From Per-Image Low-Rank to Encoding Mismatch: Rethinking Feature Distillation in Vision Transformers
Pith reviewed 2026-05-17 20:19 UTC · model grok-4.3
The pith
An encoding mismatch from per-image low-rank features and rotating dataset subspaces blocks feature-map distillation for compressing Vision Transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Sample-wise SVD shows each image is highly compressible, yet dataset-level PCA reveals the teacher as a union of low-rank subspaces with substantial rotation across inputs. Token-level spectral energy patterns further show tokens distribute energy broadly across channel modes even inside low-rank subspaces. The combined effect is an encoding mismatch that prevents a compressed student from matching the teacher under standard feature-map distillation. Two lightweight remedies, Lift (retaining a wider projector at inference) and WideLast (widening only the final student block), eliminate the mismatch and raise DeiT-Tiny accuracy from 74.86 percent to 77.53 percent or 78.23 percent when distil
What carries the argument
encoding mismatch: the joint phenomenon of per-image low-rank compressibility, dataset-level subspace rotations, and broad token spectral energy patterns that together produce a channel-bandwidth mismatch for feature-map distillation.
If this is right
- Feature-map distillation regains effectiveness for ViT compression once the encoding mismatch is removed.
- Lift keeps a lightweight wider projector at test time while WideLast expands only the student's last block.
- The same fixes also improve students trained from scratch without any distillation.
- The mismatch accounts for why distillation works between equal-sized models but fails under compression.
Where Pith is reading between the lines
- Architectures that already widen their final layers may suffer less from the same mismatch when used as students.
- The subspace-rotation view suggests that input-dependent or conditional projectors could be explored beyond the two minimal fixes.
- Similar per-image versus dataset-level rank discrepancies might appear in other modalities or tasks where feature alignment is attempted.
Load-bearing premise
The per-image low-rank structure, dataset subspace rotations, and token spectral energy patterns are the main causal drivers of distillation failure rather than optimization or capacity limits.
What would settle it
Train a standard narrow student whose final projector is forced to match the teacher's observed subspace rotations and spectral energy distribution on the same data; if accuracy gains disappear without Lift or WideLast, the mismatch explanation is supported.
Figures
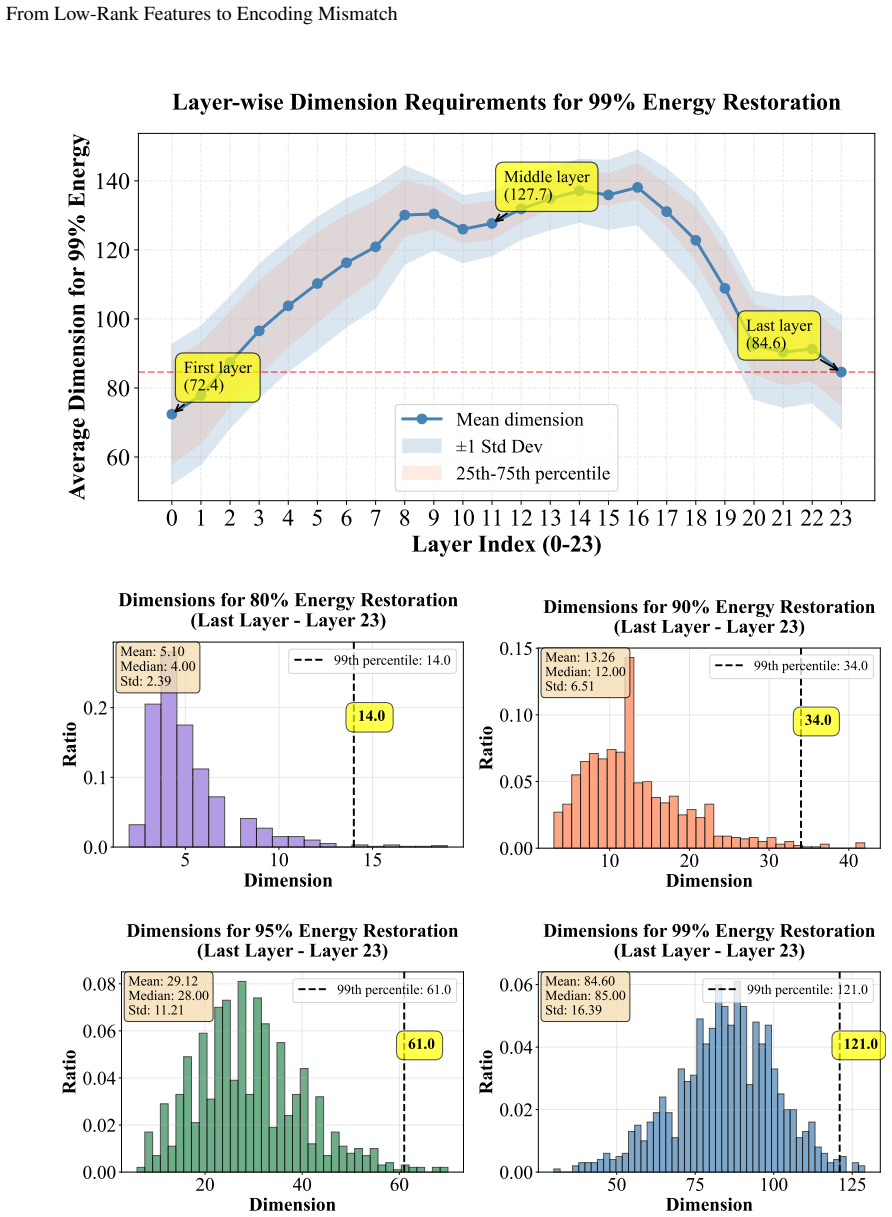
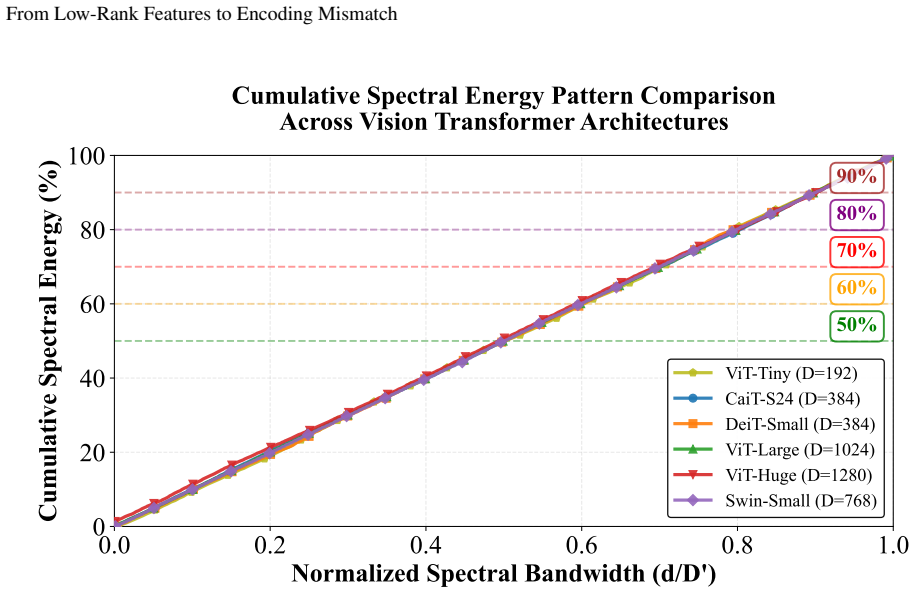






read the original abstract
Feature-map knowledge distillation (KD) transfers internal representations well between comparably sized Vision Transformers (ViTs), but it often fails in compression. We revisit this failure and uncover a paradox. Sample-wise SVD shows that each image is highly compressible, which seems to suggest that a narrow student with a linear projector should match the teacher "in principle". However, a dataset-level view contradicts this intuition: PCA shows that the teacher is a union of low-rank subspaces with significant subspace rotation across inputs. We further introduce token-level Spectral Energy Patterns (SEP) and find an architecture-invariant encoding law: tokens spread energy broadly across channel modes even when they live in low-rank subspace, creating a bandwidth mismatch. We refer to this combined phenomenon as an encoding mismatch. We propose two minimal remedies, Lift or WideLast: (i) Lift retains a lightweight lifting projector at inference to provide wider channel, or (ii) WideLast widens only the student's last block, enabling an input-dependent expansion. On ImageNet-1K, these fixes revive feature KD for ViT compression, improving DeiT-Tiny distilled from CaiT-S24 from 74.86% to 77.53%/78.23% top-1 accuracy, and they also strengthen students trained without distillation. Our analyses clarify when and why feature-map KD fails and then how to fix it. Code and raw data are provided in https://github.com/thy960112/From-Per-Image-Low-Rank-to-Encoding-Mismatch.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that feature-map knowledge distillation fails for ViT compression due to an 'encoding mismatch': per-image SVD shows low-rank structure (suggesting narrow students should suffice), but dataset-level PCA reveals subspace rotations across inputs, and token-level Spectral Energy Patterns (SEP) show broad energy distribution across channel modes despite low-rank subspaces. This mismatch explains KD underperformance. Two minimal fixes are proposed—Lift (retaining a lightweight projector at inference for wider channels) and WideLast (widening only the final student block for input-dependent expansion). On ImageNet-1K, these revive KD, e.g., improving DeiT-Tiny distilled from CaiT-S24 from 74.86% to 77.53%/78.23% top-1 accuracy, with gains also for non-distilled students. Code and raw data are released.
Significance. If the analyses establish causality and the remedies are shown to target the mismatch rather than add capacity, the work clarifies a key limitation in feature KD for ViT compression and provides simple, practical architectural adjustments. Credit is due for releasing code and raw data, enabling reproducibility. The application of SVD/PCA/SEP to diagnose KD behavior is a clear contribution, though the central claim hinges on linking the observations directly to the proposed fixes.
major comments (1)
- [Experiments section] Experiments section (ImageNet-1K results and Table reporting 74.86% → 77.53%/78.23% gains): the manuscript does not report subspace rotation angles or SEP bandwidth metrics for the Lift/WideLast students on the same teacher-student pairs before and after modification. Without this, the accuracy improvements cannot be unambiguously attributed to resolution of the encoding mismatch rather than increased effective capacity, weakening the causal claim for the remedies.
minor comments (2)
- [Abstract] Abstract: the introduction of 'Spectral Energy Patterns (SEP)' and 'encoding mismatch' would benefit from a one-sentence definition to aid readers before the detailed sections.
- Notation: ensure consistent use of 'channel modes' versus 'feature dimensions' when describing SEP across sections to avoid minor ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and will revise the manuscript to incorporate the requested analysis.
read point-by-point responses
-
Referee: [Experiments section] Experiments section (ImageNet-1K results and Table reporting 74.86% → 77.53%/78.23% gains): the manuscript does not report subspace rotation angles or SEP bandwidth metrics for the Lift/WideLast students on the same teacher-student pairs before and after modification. Without this, the accuracy improvements cannot be unambiguously attributed to resolution of the encoding mismatch rather than increased effective capacity, weakening the causal claim for the remedies.
Authors: We agree that the manuscript currently does not report subspace rotation angles or SEP bandwidth metrics for the Lift and WideLast variants. To strengthen the causal attribution of the accuracy gains to resolution of the encoding mismatch (rather than capacity increase alone), we will compute and add these metrics for the modified students on the same teacher-student pairs in the revised manuscript, enabling direct before-and-after comparison. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's central claims rest on empirical observations obtained by applying standard linear-algebra operations (sample-wise SVD, dataset-level PCA, and token-level spectral energy patterns) to extracted feature maps. These observations are then used to motivate the architectural remedies Lift and WideLast, whose effects are measured on held-out ImageNet-1K validation data. No equation or derivation reduces by construction to a fitted parameter, self-citation, or renamed input; the analysis remains externally falsifiable and does not rely on load-bearing self-references.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Singular value decomposition and principal component analysis can be used to characterize rank and subspace structure of feature maps
- domain assumption Feature-map knowledge distillation transfers internal representations between teacher and student Vision Transformers
invented entities (2)
-
encoding mismatch
no independent evidence
-
Spectral Energy Patterns (SEP)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Attention Transfer Is Not Universally Effective for Vision Transformers
Attention transfer from ViT teachers succeeds for only 7 of 11 families and fails for the rest because of architectural mismatch between teacher and student.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.