When Certainty Is an Artifact: Keyword Lexicon Blindness and the (Mis)Measurement of Rhetorical Stance
Pith reviewed 2026-06-25 19:30 UTC · model grok-4.3
The pith
Keyword lexicons measure lexical co-occurrence patterns rather than actual rhetorical stance or epistemic certainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
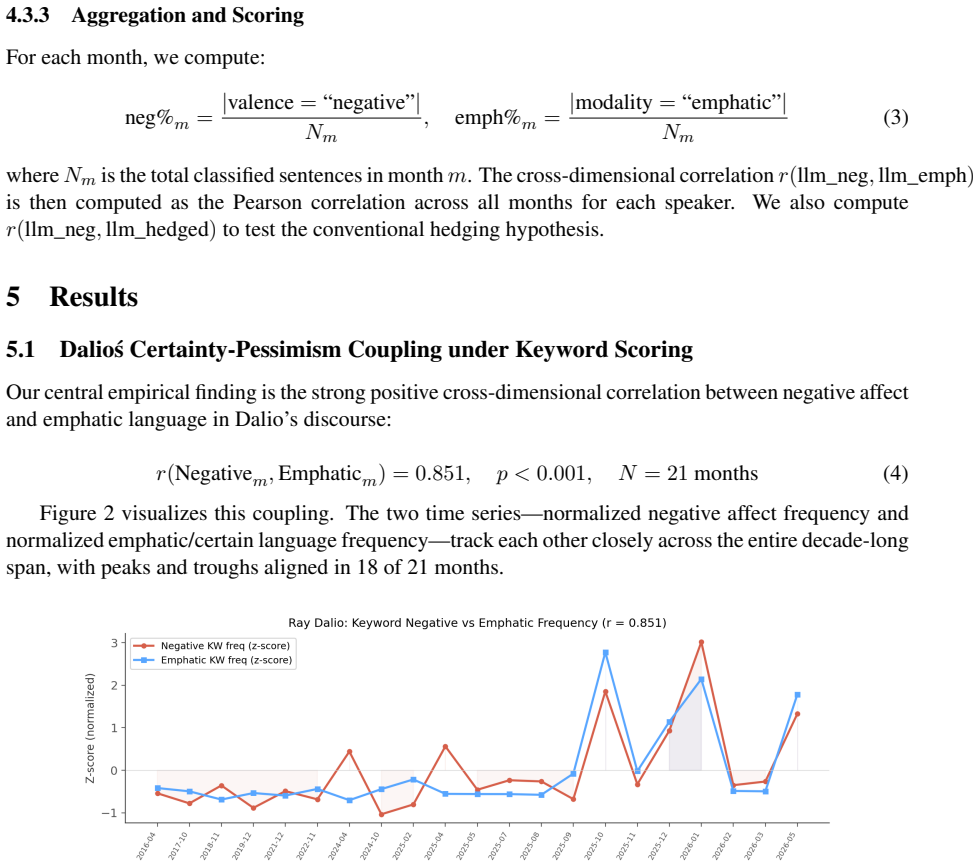
Keyword lexicon scoring detects a universal tendency for negative discourse to attract emphatic vocabulary, producing high negative-affect/emphatic-certainty correlations that largely disappear or invert when the same corpus is scored by LLM semantic classification; the paper shows this occurs because lexicons cannot distinguish syntactic scope, word sense, or missing categories, so counts of words like “never,” “absolutely,” and “confident” in the phrase “never absolutely totally confident” register as high certainty.
What carries the argument
Direct replacement of keyword lexicon counts with LLM zero-shot semantic classification on the complete diarized corpus, exposing the three structural failure modes (syntactic blindness, polysemy blindness, categorical absence) that make lexicon scores orthogonal to rhetorical stance.
If this is right
- Many published correlations between affect and certainty derived from keyword lexicons may reflect word co-occurrence habits rather than speaker psychology.
- The conventional view that pessimistic discourse attracts hedging receives support only after the measurement method is changed from keywords to semantic classification.
- Treating raw keyword counts as direct indicators of epistemic stance constitutes a category error in computational social science.
- Lexicon-based results can systematically invert the direction of relationships that semantic methods recover.
Where Pith is reading between the lines
- Existing studies that relied on the same lexicons for claims about public intellectuals or media figures may require re-analysis with context-sensitive methods.
- Similar measurement artifacts could affect other lexicon-driven variables such as sentiment polarity or moral foundations when applied to spoken or transcribed text.
- Hybrid pipelines that first apply lexicons and then filter or correct for the three blindness modes might reduce the discrepancy without full LLM replacement.
Load-bearing premise
That LLM zero-shot classification on full sentences supplies a valid ground-truth measure of certainty, hedging, and negative affect without its own systematic misclassifications that could produce the observed shifts.
What would settle it
Human annotation of a random sample of the same sentences for the three rhetorical dimensions, followed by a direct correlation comparison showing whether keyword scores or LLM scores align more closely with the human labels.
Figures
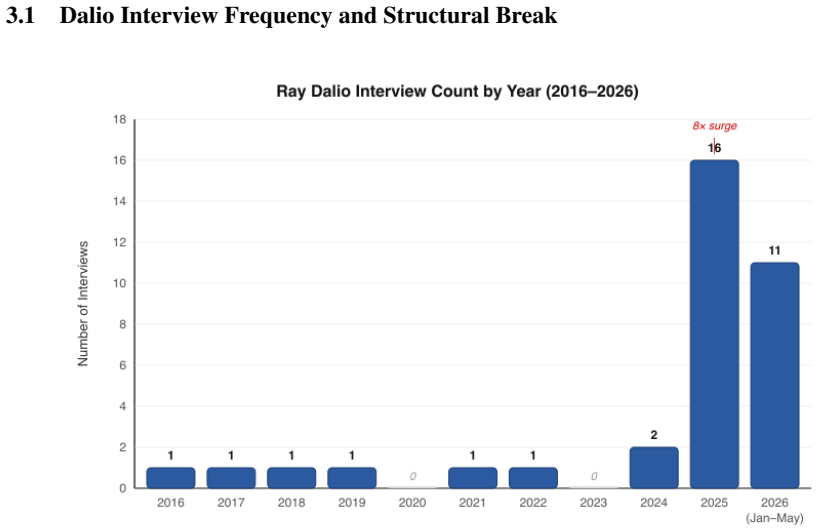
read the original abstract
Can a statistically significant, large-effect-size finding in computational social science be entirely an artifact of the measurement instrument? We present a case where the answer appears to be yes. Analyzing 85 interviews across four public intellectuals (2016--2026), we find a robust negative-affect/emphatic-certainty lexical co-occurrence pattern under keyword-based scoring ($r = 0.72$--$0.93$, $p < 0.01$ for all four speakers). Replacing keyword counting with LLM-based zero-shot semantic classification on the complete diarized corpus (32,625 sentences) dramatically reduces this correlation: Dalio's $r = 0.851$ drops to $r = 0.206$, with two speakers showing negative $r(\text{neg}, \text{emphatic})$ and one showing null. In contrast, the LLM reveals a strong negative-hedging coupling across speakers -- Rogoff's $r(\text{neg}, \text{hedged}) = 0.875$ ($p = 0.001$) and Zeihan's $r(\text{neg}, \text{hedged}) = 0.722$ ($p = 0.008$) -- consistent with the conventional expectation that pessimistic discourse attracts hedging, not certainty. Sentence-level error analysis traces this discrepancy to three structural failure modes in keyword lexicons -- syntactic blindness, polysemy blindness, and categorical absence -- illustrated through cases where keyword counting inverts semantic meaning (e.g., ''never absolutely totally confident'' scored as high-certainty). We argue that keyword lexicons measure a universal lexical co-occurrence tendency -- negative discourse naturally attracts emphatic vocabulary -- that is orthogonal to, and can systematically invert, rhetorical stance. Treating keyword counts as measurements of epistemic certainty is a category error: a finding that appears to be about a speaker's psychology may be entirely about the counting of words.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that keyword lexicons for epistemic certainty, hedging, and negative affect produce artifactual correlations (r=0.72–0.93) in 85 interviews with four speakers because they suffer from syntactic blindness, polysemy, and categorical absence; replacing them with LLM zero-shot semantic classification on the full 32,625-sentence diarized corpus reduces or reverses the certainty–negative-affect correlations (e.g., Dalio r drops from 0.851 to 0.206) while revealing the expected negative-affect–hedging pattern, demonstrating that keyword counts measure lexical co-occurrence rather than rhetorical stance.
Significance. If the LLM labels are shown to be valid, the result would be a substantive methodological warning for computational social science: many published correlations between lexical certainty markers and affect may be measurement artifacts rather than evidence about speakers’ psychology. The scale of the corpus and the concrete inversion examples (e.g., “never absolutely totally confident”) strengthen the demonstration that the discrepancy is structural rather than idiosyncratic.
major comments (2)
- [Abstract and §3] Abstract and §3 (results): the central claim that LLM zero-shot classification reveals the “true” rhetorical stance rests on the untested premise that the LLM is systematically more valid than the keyword lexicons. No human-annotated gold standard, inter-rater reliability, accuracy metrics, or error analysis for the zero-shot labels is reported; without this, the observed correlation shifts (Dalio r=0.851→0.206, sign changes for two speakers) could equally reflect LLM-specific biases such as default hedging or context misreading, leaving the category-error conclusion unsupported.
- [§4] §4 (error analysis): the three failure modes are illustrated with selected counter-examples but are not quantified across the 32,625 sentences. It is therefore unclear what fraction of the corpus is affected by syntactic blindness, polysemy, or categorical absence, and whether these modes account for the full magnitude of the reported correlation drops.
minor comments (2)
- [Methods] The manuscript should report the exact LLM prompts, model version, temperature, and any post-processing rules used for zero-shot classification.
- [Methods] Corpus construction details (interview selection criteria, diarization method, sentence segmentation) are referenced but not fully specified; these are needed to assess generalizability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (results): the central claim that LLM zero-shot classification reveals the “true” rhetorical stance rests on the untested premise that the LLM is systematically more valid than the keyword lexicons. No human-annotated gold standard, inter-rater reliability, accuracy metrics, or error analysis for the zero-shot labels is reported; without this, the observed correlation shifts (Dalio r=0.851→0.206, sign changes for two speakers) could equally reflect LLM-specific biases such as default hedging or context misreading, leaving the category-error conclusion unsupported.
Authors: We agree that the manuscript does not report a human-annotated gold standard or accuracy metrics for the LLM zero-shot labels, which leaves open the possibility of LLM-specific biases. Our primary argument is comparative: the keyword method produces results inconsistent with established expectations from the hedging and affect literature (negative affect should pair with hedging), while the LLM results are consistent with those expectations, and the lexicon method demonstrably inverts meaning in the provided counter-examples. We will add a limitations paragraph acknowledging the absence of direct validation and include a small-scale human annotation check on a subsample in the revision to assess LLM label quality. revision: yes
-
Referee: [§4] §4 (error analysis): the three failure modes are illustrated with selected counter-examples but are not quantified across the 32,625 sentences. It is therefore unclear what fraction of the corpus is affected by syntactic blindness, polysemy, or categorical absence, and whether these modes account for the full magnitude of the reported correlation drops.
Authors: The error analysis is intended to be illustrative, identifying the structural mechanisms (syntactic blindness, polysemy, categorical absence) that allow keyword counts to invert semantic meaning. We did not quantify the exact prevalence of each mode across the full corpus. The demonstration does not require that these modes explain the entire correlation drop, only that they are sufficient to produce artifactual results. We will revise §4 to explicitly state the illustrative purpose and add this as a limitation. revision: partial
Circularity Check
No circularity: independent measurement comparison on shared corpus
full rationale
The paper's core result is an empirical discrepancy between two distinct scoring procedures (keyword lexicon counts vs. LLM zero-shot labels) applied to the identical set of 32,625 sentences. No parameter is fitted to the target correlations and then re-used as a 'prediction'; no derivation reduces to a self-citation chain; no ansatz or uniqueness theorem is invoked. The reported r-value drops are direct outputs of the two independent classifiers rather than algebraic identities or fitted-input artifacts. The analysis therefore remains self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM zero-shot semantic classification accurately captures rhetorical stance (certainty, hedging, negative affect) without systematic errors that would explain the observed differences from keyword results.
Reference graph
Works this paper leans on
-
[1]
V ADER: A parsimonious rule-based model for sentiment analysis of social media text
C. J. Hutto and E. Gilbert. “V ADER: A parsimonious rule-based model for sentiment analysis of social media text.” InProc. ICWSM, 2014
2014
-
[2]
The development and psychometric prop- erties of LIWC2015
J. Pennebaker, R. Boyd, K. Jordan, and K. Blackburn. “The development and psychometric prop- erties of LIWC2015.” University of Texas at Austin, 2015
2015
-
[3]
When is a liability not a liability? Textual analysis, dictionaries, and 10-Ks
T. Loughran and B. McDonald. “When is a liability not a liability? Textual analysis, dictionaries, and 10-Ks.”Journal of Finance, 66(1):35–65, 2011
2011
-
[4]
BERT: Pre-training of deep bidirectional transformers for language understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. “BERT: Pre-training of deep bidirectional transformers for language understanding.” InProc. NAACL, 2019
2019
-
[5]
RoBERTa: A robustly optimized BERT pretraining approach
Y . Liu et al. “RoBERTa: A robustly optimized BERT pretraining approach.”arXiv:1907.11692, 2019
Pith/arXiv arXiv 1907
-
[6]
Text style transfer and sentiment analysis: A case study in confounding factors
K. Keith et al. “Text style transfer and sentiment analysis: A case study in confounding factors.” In Proc. ACL, 2020
2020
-
[7]
How context affects language models’ factual predictions
F. Petroni et al. “How context affects language models’ factual predictions.” InProc. AKBC, 2020
2020
-
[8]
F. R. Palmer.Mood and Modality. Cambridge University Press, 2001
2001
-
[9]
Stance and engagement: A model of interaction in academic discourse
K. Hyland. “Stance and engagement: A model of interaction in academic discourse.”Discourse Studies, 7(2):173–192, 2005
2005
-
[10]
R. P. Hart.Campaign Talk: Why Elections Are Good for Us. Princeton University Press, 2000
2000
-
[11]
Leading in an uncertain world: A rhetorical analysis of Federal Reserve communications
M. C. Bligh and J. C. Hess. “Leading in an uncertain world: A rhetorical analysis of Federal Reserve communications.”Leadership Quarterly, 2010
2010
-
[12]
Temporal dynamics of sentiment in online discourse
Y . Wang, J. Zhao, and M. Zhu. “Temporal dynamics of sentiment in online discourse.” InProc. ACL, 2019
2019
-
[13]
Time-aware sentiment analysis of political speeches
K. Larsen, L. Hansen, and P. Johansen. “Time-aware sentiment analysis of political speeches.” Journal of Computational Linguistics, 47(3):521–548, 2021. 15
2021
-
[14]
The Fed and the stock market: A textual analysis of FOMC minutes
W. Brady et al. “The Fed and the stock market: A textual analysis of FOMC minutes.”Journal of Financial Economics, 2022
2022
-
[15]
yt-dlp: A youtube-dl fork with additional features and fixes
yt-dlp Contributors. “yt-dlp: A youtube-dl fork with additional features and fixes.” https://github.com/yt-dlp/yt-dlp, 2024
2024
-
[16]
youtube-transcript-api: A Python API for retrieving YouTube transcripts
J. Depoix. “youtube-transcript-api: A Python API for retrieving YouTube transcripts.” https://github.com/jdepoix/youtube-transcript-api, 2020
2020
-
[17]
BERT rediscovers the classical NLP pipeline
I. Tenney, D. Das, and E. Pavlick. “BERT rediscovers the classical NLP pipeline.” InProc. ACL, 2019
2019
-
[18]
ChatGPT outperforms crowd workers for text-annotation tasks
F. Gilardi, M. Alizadeh, and M. Kubli. “ChatGPT outperforms crowd workers for text-annotation tasks.”Proceedings of the National Academy of Sciences, 120(30):e2305016120, 2023
2023
-
[19]
ChatGPT for text annotation? Mind the hype!
E. Ollion, Y . Shen, and A. Macanovic. “ChatGPT for text annotation? Mind the hype!” SocArXiv preprint, 2023
2023
-
[20]
Can large language models transform computational social science?
C. Ziems, W. Held, O. Shaikh, J. Chen, Z. Zhang, and D. Yang. “Can large language models transform computational social science?”Computational Linguistics, 50(1):237–272, 2024
2024
-
[21]
Can generative AI improve social science?
C. A. Bail. “Can generative AI improve social science?”Proceedings of the National Academy of Sciences, 121(21):e2314021121, 2024
2024
-
[22]
Financial statement analysis with large language models
A. Kim, M. Muhn, and V . Nikolaev. “Financial statement analysis with large language models.” SSRN Working Paper 4835311, 2024
2024
-
[23]
Hyland.Metadiscourse: Exploring Interaction in Writing
K. Hyland.Metadiscourse: Exploring Interaction in Writing. Continuum, 2005. 16
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.