Editing Everything Everywhere All at Once
Pith reviewed 2026-07-01 06:08 UTC · model grok-4.3
The pith
MICE modifies additive bias in joint attention of diffusion transformers using segmentation masks to bind multiple concurrent edits to their instances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
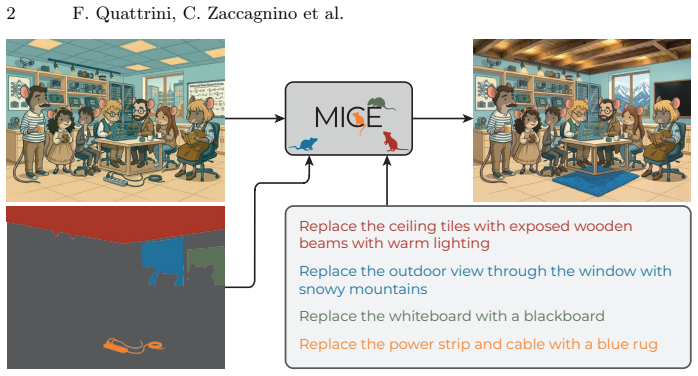
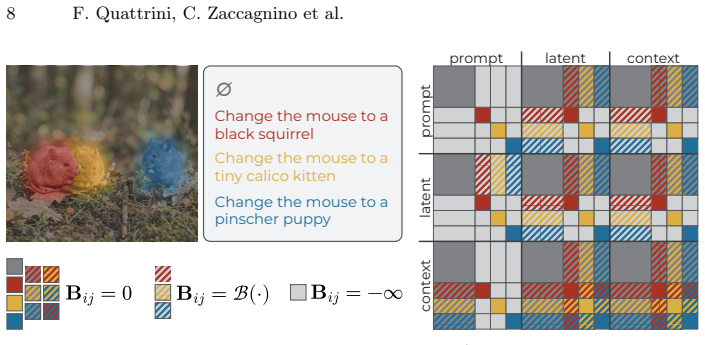
MICE modifies the additive bias of joint attention to regulate interactions between instance-specific edit instructions, latent, and context tokens identified via user-provided segmentation masks. Specifically, MICE allows intra-instance attention, penalizes interactions between neighboring region tokens, and suppresses unrelated cross-instance attention. As a result, our method enforces attribute binding while preserving global visual consistency.
What carries the argument
Additive bias modification in joint attention, which uses instance masks to selectively permit, penalize, or suppress token interactions during multi-edit diffusion.
If this is right
- Multi-instance editing becomes practical in one forward pass instead of sequential turns.
- Attribute leakage drops because cross-instance attention is suppressed by the bias change.
- Visual consistency holds as intra-instance attention and neighbor penalties are applied together.
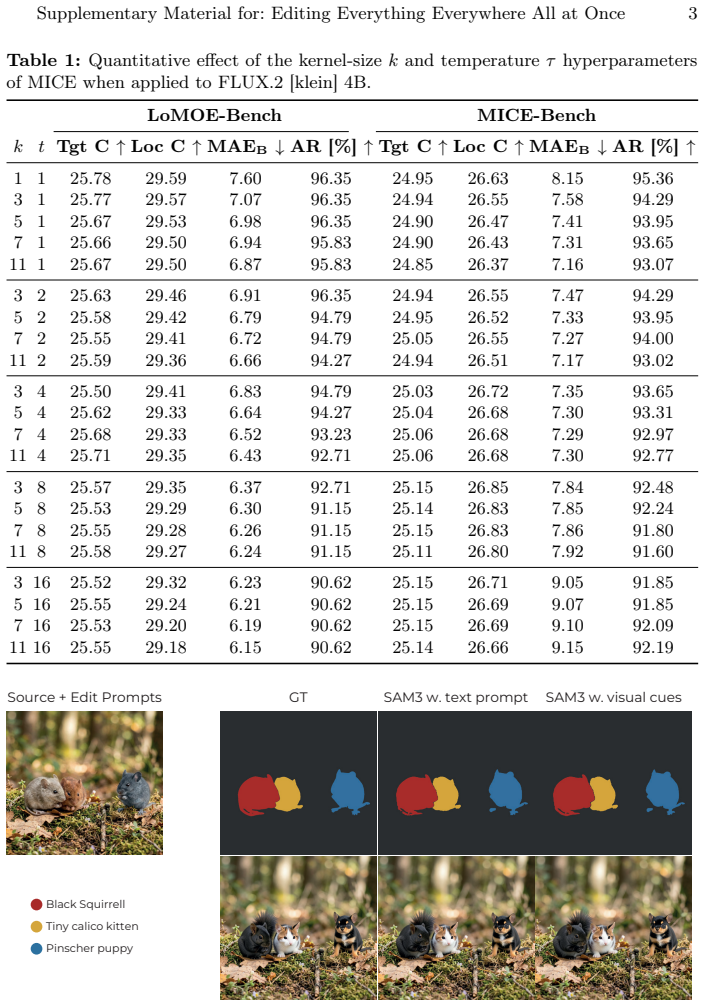
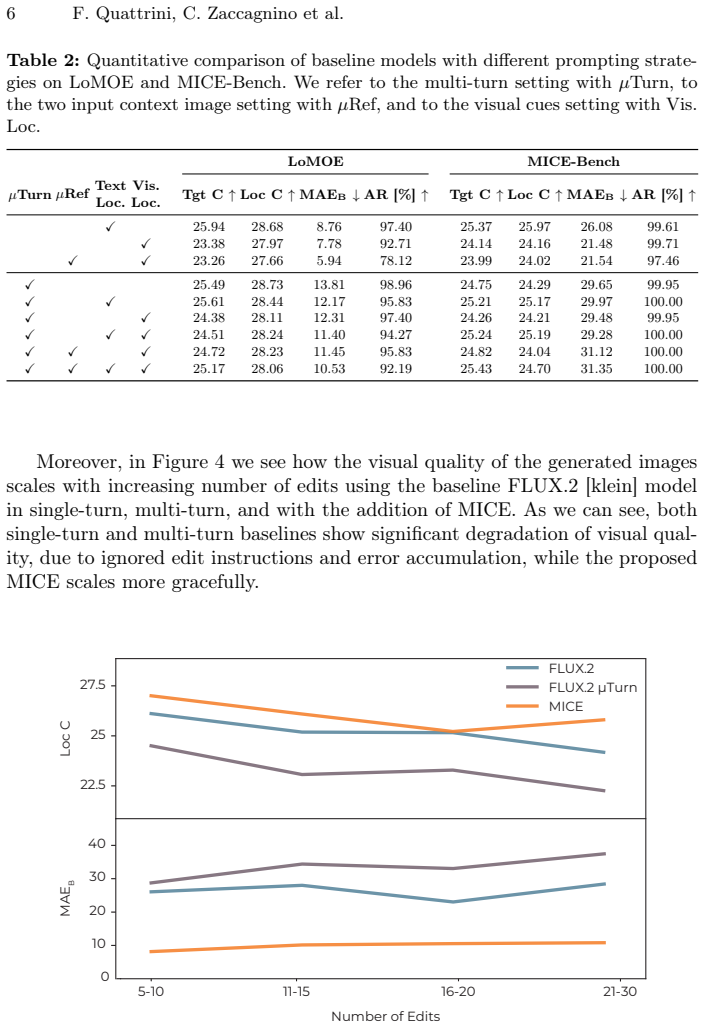
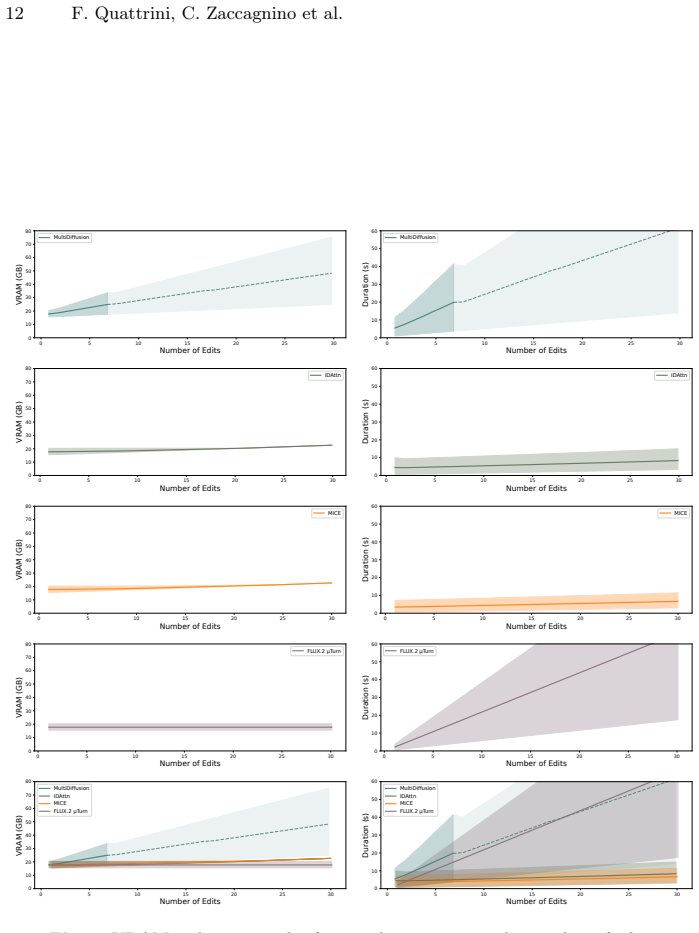
- The method scales to higher edit counts, as shown on the introduced MICE-Bench.
Where Pith is reading between the lines
- If the bias rule generalizes, similar mask-driven attention edits could apply to other transformer-based image generators.
- Automatic mask predictors could replace manual segmentation to make the workflow fully automatic.
- The same regulation might reduce interference when editing video frames that share a common background.
Load-bearing premise
User-provided segmentation masks correctly label the relevant tokens for each edit, and the chosen bias adjustments will stop attribute leakage across any number of edits without creating new visual artifacts.
What would settle it
Images with 8 or more simultaneous edits where MICE still shows clear attribute leakage between regions despite accurate input masks would falsify the central claim.
Figures












read the original abstract
Editing multiple elements of an image in a single forward pass is a practical alternative to multi-turn image manipulation, offering improved efficiency and potentially better harmonization. However, when several instructions target different regions, semantic interference often leads to attribute leakage and poor edit disentanglement, especially as the number of edits increases. In this work, we propose MICE (Multi-Instance Concurrent Editing), a training-free strategy for scalable multi-instance image editing with Multimodal Diffusion Transformers. MICE modifies the additive bias of joint attention to regulate interactions between instance-specific edit instructions, latent, and context tokens identified via user-provided segmentation masks. Specifically, MICE allows intra-instance attention, penalizes interactions between neighboring region tokens, and suppresses unrelated cross-instance attention. As a result, our method enforces attribute binding while preserving global visual consistency. We evaluate MICE on LoMOE-Bench and introduce MICE-Bench, a more challenging benchmark with an average of 8.5 concurrent edits per image. The experiments demonstrate that our approach outperforms strong baselines and recent competitors in terms of visual quality preservation and faithfulness to the editing instructions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MICE (Multi-Instance Concurrent Editing), a training-free strategy for scalable multi-instance image editing with Multimodal Diffusion Transformers. MICE modifies the additive bias of joint attention to regulate interactions between instance-specific edit instructions, latent, and context tokens identified via user-provided segmentation masks. Specifically, it allows intra-instance attention, penalizes interactions between neighboring region tokens, and suppresses unrelated cross-instance attention. This is claimed to enforce attribute binding while preserving global visual consistency. The method is evaluated on LoMOE-Bench and a new MICE-Bench (average 8.5 concurrent edits per image), with the abstract stating outperformance over strong baselines and recent competitors in visual quality preservation and faithfulness to editing instructions.
Significance. If substantiated by detailed experiments, the approach could provide a practical efficiency gain for concurrent multi-edit tasks in diffusion models by addressing semantic interference without retraining. The introduction of MICE-Bench is a constructive addition for testing scalability. However, the central claim of reliable disentanglement via heuristic attention bias changes rests on unverified experimental support and lacks derivation of why the specific modifications regulate interactions without side effects on the diffusion trajectory.
major comments (2)
- [Abstract] Abstract: The claim that 'our approach outperforms strong baselines and recent competitors' is stated without any quantitative metrics, tables, error analysis, or specific numbers (e.g., no FID, CLIP scores, or success rates), which is load-bearing for the central claim of improved disentanglement and faithfulness.
- [Method (MICE bias modification)] Method description of MICE: The bias modifications (intra-instance allowance + neighbor penalization + cross-instance suppression conditioned on masks) are presented as an ad-hoc change to attention logits with no analysis or derivation showing why these particular terms achieve the claimed regulation of token interactions rather than producing unintended global shifts or new inconsistencies across the diffusion trajectory; this directly impacts the weakest assumption that the heuristic will reliably prevent attribute leakage for ~8.5 edits.
minor comments (1)
- [Abstract] Abstract: The benchmark construction details for MICE-Bench (e.g., how the average of 8.5 edits is achieved, mask quality assumptions) are referenced but not elaborated, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and method. We address each major comment below, clarifying the experimental support present in the manuscript and noting where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'our approach outperforms strong baselines and recent competitors' is stated without any quantitative metrics, tables, error analysis, or specific numbers (e.g., no FID, CLIP scores, or success rates), which is load-bearing for the central claim of improved disentanglement and faithfulness.
Authors: We agree the abstract would benefit from explicit metrics to support the outperformance claim. The full manuscript reports quantitative results in the experiments section, including CLIP-based faithfulness scores, visual quality metrics, and success rates on both LoMOE-Bench and MICE-Bench (with average 8.5 edits). We will revise the abstract to include key numerical comparisons demonstrating gains in attribute binding and consistency. revision: yes
-
Referee: [Method (MICE bias modification)] Method description of MICE: The bias modifications (intra-instance allowance + neighbor penalization + cross-instance suppression conditioned on masks) are presented as an ad-hoc change to attention logits with no analysis or derivation showing why these particular terms achieve the claimed regulation of token interactions rather than producing unintended global shifts or new inconsistencies across the diffusion trajectory; this directly impacts the weakest assumption that the heuristic will reliably prevent attribute leakage for ~8.5 edits.
Authors: The modifications are directly motivated by the joint attention structure in Multimodal Diffusion Transformers and the goal of using user masks to isolate instance-specific tokens, thereby limiting cross-instance leakage while preserving intra-instance and global context flow. Although a closed-form derivation of the exact bias values is not derived, the manuscript includes targeted ablations that isolate each term and measure their impact on edit disentanglement versus global consistency across the trajectory. These results support reliable performance at the reported edit counts without introducing measurable inconsistencies. We will expand the method section with additional rationale on the design choices. revision: partial
Circularity Check
No circularity: heuristic attention modification presented as independent strategy
full rationale
The paper describes MICE as a direct, training-free modification of additive bias in joint attention, conditioned on user-provided segmentation masks to allow intra-instance attention, penalize neighbors, and suppress cross-instance attention. No equations, derivations, or predictions are shown that reduce by construction to fitted parameters, self-definitions, or self-citation chains. The central claim is an empirical intervention on diffusion attention mechanics whose justification rests on the stated design choices rather than any load-bearing reduction to prior self-referential results. This is the most common honest finding for a methods paper that does not claim first-principles derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User-provided segmentation masks accurately delineate instance regions for token identification
Reference graph
Works this paper leans on
-
[1]
1981 , publisher=
Typographie: a manual of design , author=. 1981 , publisher=
1981
-
[2]
2004 , publisher=
The elements of typographic style , author=. 2004 , publisher=
2004
-
[3]
Auto-Encoding Variational Bayes , author=
-
[4]
Heusel, Martin and Ramsauer, Hubert and Unterthiner, Thomas and Nessler, Bernhard and Hochreiter, Sepp , booktitle=NIPS, year=
-
[5]
Wu, Liang and Zhang, Chengquan and Liu, Jiaming and Han, Junyu and Liu, Jingtuo and Ding, Errui and Bai, Xiang , booktitle=ACMMM, year=
-
[6]
2020 , organization=
Yang, Qiangpeng and Huang, Jun and Lin, Wei , booktitle=CVPR, pages=. 2020 , organization=
2020
-
[7]
Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J , journal=JMLR, pages=
-
[8]
2020 , organization=
Roy, Prasun and Bhattacharya, Saumik and Ghosh, Subhankar and Pal, Umapada , booktitle=CVPR, pages=. 2020 , organization=
2020
-
[9]
2021 , organization=
Shen, Zejiang and Zhang, Ruochen and Dell, Melissa and Lee, Benjamin Charles Germain and Carlson, Jacob and Li, Weining , booktitle=. 2021 , organization=
2021
-
[10]
2021 , organization=
BG, Vijay Kumar and Subramanian, Jeyasri and Chordia, Varnith and Bart, Eugene and Fang, Shaobo and Guan, Kelly and Bala, Raja , booktitle=ICCV, pages=. 2021 , organization=
2021
-
[11]
Sohl-Dickstein, Jascha and Weiss, Eric and Maheswaranathan, Niru and Ganguli, Surya , booktitle=ICML, year=
-
[12]
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , journal=nips, year=
-
[13]
Bar-Tal, Omer and Yariv, Lior and Lipman, Yaron and Dekel, Tali , booktitle=icml, year=
-
[14]
Yang Song and Jascha Sohl-Dickstein and Diederik P Kingma and Abhishek Kumar and Stefano Ermon and Ben Poole , booktitle=iclr, year=
-
[15]
2021 , organization=
Yamaguchi, Kota , booktitle=ICCV, pages=. 2021 , organization=
2021
-
[16]
Li, Minghao and Lv, Tengchao and Cui, Lei and Lu, Yijuan and Florencio, Dinei and Zhang, Cha and Li, Zhoujun and Wei, Furu , journal=AAAI, year=
-
[17]
Lee, Junyeop and Kim, Yoonsik and Kim, Seonghyeon and Yim, Moonbin and Shin, Seung and Lee, Gayoung and Park, Sungrae , journal=
-
[18]
2021 , organization=
Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and others , booktitle=ICML, pages=. 2021 , organization=
2021
-
[19]
Huang, Yupan and Lv, Tengchao and Cui, Lei and Lu, Yutong and Wei, Furu , booktitle=ACMMM, year=
-
[20]
Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and others , booktitle=ICLR, year=
-
[21]
Blended diffusion for text-driven editing of natural images , author=
-
[22]
Chen, Haoxing and Xu, Zhuoer and Gu, Zhangxuan and Li, Yaohui and Meng, Changhua and Zhu, Huijia and Wang, Weiqiang and others , journal=NIPS, volume=
-
[23]
Chen, Jingye and Huang, Yupan and Lv, Tengchao and Cui, Lei and Chen, Qifeng and Wei, Furu , journal=NIPS, volume=
-
[24]
Li, Junyi and Zhao, Wayne Xin and Nie, Jian-Yun and Wen, Ji-Rong , journal=
-
[25]
Qu, Yadong and Tan, Qingfeng and Xie, Hongtao and Xu, Jianjun and Wang, YuXin and Zhang, Yongdong , booktitle=AAAI, year=
-
[26]
Ma, Jian and Zhao, Mingjun and Chen, Chen and Wang, Ruichen and Niu, Di and Lu, Haonan and Lin, Xiaodong , journal=
-
[27]
Yang, Yukang and Gui, Dongnan and Yuan, Yuhui and Liang, Weicong and Ding, Haisong and Hu, Han and Chen, Kai , journal=NIPS, volume=
-
[28]
2023 , publisher=
TextStyleBrush: Transfer of Text Aesthetics From a Single Example , author=. 2023 , publisher=
2023
-
[29]
Pippi, Vittorio and Quattrini, Fabio and Cascianelli, Silvia and Cucchiara, Rita , booktitle=BMVC, year=
-
[30]
2023 , organization=
Lee, Kenton and Joshi, Mandar and Turc, Iulia Raluca and Hu, Hexiang and Liu, Fangyu and Eisenschlos, Julian Martin and Khandelwal, Urvashi and Shaw, Peter and Chang, Ming-Wei and Toutanova, Kristina , booktitle=ICML, pages=. 2023 , organization=
2023
-
[31]
Hertz, Amir and Mokady, Ron and Tenenbaum, Jay and Aberman, Kfir and Pritch, Yael and Cohen-or, Daniel , booktitle=ICLR, year=
-
[32]
Null-text inversion for editing real images using guided diffusion models , author=
-
[33]
Couairon, Guillaume and Verbeek, Jakob and Schwenk, Holger and Cord, Matthieu , booktitle=ICLR, year=
-
[34]
Liu, Yuliang and Yang, Biao and Liu, Qiang and Li, Zhang and Ma, Zhiyin and Zhang, Shuo and Bai, Xiang , journal=
-
[35]
Hu, Anwen and Xu, Haiyang and Ye, Jiabo and Yan, Ming and Zhang, Liang and Zhang, Bo and Zhang, Ji and Jin, Qin and Huang, Fei and Zhou, Jingren , booktitle=
-
[36]
Peng, Dezhi and Liu, Chongyu and Liu, Yuliang and Jin, Lianwen , booktitle=AAAI, year=
-
[37]
Chen, Jingye and Huang, Yupan and Lv, Tengchao and Cui, Lei and Chen, Qifeng and Wei, Furu , booktitle=ECCV, pages=
-
[38]
2024 , organization=
Dahary, Omer and Patashnik, Or and Aberman, Kfir and Cohen-Or, Daniel , booktitle=ECCV, pages=. 2024 , organization=
2024
-
[39]
Haraguchi, Daichi and Inoue, Naoto and Shimoda, Wataru and Mitani, Hayato and Uchida, Seiichi and Yamaguchi, Kota , booktitle=
-
[40]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, YK and others , journal=
-
[41]
Tuo, Yuxiang and Xiang, Wangmeng and He, Jun-Yan and Geng, Yifeng and Xie, Xuansong , booktitle=ICLR, year=
-
[42]
Qian, Zhipeng and Zhang, Pei and Yang, Baosong and Fan, Kai and Ma, Yiwei and Wong, Derek F and Sun, Xiaoshuai and Ji, Rongrong , booktitle=
-
[43]
Tuo, Yuxiang and Geng, Yifeng and Bo, Liefeng , journal=
-
[44]
Liu, Zeyu and Liang, Weicong and Liang, Zhanhao and Luo, Chong and Li, Ji and Huang, Gao and Yuan, Yuhui , booktitle=ECCV, pages=
-
[45]
Liu, Zeyu and Liang, Weicong and Zhao, Yiming and Chen, Bohan and Liang, Lin and Wang, Lijuan and Li, Ji and Yuan, Yuhui , journal=
-
[46]
Zeng, Weichao and Shu, Yan and Li, Zhenhang and Yang, Dongbao and Zhou, Yu , journal=NIPS, volume=
-
[47]
Wang, Aoqiang and Wang, Jian and Yan, Zhenyu and Shang, Wenxiang and Lin, Ran and Zhang, Zhao , journal=
-
[48]
Ma, Lichen and Yue, Tiezhu and Fu, Pei and Zhong, Yujie and Zhou, Kai and Wei, Xiaoming and Hu, Jie , journal=
-
[49]
Goel, Vidit and Peruzzo, Elia and Jiang, Yifan and Xu, Dejia and Xu, Xingqian and Sebe, Nicu and Darrell, Trevor and Wang, Zhangyang and Shi, Humphrey , booktitle=CVPR, pages=
-
[50]
Shi, Wenda and Song, Yiren and Zhang, Dengming and Liu, Jiaming and Zou, Xingxing , booktitle=ICCV, pages=
-
[51]
Shi, Wenda and Song, Yiren and Rao, Zihan and Zhang, Dengming and Liu, Jiaming and Zou, Xingxing , journal=
-
[52]
Jiang, Bowen and Yuan, Yuan and Bai, Xinyi and Hao, Zhuoqun and Yin, Alyson and Hu, Yaojie and Liao, Wenyu and Ungar, Lyle and Taylor, Camillo J , journal=
-
[53]
Wang, Alex Jinpeng and Li, Linjie and Yang, Zhengyuan and Wang, Lijuan and Li, Min , journal=
-
[54]
Peng, Yuyang and Xiao, Shishi and Wu, Keming and Liao, Qisheng and Chen, Bohan and Lin, Kevin and Huang, Danqing and Li, Ji and Yuan, Yuhui , booktitle=CVPR, pages=
-
[55]
Cheng, Shanbo and Bao, Yu and Cao, Qian and Huang, Luyang and Kang, Liyan and Liu, Zhicheng and Lu, Yu and Zhu, Wenhao and Chen, Jingwen and Huang, Zhichao and others , journal=
-
[56]
Jiangning Zhu and Yuxing Zhou and Zheng Wang and Juntao Yao and Yima Gu and Yuhui Yuan and Shixia Liu , journal=
-
[57]
Liu, Shiyu and Han, Yucheng and Xing, Peng and Yin, Fukun and Wang, Rui and Cheng, Wei and Liao, Jiaqi and Wang, Yingming and Fu, Honghao and Han, Chunrui and others , journal=
-
[58]
Tan, Zhenxiong and Liu, Songhua and Yang, Xingyi and Xue, Qiaochu and Wang, Xinchao , booktitle=ICCV, pages=
-
[59]
Wu, Chenfei and Li, Jiahao and Zhou, Jingren and Lin, Junyang and Gao, Kaiyuan and Yan, Kun and Yin, Sheng-ming and Bai, Shuai and Xu, Xiao and Chen, Yilei and others , journal=
-
[60]
Wang, Peng and Shi, Yichun and Lian, Xiaochen and Zhai, Zhonghua and Xia, Xin and Xiao, Xuefeng and Huang, Weilin and Yang, Jianchao , journal=
-
[61]
2025 , organization=
Simsar, Enis and Tonioni, Alessio and Xian, Yongqin and Hofmann, Thomas and Tombari, Federico , booktitle=WACV, pages=. 2025 , organization=
2025
-
[62]
Zhang, Hong and Duan, Zhongjie and Wang, Xingjun and Chen, Yingda and Zhang, Yu , booktitle=
-
[63]
Ma, Yue and Bai, Qingyan and Ouyang, Hao and Cheng, Ka Leong and Wang, Qiuyu and Liu, Hongyu and Liu, Zichen and Wang, Haofan and Chen, Jingye and Shen, Yujun and others , journal=
-
[64]
Zou, Xingxing and Zhang, Wen and Zhao, Nanxuan , journal=
-
[65]
Comanici, Gheorghe and Bieber, Eric and Schaekermann, Mike and Pasupat, Ice and Sachdeva, Noveen and Dhillon, Inderjit and Blistein, Marcel and Ram, Ori and Zhang, Dan and Rosen, Evan and others , journal=
-
[66]
Greenberg, Or , journal=
-
[67]
Karras, Tero and Aittala, Miika and Aila, Timo and Laine, Samuli , journal=nips, year=
-
[68]
Labs, Black Forest and Batifol, Stephen and Blattmann, Andreas and Boesel, Frederic and Consul, Saksham and Diagne, Cyril and Dockhorn, Tim and English, Jack and English, Zion and Esser, Patrick and others , journal=
-
[69]
Cui, Cheng and Sun, Ting and Lin, Manhui and Gao, Tingquan and Zhang, Yubo and Liu, Jiaxuan and Wang, Xueqing and Zhang, Zelun and Zhou, Changda and Liu, Hongen and others , journal=
-
[70]
2025 , organization=
Das, Alloy and Biswas, Sanket and Roy, Prasun and Ghosh, Subhankar and Pal, Umapada and Blumenstein, Michael and Llad. 2025 , organization=
2025
-
[71]
Zhu, Hongyang and Liu, Haipeng and Fu, Bo and Wang, Yang , journal=
-
[72]
2024 , organization=
Matsuda, Haruka and Togo, Ren and Maeda, Keisuke and Ogawa, Takahiro and Haseyama, Miki , booktitle=. 2024 , organization=
2024
-
[73]
2024 , booktitle = ACMMM, pages =
Chakrabarty, Goirik and Chandrasekar, Aditya and Hebbalaguppe, Ramya and AP, Prathosh , title =. 2024 , booktitle = ACMMM, pages =
2024
-
[74]
Yang, Zhen and Ding, Ganggui and Wang, Wen and Chen, Hao and Zhuang, Bohan and Shen, Chunhua , booktitle=ICLR, year=
-
[75]
Li, Yanfeng and Chan, Kahou and Sun, Yue and Lam, Chantong and Tong, Tong and Yu, Zitong and Fu, Keren and Liu, Xiaohong and Tan, Tao , booktitle=CVPR, pages=
-
[76]
TMLR , pages=
Improving and generalizing flow-based generative models with minibatch optimal transport , author=. TMLR , pages=
-
[77]
arXiv preprint arXiv:2311.13443 , year=
Guided flows for generative modeling and decision making , author=. arXiv preprint arXiv:2311.13443 , year=
-
[78]
Zhou, Dewei and Li, Mingwei and Yang, Zongxin and Yang, Yi , journal=ICCV, year=
-
[79]
Region-aware text-to-image generation via hard binding and soft refinement , author=
-
[80]
Eijkelboom, Floor and Zimmermann, Heiko and Vadgama, Sharvaree and Bekkers, Erik J and Welling, Max and Naesseth, Christian A and van de Meent, Jan-Willem , booktitle=ICML, year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.