CPC-VAR:Continual Personalized and Compositional Generation in Visual Autoregressive Models
Pith reviewed 2026-05-20 06:57 UTC · model grok-4.3
The pith
Gradient-based neuron selection lets visual autoregressive models learn new user concepts sequentially without erasing earlier ones and compose multiple concepts with spatial control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
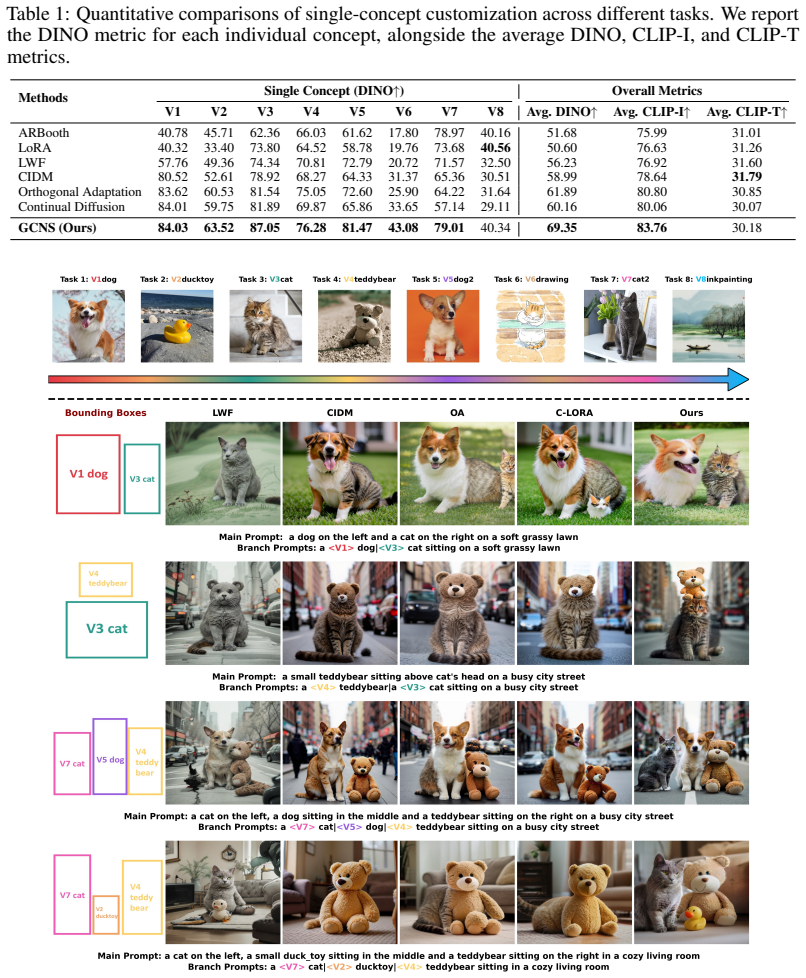
The authors introduce Gradient-based Concept Neuron Selection (GCNS) that identifies concept-relevant neurons via gradients and constrains only the conflicting parameters across sequential tasks, together with a context-aware composition strategy that performs multi-branch feature modeling and localized cross-attention fusion under spatial guidance; these two components together mitigate catastrophic forgetting in continual single-concept learning and reduce feature entanglement in multi-concept synthesis.
What carries the argument
Gradient-based Concept Neuron Selection (GCNS), which identifies concept-relevant neurons and constrains only conflicting parameters across tasks.
If this is right
- Long sequences of personalization tasks become feasible without replay buffers or model expansion.
- Multi-concept images can be synthesized with explicit spatial control over each concept's placement and attributes.
- The same neuron-selection principle could be applied to other autoregressive or diffusion-based generators that suffer from sequential interference.
- Generation time remains comparable to the base VAR model because no additional parameters are stored per concept.
Where Pith is reading between the lines
- If GCNS scales to open-ended user streams, personal image models could evolve continuously on-device without cloud retraining.
- The spatial fusion mechanism might generalize to video or 3-D generation where concepts must occupy consistent locations across frames.
- Testing whether the selected neurons remain stable when the base model is later fine-tuned on unrelated data would reveal limits of the method.
Load-bearing premise
Identifying a small set of concept-relevant neurons through gradients and freezing only the parameters that conflict with prior tasks is enough to block forgetting for any sequence of user concepts.
What would settle it
A sequence of ten or more distinct user concepts learned one after another; after the final concept is added, early concepts should still generate accurate images when prompted, without visible degradation or mixing of later attributes.
Figures





read the original abstract
Visual autoregressive (VAR) models have recently emerged as an efficient paradigm for text-to-image generation. Despite their strong generative capability, existing VAR-based personalization methods remain limited to static settings, failing to accommodate evolving user demands. In particular, sequential concept learning leads to severe catastrophic forgetting, while multi-concept synthesis often suffers from feature entanglement and attribute inconsistency. In this work, we present the first systematic study of continual personalized generation in VAR models. We identify two key challenges: (i) preserving previously learned concepts during sequential customization, and (ii) composing multiple personalized concepts in a controllable manner. To address these issues, we propose a unified framework with two core components. For continual single-concept learning, we introduce Gradient-based Concept Neuron Selection (GCNS), which identifies concept-relevant neurons and constrains only conflicting parameters across tasks, effectively mitigating forgetting without additional model expansion. For multi-concept synthesis, we propose a context-aware composition strategy that performs multi-branch feature modeling and localized cross-attention fusion guided by spatial conditions, enabling precise and disentangled concept composition. Extensive experiments demonstrate that our method significantly improves performance in long-sequence continual personalization while achieving superior results in multi-concept image synthesis compared to existing baselines. These findings highlight the potential of VAR models for scalable and controllable personalized generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CPC-VAR, a unified framework for continual personalized and compositional generation in Visual Autoregressive (VAR) models. It addresses catastrophic forgetting in sequential single-concept learning via Gradient-based Concept Neuron Selection (GCNS), which identifies concept-relevant neurons and constrains only conflicting parameters without model expansion or replay. For multi-concept synthesis, it proposes a context-aware composition strategy using multi-branch feature modeling and localized cross-attention fusion guided by spatial conditions. The authors claim that extensive experiments demonstrate significant improvements in long-sequence continual personalization and superior results in multi-concept image synthesis over existing baselines.
Significance. If the central claims hold, this work would be significant for enabling scalable continual personalization in efficient VAR architectures without requiring model growth or buffers, potentially advancing controllable multi-concept generation for evolving user demands in text-to-image systems.
major comments (2)
- [§3.1] §3.1 (GCNS description): The claim that constraining only conflicting parameters after gradient-based neuron selection suffices to prevent catastrophic forgetting across arbitrary sequences rests on the unverified premise that selected neurons remain sufficiently disjoint; no explicit measurement of neuron overlap or cumulative parameter drift over sequences longer than 5 tasks is provided, which is load-bearing for the no-expansion/no-replay assertion.
- [§4] §4 (Experiments): The reported superiority in long-sequence continual personalization lacks ablations that isolate the contribution of the parameter-constraint step (e.g., GCNS without constraints) and does not report retention metrics or statistical significance across task sequences, undermining verification of the mitigation effectiveness.
minor comments (2)
- [Abstract] Abstract: The summary of results refers to 'extensive experiments' and 'existing baselines' without naming datasets, metrics, or the number of tasks/sequences evaluated, reducing clarity for readers.
- [§3.2] Notation in §3.2: The context-aware composition strategy would benefit from an explicit equation or pseudocode for the localized cross-attention fusion to clarify how spatial conditions guide the multi-branch modeling.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below and outline the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (GCNS description): The claim that constraining only conflicting parameters after gradient-based neuron selection suffices to prevent catastrophic forgetting across arbitrary sequences rests on the unverified premise that selected neurons remain sufficiently disjoint; no explicit measurement of neuron overlap or cumulative parameter drift over sequences longer than 5 tasks is provided, which is load-bearing for the no-expansion/no-replay assertion.
Authors: We agree that explicit measurements of neuron overlap and cumulative parameter drift would provide stronger empirical support for the premise that selected neurons remain sufficiently disjoint. In the revised manuscript, we will add an analysis section with visualizations and quantitative metrics of neuron overlap across tasks as well as cumulative parameter drift for sequences of up to 10 tasks. revision: yes
-
Referee: [§4] §4 (Experiments): The reported superiority in long-sequence continual personalization lacks ablations that isolate the contribution of the parameter-constraint step (e.g., GCNS without constraints) and does not report retention metrics or statistical significance across task sequences, undermining verification of the mitigation effectiveness.
Authors: We concur that isolating the parameter-constraint component and adding retention metrics with statistical significance would improve verification. We will include the requested ablations (GCNS without constraints) and report retention metrics together with standard deviations and significance tests over multiple random task sequences in the updated experiments section. revision: yes
Circularity Check
No circularity: method components and claims rest on experimental validation rather than self-referential definitions or fitted inputs
full rationale
The abstract and provided text introduce GCNS for neuron selection and a context-aware composition strategy as novel components to mitigate forgetting and enable disentangled synthesis in VAR models. No equations, derivations, or parameter-fitting steps are described that reduce claimed performance gains to inputs by construction. The central claims are supported by reference to extensive experiments comparing against baselines, without load-bearing self-citations, uniqueness theorems from prior author work, or renaming of known results as new derivations. The approach is presented as building on standard neural network techniques with added constraints, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gradient signals reliably identify concept-specific neurons without excessive noise from task interference
- domain assumption Spatial conditions can be used to guide disentangled feature fusion without introducing new artifacts
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Gradient-based Concept Neuron Selection (GCNS), which identifies concept-relevant neurons and constrains only conflicting parameters across tasks
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Ltotal = Lvar(θt) + λ∥Mreg ⊙ (θt − θold)∥2 2
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Coyo-700m: Image-text pair dataset
Minwoo Byeon, Beomhee Park, Haecheon Kim, Sungjun Lee, Woonhyuk Baek, and Sae- hoon Kim. Coyo-700m: Image-text pair dataset. https://github.com/kakaobrain/ coyo-dataset, 2022
work page 2022
-
[2]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
work page 2021
-
[3]
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models.ACM transactions on Graphics (TOG), 42(4):1–10, 2023
work page 2023
-
[4]
Anydoor: Zero-shot object-level image customization
Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, and Hengshuang Zhao. Anydoor: Zero-shot object-level image customization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6593–6602, 2024
work page 2024
-
[5]
Fine-tuning visual autogressive models for subject-driven generation
Jiwoo Chung, Sangeek Hyun, Hyunjun Kim, Eunseo Koh, MinKyu Lee, and Jae-Pil Heo. Fine-tuning visual autogressive models for subject-driven generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19174–19184, 2025
work page 2025
-
[6]
Jiahua Dong, Wenqi Liang, Hongliu Li, Duzhen Zhang, Meng Cao, Henghui Ding, Salman Khan, and Fahad S Khan. How to continually adapt text-to-image diffusion models for flexible customization?Advances in Neural Information Processing Systems, 37:130057–130083, 2024
work page 2024
-
[7]
Federated class-incremental learning
Jiahua Dong, Lixu Wang, Zhen Fang, Gan Sun, Shichao Xu, Xiao Wang, and Qi Zhu. Federated class-incremental learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10164–10173, 2022
work page 2022
-
[8]
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Dennis Wei, and Sijia Liu. Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation.arXiv preprint arXiv:2310.12508, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Weixi Feng, Xuehai He, Tsu-Jui Fu, Varun Jampani, Arjun Akula, Pradyumna Narayana, Sugato Basu, Xin Eric Wang, and William Yang Wang. Training-free structured diffusion guidance for compositional text-to-image synthesis.arXiv preprint arXiv:2212.05032, 2022
-
[10]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion.arXiv preprint arXiv:2208.01618, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Rinon Gal, Moab Arar, Yuval Atzmon, Amit H Bermano, Gal Chechik, and Daniel Cohen- Or. Encoder-based domain tuning for fast personalization of text-to-image models.ACM Transactions on Graphics (TOG), 42(4):1–13, 2023
work page 2023
-
[12]
Yuchao Gu, Xintao Wang, Jay Zhangjie Wu, Yujun Shi, Yunpeng Chen, Zihan Fan, Wuyou Xiao, Rui Zhao, Shuning Chang, Weijia Wu, et al. Mix-of-show: Decentralized low-rank adaptation for multi-concept customization of diffusion models.Advances in Neural Information Processing Systems, 36:15890–15902, 2023
work page 2023
-
[13]
Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis
Jian Han, Jinlai Liu, Yi Jiang, Bin Yan, Yuqi Zhang, Zehuan Yuan, Bingyue Peng, and Xiaobing Liu. Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 15733–15744, 2025. 10
work page 2025
-
[14]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[15]
Sangwon Jang, Jaehyeong Jo, Kimin Lee, and Sung Ju Hwang. Identity decoupling for multi- subject personalization of text-to-image models.Advances in Neural Information Processing Systems, 37:100895–100937, 2024
work page 2024
-
[16]
Jimyeong Kim, Jungwon Park, and Wonjong Rhee. Selectively informative description can reduce undesired embedding entanglements in text-to-image personalization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8312–8322, 2024
work page 2024
-
[17]
Multi- concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi- concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1931–1941, 2023
work page 1931
-
[18]
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale.International journal of computer vision, 128(7):1956–1981, 2020
work page 1956
-
[19]
Aligning Text-to-Image Models using Human Feedback
Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing Du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, and Shixiang Shane Gu. Aligning text-to-image models using human feedback.arXiv preprint arXiv:2302.12192, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Dongxu Li, Junnan Li, and Steven Hoi. Blip-diffusion: Pre-trained subject representation for controllable text-to-image generation and editing.Advances in Neural Information Processing Systems, 36:30146–30166, 2023
work page 2023
-
[21]
Gligen: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22511–22521, 2023
work page 2023
-
[22]
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017
work page 2017
-
[23]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Di- rected diffusion: Direct control of object placement through attention guidance
Wan-Duo Kurt Ma, Avisek Lahiri, John P Lewis, Thomas Leung, and W Bastiaan Kleijn. Di- rected diffusion: Direct control of object placement through attention guidance. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 4098–4106, 2024
work page 2024
-
[25]
Saman Motamed, Danda Pani Paudel, and Luc Van Gool. Lego: Learning to disentangle and invert personalized concepts beyond object appearance in text-to-image diffusion models.arXiv preprint arXiv:2311.13833, 2023
-
[26]
Jisu Nam, Heesu Kim, DongJae Lee, Siyoon Jin, Seungryong Kim, and Seunggyu Chang. Dreammatcher: Appearance matching self-attention for semantically-consistent text-to-image personalization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8100–8110, 2024
work page 2024
-
[27]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[28]
Orthogonal adaptation for modular customization of diffusion models
Ryan Po, Guandao Yang, Kfir Aberman, and Gordon Wetzstein. Orthogonal adaptation for modular customization of diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7964–7973, 2024
work page 2024
-
[29]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 11
work page 2021
-
[30]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017
work page 2001
-
[32]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[33]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500–22510, 2023
work page 2023
-
[34]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs.arXiv preprint arXiv:2111.02114, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
A survey of multimodal-guided image editing with text-to-image diffusion models
X Shuai, H Ding, X Ma, R Tu, YG Jiang, and D Tao. A survey of multimodal-guided image editing with text-to-image diffusion models. arxiv 2024.arXiv preprint arXiv:2406.14555
-
[36]
SmoothGrad: removing noise by adding noise
Daniel Smilkov, Nikhil Thorat, Been Kim, Fernanda Viégas, and Martin Wattenberg. Smooth- grad: removing noise by adding noise.arXiv preprint arXiv:1706.03825, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
James Seale Smith, Yen-Chang Hsu, Lingyu Zhang, Ting Hua, Zsolt Kira, Yilin Shen, and Hongxia Jin. Continual diffusion: Continual customization of text-to-image diffusion with c-lora.arXiv preprint arXiv:2304.06027, 2023
-
[38]
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
work page 2024
-
[39]
Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
work page 2017
-
[40]
Human preference score: Better aligning text-to-image models with human preference
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score: Better aligning text-to-image models with human preference. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2096–2105, 2023
work page 2096
-
[41]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems, 36:15903–15935, 2023
work page 2023
-
[42]
Yang Yang, Wen Wang, Liang Peng, Chaotian Song, Yao Chen, Hengjia Li, Xiaolong Yang, Qinglin Lu, Deng Cai, Xiaofei He, et al. Lora-composer: Leveraging low-rank adaptation for multi-concept customization in training-free diffusion models.IEEE Transactions on Image Processing, 34:8145–8158, 2025
work page 2025
-
[43]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, et al. Scaling autoregressive models for content-rich text-to-image generation.arXiv preprint arXiv:2206.10789, 2(3):5, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
Attention calibration for disentan- gled text-to-image personalization
Yanbing Zhang, Mengping Yang, Qin Zhou, and Zhe Wang. Attention calibration for disentan- gled text-to-image personalization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4764–4774, 2024
work page 2024
-
[45]
Motiondirector: Motion customization of text-to-video diffusion models
Rui Zhao, Yuchao Gu, Jay Zhangjie Wu, David Junhao Zhang, Jia-Wei Liu, Weijia Wu, Jussi Keppo, and Mike Zheng Shou. Motiondirector: Motion customization of text-to-video diffusion models. InEuropean Conference on Computer Vision, pages 273–290. Springer, 2024. 12
work page 2024
-
[46]
Yue Zhao, Yuanjun Xiong, and Philipp Krähenbühl. Image and video tokenization with binary spherical quantization.arXiv preprint arXiv:2406.07548, 2024
-
[47]
Xinhao Zhong, Yimin Zhou, Zhiqi Zhang, Junhao Li, Yi Sun, Bin Chen, Shu-Tao Xia, Xuan Wang, and Ke Xu. Closing the safety gap: Surgical concept erasure in visual autoregressive models.arXiv preprint arXiv:2509.22400, 2025. A Technical appendices and supplementary material A.1 Baseline method ARBooth[5]We clone the code base of ARBooth from official GitHub...
-
[48]
During the inference phase, we employ Elastic Weight Aggregation to fuse the LoRA weights across distinct tasks. Orthogonal Adaptation[28]We adapt Orthogonal Adaption to the Infinity model by ourselves because official code is not available. We use the randomized orthogonal basis, which is consistent with the paper. The learning rate of text embedding is ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.