DimMem: Dimensional Structuring for Efficient Long-Term Agent Memory
Pith reviewed 2026-05-20 18:55 UTC · model grok-4.3
The pith
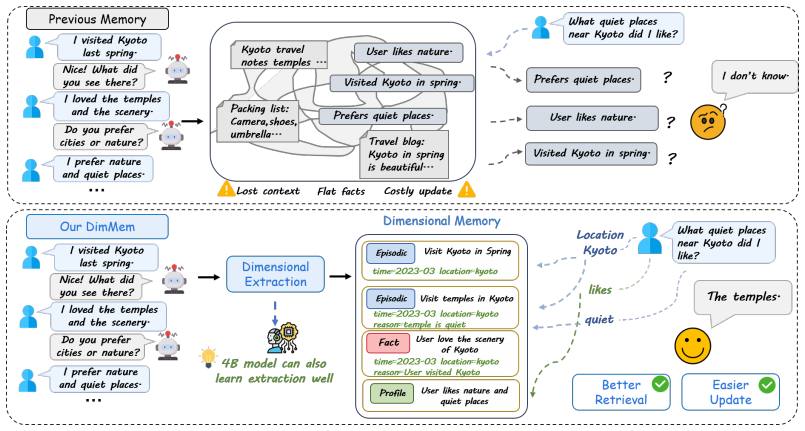
DimMem represents each memory as a typed unit with explicit fields like time, location, reason, purpose and keywords to support efficient long-term recall in LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DimMem structures each memory as an atomic, typed, and self-contained unit with explicit fields such as time, location, reason, purpose, and keywords. This representation exposes the structure needed for dimension-aware retrieval, memory update, and selective assistant-context recall without storing full histories in the model context. Across LoCoMo-10 and LongMemEval-S, the method achieves 81.43 percent and 78.20 percent overall accuracy, outperforming existing lightweight memory systems while reducing LoCoMo per-query token cost by 24 percent. Dimensional memory extraction is learnable by compact models: after fine-tuning on the DimMem schema, a Qwen3-4B extractor surpasses LightMem with a
What carries the argument
The dimensional memory unit, an atomic typed self-contained representation carrying explicit fields for time, location, reason, purpose, and keywords that enables dimension-aware retrieval and selective context injection.
If this is right
- Agents can sustain longer histories without exceeding context windows because only selected dimensional fields are injected.
- Retrieval can be performed along individual dimensions such as keywords or time rather than scanning entire records.
- Memory updates can modify or add a single field without rewriting an entire summary.
- Compact models become practical for the extraction step once fine-tuned on the schema.
Where Pith is reading between the lines
- The same explicit-field approach could be applied to other agent components such as goal tracking or tool-use logs.
- Extending the field set dynamically per domain might improve performance on specialized tasks without increasing overall token load.
- Combining the dimensional units with embedding-based search could further accelerate retrieval while preserving the interpretability of the typed fields.
Load-bearing premise
The chosen set of explicit fields is assumed to capture enough structure for precise recall and selective context injection without requiring the full original dialogue history.
What would settle it
A head-to-head test in which the same agent queries are answered once with DimMem and once with the complete original dialogue turns injected into context; if the full-history version shows materially higher accuracy on the same benchmarks, the sufficiency of the five fields would be in doubt.
Figures








read the original abstract
Large language model (LLM) agents require long-term memory to leverage information from past interactions. However, existing memory systems often face a fidelity--efficiency trade-off: raw dialogue histories are expensive, while flat facts or summaries may discard the structure needed for precise recall. We propose \textbf{DimMem}, a lightweight dimensional memory framework that represents each memory as an atomic, typed, and self-contained unit with explicit fields such as time, location, reason, purpose, and keywords. This representation exposes the structure needed for dimension-aware retrieval, memory update, and selective assistant-context recall without storing full histories in the model context. Across LoCoMo-10 and LongMemEval-S, DimMem achieves \textbf{81.43\%} and \textbf{78.20\%} overall accuracy, respectively, outperforming existing lightweight memory systems while reducing LoCoMo per-query token cost by \textbf{24\%}. We further show that dimensional memory extraction is learnable by compact models: after fine-tuning on the DimMem schema, a Qwen3-4B extractor surpasses LightMem with GPT-4.1-mini on both benchmarks and reaches performance comparable to, or better than, much larger extractors in key settings. These results suggest that explicit dimensional structuring is an effective and efficient foundation for long-term memory in LLM agents. Code is available at https://github.com/ChowRunFa/DimMem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DimMem, a lightweight dimensional memory framework for LLM agents that represents each memory as an atomic unit with explicit fields (time, location, reason, purpose, keywords). This structure supports dimension-aware retrieval, memory updates, and selective context recall without storing full dialogue histories. Empirical results show DimMem achieving 81.43% overall accuracy on LoCoMo-10 and 78.20% on LongMemEval-S, outperforming existing lightweight memory systems with a 24% reduction in LoCoMo per-query token cost. The work also shows that a Qwen3-4B model fine-tuned on the DimMem schema can serve as an effective extractor, matching or exceeding larger models in key settings. Code is released at https://github.com/ChowRunFa/DimMem.
Significance. If the results hold after addressing the noted gaps, this work offers a practical path to balancing fidelity and efficiency in long-term agent memory by leveraging explicit dimensional structure rather than raw histories or flat summaries. The release of code and the demonstration that compact models can learn the extraction task are clear strengths supporting reproducibility. The findings could inform memory module design in LLM agent systems, particularly where token efficiency and precise recall are priorities.
major comments (2)
- [Results section, Table 1] Results section, Table 1 (or equivalent benchmark table): The overall accuracies of 81.43% on LoCoMo-10 and 78.20% on LongMemEval-S are reported without error bars, standard deviations, or statistical significance tests relative to baselines such as LightMem. This makes it difficult to assess the reliability of the claimed outperformance and 24% token reduction.
- [§4.3 Ablation Studies] §4.3 or Ablation Studies subsection: The evaluation compares a fine-tuned Qwen3-4B DimMem extractor against LightMem (GPT-4.1-mini) but provides no controlled ablation that holds the extractor model fixed while varying only the representation (dimensional fields vs. flat text or summary). This leaves open whether the performance lift is attributable to the explicit fields or primarily to schema-specific fine-tuning, directly affecting the central claim that the chosen fields enable precise recall without full history.
minor comments (2)
- [Abstract] Abstract: The 24% token cost reduction is stated without specifying the exact baseline system or providing absolute token counts for context.
- [Figures] Figure captions and legends: Some figures illustrating retrieval flow would benefit from explicit labels indicating how dimension-specific queries map to selected memory units.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve statistical reporting and add a controlled ablation.
read point-by-point responses
-
Referee: [Results section, Table 1] Results section, Table 1 (or equivalent benchmark table): The overall accuracies of 81.43% on LoCoMo-10 and 78.20% on LongMemEval-S are reported without error bars, standard deviations, or statistical significance tests relative to baselines such as LightMem. This makes it difficult to assess the reliability of the claimed outperformance and 24% token reduction.
Authors: We agree that error bars and statistical tests are needed to strengthen the claims. In the revision we will rerun all evaluations across 5 random seeds, report means with standard deviations in Table 1, and include paired significance tests (e.g., t-tests) against LightMem and other baselines. The 24% token reduction will also be reported with variance. revision: yes
-
Referee: [§4.3 Ablation Studies] §4.3 or Ablation Studies subsection: The evaluation compares a fine-tuned Qwen3-4B DimMem extractor against LightMem (GPT-4.1-mini) but provides no controlled ablation that holds the extractor model fixed while varying only the representation (dimensional fields vs. flat text or summary). This leaves open whether the performance lift is attributable to the explicit fields or primarily to schema-specific fine-tuning, directly affecting the central claim that the chosen fields enable precise recall without full history.
Authors: This is a fair observation. To isolate the contribution of the dimensional fields, we will add a controlled ablation in the revised §4.3 that fine-tunes the identical Qwen3-4B model on both the DimMem schema and a flat-text/summary schema, then evaluates both on LoCoMo-10 and LongMemEval-S under the same retrieval protocol. This will directly test whether the explicit fields, rather than fine-tuning alone, drive the observed gains. revision: yes
Circularity Check
No circularity: purely empirical proposal and benchmark results
full rationale
The paper introduces DimMem as a structured memory representation with explicit fields and reports empirical accuracies (81.43% on LoCoMo-10, 78.20% on LongMemEval-S) plus token reduction after fine-tuning a Qwen3-4B extractor on the schema. No equations, derivations, or self-referential definitions appear in the provided text; performance numbers are obtained via standard benchmark evaluation rather than any fitted parameter renamed as a prediction or any load-bearing self-citation chain. The central claim rests on comparative results against baselines, which are externally falsifiable and do not reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Explicit fields such as time, location, reason, purpose, and keywords expose sufficient structure for dimension-aware retrieval and selective context recall.
invented entities (1)
-
Dimensional memory unit
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DimMem represents each memory as an atomic, typed, and self-contained unit with explicit fields such as time, location, reason, purpose, and keywords. This representation exposes the structure needed for dimension-aware retrieval, memory update, and selective assistant-context recall
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Inspired by cognitive distinctions among episodic, semantic, and personal semantic memory and by event-oriented 5W1H information structure
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S
Joon Sung Park, Joseph C. O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, UIST 2023, pages 2:1–2:22. ACM, 2023
work page 2023
-
[2]
MemoryBank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. MemoryBank: Enhancing large language models with long-term memory. InThirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, pages 19724–19731. AAAI Press, 2024
work page 2024
-
[3]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems.CoRR, abs/2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory.CoRR, abs/2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents.CoRR, abs/2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
LightMem: Lightweight and Efficient Memory-Augmented Generation
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Huajun Chen, and Ningyu Zhang. LightMem: Lightweight and efficient memory-augmented generation.CoRR, abs/2510.18866, 2025
work page internal anchor Pith review arXiv 2025
-
[7]
Simplemem: Efficient lifelong memory for llm agents.arXiv preprint arXiv:2601.02553, 2026
Jiaqi Liu, Yaofeng Su, Peng Xia, Siwei Han, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Yao. SimpleMem: Efficient lifelong memory for LLM agents.CoRR, abs/2601.02553, 2026
-
[8]
Evaluating very long-term conversational memory of LLM agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, pages 13851–13870. Association for Computational Linguistics, 2024
work page 2024
-
[9]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. LongMemEval: Benchmarking chat assistants on long-term interactive memory.CoRR, abs/2410.10813, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
GAM: Hierarchical Graph-based Agentic Memory for LLM Agents
Zhaofen Wu, Hanrong Zhang, Fulin Lin, Wujiang Xu, Xinran Xu, Yankai Chen, Henry Peng Zou, Shaowen Chen, Weizhi Zhang, Xue Liu, Philip S. Yu, and Hongwei Wang. GAM: Hierarchical graph-based agentic memory for LLM agents.CoRR, abs/2604.12285, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
HiMem: Hierarchical long-term memory for LLM long-horizon agents.CoRR, abs/2601.06377, 2026
Ningning Zhang, Xingxing Yang, Zhizhong Tan, Weiping Deng, and Wenyong Wang. HiMem: Hierarchical long-term memory for LLM long-horizon agents.CoRR, abs/2601.06377, 2026
-
[12]
StructMem: Structured Memory for Long-Horizon Behavior in LLMs
Buqiang Xu, Yijun Chen, Jizhan Fang, Ruobin Zhong, Yunzhi Yao, Yuqi Zhu, Lun Du, and Shumin Deng. StructMem: Structured memory for long-horizon behavior in LLMs.CoRR, abs/2604.21748, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
All-Mem: Agentic lifelong memory via dynamic topology evolution.CoRR, abs/2603.19595, 2026
Can Lv, Heng Chang, Yuchen Guo, Shengyu Tao, and Shiji Zhou. All-Mem: Agentic lifelong memory via dynamic topology evolution.CoRR, abs/2603.19595, 2026
-
[14]
AtomMem: Learnable dynamic agentic memory with atomic memory operation.CoRR, abs/2601.08323, 2026
Yupeng Huo, Yaxi Lu, Zhong Zhang, Haotian Chen, and Yankai Lin. AtomMem: Learnable dynamic agentic memory with atomic memory operation.CoRR, abs/2601.08323, 2026
-
[15]
Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Jiaqi Feng, Yaliang Li, and Libing Wu. Agentic memory: Learning unified long-term and short-term memory management for large language model agents.CoRR, abs/2601.01885, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z. Pan, Hinrich Schütze, V olker Tresp, and Yunpu Ma. Memory-R1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.CoRR, abs/2508.19828, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Memory and consciousness.Canadian Psychology / Psychologie canadienne, 26(1):1–12, 1985
Endel Tulving. Memory and consciousness.Canadian Psychology / Psychologie canadienne, 26(1):1–12, 1985
work page 1985
-
[18]
Episodic memory: From mind to brain.Annual Review of Psychology, 53(1):1– 25, 2002
Endel Tulving. Episodic memory: From mind to brain.Annual Review of Psychology, 53(1):1– 25, 2002
work page 2002
-
[19]
Louis Renoult, Patrick S. R. Davidson, Daniela J. Palombo, Morris Moscovitch, and Brian Levine. Personal semantics: At the crossroads of semantic and episodic memory.Trends in Cognitive Sciences, 16(11):550–558, 2012
work page 2012
-
[20]
Felix Hamborg, Corinna Breitinger, and Bela Gipp. Giveme5W1H: A universal system for extracting main events from news articles.CoRR, abs/1909.02766, 2019
-
[21]
Jason Weston, Sumit Chopra, and Antoine Bordes. Memory networks. In3rd International Conference on Learning Representations, ICLR 2015, 2015
work page 2015
-
[22]
Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus. End-to-end memory networks. InAdvances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, NeurIPS 2015, pages 2440–2448, 2015
work page 2015
-
[23]
Retrieval augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. Retrieval augmented language model pre-training. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, volume 119 ofProceedings of Machine Learning Research, pages 3929–3938. PMLR, 2020
work page 2020
-
[24]
Gen- eralization through memorization: Nearest neighbor language models
Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. Gen- eralization through memorization: Nearest neighbor language models. In8th International Conference on Learning Representations, ICLR 2020. OpenReview.net, 2020
work page 2020
-
[25]
Rae, Erich Elsen, and Laurent Sifre
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego de Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Ori...
work page 2022
-
[26]
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. Memory OS of AI agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, pages 25961–25970. Association for Computational Linguistics, 2025
work page 2025
-
[27]
MemOS: A Memory OS for AI System
Zhiyu Li, Chenyang Xi, Chunyu Li, Ding Chen, Boyu Chen, Shichao Song, Simin Niu, Hanyu Wang, Jiawei Yang, Chen Tang, Qingchen Yu, Jihao Zhao, Yezhaohui Wang, Peng Liu, Zehao Lin, Pengyuan Wang, Jiahao Huo, Tianyi Chen, Kai Chen, Kehang Li, Zhen Tao, Huayi Lai, Hao Wu, Bo Tang, Zhengren Wang, Zhaoxin Fan, Ningyu Zhang, Linfeng Zhang, Junchi Yan, Mingchuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Beyond RAG for Agent Memory: Retrieval by Decoupling and Aggregation
Zhanghao Hu, Qinglin Zhu, Di Liang, Hanqi Yan, Yulan He, and Lin Gui. Beyond RAG for agent memory: Retrieval by decoupling and aggregation.CoRR, abs/2602.02007, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Kehao Zhang, Shangtong Gui, Sheng Yang, Wei Chen, and Yang Feng. Learning to remember: End-to-end training of memory agents for long-context reasoning.CoRR, abs/2602.18493, 2026
-
[30]
LLMLingua: Com- pressing prompts for accelerated inference of large language models
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. LLMLingua: Com- pressing prompts for accelerated inference of large language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13358–13376, Singapore, December 2023. Association for ...
work page 2023
-
[31]
Stephen E. Robertson and Hugo Zaragoza. The probabilistic relevance framework: BM25 and beyond.Foundations and Trends in Information Retrieval, 3(4):333–389, 2009
work page 2009
-
[32]
Sentence-BERT: Sentence embeddings using siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Lan- guage Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, pages 3982–3992. Association for Computational Linguistics, 2019
work page 2019
-
[33]
Vladimir Karpukhin, Barlas O˘guz, Sewon Min, Patrick S. H. Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, pages 6769–6781. Association for Computational Linguistics, 2020
work page 2020
-
[34]
Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information...
work page 2020
-
[35]
Enhancing chat language models by scaling high-quality instructional conversations
Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3029–3051, Singapore, Dec...
work page 2023
-
[36]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InThe Tenth International Conference on Learning Representations, ICLR 2022. OpenReview.net, 2022
work page 2022
-
[38]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles, SOSP 2023, pages 611–626. ACM, 2023
work page 2023
-
[39]
MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. InAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, 2020
work page 2020
-
[40]
How many days did I spend on camping trips in the United States this year?
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and chatbot arena. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, ...
work page 2023
-
[41]
Type groupingeliminates the vast majority of pairwise comparisons: only records of the same memory type can conflict
- [42]
-
[43]
A lower embedding threshold( 0.7 vs. the typical 0.85) is safe because it is appliedafterthe keyword filter has already ensured topical relatedness. Without this multi-level design, either the pair goes undetected (threshold too high) or all memory pairs must be checked by the LLM consolidator (no keyword pre-filter). DimMem’s cascaded approach achieves h...
-
[44]
Factual information, identity/background, relationships, current status, tools, models, datasets, and project configurations
-
[45]
Specific experiences, events, actions, behavioral records, stage progress, and future plans
-
[46]
Long-term preferences, habits, interests, values, goals, abilities, interaction style, or writing style
-
[47]
Information that helps understand the user’s future needs or retrieve the user’s background. Do not extract:
-
[48]
Greetings, thanks, simple confirmations, or meaningless small talk
-
[49]
what it is / what exists / what is used / what the relationship is / what the current status is
Temporary formatting requirements, one-off operation instructions, or current-task details without long-term value. ======================== memory_type ======================== dimension.memory_type must be one of: fact, episodic, profile. fact: stable facts, answering "what it is / what exists / what is used / what the relationship is / what the current...
-
[50]
Clearly state who the memory is about and the core fact, event, or profile information
-
[51]
If the source text contains time, location, reason, or purpose, include them in content when possible
-
[52]
Remove ambiguous pronouns so that content does not depend on the original context
-
[53]
Normalize relative time expressions based on the message timestamp, e.g., yesterday→a specific date
-
[54]
Do not add unsupported information, and do not overgeneralize a single event into a long-term profile. ======================== dimension Rules ======================== dimension is used for structured retrieval. Except for memory_type, use "" when there is no clear evidence; use [] for keywords when there are no clear keywords. time: the time when the me...
-
[55]
Process messages in chronological order
-
[56]
Extract memories mainly from user messages
-
[57]
Each memory should be as atomic as possible. If a message is long or contains multiple independent information points, split it into multiple memories, preserving key details such as people, time, location, events, reasons, purposes, preferences, and objects separately. Avoid over-merging or omitting details
-
[58]
The content field must be self-contained and must not rely on the original dialogue context
-
[59]
The time field should be normalized based on the message timestamp: relative time expressions must be converted into absolute dates or time ranges. For example, if the message timestamp is 2023-05-08 and the original text says yesterday, then time should be 2023-05-07
work page 2023
-
[60]
Simple confirmations, temporary formatting requirements, and one-off tasks in the current conversation should generally not be extracted
-
[61]
The output must be valid JSON. Do not output any text outside the JSON. ======================== Input and Overlap Context Rules ======================== You will receive a “current conversation segment”. The first {overlap_count} messages in the input, namely messages numbered 1 to {overlap_count}, are overlapping context from the previous segment and mu...
-
[62]
source_id The message number from which this memory is mainly derived
-
[63]
source_speaker The speaker of the message corresponding to source_id
-
[64]
content The core memory text; it must be self-contained, clear, independently understandable and retrievable, and preserve key details supported by the original text. Rules: - Resolve pronouns and ambiguous references by explicitly naming the people, objects, places, or events. - Preserve important details such as time, location, people, relationships, ob...
-
[65]
dimension.memory_type Must be one of fact, episodic, or profile. - fact: stable facts, identities, relationships, backgrounds, current states, possessions, tools, models, datasets, or configurations. - episodic: specific events, experiences, actions, meetings, purchases, trips, sharing, plans, stage progress, or media such as photos, images, and videos ti...
-
[66]
Rules: - Use the absolute date if one is available
dimension.time The time when the memory is valid, happened, is planned to happen, or repeatedly occurs. Rules: - Use the absolute date if one is available. - Normalize relative time based on the message timestamp. - Use YYYY-MM-DD, YYYY-MM, YYYY, or YYYY-MM-DD/YYYY-MM-DD for date ranges. - Use "" if no time is supported. - The time description in content ...
-
[67]
dimension.location The physical place, online platform, organizational context, home space, workplace, system environment, 21 or activity venue explicitly mentioned or strongly implied by the original text
-
[68]
dimension.reason The reason, motivation, trigger, or background condition explicitly stated in the original text or strongly supported by context
-
[69]
dimension.purpose The goal, intention, or expected result explicitly stated in the original text or strongly supported by context
-
[70]
======================== Extraction Rules ========================
dimension.keywords Short retrieval keywords or noun phrases, such as people, places, activities, objects, events, relationships, photos, goals, preferences, or values. ======================== Extraction Rules ========================
-
[71]
Process all messages in message order
-
[72]
In multi-party conversations, extract from any speaker’s message as long as it contains valuable information
-
[73]
Each memory should express only one core fact, event, plan, or profile feature
-
[74]
If one sentence contains multiple independent pieces of information, split them into multiple memories
-
[75]
Highly overlapping information may be merged, but key details must not be lost
-
[76]
content must be self-contained and must not depend on the original conversation context
-
[77]
Normalize time whenever possible, and keep content consistent with dimension.time
-
[78]
Do not hallucinate fields; use "" for unsupported time, location, reason, or purpose
-
[79]
The final output must be valid JSON only. ======================== What Should Be Extracted ======================== Extract: - Identities, relationships, backgrounds, possessions, current states. - Meetings, activities, purchases, trips, sharing, plans, stage progress. - Preferences, habits, interests, values, long-term goals, long-term sources of suppor...
-
[80]
query_anchor Rewrite the original question into a retrieval-friendly natural language sentence. I/me/my→the user. Preserve the core intent, time, location, quantity, order, and other key information. This is not a keyword list
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.