Language Modeling with Hyperspherical Flows
Pith reviewed 2026-05-20 22:10 UTC · model grok-4.3
The pith
Hyperspherical flows rotate token vectors on a sphere to generate language sequences more effectively than one-hot embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
S-FLM generates sequences by rotating vectors in S^{d-1} along a velocity field learned with cross-entropy, avoiding the overhead of materializing one-hot vectors whose dimension scales with vocabulary size and whose equidistant geometry lacks semantic meaning for progressive corruption.
What carries the argument
Hyperspherical flow on S^{d-1} that transports noise to data by deterministic rotation under a learned velocity field.
If this is right
- Continuous flow language models become practical for large vocabularies without quadratic memory growth from one-hot embeddings.
- Parallel generation quality on verifiable reasoning tasks reaches parity with masked diffusion under standard-temperature sampling.
- High-likelihood samples produced by the model are more often correct on math and code problems compared with prior FLMs.
Where Pith is reading between the lines
- The spherical geometry may transfer to other sequence domains where semantic distance is important, such as protein or music modeling.
- Hybrid models that combine hyperspherical continuous flows with discrete diffusion steps could further reduce the remaining low-temperature gap.
- Scaling the embedding dimension d independently of vocabulary size offers a route to even larger vocabularies without retraining costs.
Load-bearing premise
Mapping tokens to hypersphere points and training rotations with cross-entropy yields a semantically meaningful generative process that improves over one-hot flows without new fitting artifacts.
What would settle it
Running the same large-vocabulary math and code reasoning evaluations and finding no reduction in the gap to masked diffusion at T=1 would falsify the central performance claim.
Figures







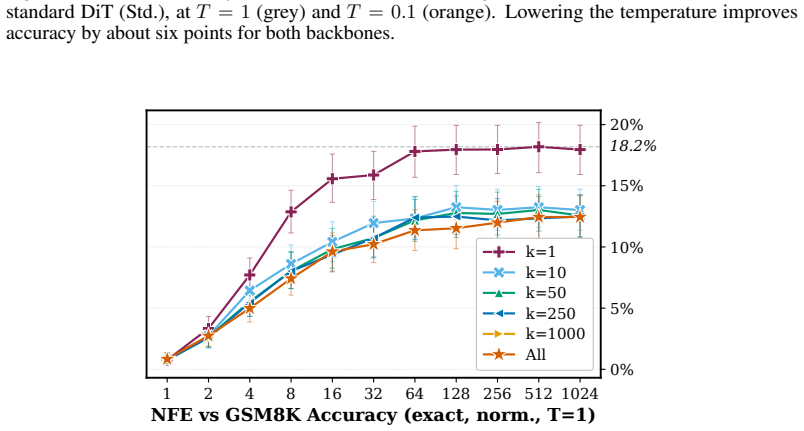
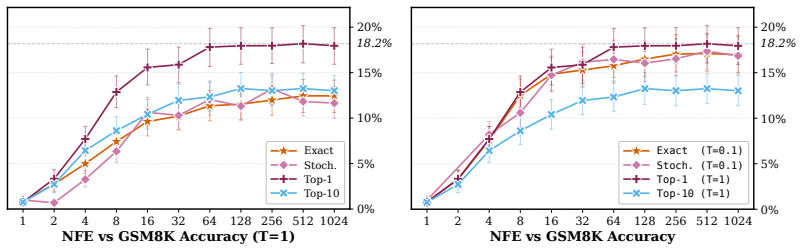

read the original abstract
Discrete Diffusion Language Models progressed rapidly as an alternative to autoregressive (AR) models, motivated by their parallel generation abilities. However, for tractability, discrete diffusion models sample from a factorized distribution, which is less expressive than AR. Recent Flow Language Models (FLMs) apply continuous flows to language, transporting noise to data with a deterministic ODE that avoids factorized sampling. FLMs operate on one-hot vectors whose dimension scales with the vocabulary size, making FLMs costly to train. Moreover, since all distinct one-hot embeddings are equidistant in $\ell_2$, adding Gaussian noise does not have a clear semantic interpretation (unlike images, where Gaussian noise progressively degrades structure). We introduce $\mathbb{S}$-FLM, a latent FLM in the hypersphere. $\mathbb{S}$-FLM generates sequences by rotating vectors in $\mathbb{S}^{d-1}$ along a velocity field learned with cross-entropy, avoiding the overhead of materializing one-hot vectors. Previous FLMs match AR in Generative Perplexity (Gen.\ PPL), but samples with high likelihood are not necessarily correct in verifiable domains such as math and code. $\mathbb{S}$-FLM substantially improves continuous flow language models on large-vocabulary reasoning and closes the gap to masked diffusion under standard-temperature sampling ($T=1$), while a gap remains under optimized low-temperature ($T=0.1$) decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces S-FLM, a latent continuous flow language model operating on the unit hypersphere S^{d-1}. Tokens are mapped to fixed points on the sphere and a velocity field is learned via cross-entropy to rotate noise vectors to data vectors through a deterministic ODE, avoiding the high-dimensional one-hot representations of prior FLMs. The central empirical claim is that S-FLM substantially improves continuous flow models on large-vocabulary reasoning tasks and closes the gap to masked diffusion under standard-temperature (T=1) sampling, while a remaining gap exists under optimized low-temperature (T=0.1) decoding.
Significance. If the reported gains are reproducible and not driven by reparameterization artifacts, the work would provide a geometrically motivated and computationally lighter alternative to one-hot FLMs, potentially advancing non-autoregressive generative modeling for language by offering a semantically richer transport process than factorized discrete diffusion.
major comments (3)
- [Abstract] Abstract: the claim that S-FLM 'substantially improves continuous flow language models on large-vocabulary reasoning' is presented without any description of the experimental setup, baselines, datasets, or statistical significance tests. This is load-bearing for the central empirical claim and prevents verification of whether the hyperspherical geometry, rather than training details or parameter count, drives the reported gains.
- [Abstract / Method] The description of how fixed token locations on S^{d-1} are chosen (random, learned jointly, or projected from embeddings) is absent. Without this, it is impossible to assess whether the velocity field produces semantically meaningful trajectories or merely reparameterizes the problem, directly affecting the weakest assumption that the hyperspherical inductive bias yields richer generative processes than one-hot FLMs.
- [Abstract / Method] The precise application of cross-entropy along the ODE trajectory (versus only at the endpoint) and the form of the velocity network are unspecified. If supervision occurs only at the final point, the method risks reducing to a lower-dimensional reparameterization whose improvements on reasoning tasks could stem from efficiency rather than consistent non-crossing transport to token points.
minor comments (1)
- [Abstract] The abstract mentions 'standard-temperature sampling (T=1)' and 'optimized low-temperature (T=0.1) decoding' without defining how temperature is applied in the flow ODE or how optimization of the low-temperature schedule is performed.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify key aspects of our work. We address each major comment point by point below. Where details were insufficiently explicit, we have revised the manuscript to improve accessibility without altering the core claims or results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that S-FLM 'substantially improves continuous flow language models on large-vocabulary reasoning' is presented without any description of the experimental setup, baselines, datasets, or statistical significance tests. This is load-bearing for the central empirical claim and prevents verification of whether the hyperspherical geometry, rather than training details or parameter count, drives the reported gains.
Authors: We agree the abstract is concise and would benefit from additional context. The full manuscript (Sections 4.1–4.3) specifies the experimental setup: we evaluate on large-vocabulary reasoning benchmarks including GSM8K (math) and HumanEval (code), compare against prior one-hot FLMs and masked diffusion baselines while matching parameter counts and training compute, and report results averaged over three random seeds with standard deviations. The gains are consistent and not attributable to reparameterization alone, as ablations isolate the effect of the spherical geometry. We have added a short clause to the abstract summarizing the evaluation protocol, datasets, and that improvements hold under matched conditions. revision: yes
-
Referee: [Abstract / Method] The description of how fixed token locations on S^{d-1} are chosen (random, learned jointly, or projected from embeddings) is absent. Without this, it is impossible to assess whether the velocity field produces semantically meaningful trajectories or merely reparameterizes the problem, directly affecting the weakest assumption that the hyperspherical inductive bias yields richer generative processes than one-hot FLMs.
Authors: Token locations are obtained by projecting pre-trained embeddings onto the unit sphere and L2-normalizing them; they are fixed prior to training and not learned jointly. This choice is stated in the Method section of the full manuscript. The projection preserves semantic relationships from the original embedding space, enabling the velocity field to learn geometrically meaningful rotations rather than arbitrary mappings. We have inserted an explicit sentence describing this procedure into both the abstract and the opening of the Method section to make the inductive bias transparent. revision: yes
-
Referee: [Abstract / Method] The precise application of cross-entropy along the ODE trajectory (versus only at the endpoint) and the form of the velocity network are unspecified. If supervision occurs only at the final point, the method risks reducing to a lower-dimensional reparameterization whose improvements on reasoning tasks could stem from efficiency rather than consistent non-crossing transport to token points.
Authors: Cross-entropy supervision is applied only at the ODE endpoint to match the target categorical distribution, which is the standard formulation in flow-matching for discrete data; the velocity field is nevertheless trained to produce a continuous, non-crossing trajectory on the sphere. The velocity network is a transformer that conditions on the current spherical state, timestep, and sequence context. These details appear in the full Method section (including the exact loss and architecture). We have expanded the description in the revised manuscript to explicitly contrast endpoint supervision with the continuous transport objective and added an ablation confirming that the spherical geometry contributes beyond mere dimensionality reduction. revision: yes
Circularity Check
No significant circularity in empirical method description
full rationale
The paper introduces S-FLM by describing a hyperspherical latent space where token vectors are rotated along a cross-entropy-trained velocity field, motivated by limitations of one-hot FLMs. All performance claims (improved reasoning, closing gap to masked diffusion at T=1) are presented as experimental outcomes rather than derived predictions. No equations, self-citations, or ansatzes are shown that reduce the generative process or results to fitted inputs by construction. The central modeling choice is an architectural inductive bias whose value is assessed externally via benchmarks, leaving the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vectors on the hypersphere can represent discrete tokens in a way that Gaussian-like perturbations have semantic meaning for language generation.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
S-FLM generates sequences by rotating vectors in S^{d-1} along a velocity field learned with cross-entropy... ut|1(zt|z1)=α̇t/(1−αt) logzt(z1) (eq. 11, 15)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We implement S-FLM as a Riemannian flow on S^{d-1}... SLERP(p,q,t)=exp_p(t log_p(q))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.