ReNF: Rethinking the Design of Neural Long-Term Time Series Forecasters
Pith reviewed 2026-05-18 12:59 UTC · model grok-4.3
pith:PNCMBLEM Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{PNCMBLEM}
Prints a linked pith:PNCMBLEM badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Direct temporal MLPs with boosted direct outputs outperform complex state-of-the-art models on long-term time series benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
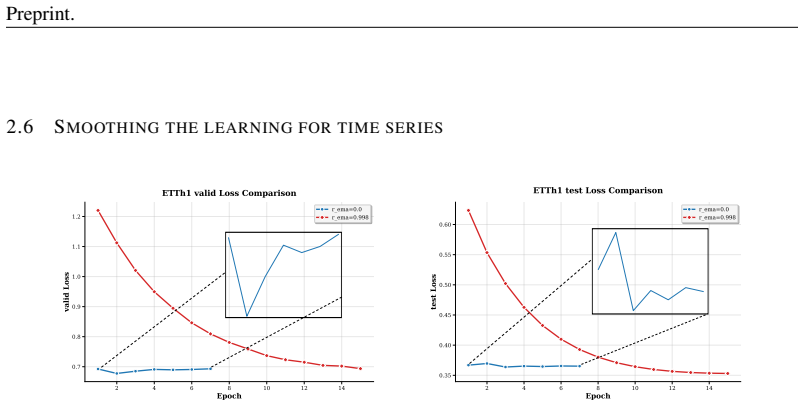
The authors claim that the Variance Reduction Hypothesis is implicitly realized by the Boosted Direct Output paradigm, which hybridizes the causal structure of auto-regressive forecasting with the stability of direct output to combine multiple forecasts inside a single network, and that adding parameter smoothing stabilizes optimization; together these changes allow a direct temporal MLP to outperform recent complex state-of-the-art models in nearly all long-term time series forecasting benchmarks without relying on intricate inductive biases.
What carries the argument
Boosted Direct Output (BDO), a streamlined paradigm that generates and combines multiple forecasts by hybridizing auto-regressive causality with direct-output stability inside one network while implicitly realizing forecast combination.
If this is right
- Architectural complexity becomes less critical than output structure for long-term forecasting performance.
- Parameter smoothing provides a practical way to reduce the validation-test generalization gap in neural forecasters.
- Simple multilayer perceptrons can serve as strong baselines that set new performance levels on existing benchmarks.
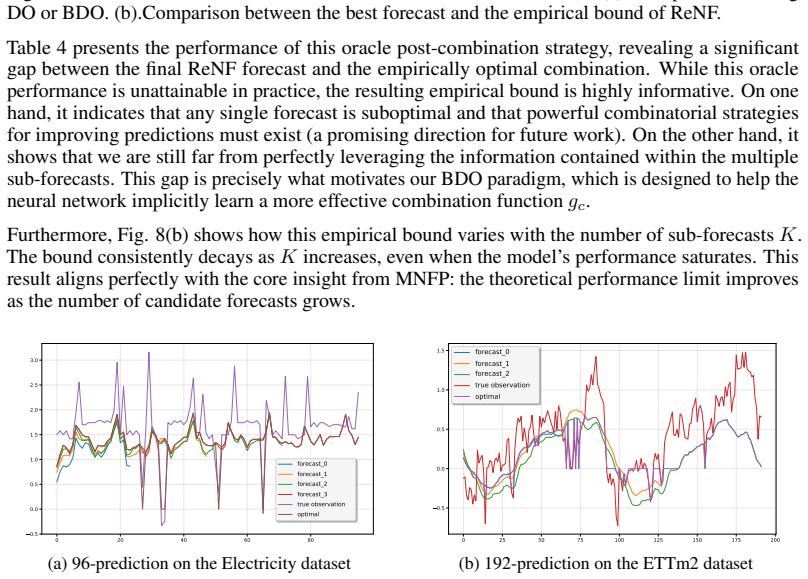
- Empirical verification of the hypothesis yields a dynamic performance bound that can guide future model development.
Where Pith is reading between the lines
- The same variance-reduction logic could be tested on other sequential tasks such as video prediction or speech synthesis.
- Explicitly optimizing networks to minimize the dynamic performance bound rather than point-wise error might produce further gains.
- The findings suggest that many transformer-based forecasters could be simplified by replacing their attention layers with a BDO-style output head.
Load-bearing premise
The Variance Reduction Hypothesis holds and is implicitly realized by the Boosted Direct Output paradigm within a single network.
What would settle it
An experiment in which a temporal MLP trained without the Boosted Direct Output component fails to match or exceed current complex models on the standard LTSF benchmarks would falsify the central claim.
Figures












read the original abstract
Neural Forecasters (NFs) have become a cornerstone of Long-term Time Series Forecasting (LTSF). However, recent progress has been hampered by an overemphasis on architectural complexity at the expense of fundamental forecasting structures. In this work, we revisit principled designs of LTSF. We begin by formulating a Variance Reduction Hypothesis (VRH), positing that generating and combining multiple forecasts is essential to reducing the inherent uncertainty of NFs. Guided by this, we propose Boosted Direct Output (BDO), a streamlined paradigm that synergistically hybridizes the causal structure of Auto-Regressive (AR) with the stability of Direct Output (DO), while implicitly realizing the principle of forecast combination within a single network. Furthermore, we mitigate a critical validation-test generalization gap by employing parameter smoothing to stabilize optimization. Extensive experiments demonstrate that these trivial yet principled improvements enable a direct temporal MLP to outperform recent, complex state-of-the-art models in nearly all benchmarks, without relying on intricate inductive biases. Finally, we empirically verify our hypothesis, establishing a dynamic performance bound that highlights promising directions for future research. The code is publicly available at: https://github.com/Luoauoa/ReNF.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that overemphasis on architectural complexity has hindered progress in neural long-term time series forecasting (LTSF). It formulates a Variance Reduction Hypothesis (VRH) positing that generating and combining multiple forecasts reduces inherent uncertainty in neural forecasters. Guided by VRH, it proposes Boosted Direct Output (BDO), a hybrid of Auto-Regressive (AR) causal structure and Direct Output (DO) stability that implicitly enacts forecast combination inside one network. Parameter smoothing is added to mitigate validation-test generalization gaps. Extensive experiments show a simple temporal MLP with these changes outperforms recent complex SOTA models on nearly all benchmarks without intricate inductive biases; the hypothesis is empirically verified via a dynamic performance bound. Code is released publicly.
Significance. If the central claims hold, the work would be significant by redirecting LTSF research toward principled, minimal designs (hybrid structures and smoothing) rather than ever-more-complex architectures. The public code, hypothesis verification, and dynamic bound provide concrete, falsifiable contributions that could influence future model development. It offers a potential performance bound for simple forecasters that challenges the necessity of elaborate inductive biases.
major comments (2)
- [Abstract/Introduction and §4] Abstract/Introduction and §4 (Hypothesis Verification): The central claim that BDO 'implicitly realizing the principle of forecast combination within a single network' (and thereby enacting VRH) is load-bearing for explaining why the simple MLP outperforms complex models. However, the experiments do not isolate variance reduction from confounding factors such as the hybrid AR+DO structure or parameter smoothing. Controlled ablations that directly measure prediction variance (or ensemble-like effects) with/without BDO components are needed to substantiate that VRH, rather than optimization stability alone, drives the gains.
- [§5] §5 (Experiments): The outperformance is reported across benchmarks, but the manuscript lacks error bars, statistical significance tests, and explicit dataset exclusion rules. These omissions make the 'nearly all benchmarks' claim only partially verifiable and weaken the strength of the empirical support for both the performance results and the dynamic performance bound.
minor comments (2)
- Clarify the exact formulation of parameter smoothing (including the smoothing coefficient) and provide sensitivity analysis, as this is listed among free parameters but its interaction with BDO is not fully detailed.
- [§5] In tables reporting benchmark results, ensure consistent notation for metrics and add a brief discussion of how the hybrid structure differs from prior AR/Direct Output combinations in the literature.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major point below, indicating where we agree and plan revisions to strengthen the work.
read point-by-point responses
-
Referee: [Abstract/Introduction and §4] Abstract/Introduction and §4 (Hypothesis Verification): The central claim that BDO 'implicitly realizing the principle of forecast combination within a single network' (and thereby enacting VRH) is load-bearing for explaining why the simple MLP outperforms complex models. However, the experiments do not isolate variance reduction from confounding factors such as the hybrid AR+DO structure or parameter smoothing. Controlled ablations that directly measure prediction variance (or ensemble-like effects) with/without BDO components are needed to substantiate that VRH, rather than optimization stability alone, drives the gains.
Authors: We appreciate the referee's emphasis on isolating the variance reduction mechanism. The dynamic performance bound in §4 is designed to provide empirical support for the VRH by demonstrating performance scaling consistent with implicit forecast combination under BDO. Nevertheless, we agree that additional controlled ablations directly quantifying prediction variance (e.g., via multiple stochastic forward passes or output perturbation analysis) with and without BDO components, while holding the hybrid structure and smoothing fixed, would more rigorously separate VRH effects from optimization stability. We will incorporate these ablations into the revised §4. revision: yes
-
Referee: [§5] §5 (Experiments): The outperformance is reported across benchmarks, but the manuscript lacks error bars, statistical significance tests, and explicit dataset exclusion rules. These omissions make the 'nearly all benchmarks' claim only partially verifiable and weaken the strength of the empirical support for both the performance results and the dynamic performance bound.
Authors: We concur that reporting error bars, statistical tests, and explicit dataset rules will improve verifiability. In the revised §5 we will add standard deviation error bars computed over multiple random seeds to all main tables, include paired statistical significance tests (e.g., t-tests) for the reported outperformance, and explicitly document the dataset exclusion criteria, preprocessing steps, and benchmark selection rules used throughout the experiments. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper formulates VRH as an initial hypothesis, designs BDO as a hybrid structure guided by it, and then performs empirical verification on external benchmarks against SOTA models. No derivation step reduces by construction to its own inputs, no parameter is fitted on a subset and renamed as prediction, and no self-citation chain bears the central load. Benchmark results supply independent grounding outside the hypothesis itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- smoothing coefficient
axioms (1)
- domain assumption Variance Reduction Hypothesis: generating and combining multiple forecasts is essential to reducing the inherent uncertainty of neural forecasters.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose Boosted Direct Output (BDO), a novel forecasting paradigm that synergistically hybridizes the causal nature of Auto-Regressive (AR) models with the stability of Direct Output (DO).
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and embed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 1 (Multiple Neural Forecasting Proposition (MNFP))... an accurate forecast is theoretically achievable even with a rather weak generator, provided a sufficiently large number of candidate outputs is produced.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Adrien Cort´es, R´emi Rehm, and Victor Letzelter. Winner-takes-all for multivariate probabilistic time series forecasting.arXiv preprint arXiv:2506.05515,
-
[2]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Patch-wise structural loss for time series forecasting.arXiv preprint arXiv:2503.00877,
Dilfira Kudrat, Zongxia Xie, Yanru Sun, Tianyu Jia, and Qinghua Hu. Patch-wise structural loss for time series forecasting.arXiv preprint arXiv:2503.00877,
-
[4]
Rodrigo Gonz ˜A ˜Alez Laiz, Tobias Schmidt, and Steffen Schneider. Self-supervised contrastive learning performs non-linear system identification.arXiv preprint arXiv:2410.14673,
-
[5]
A path towards autonomous machine intelligence version 0.9
Yann LeCun. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27.Open Review, 62(1):1–62,
work page 2022
-
[6]
Shengsheng Lin, Haojun Chen, Haijie Wu, Chunyun Qiu, and Weiwei Lin. Temporal query network for efficient multivariate time series forecasting.arXiv preprint arXiv:2505.12917,
-
[7]
Peiyuan Liu, Beiliang Wu, Yifan Hu, Naiqi Li, Tao Dai, Jigang Bao, and Shu-tao Xia. Timebridge: Non-stationarity matters for long-term time series forecasting.arXiv preprint arXiv:2410.04442, 2025a. Yong Liu, Haixu Wu, Jianmin Wang, and Mingsheng Long. Non-stationary transformers: Exploring the stationarity in time series forecasting.Advances in neural in...
-
[8]
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
10 Preprint. Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. itransformer: Inverted transformers are effective for time series forecasting.arXiv preprint arXiv:2310.06625,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Yong Liu, Guo Qin, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Timer-xl: Long-context transformers for unified time series forecasting.arXiv preprint arXiv:2410.04803, 2025b. Yihang Lu, Yangyang Xu, Qitao Qin, and Xianwei Meng. Timecapsule: Solving the jigsaw puzzle of long-term time series forecasting with compressed predictive representations. In...
-
[10]
Dhruv D Modi and Rong Pan. Enhancing transformer-based foundation models for time series forecasting via bagging, boosting and statistical ensembles.arXiv preprint arXiv:2508.16641,
-
[11]
Juntong Ni, Zewen Liu, Shiyu Wang, Ming Jin, and Wei Jin. Timedistill: Efficient long-term time series forecasting with mlp via cross-architecture distillation.arXiv preprint arXiv:2502.15016,
-
[12]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers.arXiv preprint arXiv:2211.14730,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Boris N Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio. N-beats: Neural basis expansion analysis for interpretable time series forecasting.arXiv preprint arXiv:1905.10437,
-
[14]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[15]
Fredf: Learning to forecast in the frequency domain.arXiv preprint arXiv:2402.02399, 2024a
Hao Wang, Licheng Pan, Zhichao Chen, Degui Yang, Sen Zhang, Yifei Yang, Xinggao Liu, Haoxuan Li, and Dacheng Tao. Fredf: Learning to forecast in the frequency domain.arXiv preprint arXiv:2402.02399, 2024a. Shiyu Wang, Haixu Wu, Xiaoming Shi, Tengge Hu, Huakun Luo, Lintao Ma, James Y Zhang, and Jun Zhou. Timemixer: Decomposable multiscale mixing for time s...
-
[16]
Wang Xue, Tian Zhou, Qingsong Wen, Jinyang Gao, Bolin Ding, and Rong Jin. Card: Channel aligned robust blend transformer for time series forecasting.arXiv preprint arXiv:2305.12095,
-
[17]
Wenzhen Yue, Yong Liu, Haoxuan Li, Hao Wang, Xianghua Ying, Ruohao Guo, Bowei Xing, and Ji Shi
11 Preprint. Wenzhen Yue, Yong Liu, Haoxuan Li, Hao Wang, Xianghua Ying, Ruohao Guo, Bowei Xing, and Ji Shi. Olinear: A linear model for time series forecasting in orthogonally transformed domain. arXiv preprint arXiv:2505.08550,
-
[18]
is also relevant, as it demonstrates an ability to handle the diverse and multi-modal nature of the future from a probabilistic perspective. Furthermore, the characterization of TimeMCL as a conditional stationary quantizer for time series may offer additional theoretical support and interpretations for our framework. Our work also connects to classic ens...
work page 2018
-
[19]
re-certified the benefits of such ensemble methods for enhancing Transformer-based NFs, providing further empirical support for the direction of our research. Forecast Combinations.Forecast combination is a classic technique for improving forecast accuracy and robustness by leveraging the diverse strengths of multiple models (Clemen, 1989). In this work, ...
work page 1989
-
[20]
to the domain of deep learning for long-term time series forecasting. Rather than combining distinct, parallel forecasters into a hybrid model (Zhang, 2003), our framework achieves this goal efficiently within a single, structured approach for generating and implicitly combining forecasts within a single neural network. By recursively stacking sub-forecas...
work page 2003
-
[21]
and patch-wise structural losses (Kudrat et al., 2025). We posit that the BDO learning objective, formed by the weighted sum of losses from hierarchical sub-forecasts, inherently functions as a complex structural loss. This seemingly implicit loss can be seen as the generalized version of the above two. To formalize this property, we first simplify the lo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.