Depth over Fidelity in Fixed-Budget Noisy Evolution Strategies
Pith reviewed 2026-06-27 23:00 UTC · model grok-4.3
The pith
Probabilistic elite membership replaces hard ranks with conditional expected ranks to cut update dispersion while keeping the mean update unchanged in noisy evolution strategies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PEM replaces hard rank-based weights in evolution strategies with conditional expected rank weights that integrate over ranking uncertainty. It preserves the conditional mean update while reducing conditional update dispersion, amounting to a Rao-Blackwellization of the noisy rank-based step. The approach is realized through residual bootstrapping (RB-PEM) that caps per-generation overhead and adds an adaptive probe-and-switch mechanism for low-noise regimes.
What carries the argument
Probabilistic elite membership (PEM), which substitutes conditional expected ranks for observed hard ranks to weight the update step.
If this is right
- More generations become feasible within the same evaluation budget because per-generation overhead stays bounded.
- Performance gains appear consistently in high-misranking regimes on the COCO bbob-noisy suite.
- The same gains transfer to external tasks such as RL policy search and hyperparameter optimization under noise.
- An adaptive probe-and-switch mechanism automatically falls back to conventional behavior when noise is low.
Where Pith is reading between the lines
- The Rao-Blackwellization framing suggests PEM could be applied to other rank-based noisy optimizers that currently commit to single noisy rankings.
- If the conditional expectation can be approximated more cheaply than bootstrapping, the depth advantage would increase further.
- In extremely high-noise regimes the method may still require a minimum number of probes per generation to keep the approximation reliable.
Load-bearing premise
Residual bootstrapping with capped per-generation overhead accurately approximates conditional expected ranks without introducing bias that would degrade performance when misranking is severe.
What would settle it
Run RB-PEM and a standard denoising baseline on a high-misranking noisy benchmark with the same total evaluations; if the denoising baseline achieves lower final error or higher success rate, the advantage of depth via PEM is refuted.
Figures
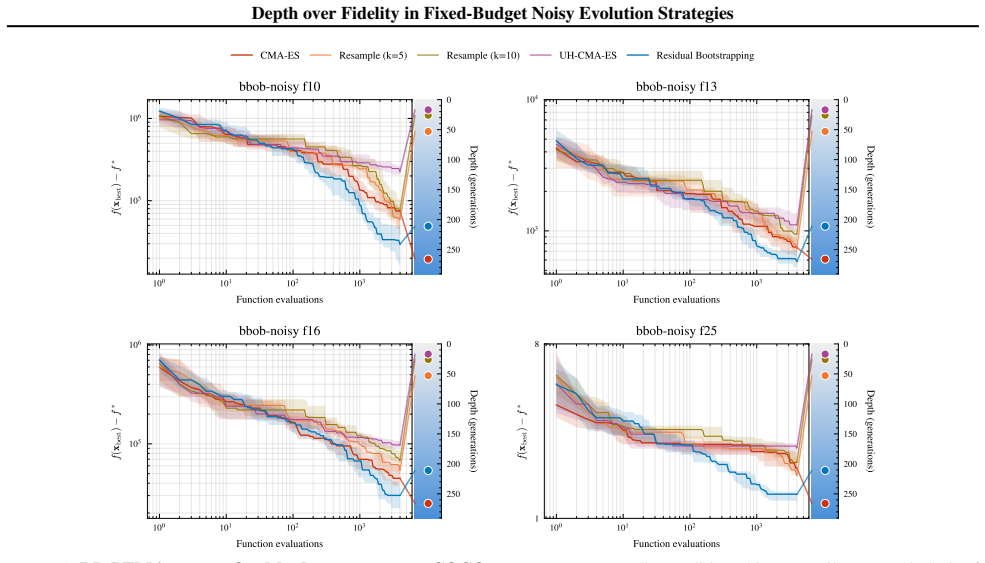
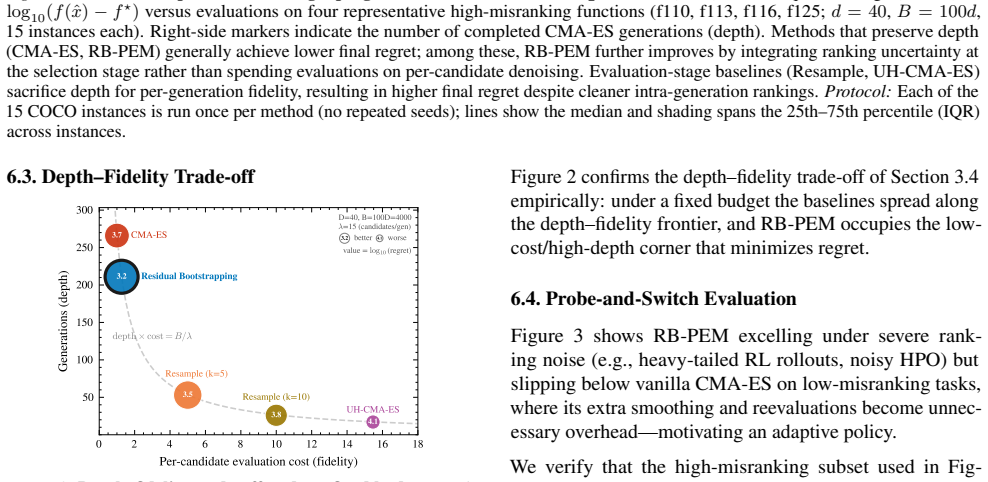
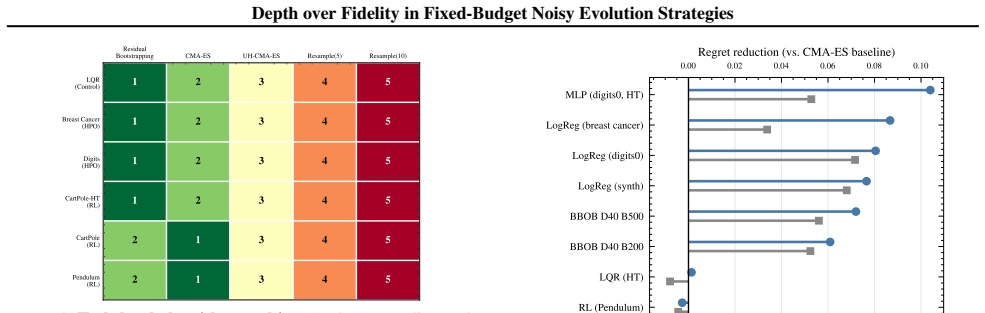
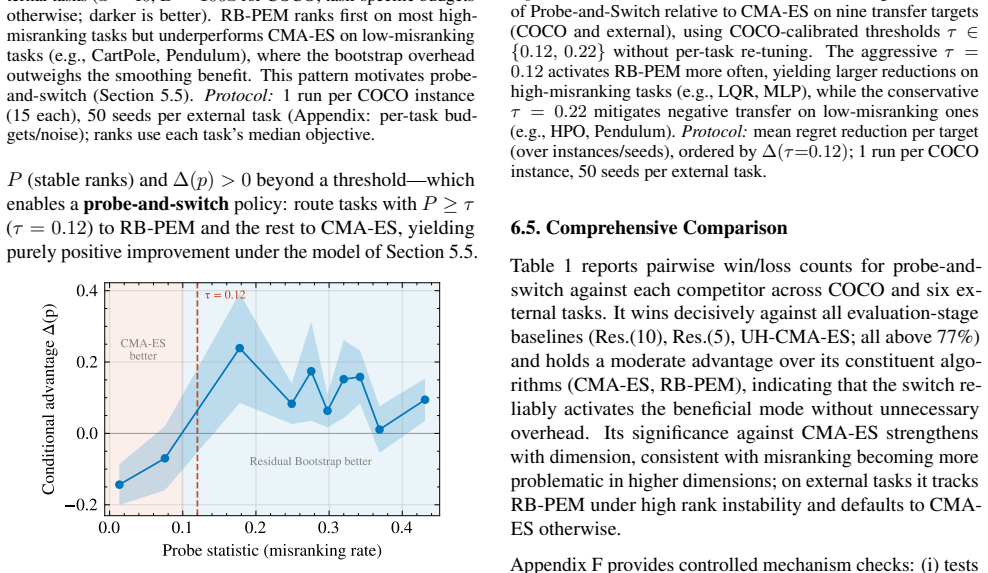
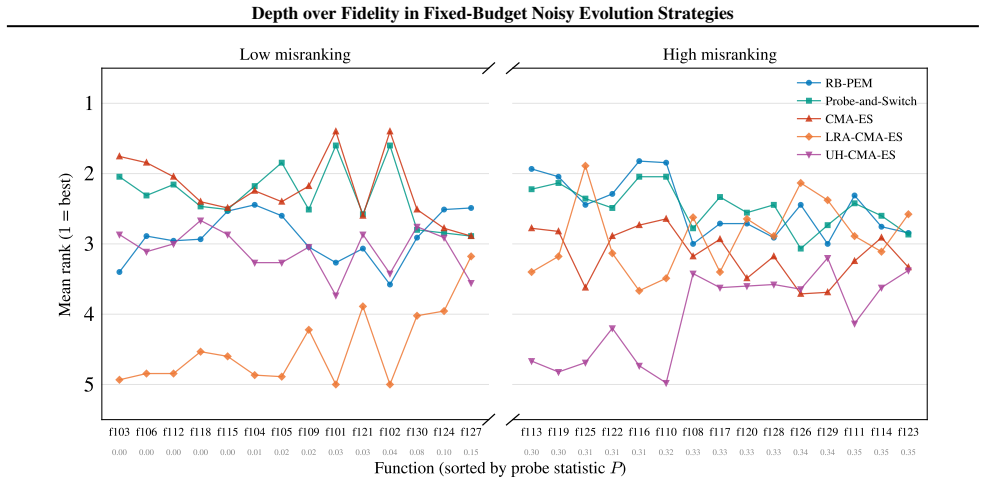
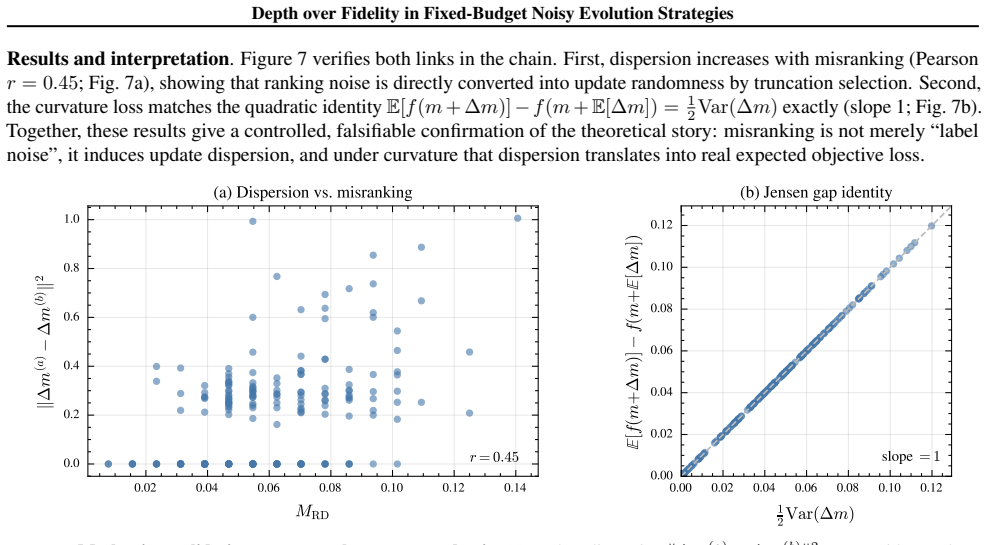
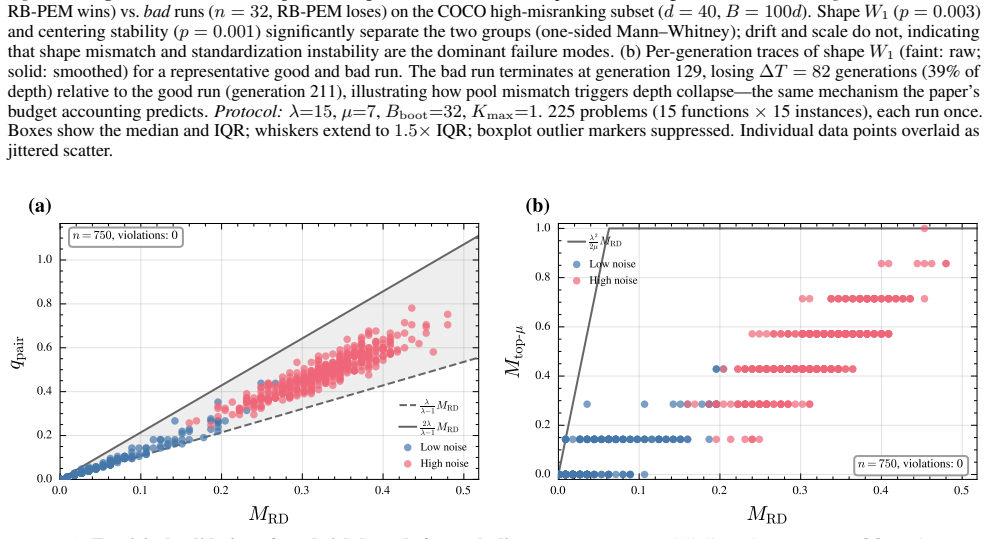

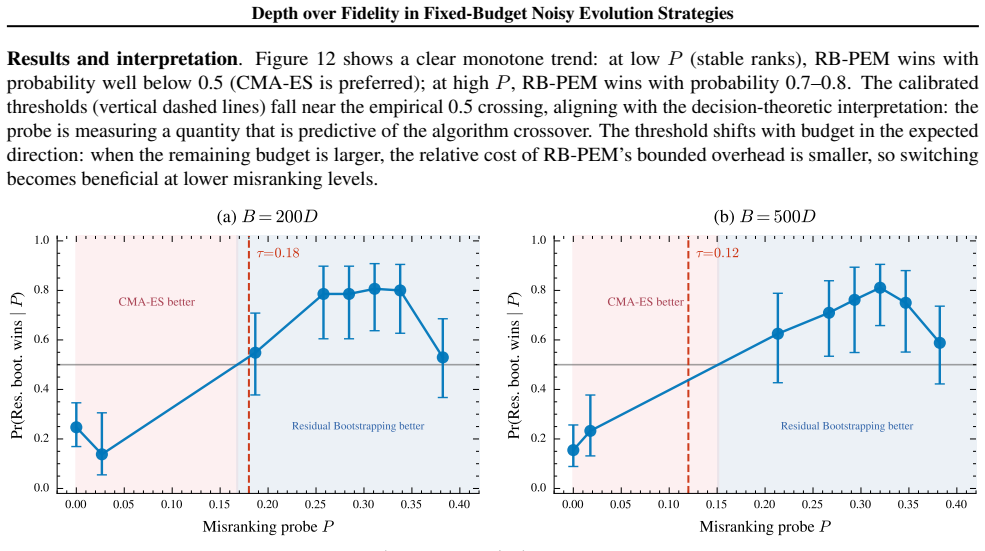
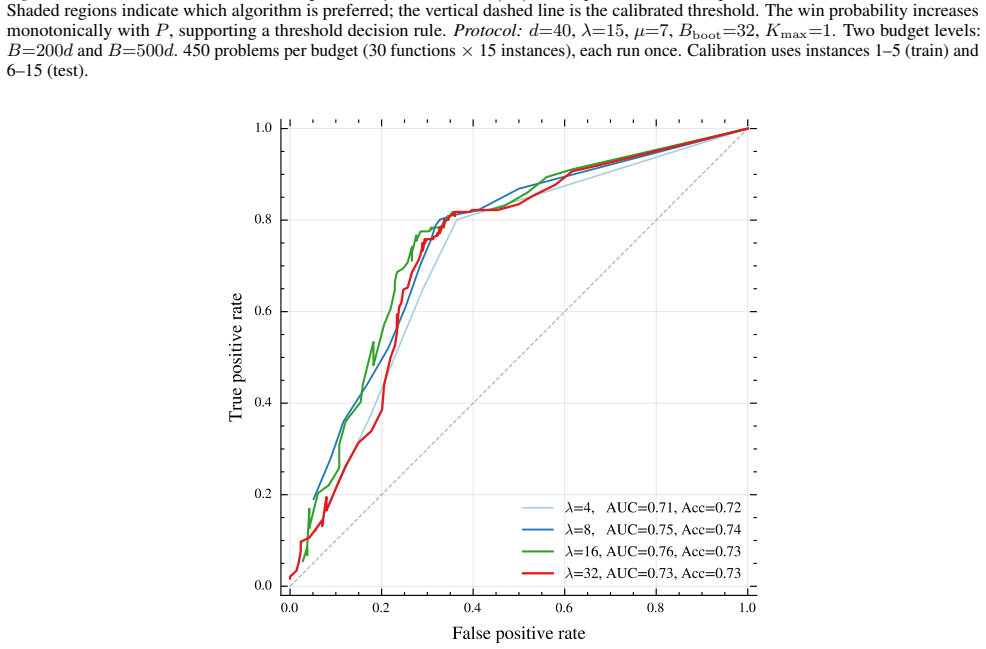

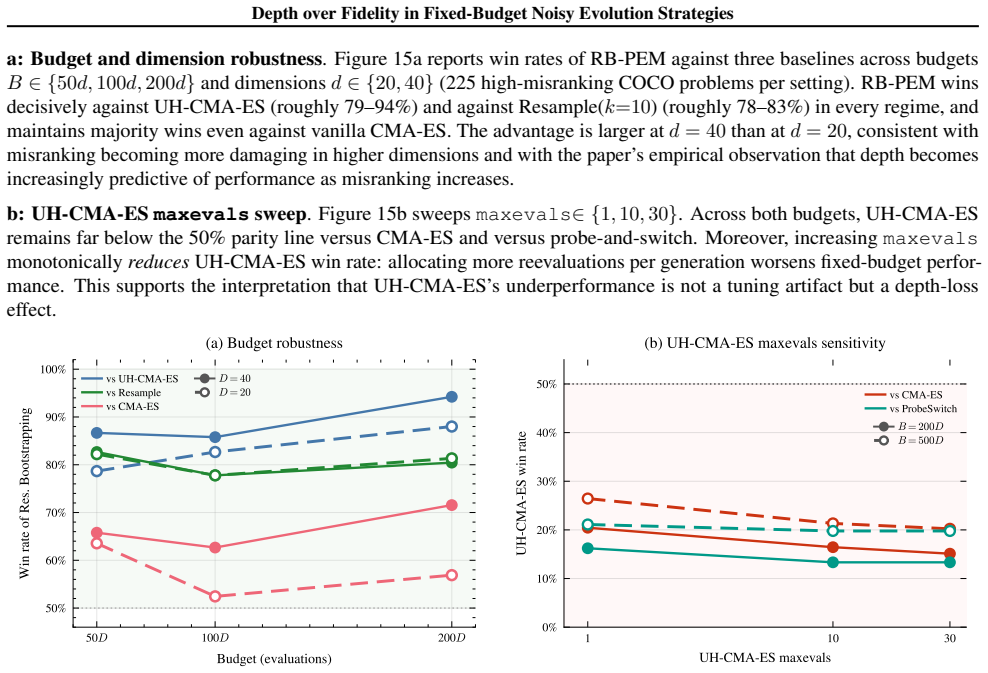
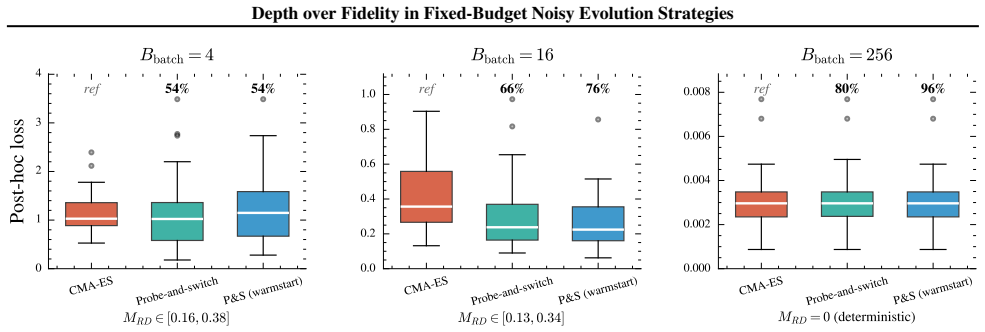
read the original abstract
Noisy evolution strategies under fixed evaluation budgets face a depth-fidelity trade-off: spending evaluations to denoise intra-generation rankings reduces the number of distribution updates the optimizer can execute. We argue for depth over fidelity and propose probabilistic elite membership (PEM), which replaces hard rank-based weights in evolution strategies with conditional expected rank weights that integrate over ranking uncertainty. PEM preserves the conditional mean update while reducing conditional update dispersion, a Rao-Blackwellization of the noisy rank-based step. We instantiate PEM via residual bootstrapping (RB-PEM) with capped per-generation overhead, complemented by an adaptive probe-and-switch mechanism for low-noise regimes. Across the COCO bbob-noisy suite and external tasks including RL policy search and hyperparameter optimization, RB-PEM achieves consistent gains in high-misranking, budget-constrained settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that in fixed-budget noisy evolution strategies, prioritizing more distribution updates (depth) over denoising individual rankings (fidelity) is preferable. It introduces probabilistic elite membership (PEM), which replaces hard rank-based weights with conditional expected ranks that integrate over ranking uncertainty. This is claimed to preserve the conditional mean update while reducing dispersion, constituting a Rao-Blackwellization of the noisy rank-based step. The approach is instantiated as RB-PEM via residual bootstrapping with capped per-generation overhead and an adaptive probe-and-switch mechanism, with empirical gains reported on the COCO bbob-noisy suite plus RL policy search and hyperparameter optimization tasks.
Significance. If the mean-preservation property holds exactly and the bootstrap approximation introduces no systematic bias, the method would provide a principled way to improve noisy ES performance under tight budgets by enabling more updates without degrading the expected direction of progress. The Rao-Blackwellization framing and empirical consistency across benchmarks would represent a useful contribution to noisy black-box optimization.
major comments (2)
- [Abstract] Abstract (paragraph on RB-PEM instantiation): the claim that residual bootstrapping with capped per-generation overhead accurately approximates the conditional expected ranks without introducing bias is load-bearing for the Rao-Blackwellization argument, yet no error analysis, bias bound, or high-misranking regime verification is provided; if the bootstrap deviates from E[rank | observations], the mean-preservation property fails and observed gains cannot be attributed to variance reduction.
- [Abstract] Abstract (PEM definition): while the high-level Rao-Blackwellization argument is grounded in standard conditional expectation properties, the manuscript provides no explicit derivation showing that the PEM-weighted update equals the conditional expectation of the noisy rank-based update; without this, the central claim that dispersion is reduced while the mean is preserved remains unverified.
minor comments (1)
- [Abstract] The abstract refers to 'COCO bbob-noisy suite' without specifying the exact functions, noise levels, or budget settings used in the experiments; this makes it difficult to assess the scope of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger theoretical grounding. We address each major comment below and will revise the manuscript to incorporate explicit derivations and approximation analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on RB-PEM instantiation): the claim that residual bootstrapping with capped per-generation overhead accurately approximates the conditional expected ranks without introducing bias is load-bearing for the Rao-Blackwellization argument, yet no error analysis, bias bound, or high-misranking regime verification is provided; if the bootstrap deviates from E[rank | observations], the mean-preservation property fails and observed gains cannot be attributed to variance reduction.
Authors: We agree that the manuscript does not include a formal error analysis or bias bounds for the residual bootstrapping approximation in RB-PEM. PEM itself is defined to achieve exact mean preservation via conditional expectation, while RB-PEM is a practical, capped-overhead approximation whose fidelity to the ideal conditional ranks is supported only empirically. We will add a dedicated subsection discussing the bootstrap approximation, its potential bias in high-misranking regimes, and the distinction between exact PEM properties and the RB-PEM instantiation. revision: yes
-
Referee: [Abstract] Abstract (PEM definition): while the high-level Rao-Blackwellization argument is grounded in standard conditional expectation properties, the manuscript provides no explicit derivation showing that the PEM-weighted update equals the conditional expectation of the noisy rank-based update; without this, the central claim that dispersion is reduced while the mean is preserved remains unverified.
Authors: The referee is correct that an explicit derivation is absent. By definition, PEM replaces each random rank with its conditional expectation given the observations; the law of total expectation then implies that the PEM-weighted update has the same conditional expectation as the original noisy rank-based update. We will insert a short, self-contained derivation (one paragraph plus two displayed equations) in the methods section to make this step explicit. revision: yes
Circularity Check
No circularity; PEM applies standard Rao-Blackwellization to rank weights without reducing to fitted inputs or self-citations
full rationale
The paper's core derivation claims that replacing noisy ranks with their conditional expectations (via PEM) preserves the mean update while reducing dispersion, presented as a direct Rao-Blackwellization of the rank-based step. This follows from standard conditional expectation properties and does not rely on any self-referential definition, fitted parameter renamed as prediction, or load-bearing self-citation. The RB-PEM instantiation uses residual bootstrapping as an approximation method, but the claimed statistical property holds independently of the specific approximation technique. No equations or steps in the provided text reduce the result to its own inputs by construction. The derivation remains self-contained against external statistical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ranking uncertainty can be integrated via residual bootstrapping to yield conditional expected ranks
invented entities (1)
-
probabilistic elite membership (PEM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Evolutionary Computation , volume =
Nikolaus Hansen and Andreas Ostermeier , title =. Evolutionary Computation , volume =
-
[2]
A Method for Handling Uncertainty in Evolutionary Optimization With an Application to Feedback Control of Combustion , journal =
Nikolaus Hansen and Andr. A Method for Handling Uncertainty in Evolutionary Optimization With an Application to Feedback Control of Combustion , journal =
-
[3]
Uncertainty handling
Verena Heidrich. Uncertainty handling. Genetic and Evolutionary Computation Conference (GECCO 2009) , pages =. 2009 , doi =
2009
-
[4]
Evolutionary Optimization in Uncertain Environments -- A Survey , journal =
Yaochu Jin and J. Evolutionary Optimization in Uncertain Environments -- A Survey , journal =. 2005 , doi =
2005
-
[5]
Swarm and Evolutionary Computation , volume =
Pratyusha Rakshit and Amit Konar and Swagatam Das , title =. Swarm and Evolutionary Computation , volume =. 2017 , doi =
2017
-
[6]
E. J. Hughes , title =. Evolutionary Multi-Criterion Optimization (EMO 2001) , series =
2001
-
[7]
Pareto-Front Exploration with Uncertain Objectives , booktitle =
J. Pareto-Front Exploration with Uncertain Objectives , booktitle =
-
[8]
Fieldsend and Richard M
Jonathan E. Fieldsend and Richard M. Everson , title =. Proceedings of the. 2005 , doi =
2005
-
[9]
Fieldsend and Richard M
Jonathan E. Fieldsend and Richard M. Everson , title =. IEEE Transactions on Evolutionary Computation , volume =. 2015 , doi =
2015
-
[10]
Comparing Solutions under Uncertainty in Multiobjective Optimization , journal =
Miha Mlakar and Tea Tu. Comparing Solutions under Uncertainty in Multiobjective Optimization , journal =
-
[11]
Gutjahr and Sabine Pichler , title =
Walter J. Gutjahr and Sabine Pichler , title =. Annals of Operations Research , volume =
-
[12]
Gomes and Bart Selman , title =
Carla P. Gomes and Bart Selman , title =. Artificial Intelligence , volume =
-
[13]
Artificial Intelligence , volume =
Stuart Russell and Eric Wefald , title =. Artificial Intelligence , volume =
-
[14]
Learning Dynamic Algorithm Portfolios , journal =
Matteo Gagliolo and J. Learning Dynamic Algorithm Portfolios , journal =
-
[15]
A Racing Algorithm for Configuring Metaheuristics , booktitle =
Mauro Birattari and Thomas St. A Racing Algorithm for Configuring Metaheuristics , booktitle =
-
[16]
2010 , doi =
Analyzing bandit-based adaptive operator selection mechanisms , journal =. 2010 , doi =
2010
-
[17]
Burke and Michel Gendreau and Matthew R
Edmund K. Burke and Michel Gendreau and Matthew R. Hyde and Graham Kendall and Gabriela Ochoa and Ender. Hyper-heuristics: a survey of the state of the art , journal =. 2013 , doi =
2013
-
[18]
Tibshirani , title =
Bradley Efron and Robert J. Tibshirani , title =
-
[19]
Optimal Transport: Old and New , series =
C. Optimal Transport: Old and New , series =
-
[20]
Concentration Inequalities: A Nonasymptotic Theory of Independence , publisher =
St. Concentration Inequalities: A Nonasymptotic Theory of Independence , publisher =
-
[21]
van der Vaart and Jon A
Aad W. van der Vaart and Jon A. Wellner , title =
-
[22]
Probability Theory and Related Fields , volume =
Nicolas Fournier and Arnaud Guillin , title =. Probability Theory and Related Fields , volume =
-
[23]
Huber and Elvezio M
Peter J. Huber and Elvezio M. Ronchetti , title =
-
[24]
Graham , title =
Persi Diaconis and Ronald L. Graham , title =. Journal of the Royal Statistical Society, Series B (Statistical Methodology) , volume =
-
[25]
Yurii Nesterov , title =
-
[26]
Econometrica , volume =
Paul Milgrom and Chris Shannon , title =. Econometrica , volume =
-
[27]
The Annals of Mathematical Statistics , volume =
Samuel Karlin and Herman Rubin , title =. The Annals of Mathematical Statistics , volume =
-
[28]
Shai Shalev-Shwartz and Shai Ben-David , title =
-
[29]
Dataset Shift in Machine Learning , publisher =
-
[30]
Roman Vershynin , title =
-
[31]
Evolutionary Algorithms in the Presence of Noise: To Sample or Not to Sample , booktitle =
Hans. Evolutionary Algorithms in the Presence of Noise: To Sample or Not to Sample , booktitle =. 2007 , doi =
2007
-
[32]
Kruisselbrink and Edgar Reehuis and Andr
Johannes W. Kruisselbrink and Edgar Reehuis and Andr. Using the uncertainty handling. Proceedings of the 13th Annual Genetic and Evolutionary Computation Conference (. 2011 , doi =
2011
-
[33]
Groves and J
Matthew J. Groves and J. Sequential sampling for noisy optimisation with. Proceedings of the Genetic and Evolutionary Computation Conference (. 2018 , doi =
2018
-
[34]
IEEE Transactions on Systems, Man, and Cybernetics: Systems , volume =
Zhenhua Li and Shuo Zhang and Xinye Cai and Qingfu Zhang and Xiaomin Zhu and Zhun Fan and Xiuyi Jia , title =. IEEE Transactions on Systems, Man, and Cybernetics: Systems , volume =. 2022 , doi =
2022
-
[35]
Proceedings of the Genetic and Evolutionary Computation Conference (
Kouhei Nishida and Youhei Akimoto , title =. Proceedings of the Genetic and Evolutionary Computation Conference (. 2016 , doi =
2016
-
[36]
Ono , title =
Masahiro Nomura and Youhei Akimoto and I. Ono , title =. Proceedings of the Genetic and Evolutionary Computation Conference (. 2023 , doi =
2023
-
[37]
Rendell , title =
Warren Armstrong and Peter Christen and Eric McCreath and Alistair P. Rendell , title =. Workshop on Integrating Artificial Intelligence and Data Mining (. 2006 , note =
2006
-
[38]
L. Sch. Greedy Restart Schedules: A Baseline for Dynamic Algorithm Selection on Numerical Black-box Optimization Problems , booktitle =. 2025 , doi =
2025
-
[39]
Towards dynamic algorithm selection for numerical black-box optimization: investigating
Diederick Vermetten and Hao Wang and Thomas B. Towards dynamic algorithm selection for numerical black-box optimization: investigating. Proceedings of the Genetic and Evolutionary Computation Conference (. 2020 , doi =
2020
-
[40]
Applications of Evolutionary Computation - 26th European Conference,
Diederick Vermetten and Hao Wang and Kevin Sim and Emma Hart , title =. Applications of Evolutionary Computation - 26th European Conference,. 2023 , doi =
2023
-
[41]
Arnold and Hans
Dirk V. Arnold and Hans. A general noise model and its effects on evolution strategy performance , journal =. 2006 , doi =
2006
-
[42]
A New Approach for Predicting the Final Outcome of Evolution Strategy Optimization Under Noise , journal =
Hans. A New Approach for Predicting the Final Outcome of Evolution Strategy Optimization Under Noise , journal =. 2005 , doi =
2005
-
[43]
Science China Information Sciences , volume =
Chao Bian and Chao Qian and Yang Yu and Ke Tang , title =. Science China Information Sciences , volume =. 2021 , doi =
2021
-
[44]
CoRR , volume =
Timo Budszuhn and Mark Joachim Krallmann and Daniel Horn , title =. CoRR , volume =. 2025 , doi =
2025
-
[45]
IEEE Transactions on Evolutionary Computation , volume =
Thomas Philip Runarsson and Xin Yao , title =. IEEE Transactions on Evolutionary Computation , volume =. 2000 , doi =
2000
-
[46]
Proceedings of the Genetic and Evolutionary Computation Conference , series =
Uchida, Kento and Nishihara, Kenta and Shirakawa, Shinichi , title =. Proceedings of the Genetic and Evolutionary Computation Conference , series =. 2024 , pages =
2024
-
[47]
Proceedings of the Genetic and Evolutionary Computation Conference , series =
Nishida, Kouhei and Akimoto, Youhei , title =. Proceedings of the Genetic and Evolutionary Computation Conference , series =. 2018 , pages =
2018
-
[48]
ACM Transactions on Evolutionary Learning and Optimization , volume =
Nomura, Masahiro and Akimoto, Youhei and Ono, Isao , title =. ACM Transactions on Evolutionary Learning and Optimization , volume =. 2025 , doi =
2025
-
[49]
Parallel Problem Solving from Nature -- PPSN XVII , series =
Krause, Oswin , title =. Parallel Problem Solving from Nature -- PPSN XVII , series =. 2022 , pages =
2022
-
[50]
Gaussian Process Surrogate Models for the
Bajer, Luk. Gaussian Process Surrogate Models for the. Evolutionary Computation , volume =. 2019 , doi =
2019
-
[51]
and Daulton, Samuel and Letham, Benjamin and Wilson, Andrew Gordon and Bakshy, Eytan , title =
Balandat, Maximilian and Karrer, Brian and Jiang, Daniel R. and Daulton, Samuel and Letham, Benjamin and Wilson, Andrew Gordon and Bakshy, Eytan , title =. Advances in Neural Information Processing Systems , volume =
-
[52]
Advances in Neural Information Processing Systems , volume =
Ament, Sebastian and Daulton, Samuel and Eriksson, David and Balandat, Maximilian and Bakshy, Eytan , title =. Advances in Neural Information Processing Systems , volume =
-
[53]
A Tutorial on Bayesian Optimization
Frazier, Peter I. , title =. arXiv preprint arXiv:1807.02811 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
, title =
Kim, Seong-Hee and Nelson, Barry L. , title =. Proceedings of the Winter Simulation Conference , year =
-
[55]
Selecting a Selection Procedure , journal =
Branke, J. Selecting a Selection Procedure , journal =. 2007 , doi =
2007
-
[56]
, title =
Frazier, Peter I. , title =. Operations Research , volume =. 2014 , doi =
2014
-
[57]
Jeff and Fan, Weiwei and Luo, Jun , title =
Hong, L. Jeff and Fan, Weiwei and Luo, Jun , title =. Frontiers of Engineering Management , volume =. 2021 , doi =
2021
-
[58]
Jeff and Jiang, Guangxin and Zhong, Ying , title =
Hong, L. Jeff and Jiang, Guangxin and Zhong, Ying , title =. INFORMS Journal on Computing , volume =. 2022 , doi =
2022
-
[59]
Efficient Expected Improvement Estimation for Continuous Multiple Ranking and Selection , booktitle =
Pearce, Michael and Branke, J. Efficient Expected Improvement Estimation for Continuous Multiple Ranking and Selection , booktitle =. 2017 , pages =
2017
-
[60]
Sequential Sampling in Noisy Environments , booktitle =
J. Sequential Sampling in Noisy Environments , booktitle =. 2004 , doi =
2004
-
[61]
Tohoku Mathematical Journal, Second Series , volume =
Azuma, Kazuoki , title =. Tohoku Mathematical Journal, Second Series , volume =. 1967 , doi =
1967
-
[62]
Journal of the American Statistical Association , volume =
Hoeffding, Wassily , title =. Journal of the American Statistical Association , volume =. 1963 , doi =
1963
-
[63]
1991 , isbn =
Williams, David , title =. 1991 , isbn =
1991
-
[64]
, title =
Casella, George and Berger, Roger L. , title =. 2002 , isbn =
2002
-
[65]
and Casella, George , title =
Lehmann, Erich L. and Casella, George , title =. 1998 , isbn =
1998
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.