ClinicalAligner26AM: A Cross-Lingual Aligner for Dataset Translation; Evidences from the MultiClinCorpus Shared Task
Pith reviewed 2026-06-27 18:44 UTC · model grok-4.3
The pith
ClinicalAligner26AM distills fused multi-level signals sharpened by optimal transport into a cross-lingual aligner that projects clinical entities with high accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
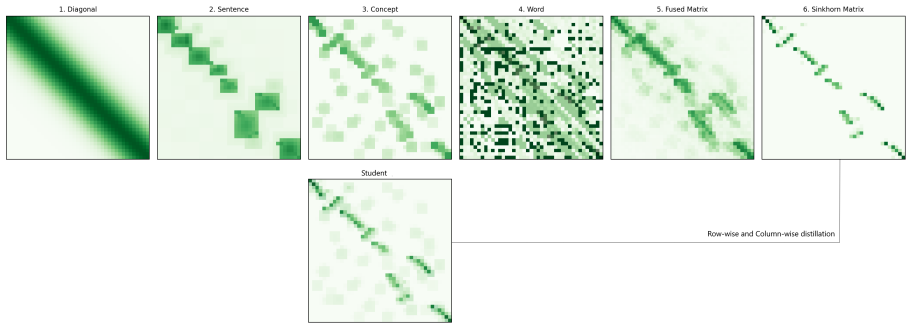
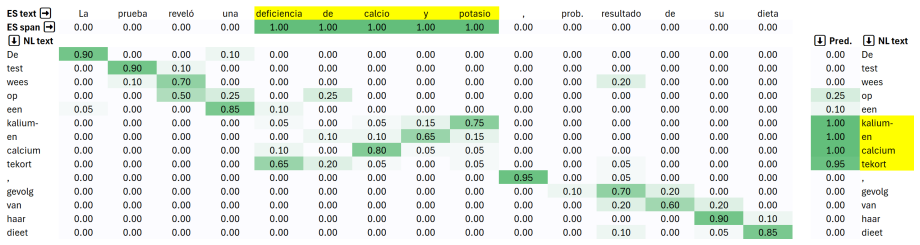
By distilling a sharpened soft alignment target—created from the fusion of sentence, phrase, and token signals in parallel clinical texts via Sinkhorn-Knop optimal transport—into a naive cosine-based student aligner, ClinicalAligner26AM produces token alignments that support accurate cross-lingual projection of clinical entity annotations on the MultiClinCorpus task.
What carries the argument
Fusion of sentence-level, phrase-level, and token-level signals from parallel clinical texts, sharpened with Sinkhorn-Knop optimal transport to form a distillation target matched by the aligner's cosine similarity scores.
If this is right
- Annotation projection for clinical entities becomes feasible across languages without direct labels in the target language.
- The same alignment matrix supports auditing of clinical text translations and estimation of cross-lingual faithfulness.
- Decoding the longest valid high-scoring span after score projection improves entity boundary accuracy in the target text.
- The trained aligner can be paired with existing named-entity recognition predictions to refine span mapping.
Where Pith is reading between the lines
- The same fusion-plus-sharpening recipe could be tested on parallel data from other specialized domains such as legal or technical writing.
- Extending the approach to zero-shot languages outside the shared task would test whether the clinical signals carry over without retraining.
- Replacing the cosine similarity head with a learned scorer after distillation might further tighten the match to the optimal-transport target.
Load-bearing premise
The fusion of sentence-level, phrase-level, and token-level signals from parallel clinical texts produces a reliable soft alignment target that generalizes when sharpened with optimal transport.
What would settle it
If a new collection of parallel clinical texts in the same languages yields character-weighted F1 scores below 0.9 after applying the same projection and decoding procedure, the claim that the distilled alignments generalize would be falsified.
Figures
read the original abstract
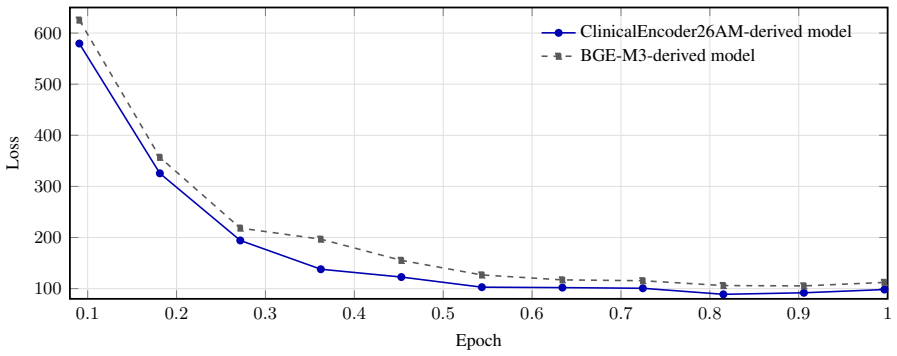
Word-level cross-lingual alignment is central to annotation projection, translation auditing, and cross-lingual faithfulness estimation, yet existing neural aligners are rarely adapted to specialized domains. In this paper, we introduce ClinicalAligner26AM, a large-context multilingual aligner model for biomedical and clinical text initialized from ClinicalEncoder26AM. Our training recipe is inspired by AWESoME Align. We build our soft alignment target by sharpening with Sinkhorn-Knop optimal transport a cost matrix established for parallel clinical texts and conversations through the fusion of sentence-level, phrase-level, and token-level signals. We distill this sharpened alignment matrix directly into our student aligner, by encouraging its naive cosine-based token similarity scores to match this target. At inference time, we project source-span scores through the learned token alignment matrix and decode the longest valid high-scoring span in the target text, optionally supported by MultiClinNER predictions summarized in Appendix B. We evaluate CA26AM on the MultiClinCorpus shared task, which projects Spanish clinical entity annotations into six target languages. Our two submitted systems ranked respectively first and second across all languages and entity types, with character-weighted F1 scores above 0.95 in nearly all settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ClinicalAligner26AM, a large-context multilingual aligner for biomedical and clinical text initialized from ClinicalEncoder26AM. Its training adapts the AWESoME Align recipe: a soft alignment target is built by fusing sentence-, phrase-, and token-level signals from parallel clinical texts, sharpened via Sinkhorn-Knopp optimal transport, and distilled into the student model by matching its cosine token similarities to this target. At inference, source-span scores are projected through the learned alignment matrix and decoded to the longest valid high-scoring target span (optionally aided by MultiClinNER predictions). Evaluation on the MultiClinCorpus shared task (projecting Spanish clinical entities to six languages) shows the two submitted systems ranking first and second across languages and entity types, with character-weighted F1 above 0.95 in nearly all settings.
Significance. If the reported rankings hold, the work demonstrates that domain-specific adaptation of alignment via multi-granularity signal fusion and OT-based distillation can yield highly accurate cross-lingual clinical entity projection. The external shared-task evaluation provides a strong, reproducible benchmark for annotation projection and dataset translation in specialized domains. Strengths include the explicit use of an independently constructed OT target and the focus on clinical text, where existing aligners are rarely tuned.
minor comments (2)
- [Abstract] Abstract: The inference decoding step ('project source-span scores through the learned token alignment matrix and decode the longest valid high-scoring span') is described at a high level; adding a short pseudocode or formal definition of the span selection procedure would improve reproducibility.
- [Abstract] Abstract: The optional use of MultiClinNER predictions (referenced to Appendix B) is mentioned without discussion of its contribution to the reported F1 scores or whether it was used in the submitted systems; clarifying this in the main text would strengthen the central performance claim.
Simulated Author's Rebuttal
We thank the referee for the detailed summary of our manuscript and the positive assessment of ClinicalAligner26AM's performance on the MultiClinCorpus shared task. The recommendation for minor revision is noted. No specific major comments were listed in the report, so we have no points to address point-by-point. We remain available to incorporate any additional feedback or minor clarifications as needed.
Circularity Check
No significant circularity
full rationale
The paper's central claim is an empirical ranking (1st/2nd place) on the external MultiClinCorpus shared task, obtained by constructing an alignment target matrix from parallel clinical data via signal fusion plus Sinkhorn-Knopp sharpening, then distilling cosine similarities to that target. No equation or step reduces the reported F1 scores to a fitted parameter renamed as a prediction, nor does any load-bearing premise collapse to a self-citation, self-definition, or imported uniqueness theorem. The derivation chain is self-contained against the shared-task benchmark and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
2021 , month = jun, publisher =
Ethics and Governance of Artificial Intelligence for Health:. 2021 , month = jun, publisher =
2021
-
[9]
2017 , month = may, howpublished =
Regulation (. 2017 , month = may, howpublished =
2017
-
[10]
Lipton , title =
Michael Oberst and Davis Liang and Zachary C. Lipton , title =. 2024 , month = sep, publisher =
2024
-
[11]
Proceedings of the 43rd International
Omar Khattab and Matei Zaharia , title =. Proceedings of the 43rd International. 2020 , doi =
2020
-
[12]
Introducing Neural Bag of Whole-Words with
Sebastian Hofst. Introducing Neural Bag of Whole-Words with. Proceedings of the 31st. 2022 , doi =
2022
-
[13]
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages =
Keshav Santhanam and Omar Khattab and Jon Saad-Falcon and Christopher Potts and Matei Zaharia , title =. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages =. 2022 , doi =
2022
-
[14]
arXiv preprint arXiv:2205.09707 , year =
Keshav Santhanam and Omar Khattab and Christopher Potts and Matei Zaharia , title =. arXiv preprint arXiv:2205.09707 , year =
-
[15]
arXiv preprint arXiv:2405.19504 , year =
Laxman Dhulipala and Majid Hadian and Rajesh Jayaram and Jason Lee and Vahab Mirrokni , title =. arXiv preprint arXiv:2405.19504 , year =
-
[16]
arXiv preprint arXiv:2109.10086 , year =
Thibault Formal and Carlos Lassance and Benjamin Piwowarski and St. arXiv preprint arXiv:2109.10086 , year =
-
[17]
arXiv preprint arXiv:2402.03216 , year =
Jianlv Chen and Shitao Xiao and Peitian Zhang and Kun Luo and Defu Lian and Zheng Liu , title =. arXiv preprint arXiv:2402.03216 , year =
-
[18]
Dowling and Tyler Thornblade and Wendy W
Hendrik Harkema and John N. Dowling and Tyler Thornblade and Wendy W. Chapman , title =. Journal of Biomedical Informatics , volume =. 2009 , doi =
2009
-
[19]
Lee and Francis Y
Dennis H. Lee and Francis Y. Lau and Hue Quan , title =. BMC Medical Informatics and Decision Making , volume =. 2010 , doi =
2010
-
[20]
Language Resources and Evaluation , volume =
Yanshan Wang and Naveed Afzal and Sunyang Fu and Liwei Wang and Feichen Shen and Majid Rastegar-Mojarad and Hongfang Liu , title =. Language Resources and Evaluation , volume =. 2020 , doi =
2020
-
[21]
arXiv preprint arXiv:2209.10652 , year =
Nelson Elhage and Tristan Hume and Catherine Olsson and Nicholas Schiefer and Tom Henighan and Shauna Kravec and Zac Hatfield-Dodds and Robert Lasenby and Dawn Drain and Carol Chen and Roger Grosse and Sam McCandlish and Jared Kaplan and Dario Amodei and Martin Wattenberg and Christopher Olah , title =. arXiv preprint arXiv:2209.10652 , year =
-
[22]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =
Seongwan Park and Taeklim Kim and Youngjoong Ko , title =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =. 2025 , month = nov, doi =
2025
-
[23]
Hao Kang and Tevin Wang and Chenyan Xiong , title =. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages =. 2025 , month = apr, doi =
2025
-
[24]
Journal of the American Medical Informatics Association , volume =
Fran. Journal of the American Medical Informatics Association , volume =. 2024 , doi =
2024
-
[25]
Proceedings of the ECML-PKDD 2021 Workshop on Fair, Effective and Sustainable Talent Management using Data Science , year =
Jens-Joris Decorte and Jeroen Van Hautte and Thomas Demeester and Chris Develder , title =. Proceedings of the ECML-PKDD 2021 Workshop on Fair, Effective and Sustainable Talent Management using Data Science , year =
2021
-
[26]
IEEE Access , volume =
Jens-Joris Decorte and Jeroen Van Hautte and Chris Develder and Thomas Demeester , title =. IEEE Access , volume =. 2025 , doi =
2025
-
[27]
Neural Vector Conceptualization for Word Vector Space Interpretation , author =. Proceedings of the 3rd Workshop on Evaluating Vector Space Representations for NLP , month = jun, year =. doi:10.18653/v1/W19-2001 , pages =
-
[28]
2026 , eprint =
Ihor Stepanov and Mykhailo Shtopko and Dmytro Vodianytskyi and Oleksandr Lukashov , title =. 2026 , eprint =
2026
-
[29]
Campbell and James R
Walter S. Campbell and James R. Campbell and William W. West and James C. McClay and Steven H. Hinrichs , title =. Journal of the American Medical Informatics Association , volume =. 2014 , doi =
2014
-
[30]
Morris and Volodymyr Kuleshov and Vitaly Shmatikov and Alexander M
John X. Morris and Volodymyr Kuleshov and Vitaly Shmatikov and Alexander M. Rush , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =. 2023 , doi =
2023
-
[31]
arXiv preprint arXiv:2602.11047 , year =
Han Xiao , title =. arXiv preprint arXiv:2602.11047 , year =. doi:10.48550/arXiv.2602.11047 , url =
-
[32]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =
Robustness Tests for Automatic Machine Translation Metrics with Adversarial Attacks , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =. 2023 , doi =
2023
-
[33]
2025 , doi =
Kang, Junmo and Ro, Yunhyeok and Heo, Junsie and Seo, Minjoon , booktitle =. 2025 , doi =
2025
-
[34]
Lima López, Salvador and Rosell, Judith and Rodríguez Miret, Jan and Gallego-Donoso, Fernando and Krallinger, Martin , title =. 2026 , publisher =. doi:10.5281/zenodo.18508039 , url =
-
[35]
2026 , eprint=
Fran. 2026 , eprint=
2026
-
[36]
M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation , author =. Findings of the Association for Computational Linguistics: ACL 2024 , month = aug, year =. doi:10.18653/v1/2024.findings-acl.137 , pages =
-
[37]
Proceedings of the 2019 Conference on Automated Knowledge Base Construction (AKBC 2019) , address =
MedMentions: A Large Biomedical Corpus Annotated with UMLS Concepts , author =. Proceedings of the 2019 Conference on Automated Knowledge Base Construction (AKBC 2019) , address =. 2019 , note =
2019
-
[38]
Studies in Health Technology and Informatics , volume =
Donnelly, Kevin , title =. Studies in Health Technology and Informatics , volume =. 2006 , pmid =
2006
-
[39]
Nucleic Acids Research , volume =
Bodenreider, Olivier , title =. Nucleic Acids Research , volume =. 2004 , doi =
2004
-
[40]
Overview of the 11th Social Media Mining for Health (\#SMM4H) and Health Real-World Data (HeaRD) Shared Tasks at ACL 2026
Lopez-Garcia, Guillermo and Acitores Cortina, Jose Miguel and Berkowitz, Jacob and Chan, Joey and Chandrasekar, Ganesh and Dey, Sumon Kanti and Flores Amaro, Ivan and Gallego, Fernando and Gryboski, Lauren and Klein, Ari Z and Krallinger, Martin and Lima-López, Salvador and Nishiyama, Tomohiro and Raithel, Lisa and Rezaie Mianroodi, Ahmad and Roller, Rola...
2026
-
[41]
The MultiClinAI Shared Task on Multilingual Clinical Corpus Construction and Concept Extraction: Systems, Evaluation, and Datasets
Gallego-Donoso, Fernando and Lima-López, Salvador and Rosell, Judith and Farré-Maduell, Eulàlia and Krallinger, Martin. The MultiClinAI Shared Task on Multilingual Clinical Corpus Construction and Concept Extraction: Systems, Evaluation, and Datasets. Proceedings of the 11th Social Media Mining for Health (\#SMM4H) and Health Real-World Data (HeaRD) Works...
-
[42]
Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzm \'a n, Francisco and Grave, Edouard and Ott, Myle and Zettlemoyer, Luke and Stoyanov, Veselin. Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. ...
- [43]
-
[44]
Word Alignment by Fine-tuning Embeddings on Parallel Corpora
Dou, Zi-Yi and Neubig, Graham. Word Alignment by Fine-tuning Embeddings on Parallel Corpora. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.181
-
[45]
Improving Pretrained Cross-Lingual Language Models via Self-Labeled Word Alignment
Chi, Zewen and Huang, Li and Liu, Liyuan and Bai, Xuan and Huang, Heyan and Collier, Nigel. Improving Pretrained Cross-Lingual Language Models via Self-Labeled Word Alignment. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Pa...
-
[46]
SpanAlign: Projecting Spans Across Languages by Aligning Subwords
Jacqmin, L \'e o and Doucet, Antoine and Morin, Emmanuel and Martin, Louis. SpanAlign: Projecting Spans Across Languages by Aligning Subwords. Proceedings of the Seventh Workshop on Noisy User-generated Text. 2021. doi:10.18653/v1/2021.wnut-1.27
-
[47]
Fraile Navarro, David and Guti \'e rrez, Pablo A. and others. Clinical named entity recognition and relation extraction using natural language processing of medical free text: A systematic review. International Journal of Medical Informatics. 2023. doi:10.1016/j.ijmedinf.2023.105182
-
[48]
Discontinuous named entities in clinical text: A systematic literature review
Alhassan, Abdulhalim and others. Discontinuous named entities in clinical text: A systematic literature review. JAMIA Open. 2025. doi:10.1093/jamiaopen/ooaf157
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.