pre-training is a viable and effective approach to imitate black-box optimization methods.
Significance. If the dataset is shown to be sufficiently diverse and the trained models demonstrate transfer to unseen problems and optimizers, the work would provide a valuable public resource that could accelerate research on learned optimizers, similar to the role of large pre-training corpora in other domains. The open release directly addresses reproducibility barriers noted in prior work.
major comments (2)
- [§3 and §4] §3 (Dataset Construction) and §4 (Data Collection): No quantitative diversity metrics are reported for the 3095 black-boxes (e.g., histograms or coverage statistics over dimensionality, modality, noise level, or degree of multimodality). Without these, it is impossible to verify that the 500K trajectories support extraction of generalizable optimization principles rather than dataset-specific heuristics, which is load-bearing for the central claim of viability for imitating BBO methods.
- [§5] §5 (Experiments and Scaling): The evaluation does not include explicit held-out splits on unseen problem classes or optimizers with reported transfer metrics (e.g., regret or success rate on out-of-distribution instances). Scaling curves alone cannot distinguish memorization from genuine imitation of general BBO strategies.
minor comments (2)
- [Abstract] The abstract states trajectories were collected 'for different optimizers' but does not list the specific optimizers or their hyperparameter settings used in data generation.
- [Figures/Tables in §5] Table or figure captions for scaling results should explicitly state the number of held-out black-boxes and whether they were drawn from the same distribution as the training set.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments on dataset diversity and held-out evaluation are well-taken and will be addressed through additional analysis in the revision.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Dataset Construction) and §4 (Data Collection): No quantitative diversity metrics are reported for the 3095 black-boxes (e.g., histograms or coverage statistics over dimensionality, modality, noise level, or degree of multimodality). Without these, it is impossible to verify that the 500K trajectories support extraction of generalizable optimization principles rather than dataset-specific heuristics, which is load-bearing for the central claim of viability for imitating BBO methods.
Authors: We agree that quantitative diversity metrics would strengthen the manuscript and help substantiate the generalizability of the trajectories. In the revised version we will add histograms and coverage statistics over dimensionality, modality, noise level, and degree of multimodality for the 3095 black-box functions. These additions will directly support the claim that the dataset enables extraction of general optimization principles. revision: yes
-
Referee: [§5] §5 (Experiments and Scaling): The evaluation does not include explicit held-out splits on unseen problem classes or optimizers with reported transfer metrics (e.g., regret or success rate on out-of-distribution instances). Scaling curves alone cannot distinguish memorization from genuine imitation of general BBO strategies.
Authors: We acknowledge that explicit held-out splits and transfer metrics are necessary to distinguish memorization from genuine imitation. While the present experiments focus on scaling behavior, the revised manuscript will include held-out splits on unseen problem classes and optimizers together with reported transfer metrics (regret and success rate) on out-of-distribution instances. revision: yes
Circularity Check
No circularity; empirical dataset release and scaling study is self-contained
full rationale
The paper introduces BBO-Pile, a new public dataset of 500K trajectories across 3095 black-boxes, then trains models at multiple scales and reports scaling behavior. No equations, fitted parameters, or derivations appear in the provided text. The central claim—that large-scale pre-training imitates black-box optimization—is supported by new empirical data collection and training runs rather than any reduction to prior fitted values, self-definitions, or self-citation chains. The work contains no load-bearing mathematical steps that could be circular by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
V . Aglietti, I. Ktena, J. Schrouff, E. Sgouritsa, F. J. R. Ruiz, A. Malek, A. Bellot, and S. Chi- appa. FunBO: Discovering acquisition functions for Bayesian optimization with funsearch. arXiv:2406.04824 [cs.LG], 2025
-
[2]
M. Andrychowicz, M. Denil, S. Gomez, M. W. Hoffman, D. Pfau, T. Schaul, B. Shillingford, and N. de Freitas. Learning to learn by gradient descent by gradient descent. InProceedings of the 29th International Conference on Advances in Neural Information Processing Systems (NeurIPS’16), 2016
work page 2016
-
[3]
A. F. Ansari, L. Stella, A. C. Turkmen, X. Zhang, P. Mercado, H. Shen, O. Shchur, S. S. Rangapuram, S. P. Arango, S. Kapoor, J. Zschiegner, D. C. Maddix, H. Wang, M. W. Mahoney, K. Torkkola, A. G. Wilson, M. Bohlke-Schneider, and B. Wang. Chronos: Learning the language of time series.Transactions on Machine Learning Research, 2024
work page 2024
-
[4]
S. P. Arango, H. Jomaa, M. Wistuba, and J. Grabocka. HPO-B: A large-scale reproducible benchmark for black-box hpo based on openml. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS’21), 2021
work page 2021
-
[5]
J. Bergstra, R. Bardenet, Y . Bengio, and B. Kégl. Algorithms for hyper-parameter optimization. InProceedings of the 24th International Conference on Advances in Neural Information Processing Systems (NeurIPS’11), 2011
work page 2011
-
[6]
J. Bergstra and Y . Bengio. Random search for hyper-parameter optimization.Journal of Machine Learning Research (JMLR-12), 2012
work page 2012
- [7]
-
[8]
R. Calandra, N. Gopalan, A. Seyfarth, J. Peters, and M. Deisenroth. Bayesian gait optimization for bipedal locomotion. InProceedings of the Eighth International Conference on Learning and Intelligent Optimization (LION’14), 2014
work page 2014
-
[9]
Y . Chen, M. W. Hoffman, S. G. Colmenarejo, M. Denil, T. P. Lillicrap, M. Botvinick, and N. de Freitas. Learning to learn without gradient descent by gradient descent. InProceedings of the 34th International Conference on Machine Learning (ICML’17), 2017. 10
work page 2017
-
[10]
Y . Chen, X. Song, C. Lee, Z. Wang, Q. Zhang, D. Dohan, K. Kawakami, G. Kochanski, A. Doucet, M. A. Ranzato, S. Perel, and N. de Freitas. Towards learning universal hyperpa- rameter optimizers with transformers. InProceedings of the 36th International Conference on Advances in Neural Information Processing Systems (NeurIPS’22), 2022
work page 2022
- [11]
- [12]
-
[13]
X. Dong and Y . Yang. Nas-bench-201: Extending the scope of reproducible neural architecture search. InInternational Conference on Learning Representations (ICLR’20), 2020
work page 2020
-
[14]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR’21), 2021
work page 2021
-
[15]
K. Eggensperger, F. Hutter, H. Hoos, and K. Leyton-Brown. Efficient benchmarking of hyperpa- rameter optimizers via surrogates. InProceedings of the 29th National Conference on Artificial Intelligence (AAAI’15), 2015
work page 2015
-
[16]
K. Eggensperger, P. Müller, N. Mallik, M. Feurer, R. Sass, A. Klein, N. Awad, M. Lindauer, and F. Hutter. HPOBench: A collection of reproducible multi-fidelity benchmark problems for HPO. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS’21), 2021
work page 2021
-
[17]
R. Garnett.Bayesian Optimization. Cambridge University Press, 2023
work page 2023
-
[18]
R. Gómez-Bombarelli, J. N. Wei, D. Duvenaud, J. M. Hernández-Lobato, B. Sánchez-Lengeling, D. Sheberla, J. Aguilera-Iparraguirre, T. D. Hirzel, R. P. Adams, and A. Aspuru-Guzik. Auto- matic chemical design using a data-driven continuous representation of molecules.ACS Central Science, 2018
work page 2018
-
[19]
N. Hansen. The CMA evolution strategy: a comparing review. InTowards a new evolutionary computation. Advances on estimation of distribution algorithms. Springer Berlin Heidelberg, 2006
work page 2006
- [20]
- [21]
-
[22]
Training Compute-Optimal Large Language Models
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. van den Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, J. W. Rae, O. Vinyals, and L. Sifre. Training compute-optimal large language models.arXiv:2203.15556 [cs.CL], 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
N. Hollmann, S. Müller, K. Eggensperger, and F. Hutter. TabPFN: A transformer that solves small tabular classification problems in a second. InInternational Conference on Learning Representations (ICLR’23), 20223
-
[24]
N. Hollmann, S. Müller, L. Purucker, A. Krishnakumar, M. Körfer, S. B. Hoo, R. T. Schirrmeis- ter, and F. Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 2025
work page 2025
- [25]
-
[26]
D. R. Jones. A taxonomy of global optimization methods based on response surfaces.Journal of Global Optimization, 2001
work page 2001
-
[27]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. Scaling laws for neural language models.arXiv:2001.08361 [cs.LG], 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
- [28]
-
[29]
Tabular Benchmarks for Joint Architecture and Hyperparameter Optimization
A. Klein and F. Hutter. Tabular benchmarks for joint architecture and hyperparameter optimiza- tion.arXiv:1905.04970 [cs.LG], 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[30]
A. Krishnamurthy, K. Harris, D. J. Foster, C. Zhang, and A. Slivkins. Can large language models explore in-context? InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track (NeurIPS’24), 2024
work page 2024
- [31]
-
[32]
Litgpt.https://github.com/Lightning-AI/litgpt, 2023
Lightning-AI. Litgpt.https://github.com/Lightning-AI/litgpt, 2023
work page 2023
-
[33]
T. Liu, N. Astorga, N. Seedat, and M. van der Schaar. Large language models to enhance Bayesian optimization. InThe Twelfth International Conference on Learning Representations (ICLR’24), 2024
work page 2024
-
[34]
I. Loshchilov and F. Hutter. SGDR: Stochastic gradient descent with warm restarts. In International Conference on Learning Representations (ICLR’17), 2017
work page 2017
- [35]
-
[36]
V . Perrone, H. Shen, M. Seeger, C. Archambeau, and R. Jenatton. Learning search spaces for bayesian optimization: Another view of hyperparameter transfer learning. InProceedings of the 32th International Conference on Advances in Neural Information Processing Systems (NeurIPS’19), 2019
work page 2019
-
[37]
F. Pfisterer, L. Schneider, J. Moosbauer, M. Binder, and B. Bischl. Yahpo gym - an efficient multi-objective multi-fidelity benchmark for hyperparameter optimization. InFirst Conference on Automated Machine Learning (Main Track), 2022
work page 2022
-
[38]
E. Real, A. Aggarwal, Y . Huang, and Q. V . Le. Regularized Evolution for Image Classifier Architecture Search. InProceedings of the Conference on Artificial Intelligence (AAAI’19), 2019
work page 2019
-
[39]
D. Salinas and N. Erickson. Tabrepo: A large scale repository of tabular model evaluations and its automl applications.arXiv preprint arXiv:2311.02971, 2023
-
[40]
D. Salinas, V . Flunkert, J. Gasthaus, and T. Januschowski. Deepar: Probabilistic forecasting with autoregressive recurrent networks.International journal of forecasting, 2020
work page 2020
-
[41]
D. Salinas, J. Golebiowsk, A. Klein, M. Seeger, and C. Archambeau. Optimizing hyperparame- ters with conformal quantile regression. InProceedings of the 40th International Conference on Machine Learning (ICML’23), 2023
work page 2023
-
[42]
D. Salinas, M. Seeger, A. Klein, V . Perrone, M. Wistuba, and C. Archambeau. Syne tune: A library for large scale hyperparameter tuning and reproducible research. InFirst Conference on Automated Machine Learning (Main Track), 2022
work page 2022
-
[43]
D. Salinas, H. Shen, and V . Perrone. A quantile-based approach for hyperparameter transfer learning. InProceedings of the 37th International Conference on Machine Learning (ICML’20), 2020. 12
work page 2020
-
[44]
J. Schmidhuber. Evolutionary principles in self-referential learning, or on learning how to learn: The meta-meta-... hook
-
[45]
A. Schwanke, L. Ivanov, D. Salinas, F. Ferreira, A. Klein, F. Hutter, and A. Zela. Improving llm-based global optimization with search space partitioning. InInternational Conference on Learning Representations (ICLR’26), 2026
work page 2026
-
[46]
R. Sennrich, B. Haddow, and A. Birch. Neural machine translation of rare words with subword units. InProceedings of the 54th annual meeting of the association for computational linguistics (volume 1: long papers), 2016
work page 2016
-
[47]
X. Song, Y . Tian, R. T. Lange, C. Lee, Y . Tang, and Y . Chen. Position: Leverage foundational models for black-box optimization. InProceedings of the Forty-first International Conference on Machine Learning (ICML’24), 2024
work page 2024
-
[48]
J. T. Springenberg, A. Klein, S. Falkner, and F. Hutter. Bayesian optimization with robust Bayesian neural networks. InProceedings of the 29th International Conference on Advances in Neural Information Processing Systems (NeurIPS’16), 2016
work page 2016
-
[49]
R. Storn and K. Price. Differential evolution – a simple and efficient heuristic for global optimization over continuous spaces.Journal of Global Optimization, 1997
work page 1997
-
[50]
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomput., 568(C), Feb. 2024
work page 2024
-
[51]
Talbi.Metaheuristics: from design to implementation
E.-G. Talbi.Metaheuristics: from design to implementation. John Wiley & Sons, 2009
work page 2009
-
[52]
L. C. Tiao, A. Klein, M. W. Seeger, E. V . Bonilla, C. Archambeau, and F. Ramos. Bore: Bayesian optimization by density-ratio estimation. InProceedings of the 38th International Conference on Machine Learning (ICML’21), 2021
work page 2021
-
[53]
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS’12), 2012
work page 2012
-
[54]
N. van Stein and T. Bäck. Llamea: Automatically generating metaheuristics with large language models. InProceedings of the Genetic and Evolutionary Computation Conference Companion (GECCO’25), 2025
work page 2025
-
[55]
P. Veliˇckovi´c, A. Vitvitskyi, L. Markeeva, B. Ibarz, L. Buesing, M. Balog, and A. Novikov. Amplifying human performance in combinatorial competitive programming.arXiv:2411.19744 [cs.LG], 2024
-
[56]
Z. Wang, G. E. Dahl, K. Swersky, C. Lee, Z. Nado, J. Gilmer, J. Snoek, and Z. Ghahramani. Pre- trained Gaussian processes for Bayesian optimization.Journal of Machine Learning Research (JMLR’24), 2024
work page 2024
-
[57]
M. Wistuba, N. Schilling, and L. Schmidt-Thieme. Learning hyperparameter optimization initializations. InIEEE International Conference on Data Science and Advanced Analytics (DSAA), 2015
work page 2015
-
[58]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
work page 2025
-
[59]
L. Zimmer, M. Lindauer, and F. Hutter. Auto-pytorch tabular: Multi-fidelity metalearning for efficient and robust autodl.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021. 13 A Benchmark Families We consider the following benchmark families from the literature: • FC-Net[ 29]: Considers the optimization of the hyperparameters and archite...
work page 2021
-
[60]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.