DR-Mamba: Automatic Inference-Time Domain Adaptation for Document Image Binarization via Sample-Conditioned Detail-Background Suppression
Pith reviewed 2026-06-26 10:53 UTC · model grok-4.3
The pith
Input-dependent subtractive gates adapt document binarization to each sample's degradation in one forward pass without labels or updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
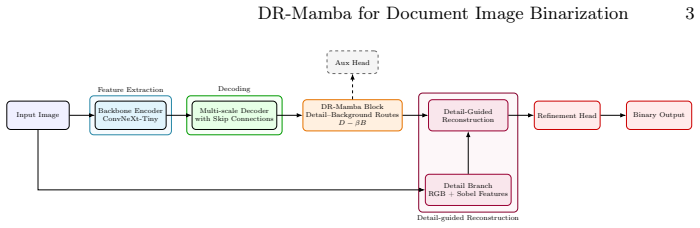
DR-Mamba performs automatic inference-time domain adaptation for document image binarization by using input-dependent gates to suppress background interference through a fast-slow route modeling of Mamba scanning, achieving improved cross-domain robustness without requiring target labels, fine-tuning, or test-time updates.
What carries the argument
The input-dependent subtractive gate that integrates a fast detail route for local stroke structures with a slow background route for persistent degradation responses.
If this is right
- Per-document subtractive suppression yields stronger cross-domain results than additive or concatenative fusion.
- Particularly large gains appear on the most severely degraded held-out folds under leave-one-year-out evaluation.
- Full-resolution detail-guided reconstruction recovers thin strokes that would otherwise be lost to downsampling.
- The entire adaptation occurs inside one forward pass with no gradient steps or auxiliary data required at inference.
Where Pith is reading between the lines
- The subtractive-gate design could be tested on other degradation-sensitive vision tasks such as low-light enhancement or shadow removal to check whether the fast-slow separation generalizes beyond binarization.
- Replacing the Mamba backbone with a different selective state-space model would reveal whether the reported robustness stems primarily from the gate or from the specific scanning mechanism.
- Applying the same per-location suppression at multiple scales might further improve performance on documents containing both fine text and large stained regions.
- The leave-one-year-out protocol on DIBCO-style data leaves open whether similar gains would hold on real archival collections whose degradation distributions differ from the benchmark years.
Load-bearing premise
The input-dependent subtractive gate can reliably separate detail from background degradation using only the single input sample and no target labels or parameter updates.
What would settle it
If a held-out degradation domain shows no accuracy gain for DR-Mamba over a non-adaptive baseline that uses the same Mamba backbone without the subtractive gate, the central claim of improved robustness via per-document per-location suppression would be falsified.
Figures

read the original abstract
Degraded document image binarization is sensitive to domain shifts caused by paper aging, bleed-through, stains, shadows, and uneven illumination, and the foreground-background separation of recent learning-based methods can become unstable on unseen degradation domains. We propose DR-Mamba, a sample-conditioned detail-background suppression framework that performs automatic inference-time domain adaptation for document image binarization. Unlike test-time adaptation methods that require gradient updates or auxiliary data at inference, DR-Mamba adapts to each input document through input-dependent gates within a single forward pass, requiring no target-domain labels, no fine-tuning, and no test-time parameter updates. Instead of using Mamba-style selective scanning as a single generic feature path, DR-Mamba reinterprets it as fast-slow route modeling: a fast detail route captures local stroke structures, while a slow background route accumulates spatially persistent degradation responses. The two routes are integrated through an input-dependent subtractive gate that explicitly suppresses background interference rather than fusing features by addition or concatenation. We further add full-resolution detail-guided reconstruction and thin-stroke-aware supervision to recover fine strokes lost during downsampling. Evaluated under a leave-one-year-out protocol on DIBCO-style benchmarks, where each held-out year is treated as an unseen degradation domain, DR-Mamba shows that per-document, per-location subtractive suppression improves cross-domain robustness, with particularly strong performance on the most severely degraded held-out fold.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DR-Mamba, a sample-conditioned framework for document image binarization that reinterprets Mamba selective scanning as parallel fast-detail and slow-background routes whose outputs are combined by an input-dependent subtractive gate. This enables automatic inference-time domain adaptation in a single forward pass with no target labels, no fine-tuning, and no parameter updates. Additional components include full-resolution detail-guided reconstruction and thin-stroke-aware supervision. Under a leave-one-year-out protocol on DIBCO-style benchmarks treating each held-out year as an unseen degradation domain, the method claims improved cross-domain robustness, with strongest gains on the most severely degraded folds.
Significance. If the input-dependent subtractive gate reliably isolates local stroke detail from spatially persistent degradation using only the single input sample, the approach would offer a lightweight, label-free alternative to existing test-time adaptation techniques that require gradient steps or auxiliary data. The emphasis on per-document, per-location suppression without retraining addresses a practical need in historical document processing where degradation varies across collections. The absence of any auxiliary diagnostic for the claimed routing, however, leaves the central adaptation mechanism unverified.
major comments (2)
- [Method description of subtractive gate and route modeling] The central mechanism reinterprets Mamba scanning as fast-slow routes combined by an input-dependent subtractive gate, yet the manuscript supplies no auxiliary loss, route-specific regularization, or diagnostic visualization to confirm that the gate performs the claimed per-location background suppression rather than some other internal computation. Training uses only the final binarization loss plus thin-stroke supervision; any failure of this implicit separation would directly undermine the cross-domain robustness claim on held-out year folds.
- [Abstract and Evaluation] The abstract asserts performance gains under the leave-one-year-out protocol, but the supplied text contains no quantitative metrics, ablation tables, or implementation details that would allow assessment of the cross-domain claims or the contribution of the subtractive gate versus the reconstruction and supervision terms.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on DR-Mamba. We address each major comment below and outline revisions to strengthen the verification of the proposed mechanism and the presentation of results.
read point-by-point responses
-
Referee: [Method description of subtractive gate and route modeling] The central mechanism reinterprets Mamba scanning as fast-slow routes combined by an input-dependent subtractive gate, yet the manuscript supplies no auxiliary loss, route-specific regularization, or diagnostic visualization to confirm that the gate performs the claimed per-location background suppression rather than some other internal computation. Training uses only the final binarization loss plus thin-stroke supervision; any failure of this implicit separation would directly undermine the cross-domain robustness claim on held-out year folds.
Authors: We acknowledge that the current training objective relies solely on the final binarization loss and thin-stroke supervision without explicit route-specific terms or diagnostics. This leaves the internal behavior of the subtractive gate as an implicit outcome. To address this, we will add diagnostic visualizations of the gate outputs and ablation experiments that isolate the gate's contribution in the revised manuscript. revision: yes
-
Referee: [Abstract and Evaluation] The abstract asserts performance gains under the leave-one-year-out protocol, but the supplied text contains no quantitative metrics, ablation tables, or implementation details that would allow assessment of the cross-domain claims or the contribution of the subtractive gate versus the reconstruction and supervision terms.
Authors: The full manuscript includes quantitative tables, ablations, and implementation details in the Experiments section. However, the abstract itself does not report specific numbers. We will revise the abstract to include key metrics from the leave-one-year-out results and ensure clearer linkage between components and performance gains. revision: partial
Circularity Check
No circularity; architectural design is independently specified and empirically evaluated
full rationale
The paper presents a neural architecture (DR-Mamba) that reinterprets Mamba selective scanning as fast-slow routes combined by an input-dependent subtractive gate, trained end-to-end with standard binarization loss plus thin-stroke supervision. No equations, derivations, or first-principles results are shown that reduce any claimed prediction or output to the inputs by construction. No self-citations are invoked to justify uniqueness theorems, import ansatzes, or load-bear the central mechanism. The cross-domain robustness claim rests on leave-one-year-out empirical results rather than tautological definitions or fitted-input renaming. This is the common case of a self-contained empirical method paper with no detectable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2312.03568 (2023)
Biswas, R., Roy, S.K., Wang, N., Pal, U., Huang, G.B.: Docbinformer: A two- level transformer network for effective document image binarization. arXiv preprint arXiv:2312.03568 (2023)
arXiv 2023
-
[2]
Biswas, R., Sarkhel, S., Roy, S.K., Pal, U.: Transdocunet: A transformer- based unet architecture for degraded document image binarization. In: Pro- ceedings of the Fourteenth Indian Conference on Computer Vision, Graphics and Image Processing. pp. 1–9. Association for Computing Machinery (2023). https://doi.org/10.1145/3627631.3627639
-
[3]
arXiv preprint arXiv:2404.05669 (2024)
Cicchetti, G., Comminiello, D.: Naf-dpm: A nonlinear activation-free diffusion probabilistic model for document enhancement. arXiv preprint arXiv:2404.05669 (2024)
arXiv 2024
-
[4]
IEEE Signal Processing Letters27, 1090–1094 (2020)
De, R., Chakraborty, A., Sarkar, R.: Document image binarization using dual dis- criminator generative adversarial networks. IEEE Signal Processing Letters27, 1090–1094 (2020). https://doi.org/10.1109/LSP.2020.3003828
-
[5]
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: Proceedings of the IEEE Con- ference on Computer Vision and Pattern Recognition. pp. 248–255 (2009). https://doi.org/10.1109/CVPR.2009.5206848
-
[6]
Gatos, B., Ntirogiannis, K., Pratikakis, I.: Icdar 2009 document image bi- narization contest (dibco 2009). In: Proceedings of the International Con- ference on Document Analysis and Recognition. pp. 1375–1382 (2009). https://doi.org/10.1109/ICDAR.2009.246
-
[7]
Pattern Recognition39(3), 317–327 (2006)
Gatos, B., Pratikakis, I., Perantonis, S.J.: Adaptive degraded docu- ment image binarization. Pattern Recognition39(3), 317–327 (2006). https://doi.org/10.1016/j.patcog.2005.09.010
-
[8]
arXiv preprint arXiv:2312.00752 (2023) 16 S.-W
Gu, A., Dao, T.: Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752 (2023) 16 S.-W. Chan et al
Pith/arXiv arXiv 2023
-
[9]
In: International Conference on Learning Representations (2022)
Gu, A., Goel, K., Ré, C.: Efficiently modeling long sequences with structured state spaces. In: International Conference on Learning Representations (2022)
2022
-
[10]
Pattern Recognition91, 379–390 (2019)
He, S., Schomaker, L.: Deepotsu: Document enhancement and binariza- tion using iterative deep learning. Pattern Recognition91, 379–390 (2019). https://doi.org/10.1016/j.patcog.2019.01.025
-
[11]
arXiv preprint arXiv:2512.14114 (2025)
Ju, R.Y., Wong, K., Jin, Y., Chiang, J.S.: Mfe-gan: Efficient gan-based frame- work for document image enhancement and binarization with multi-scale feature extraction. arXiv preprint arXiv:2512.14114 (2025)
arXiv 2025
-
[12]
In: International Conference on Medical Imaging with Deep Learning
Kervadec, H., Bouchtiba, J., Desrosiers, C., Granger, E., Dolz, J., Ayed, I.B.: Boundary loss for highly unbalanced segmentation. In: International Conference on Medical Imaging with Deep Learning. pp. 285–296 (2019)
2019
-
[13]
In: Advances in Neural Information Processing Systems
Liu, Y., Tian, Y., Zhao, Y., Yu, H., Xie, L., Wang, Y., Ye, Q., Jiao, J., Liu, Y.: Vmamba: Visual state space model. In: Advances in Neural Information Processing Systems. vol. 37 (2024)
2024
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.: A convnet for the 2020s. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11976–11986 (2022)
2022
-
[15]
In: International Conference on Learning Representations (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2019)
2019
-
[16]
In: International Conference on Learning Representations (2018)
Micikevicius, P., Narang, S., Alben, J., Diamos, G., Elsen, E., Garcia, D., Ginsburg, B., Houston, M., Kuchaiev, O., Venkatesh, G., Wu, H.: Mixed precision training. In: International Conference on Learning Representations (2018)
2018
-
[17]
IEEE Transactions on Systems, Man, and Cybernetics , author =
Otsu, N.: A threshold selection method from gray-level histograms. IEEE Transactions on Systems, Man, and Cybernetics9(1), 62–66 (1979). https://doi.org/10.1109/TSMC.1979.4310076
-
[18]
In: Advances in Neural Information Processing Systems
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., Chintala, S.: Pytorch: An imperative style, high-performance deep learning library. In: Advances in Neural Informat...
2019
-
[19]
In: Proceedings of the International Conference on Frontiers in Handwriting Recognition
Pratikakis, I., Gatos, B., Ntirogiannis, K.: H-dibco 2010: Handwritten doc- ument image binarization competition. In: Proceedings of the International Conference on Frontiers in Handwriting Recognition. pp. 727–732 (2010). https://doi.org/10.1109/ICFHR.2010.118
-
[20]
Pratikakis, I., Zagoris, K., Barlas, G., Gatos, B.: Icdar 2013 document im- age binarization contest (dibco 2013). In: Proceedings of the International Conference on Document Analysis and Recognition. pp. 1471–1476 (2013). https://doi.org/10.1109/ICDAR.2013.219
-
[21]
Pratikakis, I., Zagoris, K., Barlas, G., Gatos, B.: Icdar 2017 competition on document image binarization (dibco 2017). In: Proceedings of the Interna- tional Conference on Document Analysis and Recognition. pp. 1395–1403 (2017). https://doi.org/10.1109/ICDAR.2017.228
-
[22]
In: 2018 16th International Conference on Frontiers in Handwriting Recognition
Pratikakis, I., Zagoris, K., Kaddas, P., Gatos, B.: Icfhr 2018 competition on hand- written document image binarization (h-dibco 2018). In: Proceedings of the Inter- national Conference on Frontiers in Handwriting Recognition. pp. 489–493 (2018). https://doi.org/10.1109/ICFHR-2018.2018.00091
-
[23]
In: International Workshop on Machine Learning in Medical Imaging
Salehi, S.S.M., Erdogmus, D., Gholipour, A.: Tversky loss function for image seg- mentation using 3d fully convolutional deep networks. In: International Workshop on Machine Learning in Medical Imaging. pp. 379–387. Springer (2017) DR-Mamba for Document Image Binarization 17
2017
-
[24]
Pattern Recognition33(2), 225–236 (2000)
Sauvola, J., Pietikainen, M.: Adaptive document image binarization. Pattern Recognition33(2), 225–236 (2000). https://doi.org/10.1016/S0031-3203(99)00055- 2
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shit, S., Paetzold, J.C., Sekuboyina, A., Ezhov, I., Unger, A., Zhylka, A., Pluim, J.P.W., Bauer, U., Menze, B.H.: cldice: A novel topology-preserving loss function for tubular structure segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16560–16569 (2021)
2021
-
[26]
arXiv preprint arXiv:2201.10252 (2022)
Souibgui, M.A., Biswas, S., Jemni, S.K., Kessentini, Y., Fornés, A., Lladós, J., Pal, U.: Docentr: An end-to-end document image enhancement transformer. arXiv preprint arXiv:2201.10252 (2022)
arXiv 2022
-
[27]
IEEE Transactions on Image Processing22(4), 1408– 1417 (2013)
Su, B., Lu, S., Tan, C.L.: A robust document image binarization technique for degraded document images. IEEE Transactions on Image Processing22(4), 1408– 1417 (2013). https://doi.org/10.1109/TIP.2012.2231089
-
[28]
In: Proceedings of the International Con- ference on Document Analysis and Recognition
Tensmeyer, C., Martinez, T.: Document image binarization with fully convolutional neural networks. In: Proceedings of the International Con- ference on Document Analysis and Recognition. pp. 99–104 (2017). https://doi.org/10.1109/ICDAR.2017.25
-
[29]
Information Fusion93, 159–173 (2023)
Yang, M., Xu, S.: A novel degraded document binarization model through vision transformer network. Information Fusion93, 159–173 (2023). https://doi.org/10.1016/j.inffus.2023.01.007
-
[30]
In: Proceedings of the 31st ACM International Conference on Multimedia
Yang, Z., Liu, B., Xiong, Y., Yi, L., Wu, G., Tang, X., Liu, Z., Zhou, J., Zhang, X.: Docdiff: Document enhancement via residual diffusion models. In: Proceedings of the 31st ACM International Conference on Multimedia. Association for Computing Machinery (2023). https://doi.org/10.1145/3581783.3611730
-
[31]
Pattern Recog- nition96, 106968 (2019)
Zhao, J., Shi, C., Jia, F., Wang, Y., Xiao, B.: Document image binarization with cascaded generators of conditional generative adversarial networks. Pattern Recog- nition96, 106968 (2019). https://doi.org/10.1016/j.patcog.2019.106968
-
[32]
In: Proceedings of the International Conference on Machine Learning
Zhu, L., Liao, B., Zhang, Q., Wang, X., Liu, W., Wang, X.: Vision mamba: Efficient visual representation learning with bidirectional state space model. In: Proceedings of the International Conference on Machine Learning. pp. 62429–62442 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.