Revisiting the Volume Hypothesis
Pith reviewed 2026-07-01 06:22 UTC · model grok-4.3
The pith
The generalization advantage of gradient learning over random sampling diminishes as training data size grows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
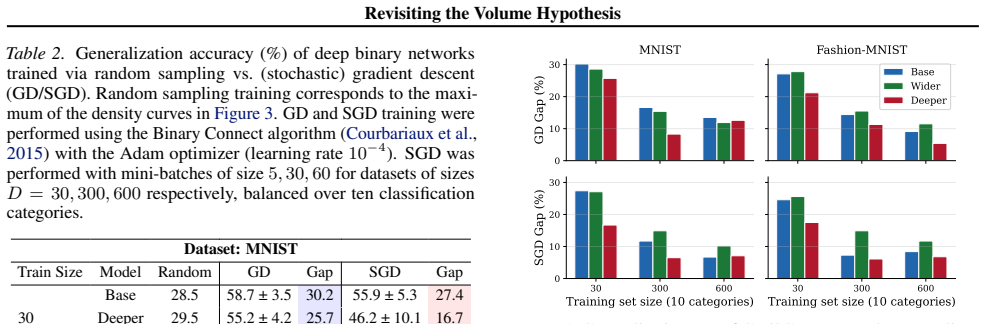
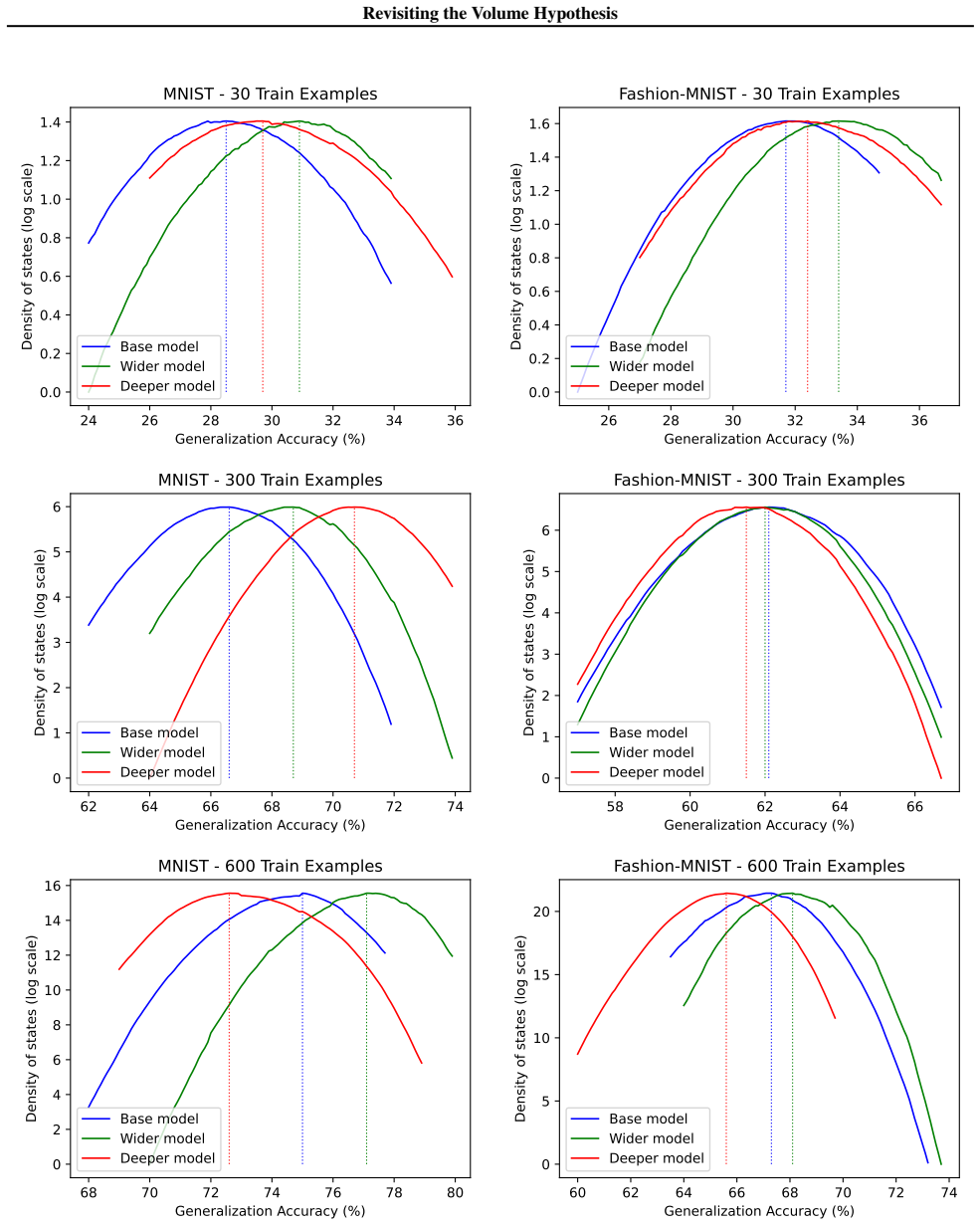
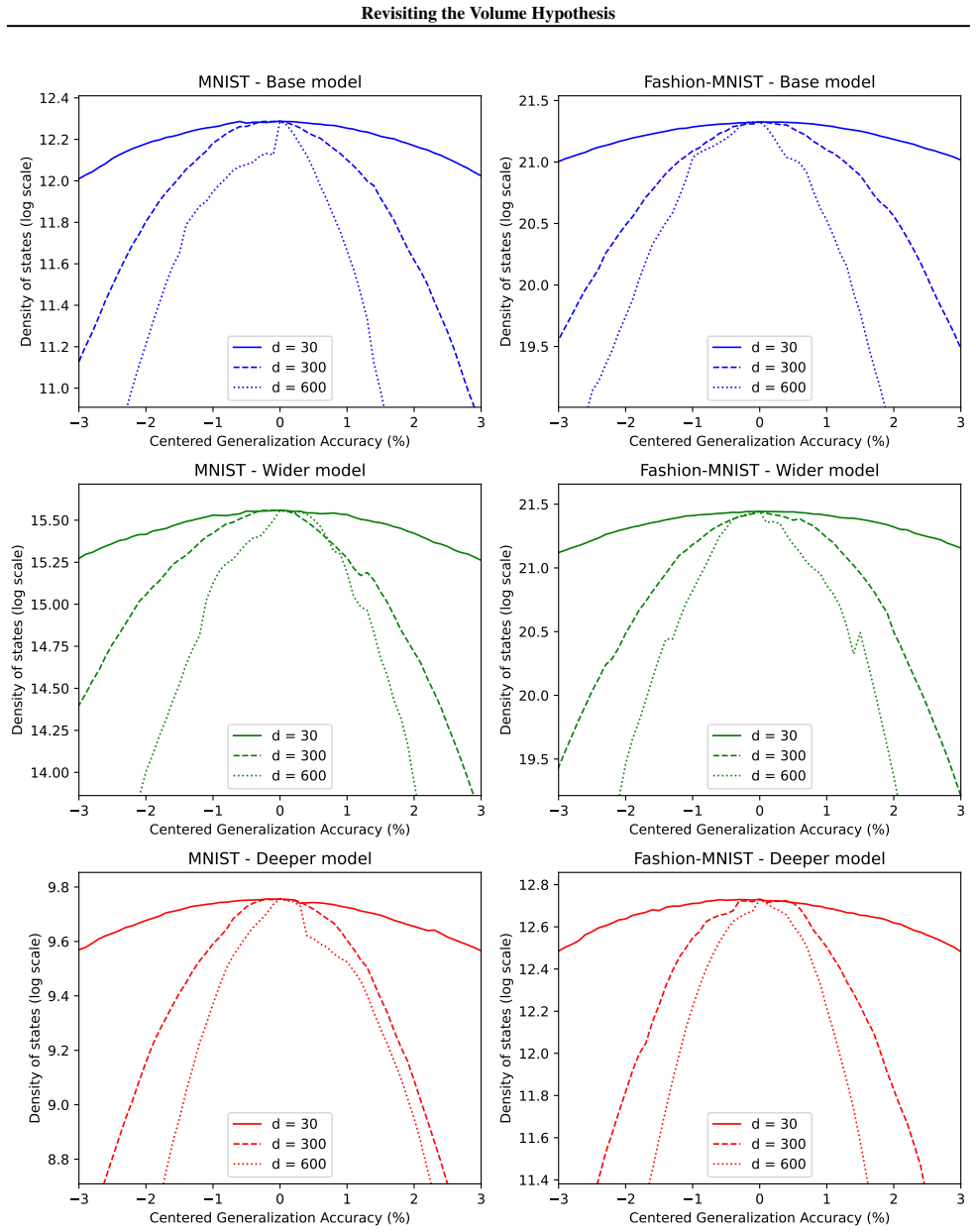
The generalization advantage of gradient learning over random sampling training generally diminishes as the training data size grows. This pattern appears across architectures and datasets when the joint density of states over training and test accuracies is estimated with the Replica Exchange Wang-Landau algorithm applied to binary networks, offering a scale-dependent reconciliation of prior conflicting results on the volume hypothesis.
What carries the argument
The joint density of states over training and test accuracies, estimated via Replica Exchange Wang-Landau sampling in binary networks, which measures the relative volumes of basins with differing generalization quality.
If this is right
- At small training-set sizes the generalization gap between gradient descent and random sampling is large.
- At larger training-set sizes the gap narrows and random sampling becomes competitive.
- Volume effects provide a stronger account of generalization when data are scarce than when data are abundant.
- Earlier contradictory findings on the volume hypothesis are explained by the different dataset-size regimes in which they operated.
Where Pith is reading between the lines
- If the observed trend continues, random sampling could become sufficient for generalization once datasets reach very large scales.
- The result links volume-based explanations to scaling behavior, suggesting overparameterization helps mainly through volume when data remain limited.
- Repeating the density estimation on continuous-weight networks would test whether the size-dependent pattern holds beyond binary models.
- Comparing the distribution of solutions actually reached by SGD trajectories against the estimated densities would directly validate the volume interpretation.
Load-bearing premise
The Replica Exchange Wang-Landau density estimates accurately reflect the relative volumes of good- and poor-generalizing basins that SGD would encounter in the same models.
What would settle it
Measuring the actual generalization rates achieved by SGD versus uniform random sampling on the identical binary networks and datasets, then checking whether the measured gap shrinks with increasing data size in the same manner as the density estimates predict.
Figures

read the original abstract
Modern deep neural networks often contain far more parameters than needed to fit their training data, yet they achieve impressive generalization. A common explanation for this success is the implicit bias of stochastic gradient descent (SGD). An alternative volume hypothesis posits that, within low training-loss regions, loss-landscape basins leading to strong generalization occupy much larger regions of weight space than basins that generalize poorly, and therefore SGD is simply more likely to land in the former. Recent experimental explorations of this idea present seemingly contradictory results. While in one set of experiments randomly sampling the network weights until achieving zero training error yielded poor generalization, molecular dynamics density estimates supported the volume hypothesis. We observe that these experiments were performed at different dataset size regimes, and explore an intermediate regime using the Replica Exchange Wang-Landau algorithm to estimate the joint density of states over training and test accuracies in binary networks. Across several architectures and datasets, we show that the generalization advantage of gradient learning over random sampling training generally diminishes as the training data size grows, suggesting a resolution of the paradox.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the generalization advantage of gradient descent over random sampling of weights (until zero training error) diminishes with increasing training dataset size. This is shown via Replica Exchange Wang-Landau estimates of the joint density of states over training and test accuracies in binary networks, across multiple architectures and datasets, offering a regime-dependent resolution to prior contradictory results on the volume hypothesis.
Significance. If the trend holds, the work empirically reconciles conflicting experiments on the volume hypothesis by demonstrating that volume-based explanations for generalization are more relevant in small-data regimes and weaken as data grows. The global sampling approach provides direct volume estimates rather than relying on fitted parameters, which is a methodological strength.
major comments (2)
- [Methods and experimental setup] The central claim concerns the generalization advantage of gradient learning, yet the analysis is restricted to binary networks (as stated in the abstract and methods). It is unclear whether the observed diminution of the advantage with data size extends to continuous-weight networks or standard DNN training, which is load-bearing for resolving the paradox in modern deep learning contexts.
- [Discussion of volume hypothesis and results] The Replica Exchange Wang-Landau algorithm performs global equilibrium sampling over the discrete hypercube to estimate volumes of good- vs. poor-generalizing regions. However, SGD follows local non-equilibrium dynamics from random initialization; if high-test-accuracy solutions lie outside SGD-reachable basins, the volume ratios will not explain the observed performance gap between gradient and random sampling (see skeptic concern on mapping to SGD trajectories).
minor comments (2)
- [Abstract] Clarify in the abstract and introduction whether the reported 'random sampling training' exactly matches the volume estimation procedure or involves additional post-processing.
- [Results] The paper should report convergence diagnostics or error bars for the Wang-Landau estimates to address potential finite-size effects noted in the reader's assessment.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, with revisions where appropriate to clarify scope and limitations.
read point-by-point responses
-
Referee: [Methods and experimental setup] The central claim concerns the generalization advantage of gradient learning, yet the analysis is restricted to binary networks (as stated in the abstract and methods). It is unclear whether the observed diminution of the advantage with data size extends to continuous-weight networks or standard DNN training, which is load-bearing for resolving the paradox in modern deep learning contexts.
Authors: Our study deliberately restricts analysis to binary networks to enable exact global volume estimation via Replica Exchange Wang-Landau sampling over the discrete hypercube. This provides a controlled test of the volume hypothesis without the intractability of continuous-space sampling. We do not claim the trend generalizes to continuous weights or standard DNN training; we will revise the discussion to explicitly delimit the scope and note that extension to continuous cases is an open question. revision: partial
-
Referee: [Discussion of volume hypothesis and results] The Replica Exchange Wang-Landau algorithm performs global equilibrium sampling over the discrete hypercube to estimate volumes of good- vs. poor-generalizing regions. However, SGD follows local non-equilibrium dynamics from random initialization; if high-test-accuracy solutions lie outside SGD-reachable basins, the volume ratios will not explain the observed performance gap between gradient and random sampling (see skeptic concern on mapping to SGD trajectories).
Authors: The method estimates equilibrium volumes to directly probe whether larger volumes of high-test-accuracy solutions exist, which is the core of the volume hypothesis. Our random-sampling baseline operationalizes volume-based selection, and the comparison to SGD shows the advantage shrinks with data size. We agree the results do not address reachability under local SGD dynamics; we will add a discussion paragraph noting this as a limitation of purely volume-based accounts. revision: partial
- Whether the observed diminution of the generalization advantage extends to continuous-weight networks or standard DNN training.
Circularity Check
No significant circularity; empirical sampling result stands independently
full rationale
The paper reports an empirical trend obtained by running Replica Exchange Wang-Landau sampling to estimate joint densities of states over training and test accuracy in binary networks, then observing how the gap between gradient and random-sampling performance changes with dataset size. This observation is produced directly by the external Monte-Carlo procedure and does not reduce to any fitted parameter, self-definition, or self-citation chain. The central claim therefore remains self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Replica Exchange Wang-Landau algorithm produces accurate estimates of the joint density of states for the binary networks studied.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Neural redshift: Random networks are not random functions , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[2]
Nature Communications , volume=
Deep neural networks have an inbuilt Occam’s razor , author=. Nature Communications , volume=. 2025 , publisher=
2025
-
[3]
arXiv preprint arXiv:2102.06701 , year=
Explaining Neural Scaling Laws , author=. arXiv preprint arXiv:2102.06701 , year=
-
[4]
International Conference on Machine Learning , pages=
Spectrum dependent learning curves in kernel regression and wide neural networks , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[5]
and Luczak, Malwina J
Levin, David A. and Luczak, Malwina J. and Peres, Yuval , doi =. Glauber dynamics for the mean-field Ising model: cut-off, critical power law, and metastability , volume =. Probability Theory and Related Fields , number =
-
[6]
and Newman, Charles M
Ellis, Richard S. and Newman, Charles M. , journal =. Limit theorems for sums of dependent random variables occurring in statistical mechanics , volume =
-
[7]
2008 , publisher=
Large deviations , author=. 2008 , publisher=
2008
-
[8]
Physics Reports , volume=
The large deviation approach to statistical mechanics , author=. Physics Reports , volume=. 2009 , publisher=
2009
-
[9]
Statistics & Probability Letters , volume=
Optimal monitoring network designs , author=. Statistics & Probability Letters , volume=. 1984 , publisher=
1984
-
[10]
Krause, Andreas and Singh, Ajit and Guestrin, Carlos , journal=
-
[11]
Physical review letters , volume=
Statistical mechanics of support vector networks , author=. Physical review letters , volume=. 1999 , publisher=
1999
-
[12]
Nature communications , volume=
Spectral bias and task-model alignment explain generalization in kernel regression and infinitely wide neural networks , author=. Nature communications , volume=. 2021 , publisher=
2021
-
[13]
Advances in Neural Information Processing Systems , volume=
Out-of-Distribution Generalization in Kernel Regression , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Machine Learning: Science and Technology , volume=
Large deviations in the perceptron model and consequences for active learning , author=. Machine Learning: Science and Technology , volume=. 2021 , publisher=
2021
-
[15]
2013 , publisher=
Theory of optimal experiments , author=. 2013 , publisher=
2013
-
[16]
2006 , publisher=
Gaussian processes for machine learning , author=. 2006 , publisher=
2006
-
[17]
Scalable approximate
Sun, Ruoxi and Paninski, Liam , booktitle =. Scalable approximate
-
[18]
Proceedings of the 35th International Conference on Machine Learning , year =
Conditional Neural Processes , author =. Proceedings of the 35th International Conference on Machine Learning , year =
-
[19]
Chichilnisky, E. J. and Kalmar, Rachel S. , title =. 2002 , doi =. http://www.jneurosci.org/content/22/7/2737.full.pdf , journal =
2002
-
[20]
, title =
Pehlevan, Cengiz and Genkin, Alexander and Chklovskii, Dmitri B. , title =. 2018 , publisher =. https://www.biorxiv.org/content/early/2018/01/27/226746.full.pdf , journal =
2018
-
[21]
2000 , publisher=
Neal, Radford M , journal=. 2000 , publisher=
2000
-
[22]
and Mitelut, Catalin and Lai, Chongxi and Gratiy, Sergey L
Jun, James J. and Mitelut, Catalin and Lai, Chongxi and Gratiy, Sergey L. and Anastassiou, Costas A. and Harris, Timothy D. , title =. 2017 , journal =
2017
-
[23]
and Jordan, Michael I
Blei, David M. and Jordan, Michael I. , title =. Proceedings of the Twenty-first International Conference on Machine Learning , series =. 2004 , location =
2004
-
[24]
Guo, Chuan and Pleiss, Geoff and Sun, Yu and Weinberger, Kilian Q , booktitle=
-
[25]
Journal of the American Statistical Association , volume=
Mixture models with a prior on the number of components , author=. Journal of the American Statistical Association , volume=. 2018 , publisher=
2018
-
[26]
Abel Rodriguez and Peter Mueller , journal =
-
[27]
Advances in neural information processing systems , pages=
Learning stochastic inverses , author=. Advances in neural information processing systems , pages=
-
[28]
Paige, Brooks and Wood, Frank , booktitle=
-
[29]
Advances in neural information processing systems , year=
Manzil Zaheer and Satwik Kottur and Siamak Ravanbakhsh and Barnab. Advances in neural information processing systems , year=
-
[30]
ICLR , year=
Towards a neural statistician , author=. ICLR , year=
-
[31]
ICML 2018 workshop on Theoretical Foundations and Applications of Deep Generative Models , year=
Neural processes , author=. ICML 2018 workshop on Theoretical Foundations and Applications of Deep Generative Models , year=
2018
-
[32]
International Conference on Machine Learning , year=
Conditional neural processes , author=. International Conference on Machine Learning , year=
-
[33]
1988 , publisher=
Mixture models: Inference and applications to clustering , author=. 1988 , publisher=
1988
-
[34]
Neural networks , volume=
Clustering: A neural network approach , author=. Neural networks , volume=. 2010 , publisher=
2010
-
[35]
ICLR , year=
Neural machine translation by jointly learning to align and translate , author=. ICLR , year=
-
[36]
Kurihara, Kenichi and Welling, Max and Teh, Yee Whye , booktitle=
-
[37]
2004 , publisher=
Jain, Sonia and Neal, Radford M , journal=. 2004 , publisher=
2004
-
[38]
Bayesian Analysis , volume=
Splitting and merging components of a nonconjugate Dirichlet process mixture model , author=. Bayesian Analysis , volume=. 2007 , publisher=
2007
-
[39]
ICLR , year=
Adam: A method for stochastic optimization , author=. ICLR , year=
-
[40]
Deep Amortized Inference for Probabilistic Programs
Deep amortized inference for probabilistic programs , author=. arXiv preprint arXiv:1610.05735 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Hughes, Michael and Kim, Dae Il and Sudderth, Erik , booktitle=
-
[42]
Inference Compilation and Universal Probabilistic Programming
Inference compilation and universal probabilistic programming , author=. arXiv preprint arXiv:1610.09900 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Hinton, GE and McClelland, JL and Rumelhart, DE , year=
-
[44]
Empirical Evaluation of Rectified Activations in Convolutional Network
Empirical evaluation of rectified activations in convolutional network , author=. arXiv preprint arXiv:1505.00853 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Blei, David M and Frazier, Peter I , journal=
-
[46]
Wallach, Hanna and Jensen, Shane and Dicker, Lee and Heller, Katherine , booktitle=
-
[47]
Lu, Jun and Li, Meng and Dunson, David , journal=
-
[48]
Non-exchangeable random partition models for microclustering
Non-exchangeable random partition models for microclustering , author=. arXiv preprint arXiv:1711.07287 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
AAAI , volume=
Learning systems of concepts with an infinite relational model , author=. AAAI , volume=
-
[50]
Uncertainity in Artificial Intelligence (UAI2006) , year=
Learning infinite hidden relational models , author=. Uncertainity in Artificial Intelligence (UAI2006) , year=
-
[51]
Journal of the American Statistical Association , volume=
Getting it right: Joint distribution tests of posterior simulators , author=. Journal of the American Statistical Association , volume=. 2004 , publisher=
2004
-
[52]
Permutation-equivariant neural networks applied to dynamics prediction
Permutation-equivariant neural networks applied to dynamics prediction , author=. arXiv preprint arXiv:1612.04530 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Deep Learning with Sets and Point Clouds
Deep learning with sets and point clouds , author=. arXiv preprint arXiv:1611.04500 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Advances in Neural Information Processing Systems , pages=
A nonparametric variable clustering model , author=. Advances in Neural Information Processing Systems , pages=
-
[55]
Journal of the American statistical association , volume=
Estimation and prediction for stochastic blockstructures , author=. Journal of the American statistical association , volume=. 2001 , publisher=
2001
-
[56]
Proceedings of the 27th International Conference on Machine Learning (ICML-10) , pages=
Nonparametric information theoretic clustering algorithm , author=. Proceedings of the 27th International Conference on Machine Learning (ICML-10) , pages=
-
[57]
Proceedings of the 23rd annual international ACM SIGIR conference on Research and development in information retrieval , pages=
Document clustering using word clusters via the information bottleneck method , author=. Proceedings of the 23rd annual international ACM SIGIR conference on Research and development in information retrieval , pages=. 2000 , organization=
2000
-
[58]
Proceedings of the National Academy of Sciences , volume=
Information-based clustering , author=. Proceedings of the National Academy of Sciences , volume=. 2005 , publisher=
2005
-
[59]
Linderman, Scott W and Mena, Gonzalo E and Cooper, Hal and Paninski, Liam and Cunningham, John P , booktitle=
-
[60]
Diaconis, Persi , journal=
-
[61]
Journal of mathematical psychology , volume=
Probability models on rankings , author=. Journal of mathematical psychology , volume=. 1991 , publisher=
1991
-
[62]
ICML , volume=
Cranking: Combining rankings using conditional probability models on permutations , author=. ICML , volume=. 2002 , organization=
2002
-
[63]
Chen, Zhengdao and Li, Lisha and Bruna, Joan , journal=
-
[64]
Physical Review E , volume=
Asymptotic analysis of the stochastic block model for modular networks and its algorithmic applications , author=. Physical Review E , volume=. 2011 , publisher=
2011
-
[65]
arXiv preprint arXiv:1811.06128 , year=
Machine Learning for Combinatorial Optimization: a Methodological Tour d'Horizon , author=. arXiv preprint arXiv:1811.06128 , year=
-
[66]
Computational Statistics & Data Analysis , volume=
Improved Bayesian inference for the stochastic block model with application to large networks , author=. Computational Statistics & Data Analysis , volume=. 2013 , publisher=
2013
-
[67]
2018 , volume =
Foundations and Trends® in Communications and Information Theory , title =. 2018 , volume =
2018
-
[68]
Journal of Machine Learning Research , volume=
Mixed membership stochastic blockmodels , author=. Journal of Machine Learning Research , volume=
-
[69]
Bayesian Analysis , volume=
Bayesian Community Detection , author=. Bayesian Analysis , volume=
-
[70]
2015 , publisher=
Foti, Nicholas J and Williamson, Sinead A , journal=. 2015 , publisher=
2015
-
[71]
MacEachern, Steven N , journal=
-
[72]
IEEE transactions on pattern analysis and machine intelligence , volume=
Bayesian models of graphs, arrays and other exchangeable random structures , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2015 , publisher=
2015
-
[73]
Social networks , volume=
Stochastic blockmodels: First steps , author=. Social networks , volume=. 1983 , publisher=
1983
-
[74]
2018 , publisher=
Min, Erxue and Guo, Xifeng and Liu, Qiang and Zhang, Gen and Cui, Jianjing and Long, Jun , journal=. 2018 , publisher=
2018
-
[75]
Aljalbout, Elie and Golkov, Vladimir and Siddiqui, Yawar and Cremers, Daniel , journal=
-
[76]
Advances in Neural Information Processing Systems 31 , year =
BRUNO: A Deep Recurrent Model for Exchangeable Data , author =. Advances in Neural Information Processing Systems 31 , year =
-
[77]
arXiv preprint arXiv:1901.06082 , year=
Probabilistic symmetry and invariant neural networks , author=. arXiv preprint arXiv:1901.06082 , year=
-
[78]
Proceedings of the 34th International Conference on Machine Learning , year =
Equivariance Through Parameter-Sharing , author =. Proceedings of the 34th International Conference on Machine Learning , year =
-
[79]
and Goodman, Dan F
Kadir, Shabnam N. and Goodman, Dan F. M. and Harris, Kenneth D. , title =. Neural Computation , volume =. 2014 , doi =
2014
-
[80]
IEEE Signal Processing Magazine , volume=
Nonparametric Bayesian modeling of complex networks: An introduction , author=. IEEE Signal Processing Magazine , volume=. 2013 , publisher=
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.