Cinematic Compositing Using Character-Environment-Harmonized Video Generation Models
Pith reviewed 2026-06-26 21:17 UTC · model grok-4.3
The pith
An end-to-end video diffusion framework jointly models how characters physically affect environments and how environments relight characters for realistic compositing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
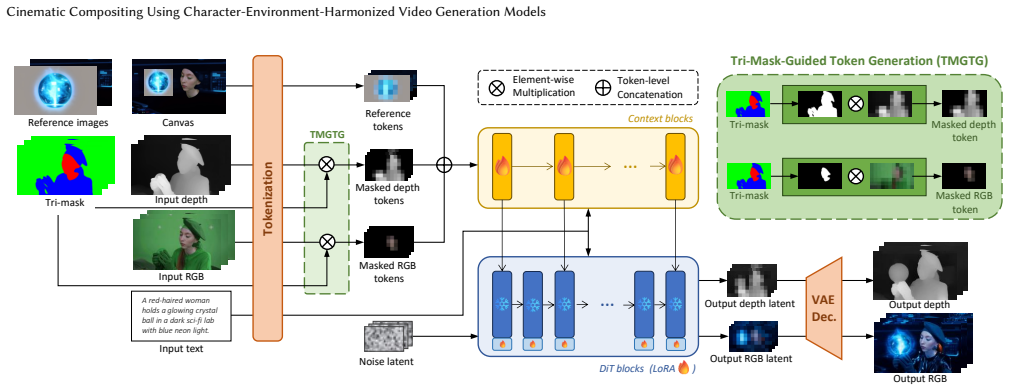
We propose an end-to-end video diffusion framework that jointly models C2E and E2C interactions, specifically handling the challenges of interactive props. Our approach introduces a tri-mask-guided architecture with RGB-D joint denoising to ensure physically consistent interactions among the character, props, and environment. We further develop an efficient prior-driven data curation pipeline to construct high-quality relighting pairs without expensive rendering. Finally, a reference-conditioned mechanism enables controllable environment synthesis and precise prop replacement.
What carries the argument
Tri-mask-guided video diffusion with RGB-D joint denoising that enforces bidirectional physical and photometric consistency between character, props, and environment.
If this is right
- Interactive props can be moved by the character and produce consistent environmental responses in the output video.
- Lighting on the inserted character and props matches the target environment without separate post-processing.
- Users can control the output environment or replace specific props using a reference image at inference time.
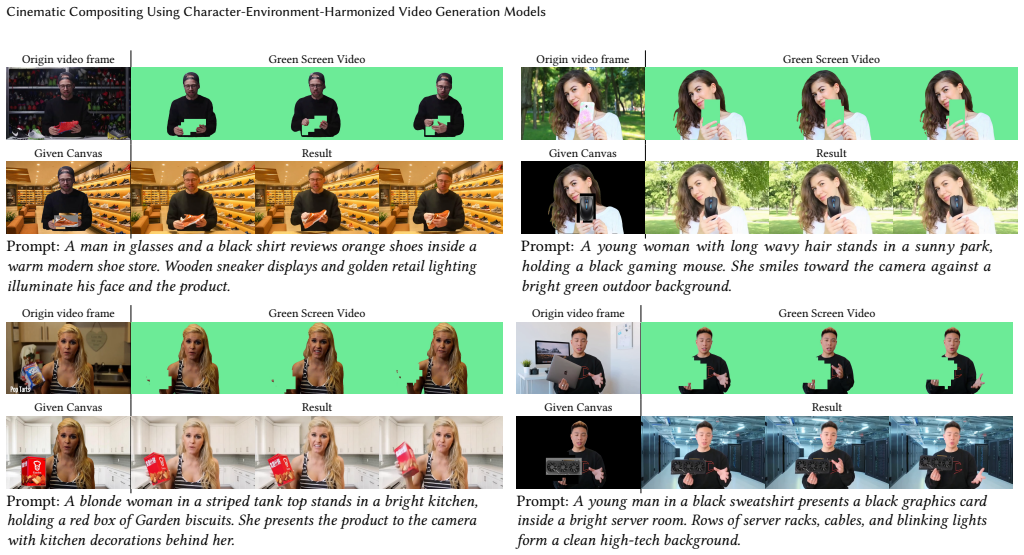
- The method produces higher-quality dynamic compositing than prior separate-stage approaches on the same tasks.
Where Pith is reading between the lines
- The same joint-interaction idea could be tested on other generative tasks that require bidirectional consistency, such as object insertion in 3D scenes.
- If the data curation step scales, it might reduce reliance on synthetic rendering datasets for training video models.
- Real-time versions would need to check whether the RGB-D denoising step can be accelerated without losing the physical consistency the model claims to achieve.
Load-bearing premise
The prior-driven data curation pipeline can produce high-quality relighting pairs sufficient to train the joint C2E/E2C model without expensive rendering or manual annotation.
What would settle it
A generated video sequence in which a character physically interacts with a prop (for example, picking it up or pushing it) but the environment shows no corresponding change in shadows, motion, or contact points.
Figures








read the original abstract
Cinematic compositing aims to integrate green-screen characters into novel environments while maintaining physical and photometric realism. Previous methods often fail to capture the complex bidirectional interactions between characters and their surroundings, which we characterize as Character-to-Environment (C2E) physical interaction and Environment-to-Character (E2C) lighting harmonization. To address this, we propose an end-to-end video diffusion framework that jointly models C2E and E2C interactions, specifically handling the challenges of interactive props. Our approach introduces a tri-mask-guided architecture with RGB-D joint denoising to ensure physically consistent interactions among the character, props, and environment. We further develop an efficient prior-driven data curation pipeline to construct high-quality relighting pairs without expensive rendering. Finally, a reference-conditioned mechanism enables controllable environment synthesis and precise prop replacement. Extensive experiments demonstrate that our framework significantly outperforms existing methods in cinematic-quality dynamic video compositing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an end-to-end video diffusion framework for cinematic compositing of green-screen characters into novel environments. It jointly models bidirectional Character-to-Environment (C2E) physical interactions and Environment-to-Character (E2C) lighting harmonization, with specific handling for interactive props via a tri-mask-guided architecture and RGB-D joint denoising. A prior-driven data curation pipeline generates relighting pairs without expensive rendering, and a reference-conditioned mechanism supports controllable synthesis. The abstract claims significant outperformance over prior methods in physical and photometric realism.
Significance. If validated, the approach could meaningfully advance video diffusion models for realistic compositing by addressing joint C2E/E2C dynamics and reducing reliance on manual annotation or full rendering pipelines. The tri-mask + RGB-D design and prior-driven curation are potentially reusable ideas for other harmonization tasks. However, the current lack of quantitative support leaves the significance unestablished.
major comments (2)
- [§3.2] §3.2: The prior-driven data curation pipeline (prior extraction, mask propagation, relighting synthesis) is presented as sufficient to train the joint model without expensive rendering, yet the manuscript reports only qualitative examples of the pairs and downstream metrics; no direct quantitative measures of pair fidelity (e.g., relighting PSNR, shadow consistency, contact geometry error) versus ground-truth rendered pairs are provided. This is load-bearing for the central claim that the synthetic data enables correct learning of bidirectional interactions.
- [§4] §4 (Experiments): The abstract states that 'extensive experiments demonstrate that our framework significantly outperforms existing methods,' but the manuscript supplies no quantitative tables, ablation studies on the tri-mask or RGB-D components, error analysis, or implementation details (e.g., training data scale, diffusion steps). Without these, the outperformance claim cannot be evaluated.
minor comments (1)
- The tri-mask and RGB-D joint denoising architecture is described at a high level; a diagram or pseudocode would clarify how the masks condition the denoising process across C2E and E2C directions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2: The prior-driven data curation pipeline (prior extraction, mask propagation, relighting synthesis) is presented as sufficient to train the joint model without expensive rendering, yet the manuscript reports only qualitative examples of the pairs and downstream metrics; no direct quantitative measures of pair fidelity (e.g., relighting PSNR, shadow consistency, contact geometry error) versus ground-truth rendered pairs are provided. This is load-bearing for the central claim that the synthetic data enables correct learning of bidirectional interactions.
Authors: We agree that direct quantitative fidelity metrics against rendered ground truth would provide additional support. However, the pipeline is explicitly designed to generate pairs without any rendering step, so no such ground-truth rendered pairs exist by construction. Validation instead occurs through the downstream compositing task performance, which directly measures whether bidirectional interactions are learned correctly. We will expand the supplementary material with additional qualitative side-by-side comparisons and indirect consistency checks (e.g., shadow alignment statistics) to further substantiate the pipeline. revision: partial
-
Referee: [§4] §4 (Experiments): The abstract states that 'extensive experiments demonstrate that our framework significantly outperforms existing methods,' but the manuscript supplies no quantitative tables, ablation studies on the tri-mask or RGB-D components, error analysis, or implementation details (e.g., training data scale, diffusion steps). Without these, the outperformance claim cannot be evaluated.
Authors: We acknowledge that the main text would benefit from consolidated quantitative tables and component ablations. Implementation details (training scale, diffusion steps, etc.) are provided in the supplementary material; we will move the key specifications into the main paper. We will also add explicit ablation tables for the tri-mask and RGB-D modules plus error analysis in the revised version to make the outperformance claims directly verifiable. revision: yes
Circularity Check
No circularity detected; derivation is self-contained
full rationale
The paper proposes an end-to-end video diffusion framework with tri-mask-guided architecture, RGB-D joint denoising, a prior-driven data curation pipeline, and reference-conditioned mechanism. No equations, fitted parameters called predictions, self-citations as load-bearing premises, or ansatzes smuggled via prior work are present in the provided text. The central claims rest on the described architecture and pipeline quality, which are presented as novel contributions rather than reductions to inputs by construction. This matches the expected case of an honest non-finding for a methods paper without detectable self-referential loops.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wan-animate: Unified character animation and replacement with holistic replication.arXiv preprint arXiv:2509.14055 (2025). Ye Fang, Zeyi Sun, Shangzhan Zhang, Tong Wu, Yinghao Xu, Pan Zhang, Jiaqi Wang, Gordon Wetzstein, and Dahua Lin
arXiv 2025
-
[2]
RelightVid: Temporal-Consistent Diffusion Model for Video Relighting.arXiv preprint arXiv:2501.16330(2025). Kai He, Ruofan Liang, Jacob Munkberg, Jon Hasselgren, Nandita Vijaykumar, Alexander Keller, Sanja Fidler, Igor Gilitschenski, Zan Gojcic, and Zian Wang
arXiv 2025
-
[3]
LoRA: Low-Rank Adaptation of Large Language Models.arXiv preprint arXiv:2106.09685(2021). Li Hu, Guangyuan Wang, Zhen Shen, Xin Gao, Dechao Meng, Lian Zhuo, Peng Zhang, Bang Zhang, and Liefeng Bo. 2025b. Animate Anyone 2: High-Fidelity Character Image Animation with Environment Affordance. InProceedings of the IEEE/CVF International Conference on Computer...
Pith/arXiv arXiv 2021
-
[4]
Jizhizi Li, Jing Zhang, Stephen J Maybank, and Dacheng Tao
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models.arXiv preprint arXiv:2301.12597(2023). Jizhizi Li, Jing Zhang, Stephen J Maybank, and Dacheng Tao
Pith/arXiv arXiv 2023
-
[5]
Shanchuan Lin et al
Bridging composite and real: towards end-to-end deep image matting.International Journal of Computer Vision130, 2 (2022), 246–266. Shanchuan Lin et al
2022
-
[6]
EditCtrl: Disentangled Local and Global Control for Real-Time Generative Video Editing.arXiv preprint arXiv:2602.15031 (2026). Bangya Liu, Xinyu Gong, Zelin Zhao, Ziyang Song, Yulei Lu, Suhui Wu, Jun Zhang, Suman Banerjee, and Hao Zhang. 2025a. ByteLoom: Weaving Geometry-Consistent Human-Object Interactions through Progressive Curriculum Learning.arXiv pr...
arXiv 2026
-
[7]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499 (2023). Tianqi Liu, Zhaoxi Chen, Zihao Huang, Shaocong Xu, Saining Zhang, Chongjie Ye, Bohan Li, Zhiguo Cao, Wei Li, Hao Zhao, and Ziwei Liu
Pith/arXiv arXiv 2023
-
[8]
Yizuo Peng, Xuelin Chen, Kai Zhang, and Xiaodong Cun
Actanywhere: Subject-aware video background generation.Advances in Neural Information Processing Systems37 (2024), 29754– 29776. Yizuo Peng, Xuelin Chen, Kai Zhang, and Xiaodong Cun
2024
-
[9]
SAM 2: Segment Anything in Images and Videos. arXiv:2408.00714 [cs.CV] https://arxiv.org/abs/2408.00714 Mengwei Ren, Wei Xiong, Jae Shin Yoon, Zhixin Shu, Jianming Zhang, HyunJoon Jung, Guido Gerig, and He Zhang
-
[10]
Wan: Open and Advanced Large-Scale Video Generative Models.arXiv preprint arXiv:2503.20314(2025). Weiqing Xiao, Hong Li, Xiuyu Yang, Houyuan Chen, Yi Wen, Tianqi Liu, Shaocong Xu, Chongjie Ye, Hao Zhao, and Beibei Wang
Pith/arXiv arXiv 2025
-
[11]
Relit-LiVE: Relight Video by Jointly Learning Environment Video.arXiv preprint arXiv:2605.06658(2026). Hu Xu, Gargi Ghosh, Po-Yao Huang, Dmytro Okhonko, Armen Aghajanyan, Florian Metze, Luke Zettlemoyer, and Christoph Feichtenhofer
Pith/arXiv arXiv 2026
-
[12]
InProceedings of the 2021 conference on empirical methods in natural language processing
VideoCLIP: Con- trastive Pre-training for Zero-shot Video-Text Understanding. InProceedings of the 2021 conference on empirical methods in natural language processing. 6787–6800. Ziyi Xu, Ziyao Huang, Juan Cao, Yong Zhang, Xiaodong Cun, Qing Shuai, Yuchen Wang, Linchao Bao, and Fan Tang. 2026a. AnchorCrafter: Animate cyber-anchors selling your products vi...
Pith/arXiv arXiv 2021
-
[13]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
MatAnyone 2: Scaling Video Matting via a Learned Quality Evaluator. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Peiqing Yang, Shangchen Zhou, Jixin Zhao, Qingyi Tao, and Chen Change Loy. 2025c. MatAnyone: Stable Video Matting with Consistent Memory Propagation.arXiv preprint arXiv:2501.14677(2025). Mingshuai...
arXiv 2025
-
[14]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala
Beyond Static Scenes: Camera-controllable Background Generation for Human Motion.arXiv preprint arXiv:2504.02004(2025). Lvmin Zhang, Anyi Rao, and Maneesh Agrawala
arXiv 2025
-
[15]
InThe Thirteenth International Conference on Learning Representations
Scaling In-the-Wild Training for Diffusion-based Illumination Harmonization and Editing by Imposing Con- sistent Light Transport. InThe Thirteenth International Conference on Learning Representations. Yuang Zhang, Jiaxi Gu, Li-Wen Wang, Han Wang, Junqi Cheng, Yuefeng Zhu, and Fangyuan Zou. 2024a. MimicMotion: High-Quality Human Motion Video Gen- eration w...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.