Interpretable Temporal Facial-Region Motion Analysis for In-the-Wild Parkinson's Disease Video Classification
Pith reviewed 2026-06-27 16:56 UTC · model grok-4.3
The pith
Normalized velocity descriptors from 14 facial regions classify in-the-wild Parkinson's videos at 0.826 balanced accuracy using a Random Forest.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
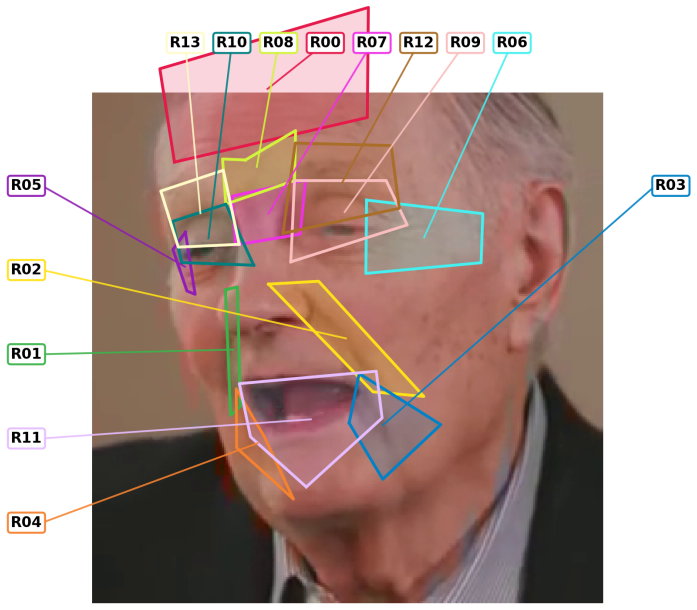
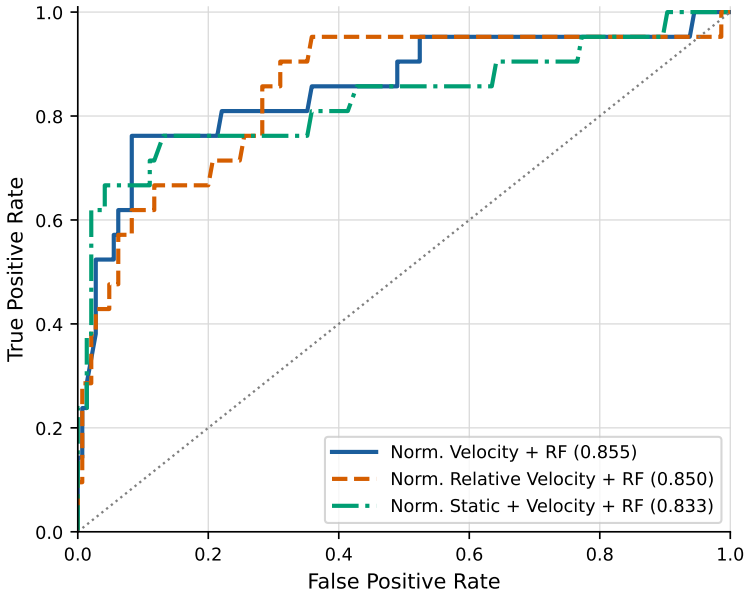
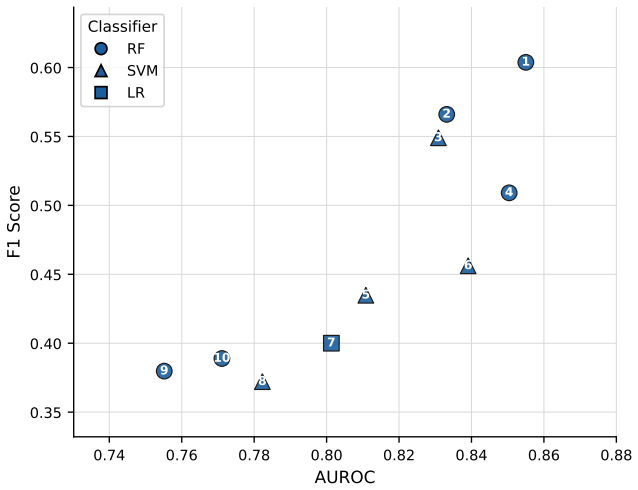
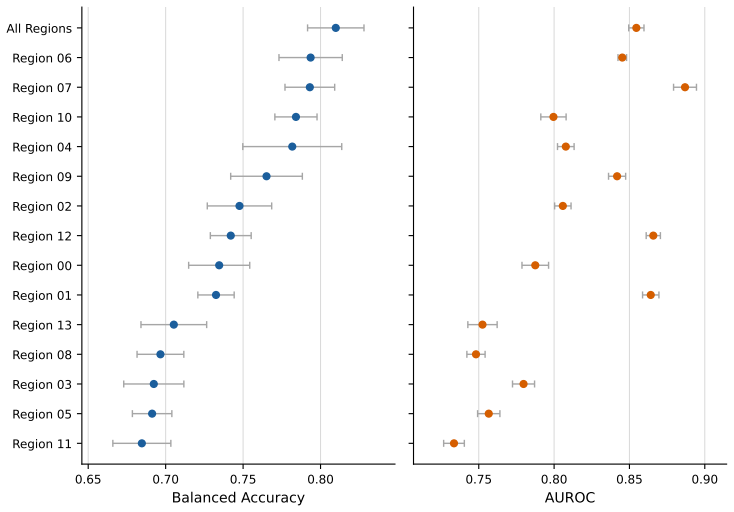
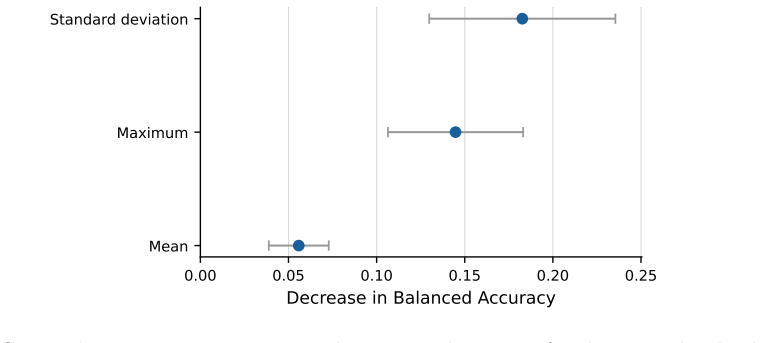
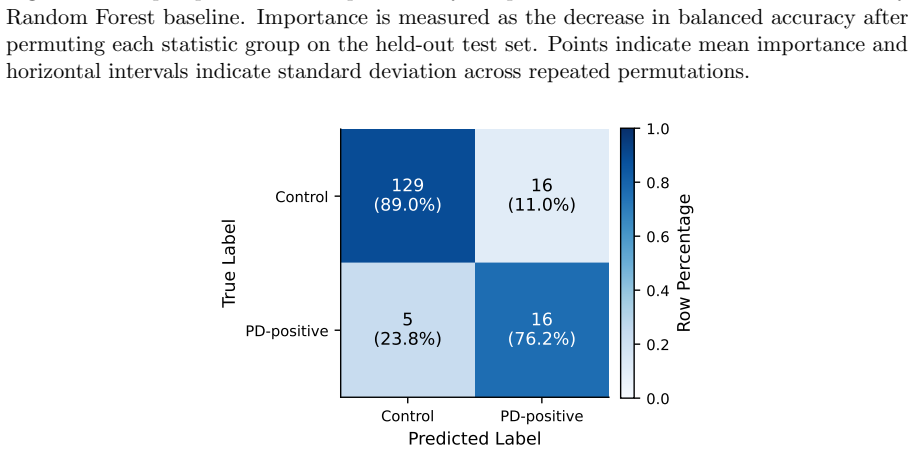
Normalized velocity descriptors computed over 14 predefined facial regions, when fed to a Random Forest, reach 0.826 balanced accuracy and 0.855 AUROC on the held-out YouTubePD test split; the same representation remains stable across ten random seeds (0.810 ± 0.018 balanced accuracy). Static geometry, un-normalized velocity, relative velocity, and a GRU sequence model all underperform this combination under identical protocol. Region ablation and permutation importance further show that the method is interpretable at the level of individual facial areas.
What carries the argument
Normalized velocity descriptors: per-region Euclidean displacements between consecutive frames, scaled by the inter-ocular distance of that frame, aggregated over time and used as input features to a Random Forest classifier.
If this is right
- The representation is stable enough that performance does not depend on a single random seed.
- Ablation shows that performance drops when any of the 14 regions is removed, indicating distributed rather than single-region information.
- Permutation importance ranks regions consistently, supplying an explicit map from motion statistics to classification decisions.
- The same descriptors remain competitive with a recurrent baseline while remaining fully interpretable by inspection of feature importances.
Where Pith is reading between the lines
- Because the features are derived only from 2D keypoints, the pipeline could be re-run on any existing video archive without new recordings.
- If the same descriptors were computed on videos paired with MDS-UPDRS facial scores, a regression extension might test whether motion magnitude tracks clinical severity.
- The seed-robustness result implies that future work can focus on dataset shift rather than hyper-parameter sensitivity when moving to new video sources.
Load-bearing premise
The YouTubePD videos constitute an unbiased and correctly labeled sample of real-world PD versus non-PD cases.
What would settle it
Retraining the identical normalized-velocity-plus-Random-Forest pipeline on a new dataset whose labels come from in-person neurological examination and observing balanced accuracy fall below 0.70 would falsify the claim that the descriptors reliably separate the classes.
Figures
read the original abstract
Reduced facial expressivity is a common motor manifestation of Parkinson's disease (PD), often described as hypomimia or facial bradykinesia. This paper examines whether temporal motion descriptors extracted from facial-region keypoints can support in-the-wild PD-related video classification on the YouTubePD benchmark. Each video is represented using geometric descriptors from 14 predefined facial regions. Static geometry, normalized geometry, velocity-based descriptors, relative-velocity descriptors, and a GRU sequence baseline are compared under the same binary classification protocol. To assess stability and interpretability, the study includes seed-robustness analysis, region-level ablation, and permutation importance. The best result is obtained with normalized velocity descriptors and a Random Forest classifier, reaching a balanced accuracy of 0.826 and an AUROC of 0.855 on the held-out test split. Across 10 random seeds, this representation remains stable, with balanced accuracy of 0.810 +/- 0.018 and AUROC of 0.855 +/- 0.005. Overall, the results suggest that normalized facial-region motion is a lightweight and interpretable representation for YouTubePD video classification. The study is framed as a benchmark-level analysis and does not claim clinical severity assessment or MDS-UPDRS facial-expression scoring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates temporal motion descriptors extracted from 14 predefined facial regions in videos for binary classification of Parkinson's disease (PD) versus non-PD on the YouTubePD benchmark. It compares static geometry, normalized geometry, velocity-based descriptors, relative-velocity descriptors, and a GRU baseline, reporting that normalized velocity descriptors paired with a Random Forest classifier achieve the highest performance: balanced accuracy 0.826 and AUROC 0.855 on the held-out test split. The work includes seed-robustness checks (stable at 0.810 ± 0.018 balanced accuracy across 10 seeds), region-level ablation, and permutation importance analysis, framing the contribution as a lightweight, interpretable benchmark study without clinical diagnostic claims.
Significance. If the YouTubePD labels are reliable, the results demonstrate that normalized facial-region velocity features can support stable in-the-wild PD video classification with competitive metrics and built-in interpretability via ablation and permutation importance. The explicit seed-robustness analysis, region ablation, and permutation importance are strengths that increase confidence in the empirical findings and distinguish the work from purely black-box approaches.
major comments (1)
- [Data / benchmark description (likely §3 or Methods)] Data / benchmark description (likely §3 or Methods): The central claim of 0.826 balanced accuracy / 0.855 AUROC on the held-out split rests on the assumption that YouTubePD provides correctly labeled, unbiased PD vs. non-PD samples. No details are given on label provenance (self-report vs. verified diagnosis), inter-rater checks, or mitigation of YouTube-specific selection bias and recording variability; without this, the numeric results cannot be interpreted as evidence for the descriptors' utility.
minor comments (2)
- [Abstract] Abstract: The phrase 'normalized velocity descriptors' is used without a brief parenthetical definition or reference to the exact computation (e.g., which keypoints and normalization), reducing immediate clarity for readers.
- [Results] Results section: The reported standard deviations across 10 seeds are given only for the best model; providing the same statistics for the other descriptor/classifier combinations would strengthen the comparative claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the strengths of our seed-robustness checks, region ablation, and permutation importance analysis. We address the single major comment below and will revise the manuscript to improve the benchmark description.
read point-by-point responses
-
Referee: [Data / benchmark description (likely §3 or Methods)] Data / benchmark description (likely §3 or Methods): The central claim of 0.826 balanced accuracy / 0.855 AUROC on the held-out split rests on the assumption that YouTubePD provides correctly labeled, unbiased PD vs. non-PD samples. No details are given on label provenance (self-report vs. verified diagnosis), inter-rater checks, or mitigation of YouTube-specific selection bias and recording variability; without this, the numeric results cannot be interpreted as evidence for the descriptors' utility.
Authors: We agree that the manuscript requires a clearer description of the YouTubePD benchmark to allow proper interpretation of the reported metrics. In the revised version we will add a dedicated subsection (likely in §3) that summarizes the benchmark construction as described in its original reference: labels derive from self-reported PD status in video titles/descriptions for the positive class and from control videos for the negative class. We will explicitly note the absence of clinical verification or inter-rater reliability metrics and acknowledge YouTube-specific selection and recording biases. This addition will frame the work strictly as a benchmark study on the given dataset. We cannot supply verified medical diagnoses or new inter-rater data, as these are outside the scope of the public benchmark and would require an entirely different data-collection protocol. revision: yes
- Absence of clinically verified diagnoses and inter-rater reliability statistics for YouTubePD labels, which are inherent limitations of the public benchmark and cannot be retroactively supplied by the present study.
Circularity Check
No circularity: purely empirical benchmark results on held-out split
full rationale
The paper performs an empirical comparison of geometric and velocity-based facial descriptors for binary PD classification on the YouTubePD benchmark using standard classifiers (Random Forest, GRU). Reported metrics (balanced accuracy 0.826, AUROC 0.855) are obtained directly from evaluation on an explicitly held-out test split, with seed-robustness and ablation checks. No derivation, uniqueness theorem, ansatz, or prediction is presented that reduces by construction to fitted inputs, self-citations, or renamed known results. The analysis is self-contained as standard ML benchmarking without load-bearing theoretical steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Facial keypoint detection is sufficiently accurate on in-the-wild YouTube videos to support velocity computation.
- domain assumption The binary PD/non-PD labels in YouTubePD are treated as ground truth without reported inter-rater reliability or clinical confirmation.
Reference graph
Works this paper leans on
-
[1]
Avner Abrami, Steven A. Gunzler, Ciara Kilbane, Vishwajit Murthy, Paolo Bonato, David Golan, Daniel Tarsy, Tanya Simuni, Terry D. Ellis, Jason Karlawish, et al. Automated computer vision assessment of hypomimia in parkinson disease: Proof-of-principle pilot study.Journal of Medical Internet Research, 23(2):e21037, 2021. doi: 10.2196/21037
-
[2]
OpenFace 2.0: Facial Behavior Analysis Toolkit
Tadas Baltruˇ saitis, Amir Zadeh, Yao Chong Lim, and Louis-Philippe Morency. OpenFace 2.0: Facial Behavior Analysis Toolkit. In2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), pages 59–66, 2018. doi: 10.1109/FG.2018.00019
-
[3]
Reyes-Garcia, Paolo Vanni, Gaetano Zaccara, and Claudia Manfredi
Andrea Bandini, Simone Orlandi, Hugo Jair Escalante, Francesco Giovannelli, Massimo Cincotta, Carlos A. Reyes-Garcia, Paolo Vanni, Gaetano Zaccara, and Claudia Manfredi. Automatic analysis of facial expressions in parkinson’s disease.Journal of Neuroscience Methods, 281:1–11, 2017. doi: 10.1016/j.jneumeth.2017.02.006. 20
-
[4]
Concept decompositions for large sparse text data using clustering
Leo Breiman. Random forests.Machine Learning, 45(1):5–32, 2001. doi: 10.1023/A: 1010933404324
work page doi:10.1023/a: 2001
-
[5]
Learning phrase representations using RNN encoder ⚶decoder for statistical machine translation
Kyunghyun Cho, Bart van Merri¨ enboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder–decoder for statistical machine translation. InProceedings of the 2014 Confer- ence on Empirical Methods in Natural Language Processing, pages 1724–1734, 2014. doi: 10.3115/v1/D14-1179
-
[6]
Corinna Cortes and Vladimir Vapnik. Support-vector networks.Machine Learning, 20(3): 273–297, 1995. doi: 10.1007/BF00994018
-
[7]
Lazzaro di Biase, Pasquale Maria Pecoraro, and Francesco Bugamelli. AI Video Analysis in Parkinson’s Disease: A Systematic Review of the Most Accurate Computer Vision Tools for Diagnosis, Symptom Monitoring, and Therapy Management.Sensors, 25(20):6373, 2025. doi: 10.3390/s25206373
-
[8]
Friesen.Facial Action Coding System: A Technique for the Measurement of Facial Movement
Paul Ekman and Wallace V. Friesen.Facial Action Coding System: A Technique for the Measurement of Facial Movement. Consulting Psychologists Press, Palo Alto, CA, 1978
1978
-
[9]
An introduction to ROC analysis.Pattern Recognition Letters, 27(8):861–874,
Tom Fawcett. An introduction to ROC analysis.Pattern Recognition Letters, 27(8):861–874,
-
[10]
doi: 10.1016/j.patrec.2005.10.010
-
[11]
Anas Filali Razzouki, Laetitia Jeancolas, Graziella Mangone, Sara Sambin, Aliz´ e Chalan¸ con, Manon Gomes, St´ ephane Leh´ ericy, Jean-Christophe Corvol, Marie Vidailhet, Isabelle Arnulf, Dijana Petrovska-Delacr´ etaz, and Mounim A. El-Yacoubi. Leveraging action unit derivatives for early-stage parkinson’s disease detection.IRBM, 46:100874, 2025. doi: 10...
-
[12]
Anas Filali Razzouki, Laetitia Jeancolas, Sara Sambin, Graziella Mangone, Aliz´ e Chalan¸ con, Manon Gomes, St´ ephane Leh´ ericy, Marie Vidailhet, Isabelle Arnulf, Jean-Christophe Corvol, Dijana Petrovska-Delacr´ etaz, and Mounim A. El-Yacoubi. Explaining facial action units’ correlation with hypomimia and clinical scores in parkinson’s disease.npj Parki...
-
[13]
Pattern Recognition40, 2110–2117 (2007).https://doi.org/10.1016/j.patcog
Anas Filali Razzouki, Laetitia Jeancolas, Dijana Petrovska-Delacr´ etaz, and Mounim A. El-Yacoubi. Facial Digital Markers for Hypomimia Detection in Parkinson’s Disease: A Systematic Review.Pattern Recognition, 172(Part C):112573, 2026. doi: 10.1016/j.patcog. 2025.112573
-
[14]
Aaron Fisher, Cynthia Rudin, and Francesca Dominici. All models are wrong, but many are useful: Learning a variable’s importance by studying an entire class of prediction models simultaneously.Journal of Machine Learning Research, 20(177):1–81, 2019. URL http://jmlr.org/papers/v20/18-760.html
2019
-
[15]
Christopher G. Goetz, Barbara C. Tilley, Stephanie R. Shaftman, Glenn T. Stebbins, Stanley Fahn, Pablo Martinez-Martin, Werner Poewe, Cristina Sampaio, Matthew B. Stern, Richard Dodel, Bruno Dubois, Robert Holloway, Joseph Jankovic, Jaime Kulisevsky, Anthony E. Lang, Andrew Lees, Sue Leurgans, Peter A. LeWitt, David Nyenhuis, C. Warren Olanow, Olivier Ras...
-
[16]
G´ omez, Aythami Morales, Julian Fierrez, and Juan R
Luis F. G´ omez, Aythami Morales, Julian Fierrez, and Juan R. Orozco-Arroyave. Exploring facial expressions and action unit domains for parkinson detection.PLOS ONE, 18(2): e0281248, 2023. doi: 10.1371/journal.pone.0281248
-
[17]
Long short-term memory.Neural Computation, 9(8): 1735–1780, 1997
Sepp Hochreiter and J¨ urgen Schmidhuber. Long short-term memory.Neural Computation, 9(8):1735–1780, 1997. doi: 10.1162/neco.1997.9.8.1735
-
[18]
Diagnosing parkinson disease through facial expression recognition: Video analysis.Journal of Medical Internet Research, 22(7):e18697,
Bo Jin, Yue Qu, Liang Zhang, and Zhan Gao. Diagnosing parkinson disease through facial expression recognition: Video analysis.Journal of Medical Internet Research, 22(7):e18697,
-
[19]
Michal Novotn´ y, Tereza Tykalov´ a, Hana R˚ uˇ ziˇ ckov´ a, Evˇ zen R˚ uˇ ziˇ cka, Petr Duˇ sek, and Jan Rusz. Automated video-based assessment of facial bradykinesia in de-novo parkinson’s disease.npj Digital Medicine, 5(1):98, 2022. doi: 10.1038/s41746-022-00642-5
-
[20]
Guilherme Oliveira, Quoc Ngo, Leandro Passos, Danilo Jodas, Jo˜ ao Papa, and Dinesh Kumar. Facial Expression Analysis in Parkinsons’s Disease Using Machine Learning: A Review.ACM Computing Surveys, 57(8):1–25, 2025. doi: 10.1145/3716818
-
[21]
Espay, Matteo Bologna, and Lazzaro di Biase
Pasquale Maria Pecoraro, Luca Marsili, Alberto J. Espay, Matteo Bologna, and Lazzaro di Biase. Computer Vision Technologies in Movement Disorders: A Systematic Review. Movement Disorders Clinical Practice, 12(9):1229–1243, 2025. doi: 10.1002/mdc3.70123
-
[22]
Elena Pegolo, Daniele Volpe, Alberto Cucca, Lucia Ricciardi, and Zimi Sawacha. Quantita- tive evaluation of hypomimia in parkinson’s disease: A face tracking approach.Sensors, 22 (4):1358, 2022. doi: 10.3390/s22041358
-
[23]
David M. W. Powers. Evaluation: From precision, recall and F-measure to ROC, informed- ness, markedness and correlation.Journal of Machine Learning Technologies, 2(1):37–63, 2011
2011
-
[24]
Takaya Saito and Marc Rehmsmeier. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets.PLOS ONE, 10(3): e0118432, 2015. doi: 10.1371/journal.pone.0118432
-
[25]
Mirian, Juana Ayala Castaneda, Michael Grundy, and Martin J
Eline Serb´ ee, Kye Won Park, Atefeh Irani, Maryam S. Mirian, Juana Ayala Castaneda, Michael Grundy, and Martin J. McKeown. Facial expression analysis to uncover the relationship between sialorrhea and hypomimia in parkinson’s disease.Frontiers in Neurology, 16:1661043, 2025. doi: 10.3389/fneur.2025.1661043
-
[26]
Ge Su, Bo Lin, Jianwei Yin, Wei Luo, Renjun Xu, Jie Xu, and Kexiong Dong. Detection of hypomimia in patients with parkinson’s disease via smile videos.Annals of Translational Medicine, 9(16):1307, 2021. doi: 10.21037/atm-21-3457
-
[27]
YouTubePD: A multimodal benchmark for parkinson’s disease analysis
Andy Zhou, Jiahua Dong, George Heintz, Volodymyr Kindratenko, Samuel Li, Xiang Li, Shirui Luo, Ansh Sharma, Pranav Sriram, Yu-Xiong Wang, Christopher Zallek, and Yuanyi Zhong. YouTubePD: A multimodal benchmark for parkinson’s disease analysis. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[28]
YouTubePD: A multimodal benchmark for parkinson’s disease analysis: Supplementary material
Andy Zhou, Jiahua Dong, George Heintz, Volodymyr Kindratenko, Samuel Li, Xiang Li, Shirui Luo, Ansh Sharma, Pranav Sriram, Yu-Xiong Wang, Christopher Zallek, and Yuanyi Zhong. YouTubePD: A multimodal benchmark for parkinson’s disease analysis: Supplementary material. Supplementary material for NeurIPS Datasets and Benchmarks, 2023. 22
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.