Critical Interval MSE: Toward Reliable Offline Validation for Robot Manipulation Policies
Pith reviewed 2026-06-30 05:56 UTC · model grok-4.3
The pith
Restricting MSE to task-critical intervals and aligning actions yields stronger correlation with robot policy rollout performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
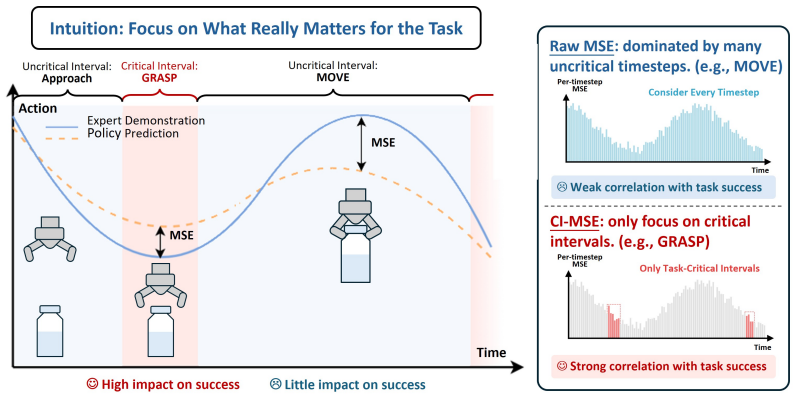
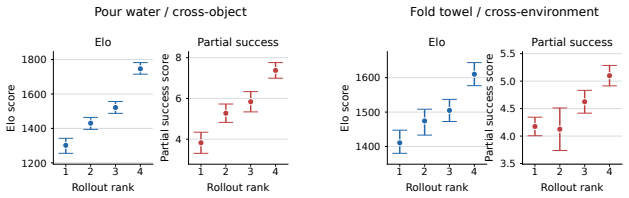
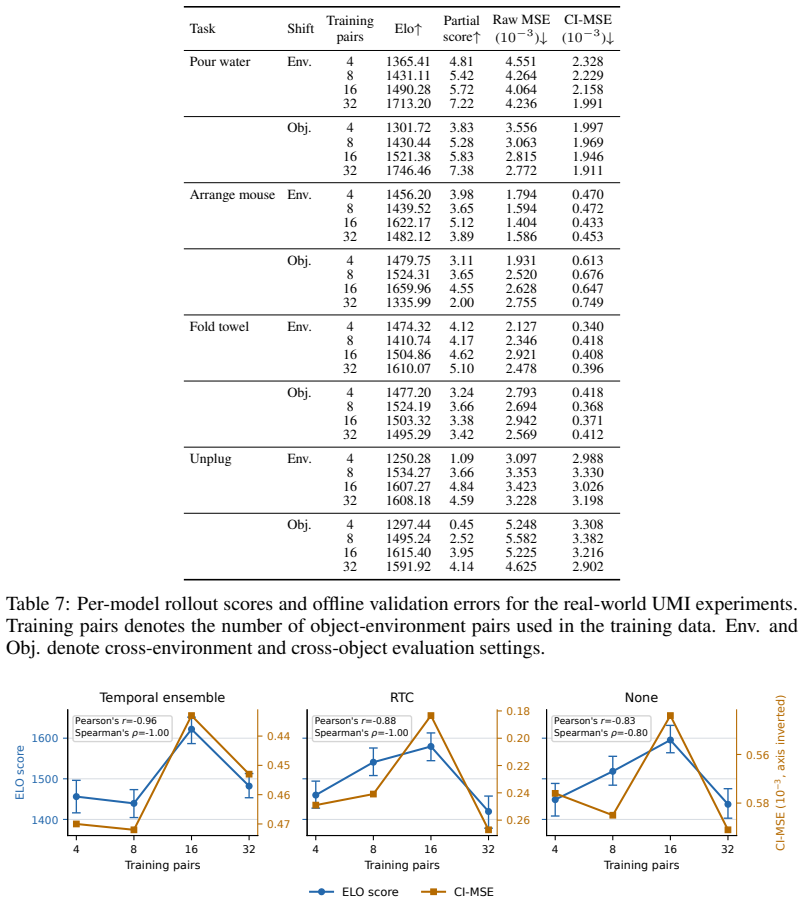
Critical Interval MSE restricts the computation of mean squared error to task-critical segments of demonstrations and incorporates action-alignment procedures to better approximate rollout-time dynamics, resulting in validation errors that correlate more strongly with real-world policy performance than standard MSE across a range of checkpoints.
What carries the argument
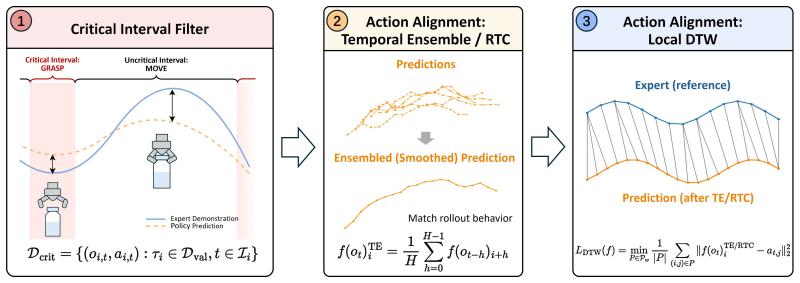
Critical Interval MSE (CI-MSE), which limits error computation to identified task-critical segments and applies action alignment to match rollout behavior.
If this is right
- Offline validation becomes a more reliable proxy, reducing the need for frequent real-world evaluations.
- Policies can be compared and iterated more efficiently using only expert demonstrations.
- The metric remains effective under some distribution shifts but has design boundaries.
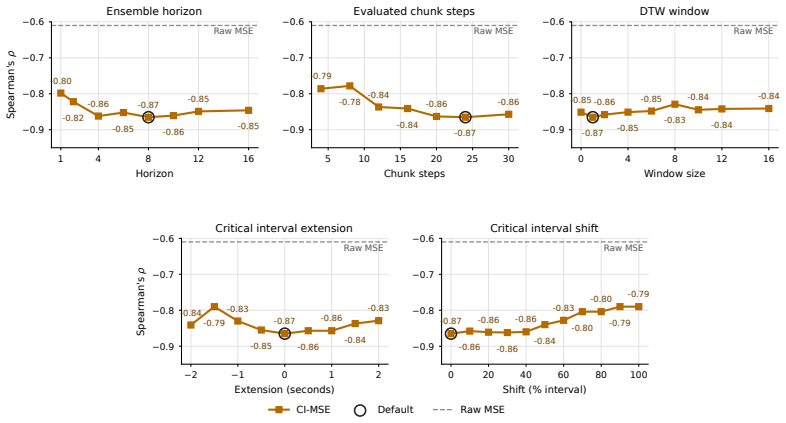
- Sensitivity analysis shows robustness to hyperparameter choices in segment identification and alignment.
Where Pith is reading between the lines
- Similar interval-based restrictions could improve validation metrics in other sequential decision domains like autonomous driving.
- If critical segments prove hard to identify automatically, the method's practicality may depend on domain-specific knowledge.
- Extending the alignment procedure to handle longer horizons might further improve correlation in complex tasks.
Load-bearing premise
Task-critical segments can be identified reliably without introducing bias, and the action-alignment step accurately reflects actual rollout dynamics.
What would settle it
Running the same experiments on additional policy checkpoints or different robot tasks where the correlation of CI-MSE falls to levels comparable with raw MSE would falsify the claimed improvement.
Figures


read the original abstract
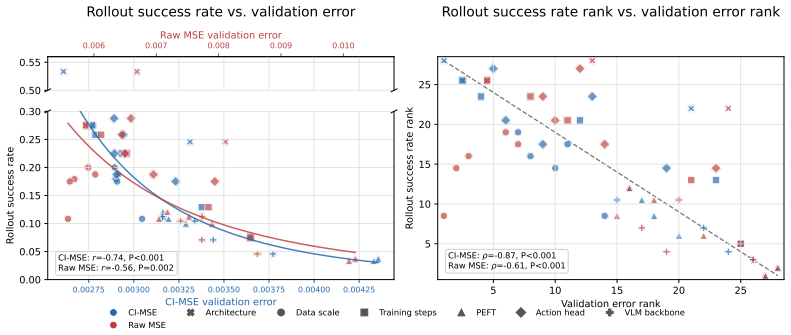
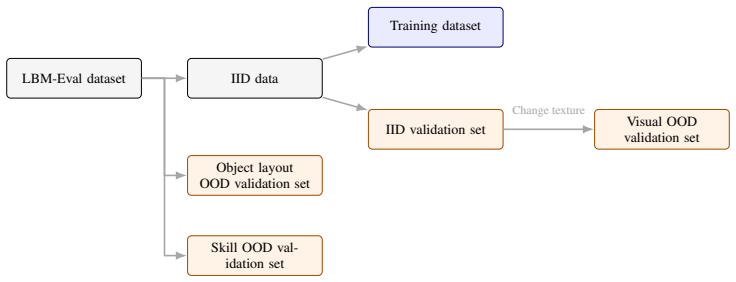
Real-world evaluation is the gold standard for robot policies because it tests them against the physical conditions and deployment challenges they are ultimately designed to handle. However, real-world evaluation is also the bottleneck for iterating on robot policies: it is costly, difficult to reproduce, and often too sparse to reliably compare nearby model variants. A straightforward proxy for performance is validation loss on expert demonstrations, but this proxy is often poorly correlated with real-world performance. In this paper, we introduce Critical Interval MSE (CI-MSE), an intuitively simple yet effective offline validation metric. CI-MSE restricts error computation to task-critical segments and pairs it with simple action-alignment procedures that better match rollout-time behavior. Across simulation and real-world experiments, CI-MSE yields a stronger correlation between validation error and rollout performance than raw MSE. Across a wide range of policy checkpoints, CI-MSE achieves a Spearman's rank correlation of $-0.87$, much closer to the ideal value of $-1$ than raw MSE's $-0.61$, demonstrating a significant improvement. We show through sensitivity analysis that our metric is robust to a wide range of hyperparameters. We further study the effectiveness of CI-MSE under evaluation distribution shifts and suggest design boundaries when using this metric. In summary, this paper provides a simple and reliable offline validation tool for accelerating policy iteration. Project webpage: https://ci-mse.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Critical Interval MSE (CI-MSE) as an offline validation metric for robot manipulation policies. It restricts MSE computation to task-critical segments of expert demonstrations and augments this with action-alignment procedures, claiming stronger correlation with real-world rollout performance than raw MSE (Spearman's rank correlation of -0.87 versus -0.61). The work reports results across simulation and real-world experiments on multiple policy checkpoints, plus sensitivity analysis and tests under distribution shifts.
Significance. If the critical-interval identification procedure proves reproducible from offline data alone without leakage from rollout outcomes, CI-MSE could meaningfully accelerate policy iteration in robotics by supplying a more reliable proxy than standard validation loss. The reported sensitivity analysis and distribution-shift experiments are positive features that strengthen the practical claim.
major comments (2)
- [Abstract / Methods description] The procedure for locating task-critical segments is described only at a high level in the abstract and is not accompanied by an explicit, reproducible algorithm (e.g., pseudocode, decision rules, or dependence on task-specific knowledge or human annotation). Because this step is load-bearing for the claimed correlation improvement, its absence prevents verification that the -0.87 result generalizes without bias to new policies or tasks.
- [Experimental protocol / Results] Implementation details of the action-alignment procedure and the precise experimental protocol used to compute CI-MSE (including how alignment is performed from offline data only) are not provided. This omission directly affects assessment of whether the alignment step introduces information unavailable at true offline validation time, undermining evaluation of the central claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on reproducibility. We address each major comment below and will revise the manuscript to supply the requested details.
read point-by-point responses
-
Referee: [Abstract / Methods description] The procedure for locating task-critical segments is described only at a high level in the abstract and is not accompanied by an explicit, reproducible algorithm (e.g., pseudocode, decision rules, or dependence on task-specific knowledge or human annotation). Because this step is load-bearing for the claimed correlation improvement, its absence prevents verification that the -0.87 result generalizes without bias to new policies or tasks.
Authors: We agree the abstract is high-level. The revised manuscript will add an explicit section with pseudocode, decision rules, and a description of the offline-only procedure for identifying critical intervals from expert demonstrations, ensuring full reproducibility without rollout leakage. revision: yes
-
Referee: [Experimental protocol / Results] Implementation details of the action-alignment procedure and the precise experimental protocol used to compute CI-MSE (including how alignment is performed from offline data only) are not provided. This omission directly affects assessment of whether the alignment step introduces information unavailable at true offline validation time, undermining evaluation of the central claim.
Authors: We agree that the current manuscript lacks sufficient implementation detail. The revision will include the complete action-alignment algorithm, the exact offline-only protocol for computing CI-MSE, and confirmation that no rollout information is used at validation time. revision: yes
Circularity Check
No significant circularity; metric definition independent of reported correlation
full rationale
The paper introduces CI-MSE by restricting MSE to task-critical segments identified from task structure plus action-alignment rules, then reports an empirical Spearman's correlation of -0.87 versus raw MSE's -0.61 on held-out policy checkpoints. No equation or procedure in the provided text defines the critical intervals or alignment using the correlation value itself, nor does any self-citation chain supply a uniqueness result that forces the metric. The correlation is presented as an outcome of applying the independently motivated metric, not as an input used to tune or rename it. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert demonstration data is available and representative enough for offline validation
Reference graph
Works this paper leans on
- [1]
-
[2]
X. Li, K. Hsu, J. Gu, O. Mees, K. Pertsch, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kirmani, S. Levine, J. Wu, C. Finn, H. Su, Q. Vuong, and T. Xiao. Evaluating real-world robot manipu- lation policies in simulation. InProceedings of the 8th Conference on Robot Learning, pages 3705–3728, 2025
2025
-
[3]
Atreya, K
P. Atreya, K. Pertsch, T. Lee, M. J. Kim, A. Jain, A. Kuramshin, C. Eppner, C. Neary, E. Hu, F. Ramos, J. Tremblay, K. Arora, K. Ellis, L. Macesanu, M. Leonard, M. Cho, O. Aslan, S. Dass, J. Wang, X. Yuan, X. Yang, A. Gupta, D. Jayaraman, G. Berseth, K. Daniilidis, R. Martin-Martin, Y . Lee, P. Liang, C. Finn, and S. Levine. Roboarena: Distributed real- w...
-
[4]
URLhttps://proceedings.mlr.press/v305/atreya25a.html
- [5]
-
[6]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset. InRobotics: Science and Systems, 2024. doi:10.15607/RSS.2024.XX.120. URL https://arxiv.org/abs/2403.12945
work page internal anchor Pith review Pith/arXiv arXiv doi:10.15607/rss.2024.xx.120 2024
-
[7]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, et al. Open x-embodiment: Robotic learning datasets and rt-x models.arXiv preprint arXiv:2310.08864, 2023. URLhttps: //arxiv.org/abs/2310.08864
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Hussenot, M
L. Hussenot, M. Andrychowicz, D. Vincent, R. Dadashi, A. Raichuk, S. Ramos, N. Mom- chev, S. Girgin, R. Marinier, L. Stafiniak, M. Orsini, O. Bachem, M. Geist, and O. Pietquin. Hyperparameter selection for imitation learning. In M. Meila and T. Zhang, editors,Pro- ceedings of the 38th International Conference on Machine Learning, volume 139 ofPro- ceeding...
2021
-
[9]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation. In A. Faust, D. Hsu, and G. Neumann, editors,Proceedings of the 9 5th Conference on Robot Learning, volume 164 ofProceedings of Machine Learning Re- sea...
2022
-
[10]
F. Lin, Y . Hu, P. Sheng, C. Wen, J. You, and Y . Gao. Data scaling laws in imitation learning for robotic manipulation. InInternational Conference on Learning Representations, volume 2025, pages 54877–54910, 2025
2025
-
[11]
Florence, C
P. Florence, C. Lynch, A. Zeng, O. A. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mordatch, and J. Tompson. Implicit behavioral cloning. In A. Faust, D. Hsu, and G. Neumann, editors,Proceedings of the 5th Conference on Robot Learning, volume 164 ofProceedings of Machine Learning Research, pages 158–168. PMLR, 2022. URLhttps: //proceedings.mlr.press/v...
2022
- [12]
-
[13]
Tune to Learn: How Controller Gains Shape Robot Policy Learning
A. Bronars, Y . Park, and P. Agrawal. Tune to learn: How controller gains shape robot policy learning.arXiv preprint arXiv:2604.02523, 2026. URLhttps://arxiv.org/abs/2604. 02523
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [14]
-
[15]
C. Wen, J. Lin, J. Qian, Y . Gao, and D. Jayaraman. Keyframe-focused visual imitation learn- ing. In M. Meila and T. Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 11123– 11133. PMLR, 18–24 Jul 2021. URLhttps://proceedings.mlr.press/v139/wen21d. html
2021
-
[16]
E. Johns. Coarse-to-fine imitation learning: Robot manipulation from a single demonstra- tion. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 4613–4619, 2021. doi:10.1109/ICRA48506.2021.9560942. URLhttps://arxiv.org/ abs/2105.06411
-
[17]
T. Tsuji, Y . Kato, G. Solak, H. Zhang, T. Petri ˇc, F. Nori, and A. Ajoudani. A survey on imitation learning for contact-rich tasks in robotics.The International Journal of Robotics Research, 2026. doi:10.1177/02783649261417694. URLhttps://doi.org/10.1177/ 02783649261417694
-
[18]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems, 2023. doi:10.15607/RSS.2023. XIX.016. URLhttps://arxiv.org/abs/2304.13705
work page internal anchor Pith review Pith/arXiv arXiv doi:10.15607/rss.2023 2023
-
[19]
Black, M
K. Black, M. Galliker, and S. Levine. Real-time execution of action chunking flow policies. Advances in Neural Information Processing Systems, 38:33383–33407, 2026
2026
- [21]
-
[22]
G. Zhou, V . Dean, M. K. Srirama, A. Rajeswaran, J. Pari, K. Hatch, A. Jain, T. Yu, P. Abbeel, L. Pinto, C. Finn, and A. Gupta. Train offline, test online: A real robot learning benchmark. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 9197–9203,
2023
-
[23]
doi:10.1109/ICRA48891.2023.10160594. 10
-
[24]
Y . Chen, K. Kimble, E. H. Adelson, T. Asfour, P. Chanrungmaneekul, S. Chitta, Y . Chitambar, Z. Chen, K. Goldberg, D. Kragic, H. Li, X. Li, Y . Li, A. Prather, N. Pollard, M. A. Roa-Garzon, R. Seney, S. Sha, S. Wang, Y . Xiang, K. Zhang, Y . Zhu, and K. Hang. Manipulationnet: An infrastructure for benchmarking real-world robot manipulation with physical ...
-
[25]
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020. doi: 10.1109/LRA.2020.2974707
-
[26]
J. Gu, F. Xiang, X. Li, Z. Ling, X. Liu, T. Mu, Y . Tang, S. Tao, X. Wei, Y . Yao, X. Yuan, P. Xie, Z. Huang, R. Chen, and H. Su. Maniskill2: A unified benchmark for generalizable manipulation skills. InInternational Conference on Learning Representations, 2023
2023
-
[27]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning. InAdvances in Neural Information Processing Sys- tems, 2023
2023
-
[28]
Jiang and L
N. Jiang and L. Li. Doubly robust off-policy value evaluation for reinforcement learning. In M. F. Balcan and K. Q. Weinberger, editors,Proceedings of The 33rd International Conference on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 652– 661, New York, New York, USA, 20–22 Jun 2016. PMLR. URLhttps://proceedings. mlr.press/...
2016
-
[29]
J. Fu, M. Norouzi, O. Nachum, G. Tucker, Z. Wang, A. Novikov, M. Yang, M. R. Zhang, Y . Chen, A. Kumar, C. Paduraru, S. Levine, and T. Le Paine. Benchmarks for deep off-policy evaluation. InInternational Conference on Learning Representations, 2021
2021
-
[30]
L. Da, P. Jenkins, T. Schwantes, J. Dotson, and H. Wei. Probabilistic offline policy ranking with approximate bayesian computation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 20370–20378, 2024
2024
-
[31]
P. Gu, M. Zhao, X. He, Y . Cai, and B. An. Porank: A practical framework for learning to rank policies. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pages 4044–4052, 2024. doi:10.24963/ijcai.2024/447
-
[32]
Zheng, W.-L
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. InAdvances in Neural Information Processing Systems, 2023. Datasets and Benchmarks Track
2023
-
[33]
S. Tan, S. Zhuang, K. Montgomery, W. Tang, A. Cuadron, C. Wang, R. Popa, and I. Stoica. Judgebench: A benchmark for evaluating llm-based judges. InInternational Conference on Learning Representations, 2025
2025
-
[34]
Barreiros, A
J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C.-H. Fang, K. Hashimoto, M. Z. Irshad, M. Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation.Science Robotics, 11(113):eaea6201, 2026
2026
-
[35]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, et al.π0.5: a vision-language-action model with open-world general- ization. In9th Annual Conference on Robot Learning, 2025
2025
-
[36]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, et al. X- vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Castañeda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. 11 A Appendix A.1 Few-Shot Prompt for Critical Interval Annotation We use the following prompt template to ask the vision-language model to annota...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.