Double Triangle Annotation: A Scalable Human-in-the-Loop Framework for High-Precision Historical Document Annotation
Pith reviewed 2026-06-29 21:33 UTC · model grok-4.3
The pith
Double Triangle Annotation uses model consensus to reach 0.003 word error rate on historical document extraction while auto-accepting over 85 percent of fields.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
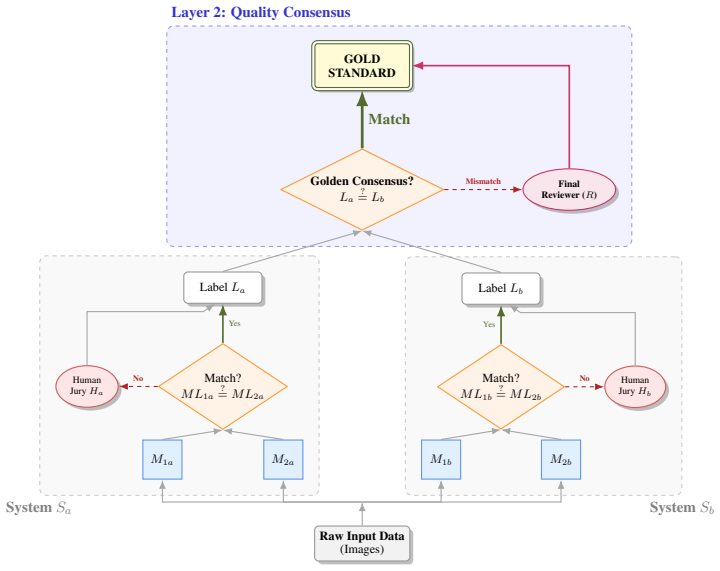
The Double Triangle Annotation framework consists of a first layer where two architecturally independent multimodal large language models annotate documents in parallel, auto-accepting on agreement and routing disagreements to a human jury, followed by a second layer that cross-checks two such consensus outputs against each other and escalates remaining conflicts to a domain expert. This process produces high-precision annotations for structured information extraction, demonstrated by a final word error rate of 0.003 on the Guides Rosenwald corpus spanning 1887-1906, while auto-accepting over 85% of 13,595 fields without requiring distributional priors or calibration.
What carries the argument
Double Triangle Annotation, the two-layer consensus mechanism using parallel independent model annotations and cross-system verification to minimize human intervention.
If this is right
- High-precision ground-truth datasets can be generated efficiently for large historical corpora.
- Annotation autonomy increases automatically with improvements in underlying models.
- The approach applies to other structured extraction tasks from documents without custom calibration.
- Released benchmarks like the Rosenwald Guides ground truth enable standardized evaluation of future extraction methods.
- The framework scales annotation efforts while maintaining low error rates through layered checks.
Where Pith is reading between the lines
- Similar consensus methods could reduce annotation costs in other domains such as legal or archival records.
- If model capabilities advance, the human jury layer might become unnecessary for many fields.
- The released dataset opens opportunities for testing extraction models specifically on 19th-20th century French medical texts.
- Extending the framework to more than two models per layer could further increase auto-acceptance rates.
Load-bearing premise
The errors produced by the two independent multimodal models are statistically independent.
What would settle it
Observing that the two models produce the same incorrect annotation on a substantial fraction of fields, resulting in auto-acceptance of errors and an elevated final word error rate above the reported 0.003.
Figures


read the original abstract
Evaluating structured-information extraction from historical documents at scale requires high-precision ground-truth annotations, yet traditional manual labeling is expensive and fully automated pipelines built on large language models are prone to hallucination. We propose Double Triangle Annotation, a two-layer human-in-the-loop framework that leverages cross-model consensus to automate the majority of annotation work while ensuring high-precision outputs. In the first layer, two architecturally independent Multimodal Large Language Models annotate each document in parallel; when they agree, the label is auto-accepted, and disagreements are routed to a human jury. A second layer cross-checks two such systems against each other, escalating residual conflicts to a domain expert. The framework rests on a single assumption -- error independence between models -- requires no distributional priors or task-specific calibration, and becomes more autonomous as model capability improves. On the Guides Rosenwald, a corpus of French medical directories spanning 1887-1906, the framework achieves a final Word Error Rate of 0.003. Applied at scale, model consensus auto-accepts over 85% of 13,595 fields. We release the resulting benchmark -- the first structured-extraction ground truth for the Rosenwald Guides -- to support future work on historical document processing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Double Triangle Annotation, a two-layer human-in-the-loop framework for high-precision structured information extraction from historical documents. Two architecturally independent MLLMs annotate in parallel in layer 1 (auto-accept on agreement, route disagreements to human jury); layer 2 cross-checks systems and escalates residuals to a domain expert. The framework assumes error independence between models, requires no priors or calibration, and improves with model capability. On the Guides Rosenwald corpus (French medical directories, 1887-1906), it reports a final WER of 0.003 and auto-accepts over 85% of 13,595 fields, releasing the resulting benchmark as the first structured-extraction ground truth for this corpus.
Significance. If the error-independence assumption holds and the reported WER is supported by rigorous validation, the framework provides a practical, scalable approach to generating high-precision annotations for historical document processing, substantially reducing manual effort while addressing hallucination risks in fully automated LLM pipelines. The public release of the Rosenwald Guides benchmark is a concrete, reusable contribution that can benchmark future work in the area.
major comments (2)
- [Abstract] Abstract: The central claims of final WER=0.003 and 85% automation rest entirely on the unvalidated assumption of error independence between the two MLLMs (explicitly identified as the sole assumption). No ablation study, error-correlation matrix, per-field expert audit of the consensus-accepted subset, or analysis of potential correlated failures on historical features (ligatures, abbreviations, faded ink) is described. Without such evidence, the measured WER on corrected disagreements alone does not establish the precision of the auto-accepted labels.
- [Methods / Experiments] Methods / Experiments (inferred from absence in provided description): The manuscript supplies no details on the specific MLLMs employed, jury composition and instructions, domain-expert escalation criteria, annotation guidelines, or dataset characteristics (e.g., field types, document image quality distribution, or train/test splits within the 13,595 fields). These omissions prevent assessment of whether the reported numbers are reproducible or generalizable.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We respond point-by-point to the major comments and indicate where revisions will be made to address valid concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of final WER=0.003 and 85% automation rest entirely on the unvalidated assumption of error independence between the two MLLMs (explicitly identified as the sole assumption). No ablation study, error-correlation matrix, per-field expert audit of the consensus-accepted subset, or analysis of potential correlated failures on historical features (ligatures, abbreviations, faded ink) is described. Without such evidence, the measured WER on corrected disagreements alone does not establish the precision of the auto-accepted labels.
Authors: We agree that the framework's claims rest on the explicitly stated error-independence assumption and that the reported WER of 0.003 is measured after human correction of all disagreements. The auto-accepted subset is not directly audited in the current manuscript. To strengthen the evidence, the revised version will add (1) an analysis of error correlations across a sample of fields, focusing on historical features such as ligatures, abbreviations, and faded ink, and (2) results from a limited per-field expert audit of randomly sampled auto-accepted labels. These additions will provide empirical support for the precision of the consensus-accepted outputs. revision: yes
-
Referee: [Methods / Experiments] Methods / Experiments (inferred from absence in provided description): The manuscript supplies no details on the specific MLLMs employed, jury composition and instructions, domain-expert escalation criteria, annotation guidelines, or dataset characteristics (e.g., field types, document image quality distribution, or train/test splits within the 13,595 fields). These omissions prevent assessment of whether the reported numbers are reproducible or generalizable.
Authors: The full manuscript contains these details, but we accept that they require greater prominence and expansion for clarity. In revision we will enlarge the Methods section to specify the exact MLLMs (names, versions, and prompting), jury composition and instructions, escalation criteria, annotation guidelines, field types, image-quality distribution across the corpus, and confirmation that no train/test split is applicable because the work concerns annotation rather than supervised model training. These changes will directly improve reproducibility and allow better assessment of generalizability. revision: yes
Circularity Check
No circularity; empirical framework with explicit assumption
full rationale
The paper presents a two-layer human-in-the-loop annotation framework whose results (0.003 WER, 85% auto-accept rate) are reported as direct empirical measurements on the Rosenwald corpus. No equations, parameter fittings, predictions derived from inputs, or self-citations appear in the provided text. The sole load-bearing premise is the explicitly stated assumption of error independence between models, which is not derived from or equivalent to any fitted quantity or prior result within the paper. The derivation chain is therefore self-contained and contains no reductions by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption error independence between models
Reference graph
Works this paper leans on
-
[1]
Large Language Models Are Effective Human Annotation Assistants, But Not Good Independent Annotators
Large language models are effective human 9 annotation assistants, but not good independent an- notators.CoRR, abs/2503.06778. Hannah Kim, Kushan Mitra, Rafael Li Chen, Sajjadur Rahman, and Dan Zhang. 2024. MEGAnno+: A human-LLM collaborative annotation system. In Proceedings of the 18th Conference of the European Chapter of the Association for Computatio...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Are large language models good annotators? InProceedings on “I Can’t Believe It’s Not Better: Failure Modes in the Age of Foundation Models” at NeurIPS 2023 Workshops, volume 239 ofProceed- ings of Machine Learning Research, pages 38–48. PMLR. Nicholas Pangakis and Samuel Wolken. 2025. Keeping humans in the loop: Human-centered automated an- notation with...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
DIV A-HisDB: A precisely annotated large dataset of challenging medieval manuscripts. In2016 15th International Conference on Frontiers in Hand- writing Recognition (ICFHR), pages 471–476. Yu-Min Tseng, Wei-Lin Chen, Chung-Chi Chen, and Hsin-Hsi Chen. 2025. Evaluating large language models as expert annotators.CoRR, abs/2508.07827. Shuohang Wang, Yang Liu...
-
[4]
Lisez la colonne de GAUCHE de haut en bas COMPLÈTEMENT
-
[5]
Puis lisez la colonne de DROITE de haut en bas COMPLÈTEMENT
-
[6]
NE MÉLANGEZ PAS les colonnes - terminez entièrement la gauche avant la droite
-
[7]
- Incluez toujours les titres de civilité (Mme, Mlle, etc.) dans le champ nom s'ils sont visibles
Cet ordre est ESSENTIEL pour l'évaluation ultérieure - Ne produisez que les entrées de médecins (ignorez publicités, textes d'éditeur). - Incluez toujours les titres de civilité (Mme, Mlle, etc.) dans le champ nom s'ils sont visibles. - Si aucune entrée de médecin n'est trouvée dans l'image, retournez seulement l'en-tête TSV. - Séparez les colonnes par de...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.