moBERTo: A Modern Encoder for Portuguese via Continued Pretraining of ModernBERT
Pith reviewed 2026-06-26 10:05 UTC · model grok-4.3
The pith
Continued pretraining of ModernBERT on a large Portuguese corpus creates an encoder that leads on retrieval and NLU benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
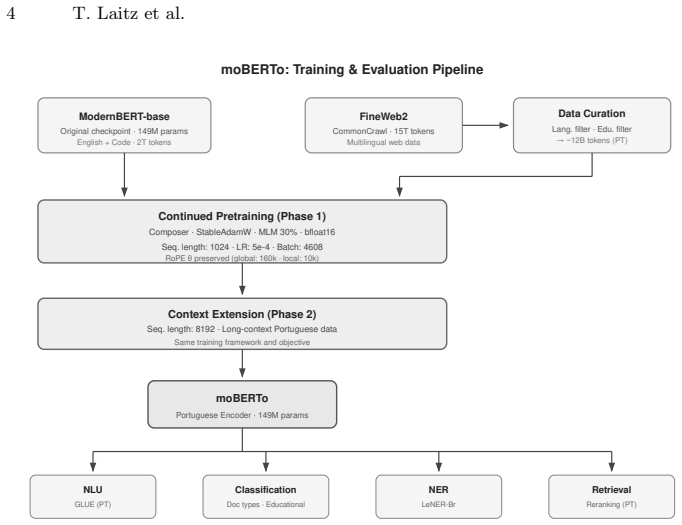
moBERTo is obtained by continued pretraining of ModernBERT-base on 60 billion tokens drawn from a 12-billion-token Portuguese corpus filtered from FineWeb2 using educational and STEM classifiers. The strongest variant applies a Portuguese tokenizer with subword-matching embedding transfer plus a long-context post-training stage at 8192 tokens, delivering the highest average reranking nDCG@10 across three Portuguese retrieval benchmarks and the best scores on PLUE-PT. Ablations establish that continued pretraining outperforms from-scratch training for long-context retention, that tokenizer adaptation aids token-level tasks while sometimes harming retrieval, and that the extra long-context pha
What carries the argument
Continued pretraining of the ModernBERT checkpoint on a filtered Portuguese corpus, optionally combined with tokenizer adaptation and a dedicated long-context post-training phase.
If this is right
- Continued pretraining preserves long-context capabilities more effectively than training from scratch.
- Tokenizer adaptation improves results on token-level tasks such as NER while sometimes lowering long-context retrieval performance.
- A separate long-context post-training phase at 8192 tokens further raises reranking and NER scores.
- Encoder-only models remain competitive with larger decoder-only models on discriminative tasks.
Where Pith is reading between the lines
- The same continued-pretraining recipe could produce usable encoders for additional languages that possess comparable filtered web corpora.
- Modern encoder architectures may transfer across languages more efficiently through targeted adaptation than through full retraining from random initialization.
- Production systems needing both retrieval and classification in non-English settings could adopt this style of adaptation to reduce compute costs.
Load-bearing premise
The 12-billion-token Portuguese corpus is representative of real usage and the evaluation benchmarks measure practical performance without hidden biases or leakage.
What would settle it
A model trained from scratch on the identical corpus achieving equal or higher nDCG@10 on the three retrieval sets and higher PLUE-PT scores would undermine the claimed advantage of continued pretraining.
Figures
read the original abstract
Encoder-only transformer models remain essential for production NLP pipelines. We introduce moBERTo, a Portuguese adaptation of ModernBERT obtained through continued pretraining of the ModernBERT-base checkpoint on 60 billion tokens (5 epochs over a 12-billion-token corpus curated from FineWeb2 and filtered with educational and STEM classifiers). We preserve the original architecture, including rotary positional embeddings, alternating local-global attention, flash attention, and unpadding. We evaluate moBERTo across information retrieval (including long-context retrieval at up to 8,192 tokens), document classification, named entity recognition, and natural language understanding. Our best variant, which combines a Portuguese tokenizer with subword-matching embedding transfer and long-context post-training, achieves the highest average reranking nDCG@10 across three Portuguese retrieval benchmarks and the best results on PLUE-PT. Through ablation studies, we show that (i) continued pretraining is strongly preferable to training from scratch, particularly for preserving long-context capabilities; (ii) tokenizer adaptation improves token-level tasks but degrades long-context retrieval; (iii) a dedicated long-context post-training phase at 8,192 tokens further improves reranking and NER; and (iv) encoder-only architectures remain competitive with larger decoder-only alternatives for discriminative tasks. We publicly release the model weights at https://huggingface.co/Tropic-AI/moBERTo and training data at https://huggingface.co/datasets/Tropic-AI/moberto-pretraining-dataset-c4-compatible on Hugging Face.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces moBERTo, a Portuguese adaptation of ModernBERT-base obtained via continued pretraining on a 12-billion-token corpus curated from FineWeb2 and filtered using educational and STEM classifiers (5 epochs over 60 billion tokens total). The architecture is preserved, including rotary embeddings, alternating local-global attention, and flash attention. The best variant combines a Portuguese tokenizer, subword-matching embedding transfer, and long-context post-training at 8192 tokens. It reports the highest average reranking nDCG@10 on three Portuguese retrieval benchmarks plus best PLUE-PT results, with ablations showing continued pretraining outperforms from-scratch training, tokenizer effects on tasks, and benefits of long-context post-training. Model weights and the pretraining dataset are released publicly.
Significance. If the empirical claims hold after addressing data-quality details, the work provides a competitive open encoder for Portuguese NLP pipelines, demonstrates practical benefits of continued pretraining for preserving long-context capabilities, and supplies reusable resources (model and 12B-token dataset). The ablations on tokenizer adaptation and long-context phases offer transferable insights for language-specific adaptation of modern encoders. The release of both weights and data strengthens reproducibility.
major comments (3)
- [Data curation / corpus filtering] Data curation section: the manuscript provides no quantitative overlap statistics between the filtered 12B-token corpus and the three Portuguese retrieval test sets, nor any decontamination protocol. This is load-bearing for the central claim of highest nDCG@10, as leakage could artifactually inflate the reported gains.
- [Corpus construction] Corpus filtering description: no details are given on the training data, architecture, or decision thresholds of the educational and STEM classifiers used to filter FineWeb2. Without these, it is impossible to assess whether the corpus is representative or whether filtering introduces unintended biases that affect downstream retrieval and PLUE-PT results.
- [Ablation studies] Evaluation and ablation sections: the abstract and results claim continued pretraining is "strongly preferable" to from-scratch training, yet no hyperparameter budgets, data schedules, or statistical significance tests (with error bars) are reported for the from-scratch baseline, undermining the ablation's ability to support the headline performance claims.
minor comments (2)
- [Abstract] The abstract states "60 billion tokens (5 epochs over a 12-billion-token corpus)"; clarify whether the 60B figure refers to total tokens seen or a different quantity, and ensure this is consistent in the methods section.
- [Results tables] Table or figure reporting nDCG@10 averages should include per-benchmark breakdowns and variance estimates to allow readers to judge whether the "highest average" is driven by one outlier benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions that will be incorporated to improve transparency and reproducibility.
read point-by-point responses
-
Referee: [Data curation / corpus filtering] Data curation section: the manuscript provides no quantitative overlap statistics between the filtered 12B-token corpus and the three Portuguese retrieval test sets, nor any decontamination protocol. This is load-bearing for the central claim of highest nDCG@10, as leakage could artifactually inflate the reported gains.
Authors: We agree this is a substantive concern for validating the retrieval results. The original manuscript omitted explicit overlap statistics and decontamination details. Since the full pretraining corpus is publicly released, we will add a new subsection reporting quantitative overlap percentages with each of the three Portuguese retrieval test sets along with the decontamination protocol used during curation. revision: yes
-
Referee: [Corpus construction] Corpus filtering description: no details are given on the training data, architecture, or decision thresholds of the educational and STEM classifiers used to filter FineWeb2. Without these, it is impossible to assess whether the corpus is representative or whether filtering introduces unintended biases that affect downstream retrieval and PLUE-PT results.
Authors: We acknowledge that the manuscript lacks sufficient detail on the classifiers. In the revised version we will expand the corpus construction section to specify the training data, model architectures, and exact decision thresholds employed for both the educational and STEM classifiers applied to FineWeb2. revision: yes
-
Referee: [Ablation studies] Evaluation and ablation sections: the abstract and results claim continued pretraining is "strongly preferable" to from-scratch training, yet no hyperparameter budgets, data schedules, or statistical significance tests (with error bars) are reported for the from-scratch baseline, undermining the ablation's ability to support the headline performance claims.
Authors: The from-scratch baseline was trained under a matched token budget and similar hyperparameter schedule to the continued-pretraining runs, but these details and statistical tests were not reported. We will revise the ablation section to include the hyperparameter budgets, data schedules, error bars, and significance tests comparing the from-scratch and continued-pretraining models. revision: yes
Circularity Check
No significant circularity; empirical results only
full rationale
The paper reports continued pretraining of ModernBERT on a curated Portuguese corpus followed by direct empirical evaluation on retrieval (nDCG@10), PLUE-PT, classification, NER, and NLU benchmarks. Ablations compare tokenizer variants, long-context post-training, and from-scratch training via measured performance differences. No equations, first-principles derivations, or fitted-parameter predictions appear in the provided text. Central claims rest on benchmark scores rather than any self-definitional reduction, self-citation chain, or ansatz smuggled via prior work. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.08824 (2025)
Almeida, T.S., Nogueira, R., Pedrini, H.: Building high-quality datasets for por- tuguese llms: From common crawl snapshots to industrial-grade corpora. arXiv preprint arXiv:2509.08824 (2025)
arXiv 2025
-
[2]
arXiv preprint arXiv:2512.12770 (2025)
Almeida, T.S., Nogueira, R., Pedrini, H.: Curi\’o-edu 7b: Examining data selection impacts in llm continued pretraining. arXiv preprint arXiv:2512.12770 (2025)
arXiv 2025
-
[3]
arXiv preprint arXiv:2411.08868 (2024)
Antoun, W., Kulumba, F., Touchent, R., de la Clergerie, É., Sagot, B., Seddah, D.: Camembert 2.0: A smarter french language model aged to perfection. arXiv preprint arXiv:2411.08868 (2024)
arXiv 2024
-
[4]
Boizard, N., Gisserot-Boukhlef, H., Alves, D.M., Martins, A., Hammal, A., Corro, C., Hudelot, C., Malherbe, E., Malaboeuf, E., Jourdan, F., Hautreux, G., Alves, J., El-Haddad, K., Faysse, M., Peyrard, M., Guerreiro, N.M., Fernandes, P., Rei, R., Colombo, P.: EuroBERT: Scaling multilingual encoders for european languages (2025)
2025
-
[5]
Bonifacio, L., Jeronymo, V., Abonizio, H.Q., Campiotti, I., Fadaee, M., Lotufo, R., Nogueira, R.: mmarco: A multilingual version of the ms marco passage ranking dataset (2022),https://arxiv.org/abs/2108.13897 Title Suppressed Due to Excessive Length 13
arXiv 2022
-
[6]
arXiv preprint arXiv:2502.19587 (2025)
Breton, L.L., Fournier, Q., Mezouar, M.E., Morris, J.X., Chandar, S.: Neobert: A next-generation bert. arXiv preprint arXiv:2502.19587 (2025)
arXiv 2025
-
[7]
Bueno, M., de Oliveira, E.S., Nogueira, R., Lotufo, R.A., Pereira, J.A.: Quati: A brazilian portuguese information retrieval dataset from native speakers (2024), https://arxiv.org/abs/2404.06976
arXiv 2024
-
[8]
Cesconetto, L.: NeoBERTugues: A portuguese ModernBERT model.https:// huggingface.co/lorenzocc/NeoBERTugues(2026)
2026
-
[9]
Chen, J., Xiao, S., Zhang, P., Luo, K., Lian, D., Liu, Z.: Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self- knowledge distillation (2024)
2024
-
[10]
In: Proceedings of the 58th annual meeting of the association for computational linguistics
Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., Guzmán, F., Grave, E., Ott, M., Zettlemoyer, L., Stoyanov, V.: Unsupervised cross-lingual representation learning at scale. In: Proceedings of the 58th annual meeting of the association for computational linguistics. pp. 8440–8451 (2020)
2020
-
[11]
In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidi- rectional transformers for language understanding. In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). pp. 4171–4186 (2019)
2019
-
[12]
In: Proceedings of the 16th International Conference on Computational Processing of Portuguese-Vol
Garcia, E., Silva, N., Siqueira, F., Gomes, J., Albuquerque, H.O., Souza, E., Lima, E., de Carvalho, A.: Robertalexpt: A legal roberta model pretrained with dedu- plication for portuguese. In: Proceedings of the 16th International Conference on Computational Processing of Portuguese-Vol. 1. pp. 374–383 (2024)
2024
-
[13]
GOMES, J.R.S.: Plue: Portuguese language understanding evaluation.https:// github.com/ju-resplande/PLUE(2020)
2020
-
[14]
arXiv preprint arXiv:2111.09543 (2021)
He, P., Gao, J., Chen, W.: Debertav3: Improving deberta using electra- style pre-training with gradient-disentangled embedding sharing. arXiv preprint arXiv:2111.09543 (2021)
Pith/arXiv arXiv 2021
-
[15]
Jeronymo,V.,Nascimento,M.,Lotufo,R.,Nogueira,R.:mrobust04:Amultilingual version of the trec robust 2004 benchmark (2022),https://arxiv.org/abs/2209. 13738
2004
-
[16]
Le Breton, L., Fournier, Q., El Mezouar, M., Morris, J.X., Chandar, S.: Neobert: A next-generation BERT (2025)
2025
-
[17]
arXiv preprint arXiv:1907.11692 (2019)
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V.: Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019)
Pith/arXiv arXiv 1907
-
[18]
In: International Conference on the Computational Processing of Por- tuguese (PROPOR)
Luz de Araujo, P.H., de Campos, T.E., de Oliveira, R.R.R., Stauffer, M., Couto, S., Bermejo, P.: LeNER-Br: a dataset for named entity recognition in Brazilian legal text. In: International Conference on the Computational Processing of Por- tuguese (PROPOR). pp. 313–323. Lecture Notes on Computer Science (LNCS), Springer, Canela, RS, Brazil (September 24-2...
2018
-
[19]
Marone, M., Weller, O., Fleshman, W., Yang, E., Lawrie, D., Van Durme, B.: mmbert: A modern multilingual encoder with annealed language learning (2025)
2025
-
[20]
In: Proceedings of the 58th annual meeting of the association for computational linguistics
Martin, L., Muller, B., Suarez, P.O., Dupont, Y., Romary, L., de La Clergerie, É.V., Seddah, D., Sagot, B.: Camembert: a tasty french language model. In: Proceedings of the 58th annual meeting of the association for computational linguistics. pp. 7203–7219 (2020)
2020
-
[21]
Mazza Zago, R., Agnoletti dos Santos Pedotti, L.: BERTugues: A novel BERT transformer model pre-trained for brazilian portuguese. Semina: Ciências Exatas 14 T. Laitz et al. e Tecnológicas45, e50630 (2024).https://doi.org/10.5433/1679-0375.2024. v45.50630
-
[22]
Muennighoff,N.,Tazi,N.,Magne,L.,Reimers,N.:MTEB:Massivetextembedding benchmark (2022)
2022
-
[23]
Nguyen, D.Q., Nguyen, A.T.: Phobert: Pre-trained language models for viet- namese.In:Findingsoftheassociationforcomputationallinguistics:EMNLP2020. pp. 1037–1042 (2020)
2020
-
[24]
arXiv preprint arXiv:2506.20920 (2025)
Penedo,G.,Kydlíček,H.,Sabolčec,V.,Messmer,B.,Foroutan,N.,Kargaran,A.H., Raffel, C., Jaggi, M., Von Werra, L., Wolf, T.: Fineweb2: One pipeline to scale them all–adapting pre-training data processing to every language. arXiv preprint arXiv:2506.20920 (2025)
arXiv 2025
-
[25]
In: EPIA Conference on Artificial Intelligence
Rodrigues, J., Gomes, L., Silva, J., Branco, A., Santos, R., Cardoso, H.L., Osório, T.: Advancing neural encoding of portuguese with transformer albertina pt. In: EPIA Conference on Artificial Intelligence. pp. 441–453. Springer (2023)
2023
-
[26]
In: Melero, M., Sakti, S., Soria, C
Santos, R., Rodrigues, J., Gomes, L., Silva, J.R., Branco, A., Lopes Cardoso, H., Osório, T.F., Leite, B.: Fostering the ecosystem of open neural encoders for Portuguese with albertina PT* family. In: Melero, M., Sakti, S., Soria, C. (eds.) Proceedings of the 3rd Annual Meeting of the Special Interest Group on Under- resourced Languages @ LREC-COLING 2024...
2024
-
[27]
In: Proceedings of the Workshop on Beyond English: Natural Language Processing for all Languages in an Era of Large Language Mod- els
Scheible-Schmitt, R., He, H., Mendes, A.B.: Portbert: Navigating the depths of portuguese language models. In: Proceedings of the Workshop on Beyond English: Natural Language Processing for all Languages in an Era of Large Language Mod- els. pp. 59–71 (2025)
2025
-
[28]
In: Proceedings of the 3rd clinical natural language processing workshop
Schneider, E.T.R., de Souza, J.V.A., Knafou, J., e Oliveira, L.E.S., Copara, J., Gumiel, Y.B., de Oliveira, L.F.A., Paraiso, E.C., Teodoro, D., Barra, C.M.C.M.: Biobertpt-a portuguese neural language model for clinical named entity recogni- tion. In: Proceedings of the 3rd clinical natural language processing workshop. pp. 65–72 (2020)
2020
-
[29]
In: Brazilian Confer- ence on Intelligent Systems
Silva, M.O., Oliveira, G.P., Costa, L.G., Pappa, G.L.: Govbert-br: A bert-based language model for brazilian portuguese governmental data. In: Brazilian Confer- ence on Intelligent Systems. pp. 19–32. Springer (2024)
2024
-
[30]
In: Brazilian conference on intelligent systems
Souza,F.,Nogueira,R.,Lotufo,R.:Bertimbau:pretrainedbertmodelsforbrazilian portuguese. In: Brazilian conference on intelligent systems. pp. 403–417. Springer (2020)
2020
-
[31]
Sugiura, I., Nakayama, K., Oda, Y.: llm-jp-modernbert: A ModernBERT model trained on a large-scale japanese corpus with long context length (2025)
2025
-
[32]
In: Proceedings of the eleventh international conference on language resources and evaluation (LREC 2018) (2018)
Wagner Filho, J.A., Wilkens, R., Idiart, M., Villavicencio, A.: The brwac corpus: A new open resource for brazilian portuguese. In: Proceedings of the eleventh international conference on language resources and evaluation (LREC 2018) (2018)
2018
-
[33]
Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., Bowman, S.R.: Glue: A multi- task benchmark and analysis platform for natural language understanding (2019), https://arxiv.org/abs/1804.07461
Pith/arXiv arXiv 2019
-
[34]
In: Proceedings of the 63rd Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers)
Warner, B., Chaffin, A., Clavié, B., Weller, O., Hallström, O., Taghadouini, S., Gallagher, A., Biswas, R., Ladhak, F., Aarsen, T., et al.: Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference. In: Proceedings of the 63rd Annual Meeting of the As- sociation for Computational ...
2025
-
[35]
Weller, O., Ricci, K., Marone, M., Chaffin, A., Lawrie, D., Van Durme, B.: Seq vs seq: An open suite of paired encoders and decoders (2025) Title Suppressed Due to Excessive Length 15
2025
-
[36]
Wu, W., Garcia, L.: Modbertbr: A modernbert-based model for brazilian por- tuguese. In: Anais do XXII Encontro Nacional de Inteligência Artificial e Computa- cional.pp.2044–2055.SBC,PortoAlegre,RS,Brasil(2025).https://doi.org/10. 5753/eniac.2025.14516,https://sol.sbc.org.br/index.php/eniac/article/ view/38875
arXiv 2044
-
[37]
Wunderle, J., Ehrmanntraut, A., Pfister, J., Jannidis, F., Hotho, A.: New en- codersforgermantrainedfromscratch:ComparingModernGBERTwithconverted LLM2Vec models (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.