Cross-lingual Self-Consistency for Multilingual Reasoning with Language Models
Pith reviewed 2026-06-28 17:02 UTC · model grok-4.3
The pith
Enforcing cross-lingual self-consistency via unsupervised RL improves multilingual reasoning in LLMs without gold answers or parallel data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
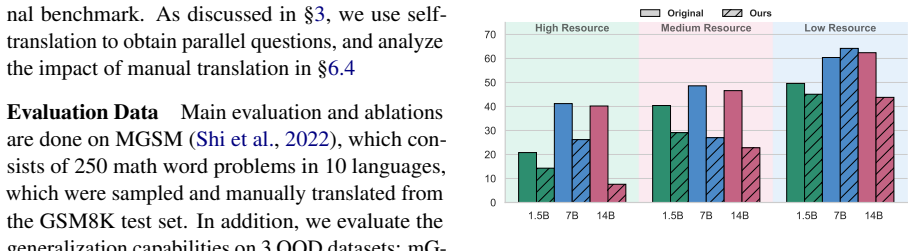
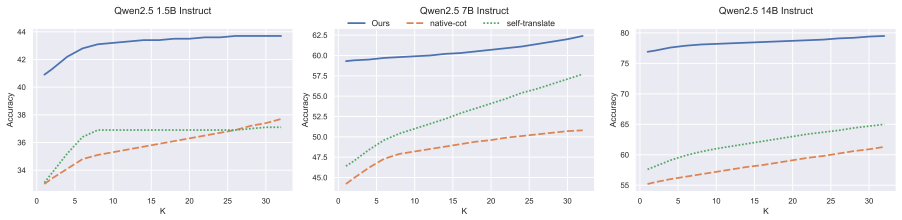
The central claim is that an unsupervised RL procedure that rewards a model for producing the same answer to equivalent problems across languages can raise multilingual reasoning performance, achieving up to 21.7 percent average improvement on MGSM for ten languages, 18.2 percent mean improvement on MGSM languages unseen in training, and up to 6.2 percent gains on three out-of-distribution benchmarks, all without gold answers or parallel data.
What carries the argument
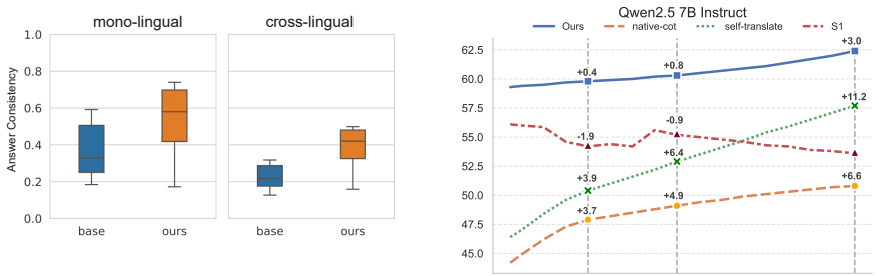
Cross-lingual self-consistency enforced by unsupervised RL, in which the model receives a reward when its final answers match across language versions of the same problem.
If this is right
- Multilingual math reasoning benchmarks improve without any labeled answers or parallel corpora.
- Performance rises on languages absent from the RL training stage.
- Gains transfer to some out-of-distribution reasoning tasks.
- Consistency-based unsupervised methods can expand LLM reasoning coverage to lower-resource languages.
Where Pith is reading between the lines
- The same consistency signal might be tested on non-mathematical reasoning tasks such as commonsense or logical inference.
- If the method mainly aligns outputs rather than reasoning, pairing it with a small amount of verification data could separate the two effects.
- The approach could be combined with existing translation-based methods to see whether the gains are additive.
Load-bearing premise
That forcing answer consistency across languages actually strengthens the model's reasoning rather than simply making incorrect answers more consistent.
What would settle it
Measure accuracy on a set of problems where the majority vote across languages is known to be wrong; if accuracy does not rise after consistency training, the claim that reasoning itself improves is falsified.
Figures


read the original abstract
Despite expanding their multilingual coverage, the advanced reasoning capabilities of LLMs remain largely confined to a few high-resource languages like English. To address this, we propose an unsupervised Reinforcement Learning (RL) approach to enhance multilingual reasoning by enforcing cross-lingual self-consistency: the principle that a model should produce the same final answer for equivalent problems in different languages. Existing methods are limited by the scarcity of multilingual reasoning data and show weak generalization to unseen languages. Our approach requires neither gold answers nor parallel data, and it achieves average gains of up to 21.7% on MGSM across 10 languages. In addition, our method demonstrates strong generalization, with an 18.2% mean improvement on MGSM languages unseen during training, and up to 6.2% gain on 3 out-of-distribution benchmarks. These results show the potential of consistency-based methods to improve the multilingual capabilities of LLMs without requiring supervised data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an unsupervised RL approach enforcing cross-lingual self-consistency improves multilingual reasoning in LLMs without requiring gold answers or parallel data. It reports average gains of up to 21.7% on MGSM across 10 languages, 18.2% mean improvement on MGSM languages unseen during training, and up to 6.2% gain on 3 out-of-distribution benchmarks.
Significance. If the empirical results hold, the work is significant because it shows that a consistency-based unsupervised RL signal can produce measurable accuracy improvements on standard multilingual reasoning benchmarks (MGSM and OOD sets) while requiring neither supervised data nor parallel corpora. The explicit reporting of generalization to unseen languages and the use of external benchmarks rather than self-defined quantities are strengths.
minor comments (2)
- [Abstract] Abstract: the phrase 'average gains of up to 21.7%' is ambiguous; clarify whether this is the mean improvement across the 10 languages, the maximum over languages, or another aggregation, and state the base model and RL algorithm used.
- [Abstract] Abstract: add one sentence on the concrete form of the consistency reward and the languages included in training to allow readers to assess the scope of the unsupervised claim.
Simulated Author's Rebuttal
We thank the referee for their positive review, accurate summary of our contributions, and recommendation for minor revision. We appreciate the recognition of the work's significance, including the unsupervised nature of the approach, generalization to unseen languages, and evaluation on external OOD benchmarks.
Circularity Check
No significant circularity detected
full rationale
The paper trains via unsupervised RL that rewards cross-lingual answer consistency on unlabeled data and evaluates final accuracy against gold labels on external benchmarks (MGSM and OOD sets). Accuracy is measured by exact numerical match to held-out gold answers, which is independent of the consistency reward used in training. No derivation reduces a claimed prediction to a fitted parameter by construction, no load-bearing result rests on self-citation chains, and generalization claims are supported by explicit held-out language and benchmark splits. The reported accuracy gains therefore constitute external evidence rather than a tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A model should produce the same final answer for equivalent problems in different languages, and enforcing this via RL improves reasoning.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Wang, Yumeng and Fan, Zhiyuan and Wang, Qingyun and Fung, Yi R. and Ji, Heng. CALM : Unleashing the Cross-Lingual Self-Aligning Ability of Language Model Question Answering. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.152
-
[9]
The Thirteenth International Conference on Learning Representations , year=
Language Imbalance Driven Rewarding for Multilingual Self-improving , author=. The Thirteenth International Conference on Learning Representations , year=
-
[10]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[11]
arXiv preprint arXiv:2407.10671 , year=
Qwen2 Technical Report , author=. arXiv preprint arXiv:2407.10671 , year=
-
[12]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[13]
2022 , eprint=
Language Models are Multilingual Chain-of-Thought Reasoners , author=. 2022 , eprint=
2022
-
[14]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[15]
2025 , eprint=
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? , author=. 2025 , eprint=
2025
-
[16]
2025 , eprint=
The Multilingual Mind : A Survey of Multilingual Reasoning in Language Models , author=. 2025 , eprint=
2025
-
[17]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[18]
arXiv preprint arXiv:2502.07346 , year=
BenchMAX: A Comprehensive Multilingual Evaluation Suite for Large Language Models , author=. arXiv preprint arXiv:2502.07346 , year=
-
[19]
arXiv preprint arXiv:2110.14168 , year=
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[20]
Bridging the Language Gaps in Large Language Models with Inference-Time Cross-Lingual Intervention
Wang, Weixuan and Wu, Minghao and Haddow, Barry and Birch, Alexandra. Bridging the Language Gaps in Large Language Models with Inference-Time Cross-Lingual Intervention. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.270
-
[21]
arXiv preprint arXiv:2405.01345 , year=
The power of question translation training in multilingual reasoning: Broadened scope and deepened insights , author=. arXiv preprint arXiv:2405.01345 , year=
-
[22]
Question Translation Training for Better Multilingual Reasoning
Zhu, Wenhao and Huang, Shujian and Yuan, Fei and She, Shuaijie and Chen, Jiajun and Birch, Alexandra. Question Translation Training for Better Multilingual Reasoning. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.498
-
[23]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
Emergent Abilities of Large Language Models under Continued Pretraining for Language Adaptation , author=. 2025 , eprint=
2025
-
[25]
2024 , eprint=
Continual Learning Under Language Shift , author=. 2024 , eprint=
2024
-
[26]
arXiv preprint arXiv:2505.22660 , year=
Maximizing Confidence Alone Improves Reasoning , author=. arXiv preprint arXiv:2505.22660 , year=
-
[27]
2025 , eprint=
The Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning , author=. 2025 , eprint=
2025
-
[28]
2025 , eprint=
Self-Questioning Language Models , author=. 2025 , eprint=
2025
-
[29]
2025 , eprint=
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models , author=. 2025 , eprint=
2025
-
[30]
Breaking Language Barriers in Multilingual Mathematical Reasoning: Insights and Observations
Chen, Nuo and Zheng, Zinan and Wu, Ning and Gong, Ming and Zhang, Dongmei and Li, Jia. Breaking Language Barriers in Multilingual Mathematical Reasoning: Insights and Observations. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.411
-
[31]
2025 , eprint=
Crosslingual Reasoning through Test-Time Scaling , author=. 2025 , eprint=
2025
-
[32]
2025 , eprint=
Could Thinking Multilingually Empower LLM Reasoning? , author=. 2025 , eprint=
2025
-
[33]
Ranaldi, Leonardo and Haddow, Barry and Birch, Alexandra. When natural language is not enough: The limits of in-context learning demonstrations in multilingual reasoning. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.412
-
[34]
Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
Liu, Chaoqun and Zhang, Wenxuan and Zhao, Yiran and Luu, Anh Tuan and Bing, Lidong. Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2...
-
[35]
2024 , eprint=
MindMerger: Efficient Boosting LLM Reasoning in non-English Languages , author=. 2024 , eprint=
2024
-
[36]
2025 , eprint=
Cross-Lingual Optimization for Language Transfer in Large Language Models , author=. 2025 , eprint=
2025
-
[37]
2025 , eprint=
A Survey of Multilingual Reasoning in Language Models , author=. 2025 , eprint=
2025
-
[38]
The twelfth international conference on learning representations , year=
On-policy distillation of language models: Learning from self-generated mistakes , author=. The twelfth international conference on learning representations , year=
-
[39]
arXiv preprint arXiv:2306.08543 , year=
Minillm: Knowledge distillation of large language models , author=. arXiv preprint arXiv:2306.08543 , year=
-
[40]
arXiv preprint arXiv:2506.02208 , year=
KDRL: Post-Training Reasoning LLMs via Unified Knowledge Distillation and Reinforcement Learning , author=. arXiv preprint arXiv:2506.02208 , year=
-
[41]
MAPO : Advancing Multilingual Reasoning through Multilingual-Alignment-as-Preference Optimization
She, Shuaijie and Zou, Wei and Huang, Shujian and Zhu, Wenhao and Liu, Xiang and Geng, Xiang and Chen, Jiajun. MAPO : Advancing Multilingual Reasoning through Multilingual-Alignment-as-Preference Optimization. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.539
-
[42]
2026 , eprint=
How Far Can Unsupervised RLVR Scale LLM Training? , author=. 2026 , eprint=
2026
-
[43]
2025 , eprint=
MMATH: A Multilingual Benchmark for Mathematical Reasoning , author=. 2025 , eprint=
2025
-
[44]
arXiv preprint arXiv:2504.18428 , year=
PolyMath: Evaluating Mathematical Reasoning in Multilingual Contexts , author=. arXiv preprint arXiv:2504.18428 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.