Riemannian Gradient Descent for Low-Rank Architectures
Pith reviewed 2026-06-28 15:58 UTC · model grok-4.3
The pith
Riemannian optimization on rank-factored attention parameters does not conclusively outperform AdamW after learning-rate tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
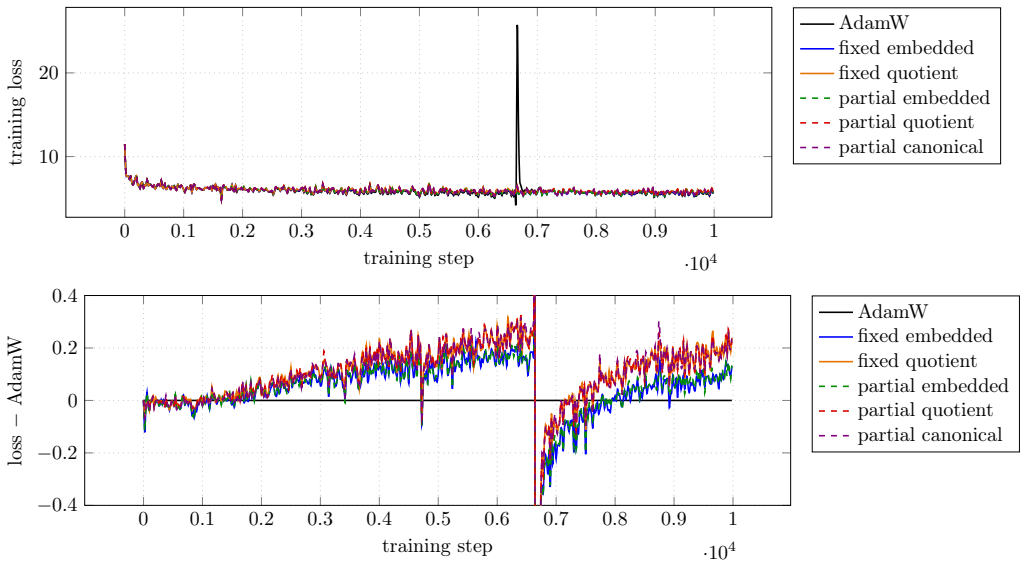
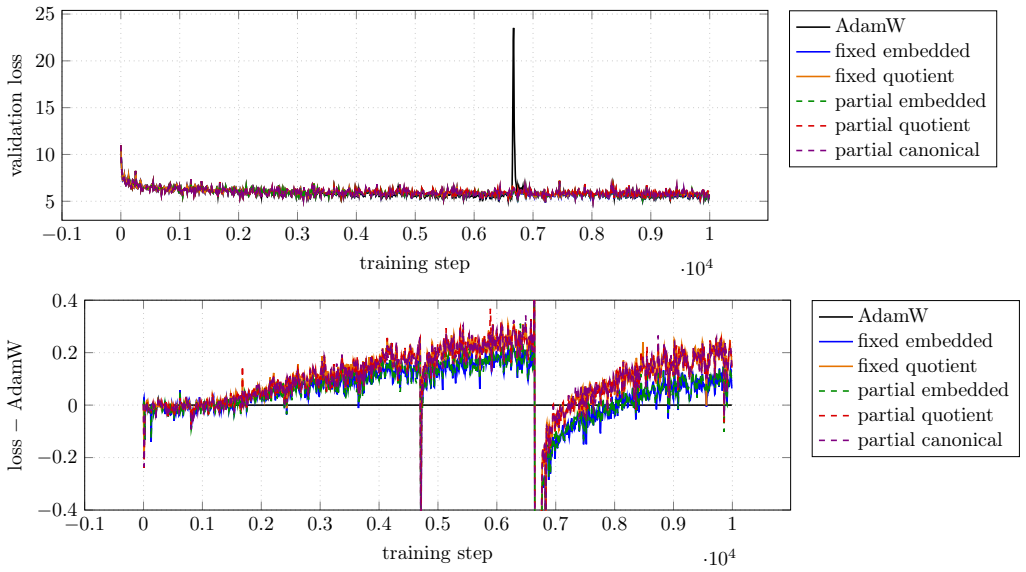
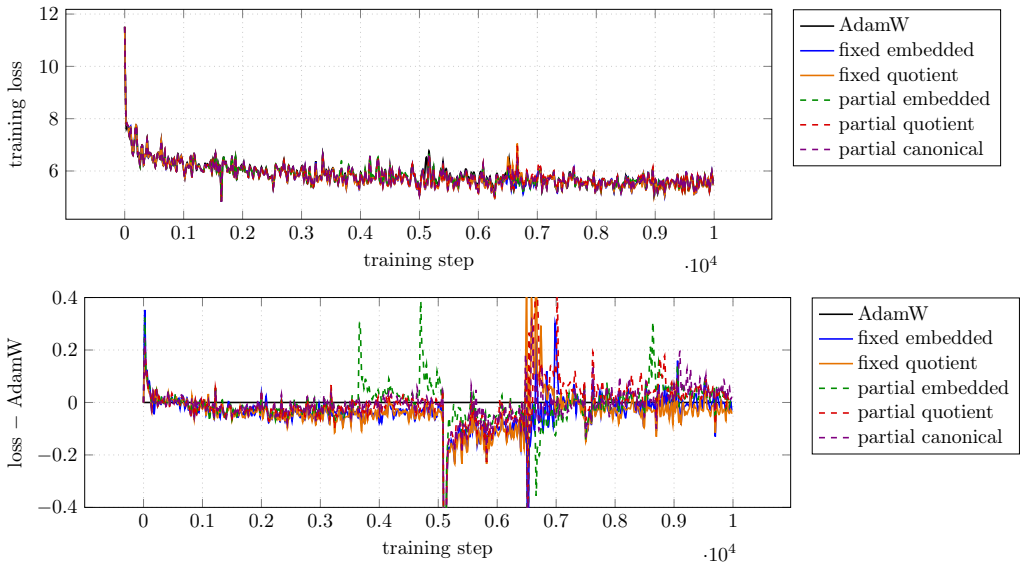
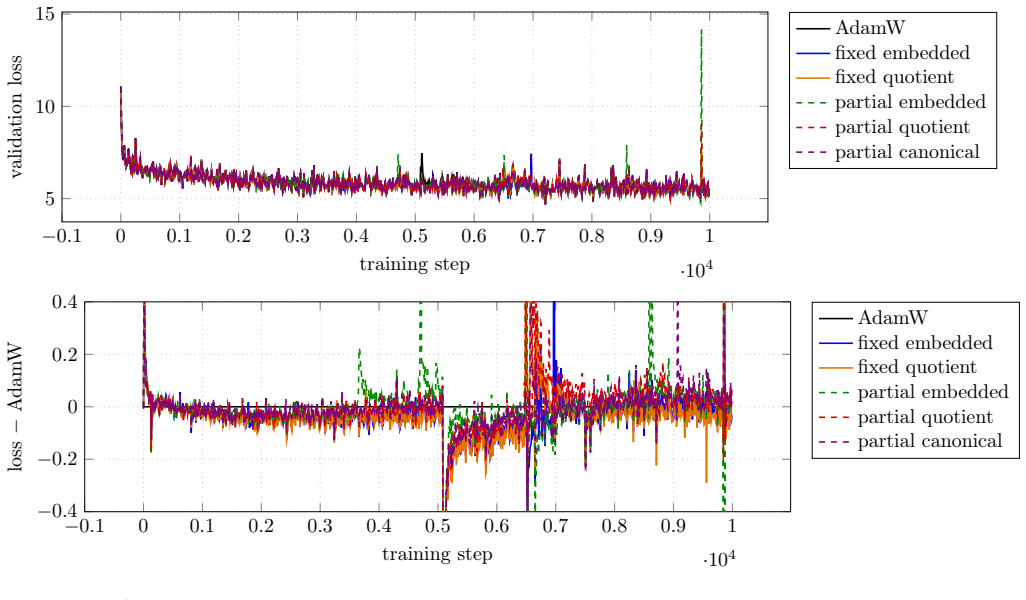
Experiments on small language models demonstrate that ten Riemannian geometries applied to rank-factored attention parameters do not produce conclusive improvements over a tuned AdamW optimizer.
What carries the argument
Riemannian geometries on the manifolds of rank-r matrices and rank-r partial isometries, extended to block-matrix factorizations with shared rows and columns.
If this is right
- AdamW remains competitive for low-rank attention parameters once learning rates are tuned.
- Differences among the ten Riemannian geometries do not translate into measurable gains in the tested setting.
- Shared-factor block-matrix variants offer no additional advantage over the simpler non-block versions.
Where Pith is reading between the lines
- The negative finding could shift if the same methods were tested on substantially larger models or different tasks.
- Alternative tuning protocols that optimize more hyperparameters than learning rate alone might alter the comparison.
- Riemannian methods might still prove useful for other low-rank parameter structures outside attention layers.
Load-bearing premise
The chosen small language models, attention layers, and learning-rate tuning protocol constitute a representative and fair test of whether Riemannian methods can outperform AdamW on rank-factored parameters.
What would settle it
An experiment on the same models that finds one Riemannian variant reaching lower validation loss than AdamW under matched tuning effort would falsify the central result.
Figures
read the original abstract
We explore Riemannian optimization techniques for rank-factored matrix parameters, targeting contemporary deep learning applications. We examine ten points in the algorithm design space: two geometries for rank-$r$ matrices, three geometries for rank-$r$ partial isometries, and block-matrix variants of these five, where factors are shared across block-rows and block-columns. We apply our methods to the multihead attention parameters in small language models. After tuning learning rates, our methods do not conclusively outperform an AdamW baseline. Our implementations are available online.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper explores Riemannian optimization for rank-factored matrix parameters in deep learning. It examines ten algorithm variants (two geometries on rank-r matrices, three on rank-r partial isometries, and block-matrix versions of each) and applies them to multi-head attention parameters in small language models. After learning-rate tuning the Riemannian methods do not conclusively outperform an AdamW baseline; code is released.
Significance. If the negative result is robust, it indicates that these Riemannian geometries do not yield practical gains over AdamW on low-rank attention factors under standard tuning, which could steer research toward other directions or more sophisticated integration of manifold constraints. Releasing implementations is a clear strength that supports direct verification.
minor comments (3)
- [Abstract] The abstract and introduction should state the model sizes (e.g., number of layers, hidden dimension) and the precise attention weight matrices that were factorized.
- [Experiments] The experimental section should report the number of random seeds, the exact LR grid searched for each method, and any statistical test used to support the claim of 'no conclusive outperformance'.
- [Method] Notation for the ten geometries (e.g., how the block-matrix variants differ from the non-block versions) should be introduced with a short table or diagram for clarity.
Simulated Author's Rebuttal
We thank the referee for their review and for recommending minor revision. The referee's summary accurately reflects the scope of our work (ten algorithm variants across two geometries for rank-r matrices, three for partial isometries, and their block-matrix extensions) and our main empirical finding that, after learning-rate tuning on small language-model attention layers, the Riemannian methods do not yield conclusive gains over AdamW. We also appreciate the recognition that releasing the implementations is a strength.
Circularity Check
No significant circularity identified
full rationale
The manuscript is an empirical comparison of ten Riemannian optimization variants against an AdamW baseline on multi-head attention parameters in small language models. It reports a negative result after learning-rate tuning and supplies code, with no mathematical derivation chain, self-referential definitions, fitted inputs presented as predictions, or load-bearing self-citations. The central claim is a transparent experimental outcome within the stated scope and is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Two Newton methods on the manifold of fixed-rank matrices endowed with Riemannian quotient geometries
P.-A. Absil, L. Amodei, and G. Meyer. “Two Newton methods on the manifold of fixed-rank matrices endowed with Riemannian quotient geometries”.Computational Statistics29.3 (2014), pp. 569–590
2014
-
[2]
Absil, R
P.-A. Absil, R. Mahony, and R. Sepulchre.Optimization Algorithms on Matrix Manifolds. Princeton University Press, 2007
2007
-
[3]
Projection-like retractions on matrix manifolds
P.-A. Absil and J. Malick. “Projection-like retractions on matrix manifolds”.SIAM Journal on Opti- mization22.1 (2012), pp. 135–158
2012
-
[4]
Low-rank retractions: A survey and new results
P.-A. Absil and I. V. Oseledets. “Low-rank retractions: A survey and new results”.Computational Optimization and Applications62.1 (2015), pp. 5–29
2015
-
[5]
GQA: Training generalized multi-query Transformer models from multi-head checkpoints
J. Ainslie, J. Lee-Thorp, M. de Jong, Y. Zemlyanskiy, F. Lebrón, and S. Sanghai. “GQA: Training generalized multi-query Transformer models from multi-head checkpoints”.Proc. EMNLP’23. 2023, pp. 4895–4901
2023
-
[6]
Old optimizer, new norm: An anthology
J. Bernstein and L. Newhouse. “Old optimizer, new norm: An anthology”.Proc. OPT’24. 2024, pp. 1– 19
2024
-
[9]
The method of steepest descent for non-linear minimization problems
H. B. Curry. “The method of steepest descent for non-linear minimization problems”.Quarterly of Applied Mathematics2.3 (1944), pp. 258–261
1944
-
[10]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-AI. “DeepSeek-V2: A strong, economical, and efficient mixture-of-experts language model”. arXiv:2405.04434. 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
The geometry of algorithms with orthogonality constraints
A. Edelman, T. A. Arias, and S. T. Smith. “The geometry of algorithms with orthogonality constraints”. SIAM Journal on Matrix Analysis and Applications20.2 (1998), pp. 303–353
1998
-
[12]
LatentMoE: Toward optimal accuracy per FLOP and parameter in mixture of experts
V. Elango, N. Bhatia, R. Waleffe, R. Shafipour, T. Asida, A. Khattar, N. Assaf, M. Golub, J. Guman, T. Mitra, R. Zhao, R. Borkar, R. Zilberstein, M. Patwary, M. Shoeybi, and B. Rouhani. “LatentMoE: Toward optimal accuracy per FLOP and parameter in mixture of experts”. arXiv:2601.18089. 2026
-
[13]
A Riemannian rank-adaptive method for low-rank matrix completion
B. Gao and P.-A. Absil. “A Riemannian rank-adaptive method for low-rank matrix completion”.Com- putational Optimization and Applications81.1 (2022), pp. 67–90
2022
-
[14]
G. H. Golub and C. F. Van Loan.Matrix Computations (4th ed.)Johns Hopkins University, 2013
2013
-
[15]
Mamba:Linear-timesequencemodelingwithselectivestatespaces
A.GuandT.Dao.“Mamba:Linear-timesequencemodelingwithselectivestatespaces”.Proc. COLM’24. 2024
2024
-
[16]
Helmke and J
U. Helmke and J. B. Moore.Optimization and Dynamical Systems. Springer, 1996
1996
-
[17]
Query-key normalization for Transformers
A. Henry, P. R. Dachapally, S. S. Pawar, and Y. Chen. “Query-key normalization for Transformers”. Proc. EMNLP’20. 2020, pp. 4246–4253
2020
-
[18]
Muon: An optimizer for hidden layers in neural networks
K. Jordan, Y. Jin, V. Boza, J. You, F. Cesista, L. Newhouse, and J. Bernstein. “Muon: An optimizer for hidden layers in neural networks”. 2024.url:https://kellerjordan.github.io/posts/muon/
2024
-
[19]
Better theory for SGD in the nonconvex world
A. Khaled and P. Richtárik. “Better theory for SGD in the nonconvex world”.Transactions on Machine Learning Research(2023)
2023
-
[20]
Tucker attention: A generalization of approximate attention mechanisms
T. Klein, J. Kusch, S. Sager, S. Schnake, and S. Schotthöfer. “Tucker attention: A generalization of approximate attention mechanisms”. arXiv:2603.30033. 2026
-
[21]
Toward Optimization on Varieties
E. Levin. “Toward Optimization on Varieties”. Undergraduate senior thesis. Princeton University, 2020
2020
-
[22]
Finding stationary points on bounded-rank matrices: A geometric hurdle and smooth remedy
E. Levin, J. Kileel, and N. Boumal. “Finding stationary points on bounded-rank matrices: A geometric hurdle and smooth remedy”.Mathematical Programming199.1 (2022), pp. 831–864
2022
-
[23]
Efficient Riemannian optimization on the Stiefel manifold via the Cayley transform
J. Li, F. Li, and S. Todorovic. “Efficient Riemannian optimization on the Stiefel manifold via the Cayley transform”.Proc. ICLR’20. 2020. 18
2020
-
[24]
MoLAE: Mixture of latent experts for parameter-efficient language models
Z. Liu, H. Wu, R. She, X. Fu, X. Han, T. Zhong, and M. Yuan. “MoLAE: Mixture of latent experts for parameter-efficient language models”. arXiv:2503.23100. 2025
-
[25]
Decoupled weight decay regularization
I. Loshchilov and F. Hutter. “Decoupled weight decay regularization”.Proc. ICLR’19. 2019
2019
-
[26]
From subspace learning to distance learning: A geometrical optimization approach
G. Meyer, M. Journée, S. Bonnabel, and R. Sepulchre. “From subspace learning to distance learning: A geometrical optimization approach”.Proc. IEEE SSP’09. 2009, pp. 385–388
2009
-
[27]
A Riemannian geometry for low-rank matrix completion
B. Mishra, K. Adithya Apuroop, and R. Sepulchre. “A Riemannian geometry for low-rank matrix completion”. arXiv:1211.1550. 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[28]
Fixed-rankmatrixfactorizationsandRiemannian low-rank optimization
B.Mishra,G.Meyer,S.Bonnabel,andR.Sepulchre.“Fixed-rankmatrixfactorizationsandRiemannian low-rank optimization”.Computational Statistics29.3 (2014), pp. 591–621
2014
-
[29]
A Newton-like method for solving rank constrained linear matrix inequalities
R. Orsi, U. Helmke, and J. B. Moore. “A Newton-like method for solving rank constrained linear matrix inequalities”.Automatica42.11 (2006), pp. 1875–1882
2006
-
[30]
Tensor methods in computer vision and deep learning
Y. Panagakis, J. Kossaifi, G. G. Chrysos, J. Oldfield, M. A. Nicolaou, A. Anandkumar, and S. Zafeiriou. “Tensor methods in computer vision and deep learning”.Proceedings of the IEEE109.5 (2021), pp. 863– 890
2021
-
[31]
The FineWeb datasets: Decanting the Web for the finest text data at scale
G. Penedo, H. Kydlíček, L. Ben allal, A. Lozhkov, M. Mitchell, C. Raffel, L. Von Werra, and T. Wolf. “The FineWeb datasets: Decanting the Web for the finest text data at scale”.Proc. NeurIPS’24. 2024
2024
-
[32]
Online learning in the manifold of low-rank matrices
U. Shalit, D. Weinshall, and G. Chechik. “Online learning in the manifold of low-rank matrices”.Proc. NIPS’10. Vol. 23. 2010
2010
-
[33]
Fast Transformer Decoding: One Write-Head is All You Need
N. Shazeer. “Fast Transformer decoding: One write-head is all you need”. arXiv:1911.02150. 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[34]
RoFormer: Enhanced Transformer with rotary position embedding
J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu. “RoFormer: Enhanced Transformer with rotary position embedding”.Neurocomputing568.C (2024)
2024
-
[35]
Principal submatrices IX: Interlacing inequalities for singular values of submatrices
R. C. Thompson. “Principal submatrices IX: Interlacing inequalities for singular values of submatrices”. Linear Algebra and its Applications5.1 (1972), pp. 1–12
1972
-
[36]
Differentiating the singular value decomposition
J. Townsend. “Differentiating the singular value decomposition”. 2016.url:https : / / j - towns . github.io/papers/svd-derivative.pdf
2016
-
[37]
Geometric Methods on Low-Rank Matrix and Tensor Manifolds
A. Uschmajew and B. Vandereycken. “Geometric Methods on Low-Rank Matrix and Tensor Manifolds”. Handbook of Variational Methods for Nonlinear Geometric Data. Springer, 2020, pp. 261–313
2020
-
[38]
Low-rank matrix completion by Riemannian optimization
B. Vandereycken. “Low-rank matrix completion by Riemannian optimization”.SIAM Journal on Op- timization23.2 (2013), pp. 1214–1236
2013
-
[39]
A Riemannian optimization approach for computing low-rank solutions of Lyapunov equations
B. Vandereycken and S. Vandewalle. “A Riemannian optimization approach for computing low-rank solutions of Lyapunov equations”.SIAM Journal on Matrix Analysis and Applications31.5 (2010), pp. 2553–2579
2010
-
[40]
Attention is all you need
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. “Attention is all you need”.Proc. NIPS’17. 2017, pp. 6000–6010
2017
-
[41]
A second-order method landing on the Stiefel manifold via Newton$\unicode{x2013}$Schulz iteration
X.Xiong, B.Gao,and P.-A. Absil.“Asecond-ordermethodlandingontheStiefel manifoldviaNewton– Schulz iteration”. arXiv:2605.02838. 2026. A Implementation Details We give more detailed descriptions of our proposed algorithms. Our PyTorch implementations, available at https://github.com/nick-knight/low-rank-optimizers, closely follow the notation used in this s...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Manopt, a Matlab toolbox for optimization on manifolds
N. Boumal, B. Mishra, P.-A. Absil, and R. Sepulchre. “Manopt, a Matlab toolbox for optimization on manifolds”.Journal of Machine Learning Research15.42 (2014), pp. 1455–1459
2014
-
[43]
Boumal.An Introduction to Optimization on Smooth Manifolds
N. Boumal.An Introduction to Optimization on Smooth Manifolds. Cambridge University Press, 2023
2023
-
[44]
Pymanopt: A Python toolbox for optimization on manifolds using automatic differentiation
J. Townsend, N. Koep, and S. Weichwald. “Pymanopt: A Python toolbox for optimization on manifolds using automatic differentiation”.Journal of Machine Learning Research17.137 (2016), pp. 1–5
2016
-
[45]
Low-rank matrix completion by Riemannian optimization
B. Vandereycken. “Low-rank matrix completion by Riemannian optimization”.SIAM Journal on Op- timization23.2 (2013), pp. 1214–1236. 31
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.