SCAIL-2: Unifying Controlled Character Animation with End-to-end In-Context Conditioning
Pith reviewed 2026-06-27 13:18 UTC · model grok-4.3
The pith
SCAIL-2 performs end-to-end character animation by directly concatenating driving videos instead of using pose skeletons or masked backgrounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
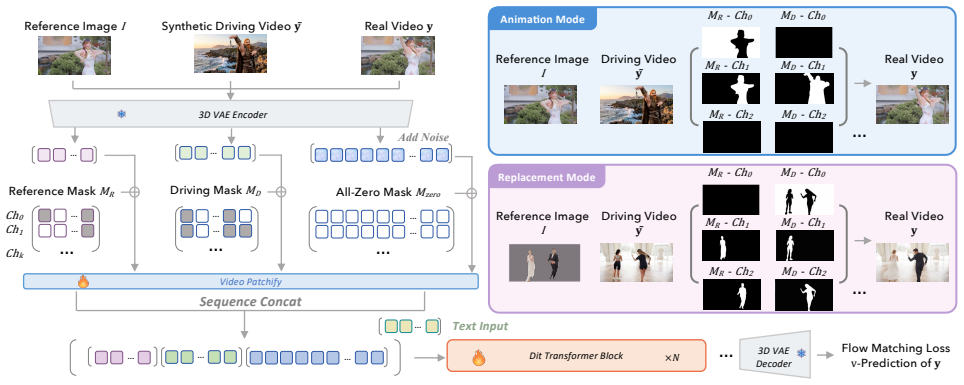
SCAIL-2 achieves end-to-end character animation by directly concatenating driving videos to the sequence, unifying sub-tasks via in-context mask conditioning and mode-specific RoPE as soft guidance, training on the synthesized MotionPair-60K dataset, and applying Bias-Aware DPO to mitigate synthetic discrepancies, which together yield superior results over methods reliant on intermediate pose or background representations.
What carries the argument
Direct concatenation of driving videos to the input sequence, augmented by in-context mask conditioning and mode-specific RoPE as soft guidance beyond text and raw visuals.
If this is right
- Character animation pipelines can eliminate separate pose estimation and background masking stages.
- Multiple sub-tasks become trainable in one model through decoupled in-context conditions.
- Synthetic data generation plus preference optimization can replace large real annotated datasets for this domain.
- End-to-end conditioning preserves fine visual details that intermediate representations typically discard.
Where Pith is reading between the lines
- The direct-concatenation approach could apply to other video-to-video transfer problems where source details must be retained.
- Releasing the dataset and weights would allow direct testing on new reference characters without retraining from scratch.
- Mode-specific RoPE may generalize to other conditional video generation settings that need task-specific positional signals.
Load-bearing premise
The synthetic MotionPair-60K dataset together with in-context conditioning and Bias-Aware DPO sufficiently closes the domain gap to real videos without introducing artifacts that undermine the performance gains.
What would settle it
Evaluating the trained model on held-out real-world driving and reference video pairs and checking whether visible artifacts appear in detailed regions or whether quantitative scores fail to exceed those of skeleton-based baselines.
Figures









read the original abstract
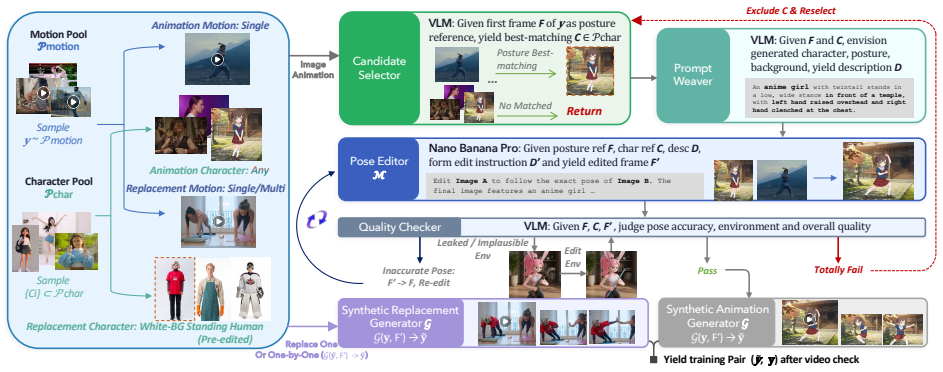
Controlled character animation requires transferring motion from a driving sequence to a reference character. Prior works heavily rely on intermediate representations, including pose skeletons to represent motion or masked background to represent environment, which inevitably leads to information loss. To address this, we present SCAIL-2, a framework that bypasses those intermediates and achieves \textbf{end-to-end} character animation. By directly concatenating driving videos to the sequence, the model can obtain all the required visual information from the input video. To address the lack of end-to-end data, we unify sub-tasks of character animation with decoupled conditions and then curate a pipeline to synthesize MotionPair-60K, an end-to-end motion transfer dataset containing heterogeneous tasks of character animation. To achieve the unification, we utilize in-context mask conditioning and mode-specific RoPE as soft guidance beyond textual instructions and raw visual information. To address synthetic discrepancy in detailed regions, we propose Bias-Aware DPO to construct preference items to mitigate the errors. Extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches in various character animation tasks. A large subset of synthetic data as well as model weights will be released at our project page: https://teal024.github.io/SCAIL-2/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SCAIL-2, a framework for end-to-end controlled character animation that directly concatenates driving videos to the input sequence, bypassing intermediate representations such as pose skeletons or masked backgrounds. It unifies heterogeneous sub-tasks via in-context mask conditioning and mode-specific RoPE as soft guidance, curates the synthetic MotionPair-60K dataset through decoupled condition unification, and applies Bias-Aware DPO on preference pairs to mitigate detailed-region errors from synthetic data. The central claim is that this yields substantial outperformance over existing state-of-the-art methods across various character animation tasks, with a large subset of the data and model weights to be released.
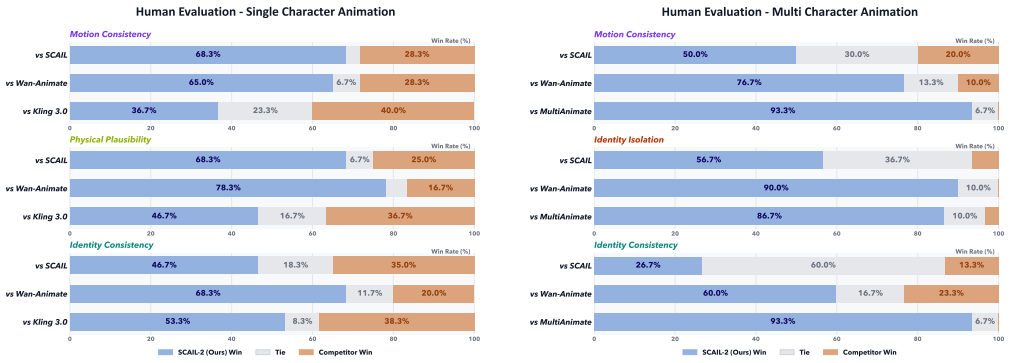
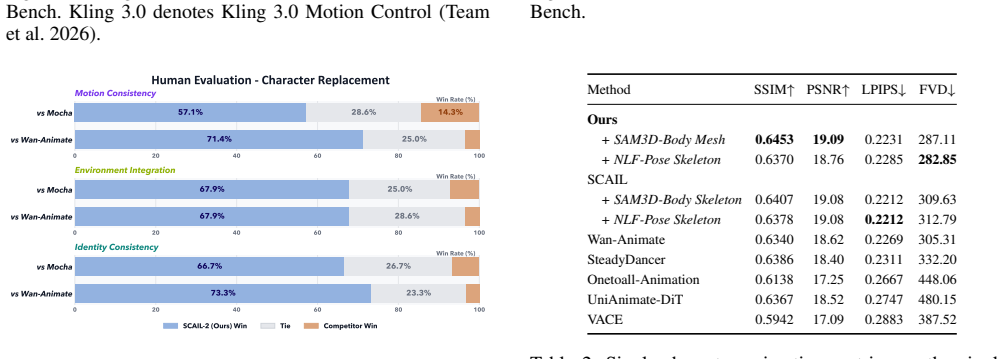
Significance. If the quantitative results and generalization claims hold, the work could meaningfully advance the field by demonstrating that direct visual concatenation plus targeted conditioning can eliminate information loss from intermediate representations. The planned release of synthetic data and weights supports reproducibility and further research on end-to-end animation pipelines.
major comments (3)
- [Abstract] Abstract: the assertion that 'extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches' supplies no quantitative metrics, baseline details, ablation results, or dataset statistics, which is load-bearing for the central performance claim.
- [Method (MotionPair-60K construction)] MotionPair-60K construction (method section): the pipeline is described only at high level with no quantitative measures (e.g., distribution distance to real data or perceptual artifact rates on real test clips), so it is unclear whether Bias-Aware DPO corrects errors that would appear under real lighting, camera motion, or clothing dynamics.
- [Experiments] Experiments section: reliance on the unreleased synthetic MotionPair-60K for both training (via DPO) and evaluation creates a risk that reported gains are synthetic-specific; no evidence is supplied that the in-context conditioning and DPO close the domain gap sufficiently for artifact-free results on real driving videos.
minor comments (1)
- [Abstract] Abstract: clarify the exact fraction of MotionPair-60K that will be released versus the full 60K.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches' supplies no quantitative metrics, baseline details, ablation results, or dataset statistics, which is load-bearing for the central performance claim.
Authors: We agree that the abstract would benefit from quantitative support for the performance claim. In the revised manuscript, we will update the abstract to include key metrics (e.g., average improvements over baselines), the number of compared methods, and dataset statistics from MotionPair-60K. revision: yes
-
Referee: [Method (MotionPair-60K construction)] MotionPair-60K construction (method section): the pipeline is described only at high level with no quantitative measures (e.g., distribution distance to real data or perceptual artifact rates on real test clips), so it is unclear whether Bias-Aware DPO corrects errors that would appear under real lighting, camera motion, or clothing dynamics.
Authors: We acknowledge that the MotionPair-60K pipeline description is high-level. We will expand the Method section with quantitative details including dataset composition statistics, any available distribution comparisons to real data, and perceptual quality metrics to better illustrate the impact of Bias-Aware DPO. revision: yes
-
Referee: [Experiments] Experiments section: reliance on the unreleased synthetic MotionPair-60K for both training (via DPO) and evaluation creates a risk that reported gains are synthetic-specific; no evidence is supplied that the in-context conditioning and DPO close the domain gap sufficiently for artifact-free results on real driving videos.
Authors: The manuscript already states that a large subset of synthetic data and model weights will be released. While training uses MotionPair-60K, evaluations cover real driving videos within the reported tasks. We will add an explicit subsection in Experiments discussing domain gap, with additional quantitative and qualitative results on real videos to demonstrate generalization. revision: yes
Circularity Check
No circularity: empirical method with independent dataset synthesis and standard training
full rationale
The paper's core contribution is an empirical end-to-end animation pipeline trained on a newly synthesized MotionPair-60K dataset, using in-context conditioning, RoPE, and Bias-Aware DPO. No load-bearing step reduces by construction to its own inputs: dataset curation is described as a unification pipeline (not a fit that predicts its own outputs), DPO preference construction addresses observed discrepancies rather than renaming fitted parameters as predictions, and no self-citation chain or uniqueness theorem is invoked to force the architecture. The derivation chain consists of architectural choices and training procedures whose validity is tested externally via experiments on held-out splits, making the result self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[2]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[3]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[4]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[5]
International Journal of Man-Machine Studies , volume = 20, number = 1, pages =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[6]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[7]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[8]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[9]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[10]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[11]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[12]
The Thirteenth International Conference on Learning Representations , year=
Animate-X: Universal Character Image Animation with Enhanced Motion Representation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[13]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Animate anyone: Consistent and controllable image-to-video synthesis for character animation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[14]
arXiv preprint arXiv:2509.14055 , year=
Wan-animate: Unified character animation and replacement with holistic replication , author=. arXiv preprint arXiv:2509.14055 , year=
-
[15]
arXiv preprint arXiv:2512.05905 , year=
SCAIL: Towards Studio-Grade Character Animation via In-Context Learning of 3D-Consistent Pose Representations , author=. arXiv preprint arXiv:2512.05905 , year=
-
[16]
Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
X-UniMotion: Animating Human Images with Expressive, Unified and Identity-Agnostic Motion Latents , author=. Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
2025
-
[17]
International Conference on Learning Representations , volume=
Cogvideox: Text-to-video diffusion models with an expert transformer , author=. International Conference on Learning Representations , volume=
-
[18]
arXiv preprint arXiv:2602.03796 , year=
3D-Aware Implicit Motion Control for View-Adaptive Human Video Generation , author=. arXiv preprint arXiv:2602.03796 , year=
-
[19]
arXiv preprint arXiv:2311.15127 , year=
Stable video diffusion: Scaling latent video diffusion models to large datasets , author=. arXiv preprint arXiv:2311.15127 , year=
-
[20]
arXiv preprint arXiv:2503.20314 , year=
Wan: Open and advanced large-scale video generative models , author=. arXiv preprint arXiv:2503.20314 , year=
-
[21]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Animate anyone 2: High-fidelity character image animation with environment affordance , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[22]
arXiv preprint arXiv:2601.08587 , year=
End-to-End Video Character Replacement without Structural Guidance , author=. arXiv preprint arXiv:2601.08587 , year=
-
[23]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Vace: All-in-one video creation and editing , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[24]
European Conference on Computer Vision , pages=
Champ: Controllable and consistent human image animation with 3d parametric guidance , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[25]
arXiv preprint arXiv:2602.21581 , year=
MultiAnimate: Pose-Guided Image Animation Made Extensible , author=. arXiv preprint arXiv:2602.21581 , year=
-
[26]
arXiv preprint arXiv:2601.21716 , year=
DreamActor-M2: Universal Character Image Animation via Spatiotemporal In-Context Learning , author=. arXiv preprint arXiv:2601.21716 , year=
-
[27]
arXiv preprint arXiv:2511.22940 , year=
One-to-All Animation: Alignment-Free Character Animation and Image Pose Transfer , author=. arXiv preprint arXiv:2511.22940 , year=
-
[28]
arXiv preprint arXiv:2505.18078 , year=
Dancetogether! identity-preserving multi-person interactive video generation , author=. arXiv preprint arXiv:2505.18078 , year=
-
[29]
Science China Information Sciences , volume=
Unianimate: Taming unified video diffusion models for consistent human image animation , author=. Science China Information Sciences , volume=. 2025 , publisher=
2025
-
[30]
arXiv preprint arXiv:2406.19680 , year=
Mimicmotion: High-quality human motion video generation with confidence-aware pose guidance , author=. arXiv preprint arXiv:2406.19680 , year=
-
[31]
1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space , author=
FLUX. 1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space , author=. arXiv preprint arXiv:2506.15742 , year=
-
[32]
2025 , eprint=
UniAnimate-DiT: Human Image Animation with Large-Scale Video Diffusion Transformer , author=. 2025 , eprint=
2025
-
[33]
arXiv preprint arXiv:2511.16719 , year=
Sam 3: Segment anything with concepts , author=. arXiv preprint arXiv:2511.16719 , year=
-
[34]
2025 , note =
Nano Banana Image Generation via Gemini API , howpublished =. 2025 , note =
2025
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wallace, Bram and Dang, Meihua and Rafailov, Rafael and Zhou, Linqi and Lou, Aaron and Purushwalkam, Senthil and Ermon, Stefano and Xiong, Caiming and Joty, Shafiq and Naik, Nikhil , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[36]
arXiv preprint arXiv:2501.13918 , year=
Improving video generation with human feedback , author=. arXiv preprint arXiv:2501.13918 , year=
-
[37]
2026 , eprint=
EverAnimate: Minute-Scale Human Animation via Latent Flow Restoration , author=. 2026 , eprint=
2026
-
[38]
2026 , eprint=
SAM 3D Body: Robust Full-Body Human Mesh Recovery , author=. 2026 , eprint=
2026
-
[39]
2023 , eprint=
Gemini: A Family of Highly Capable Multimodal Models , author=. 2023 , eprint=
2023
-
[40]
2026 , eprint=
Kling-MotionControl Technical Report , author=. 2026 , eprint=
2026
-
[41]
SSIM , author=
Image quality metrics: PSNR vs. SSIM , author=. 2010 20th international conference on pattern recognition , pages=. 2010 , organization=
2010
-
[42]
IEEE transactions on image processing , volume=
Image quality assessment: from error visibility to structural similarity , author=. IEEE transactions on image processing , volume=. 2004 , publisher=
2004
-
[43]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
The unreasonable effectiveness of deep features as a perceptual metric , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[44]
arXiv preprint arXiv:1812.01717 , year=
Towards accurate generative models of video: A new metric & challenges , author=. arXiv preprint arXiv:1812.01717 , year=
-
[45]
Proceedings of the VLDB Endowment , volume=
PyTorch FSDP: experiences on scaling fully sharded data parallel , author=. Proceedings of the VLDB Endowment , volume=. 2023 , publisher=
2023
-
[46]
Yufei Xu and Jing Zhang and Qiming Zhang and Dacheng Tao , booktitle=. Vi
-
[47]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Effective whole-body pose estimation with two-stages distillation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[48]
2025 , eprint=
MHR: Momentum Human Rig , author=. 2025 , eprint=
2025
-
[49]
2026 , eprint=
SDPose: Exploiting Diffusion Priors for Out-of-Domain and Robust Pose Estimation , author=. 2026 , eprint=
2026
-
[50]
2025 , eprint=
Video-Bench: Human-Aligned Video Generation Benchmark , author=. 2025 , eprint=
2025
-
[51]
2025 , eprint=
HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning , author=. 2025 , eprint=
2025
-
[52]
GitHub repository , howpublished =
LightX2V Contributors , title =. GitHub repository , howpublished =. 2025 , publisher =
2025
-
[53]
2026 , eprint=
SteadyDancer: Harmonized and Coherent Human Image Animation with First-Frame Preservation , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.