LangRetrieval: Language-Guided Self-Evolving Satellite-to-Radar Retrieval via CSI-Driven Reward
Pith reviewed 2026-06-27 14:12 UTC · model grok-4.3
The pith
LangRetrieval sets up a feedback loop where evolving meteorological language descriptions refine satellite-to-radar precipitation retrieval through CSI-driven rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LangRetrieval establishes a closed-loop optimization mechanism between meteorological semantics and retrieval accuracy via semantic warm-up in CFM and self-evolving semantic optimization with GRPO using multi-threshold CSI rewards.
What carries the argument
The self-evolving semantic optimization that refines a lightweight attribute policy via GRPO driven by multi-threshold CSI rewards inside the conditional flow matching framework.
If this is right
- Structured meteorological attributes provide continuous guidance across the entire CFM generation trajectory.
- Semantics adapt to dynamic convective scenes instead of relying on static external definitions.
- Retrieval accuracy improves by aligning semantic generation directly with the CSI-based objective.
- The approach supplies precipitation estimates in radar-sparse regions by resolving scene-level ambiguities.
Where Pith is reading between the lines
- The same CSI-driven evolution of language attributes could apply to other generative remote-sensing tasks with ill-posed mappings.
- Real-time satellite streams might allow ongoing policy updates to keep semantics aligned with changing weather regimes.
- The framework suggests a general pattern for using task-specific metrics to steer language conditioning in flow-based models.
Load-bearing premise
The lightweight attribute policy can be refined via GRPO with CSI rewards to evolve semantics toward improved retrieval accuracy without the optimization introducing biases or artifacts that undermine the underlying flow matching generation.
What would settle it
A direct comparison on held-out satellite-radar pairs showing no gain or a drop in retrieval CSI after GRPO semantic evolution compared with the initial vision-language model annotations.
Figures

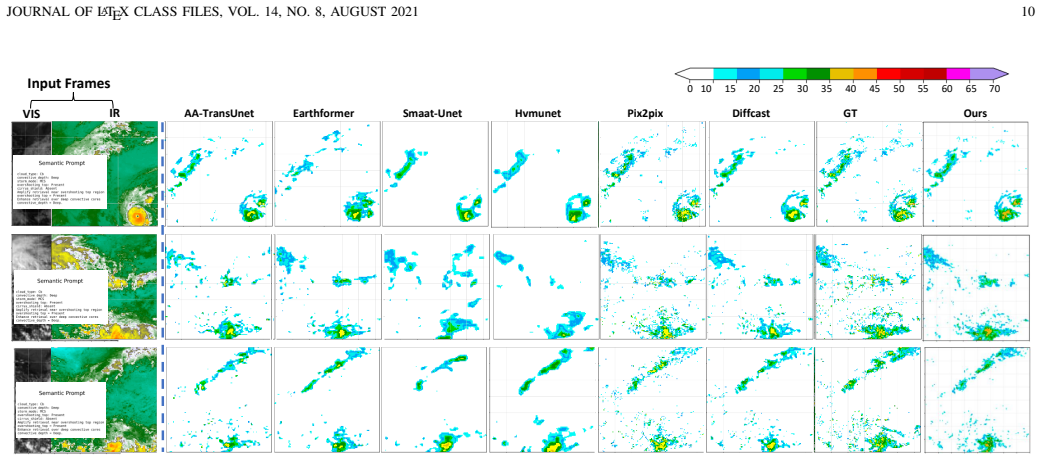
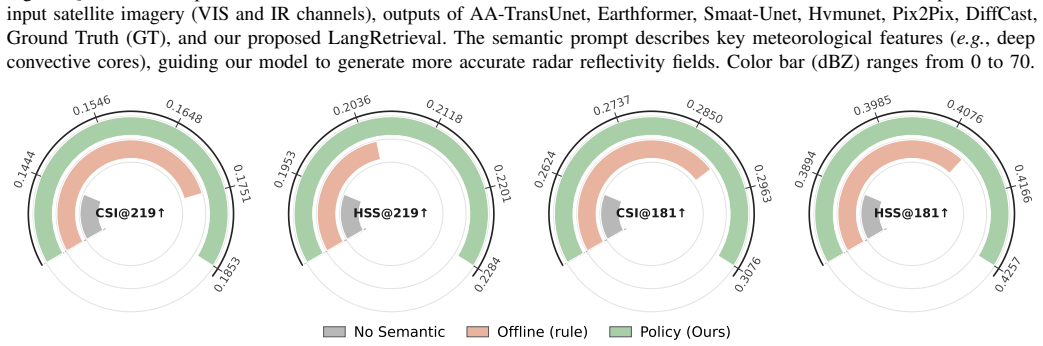
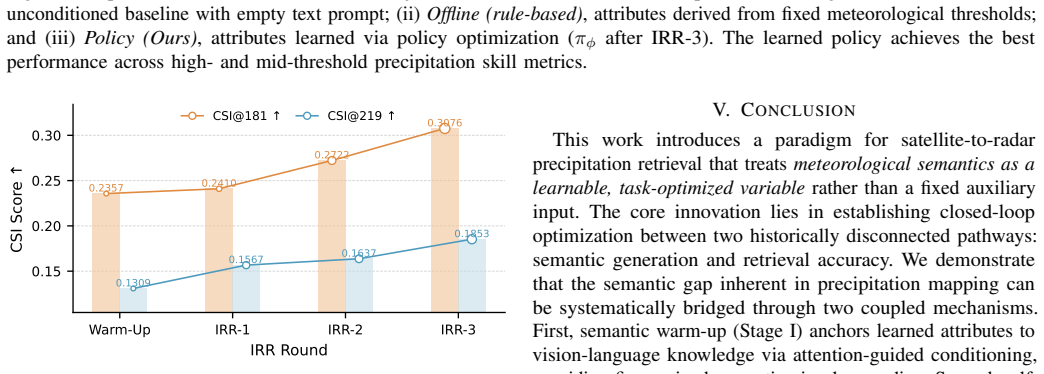
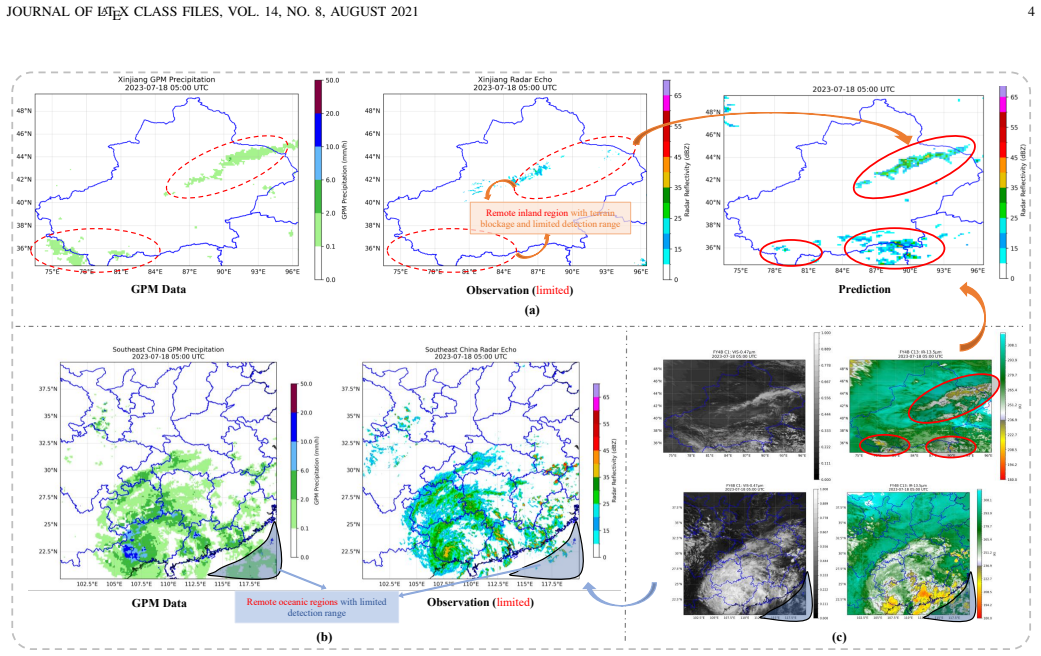
read the original abstract
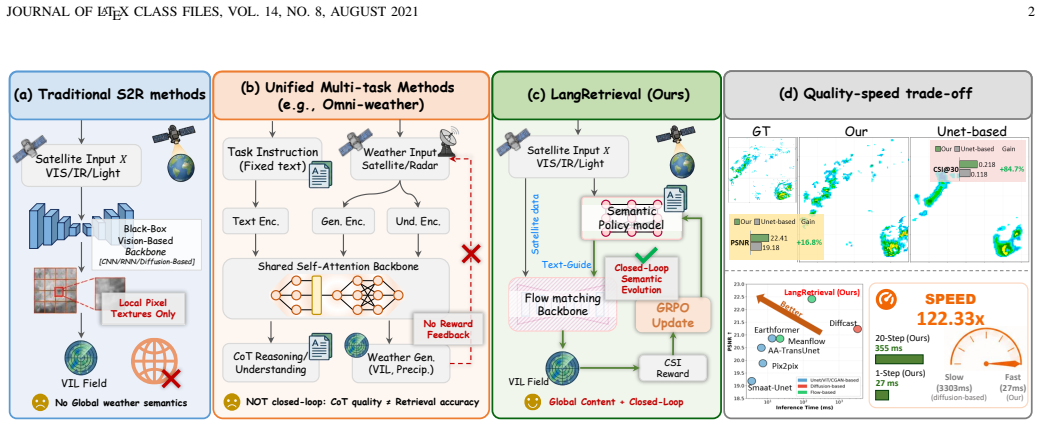
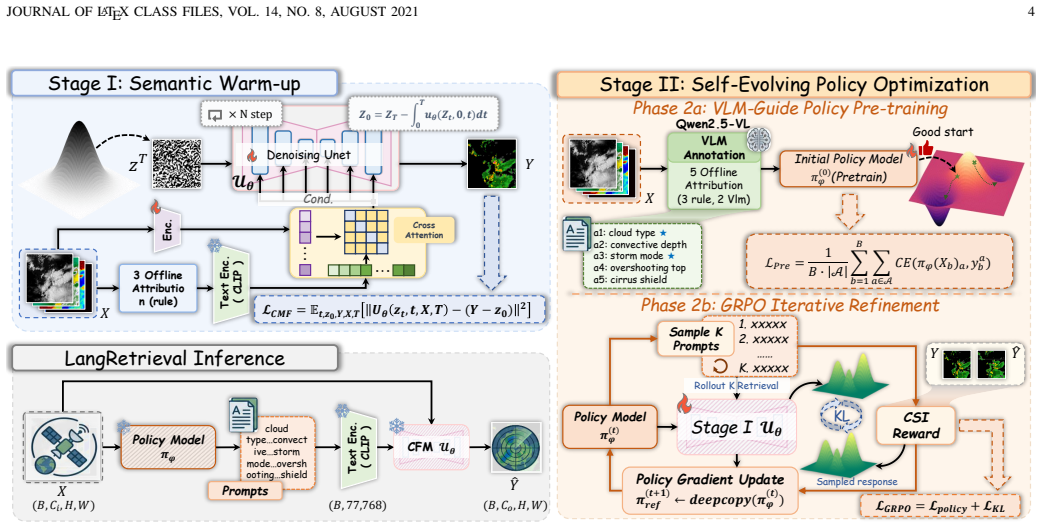
Satellite-to-radar (S2R) retrieval estimates ground radar precipitation from geostationary satellite observations, providing a critical solution for precipitation monitoring in radar-sparse regions. However, S2R retrieval is intrinsically ill-posed: similar cloud-top radiances can correspond to distinct precipitation regimes, storm organizations, and surface intensities, which are difficult to uniquely determine the underlying meteorological state from local spectral cues alone. Meteorological semantics offer complementary scene-level information that can help resolve this ambiguity. Yet existing static semantic conditioning is often insufficient, as externally predefined semantics cannot adapt to dynamic convective scenes or align with retrieval objectives. To this end, we propose LangRetrieval, a language-guided conditional flow matching (CFM) framework that establishes a closed-loop optimization mechanism between meteorological semantics and retrieval accuracy. Specifically, LangRetrieval consists of two core components: (i) Semantic Warm-up: structured meteorological attributes are injected into the CFM backbone through cross-attention conditioning, enabling continuous semantic guidance throughout the generation trajectory; and (ii) Self-Evolving Semantic Optimization: a lightweight attribute policy is first initialized from vision-language model annotations and subsequently refined via Group Relative Policy Optimization (GRPO) using multi-threshold Critical Success Index (CSI) rewards, enabling semantic generation to evolve directly toward improved retrieval accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LangRetrieval, a language-guided conditional flow matching (CFM) framework for satellite-to-radar (S2R) retrieval. It claims to resolve the intrinsic ill-posedness of S2R (similar cloud-top radiances mapping to distinct precipitation regimes) via two components: (i) semantic warm-up that injects structured meteorological attributes into the CFM backbone through cross-attention conditioning for continuous guidance, and (ii) self-evolving semantic optimization in which a lightweight attribute policy, initialized from vision-language model annotations, is refined via Group Relative Policy Optimization (GRPO) using multi-threshold Critical Success Index (CSI) rewards so that semantic generation evolves directly toward improved retrieval accuracy.
Significance. If the closed-loop mechanism is shown to improve CSI-based retrieval accuracy while preserving CFM generation integrity, the work would provide a concrete method for dynamically aligning language-derived meteorological semantics with generative retrieval objectives, offering a potential route to better precipitation estimation in radar-sparse regions.
major comments (3)
- [Abstract] Abstract: the central claim that GRPO-driven evolution of the attribute policy improves retrieval accuracy is unsupported by any experimental results, error analysis, ablation studies, or derivations; the abstract only describes the components without evidence that the optimization resolves ill-posedness or outperforms static semantic conditioning.
- [Abstract] Abstract: the self-evolving optimization directly employs multi-threshold CSI as the reward signal while CSI is also the primary evaluation metric, creating a circularity burden that requires explicit justification or safeguards (e.g., held-out metrics, reward-hacking analysis) to support the claim of genuine improvement rather than optimization to the evaluation quantity.
- [Abstract] Abstract: no mechanism or analysis is supplied to guarantee that the sparse, threshold-dependent CSI rewards will not induce reward hacking, mode collapse in semantic attributes, or distribution shift that breaks cross-attention conditioning in the CFM trajectory—the weakest link in the closed-loop argument.
minor comments (2)
- [Abstract] Abstract: the phrase 'structured meteorological attributes' is introduced without an example or definition of the attribute set, which would help readers assess the semantic warm-up component.
- [Abstract] Abstract: the transition between the two core components (semantic warm-up and self-evolving optimization) is described at a high level; a brief statement of how the refined policy is re-injected into the CFM would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the potential vulnerabilities in the closed-loop optimization. We address each major comment below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that GRPO-driven evolution of the attribute policy improves retrieval accuracy is unsupported by any experimental results, error analysis, ablation studies, or derivations; the abstract only describes the components without evidence that the optimization resolves ill-posedness or outperforms static semantic conditioning.
Authors: We acknowledge that the abstract, in its current form, emphasizes the methodological components without embedding quantitative support. The full manuscript reports experimental results in Sections 4–5, including ablations and comparisons against static semantic conditioning that demonstrate CSI improvements. To resolve the concern directly, we will revise the abstract to include concise statements of key quantitative findings supporting the performance gains from the self-evolving optimization. revision: yes
-
Referee: [Abstract] Abstract: the self-evolving optimization directly employs multi-threshold CSI as the reward signal while CSI is also the primary evaluation metric, creating a circularity burden that requires explicit justification or safeguards (e.g., held-out metrics, reward-hacking analysis) to support the claim of genuine improvement rather than optimization to the evaluation quantity.
Authors: This observation correctly identifies a risk of circularity. The reward is computed on training and validation folds while final evaluation uses a strictly held-out test set; however, we agree that explicit safeguards should be stated. We will revise the manuscript to clarify the data partitioning, report additional held-out metrics (e.g., POD, FAR, and continuous scores), and include a short discussion of why the multi-threshold formulation reduces direct optimization to the reported CSI. revision: yes
-
Referee: [Abstract] Abstract: no mechanism or analysis is supplied to guarantee that the sparse, threshold-dependent CSI rewards will not induce reward hacking, mode collapse in semantic attributes, or distribution shift that breaks cross-attention conditioning in the CFM trajectory—the weakest link in the closed-loop argument.
Authors: We agree that the manuscript currently provides no dedicated analysis or safeguards against reward hacking, mode collapse, or conditioning degradation. We will add a new subsection (likely in Section 3.3 or the experimental analysis) that (i) monitors attribute distribution entropy across GRPO iterations, (ii) reports empirical checks for mode collapse, and (iii) verifies that cross-attention conditioning remains stable by tracking reconstruction fidelity on held-out samples. These additions will be included in the revised version. revision: yes
Circularity Check
CSI reward in GRPO reduces self-evolving accuracy claim to direct metric optimization by construction
specific steps
-
fitted input called prediction
[Abstract]
"a lightweight attribute policy is first initialized from vision-language model annotations and subsequently refined via Group Relative Policy Optimization (GRPO) using multi-threshold Critical Success Index (CSI) rewards, enabling semantic generation to evolve directly toward improved retrieval accuracy."
The optimization objective is defined using CSI (the retrieval accuracy metric) as the reward; therefore the asserted evolution 'toward improved retrieval accuracy' is achieved by construction through direct maximization of the evaluation metric itself rather than derived from an independent mechanism.
full rationale
The paper's central closed-loop claim rests on GRPO refinement of the attribute policy using CSI rewards to evolve semantics toward improved retrieval accuracy. Because CSI is both the reward signal and the stated retrieval accuracy metric, the claimed improvement reduces directly to the reward design rather than an independent derivation. The semantic warm-up component via cross-attention does not exhibit this reduction and appears self-contained. No self-citation chains or other patterns are load-bearing in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alphapre: Amplitude-phase disentanglement model for precipitation nowcasting,
K. Lin, B. Zhang, D. Yu, W. Feng, S. Chen, F. Gao, X. Li, and Y . Ye, “Alphapre: Amplitude-phase disentanglement model for precipitation nowcasting,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 17 841–17 850
2025
-
[2]
Lmcast: A pretrained language model guided long- term memory transformer for precipitation nowcasting,
F. Gao, C. Luo, G. Deng, X. Li, B. Zhang, D. Yu, and Y . Ye, “Lmcast: A pretrained language model guided long- term memory transformer for precipitation nowcasting,” Neural Networks, p. 108168, 2025
2025
-
[3]
Pimmnet: Introducing multi-modal precipitation nowcast- ing via a physics-informed perspective,
D. Yu, W. Du, K. Lin, X. Li, Y . Ye, C. Luo, and X. Chen, “Pimmnet: Introducing multi-modal precipitation nowcast- ing via a physics-informed perspective,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 11 522–11 531
2025
-
[4]
End-to-end data-driven weather prediction,
A. Allen, S. Markou, W. Tebbutt, J. Requeima, W. P. Bruinsma, T. R. Andersson, M. Herzog, N. D. Lane, M. Chantry, J. S. Hoskinget al., “End-to-end data-driven weather prediction,”Nature, vol. 641, no. 8065, pp. 1172– 1179, 2025
2025
-
[5]
M4caster: Multi-source, multi-spatial, multi-temporal modeling for precipitation nowcasting,
D. Niu, C. Shi, T. Zhang, H. Wang, Z. Zang, M. Jiang, and J. Yang, “M4caster: Multi-source, multi-spatial, multi-temporal modeling for precipitation nowcasting,” Neurocomputing, vol. 648, p. 130621, 2025
2025
-
[6]
Synweather: Weather observation data synthesis across multiple regions and variables via a general diffusion transformer,
K. Xu, J. Gong, Z. Zhou, Z. Li, Y . Pu, Y . Liu, B. Fei, F. Ling, W. Zhang, and L. Bai, “Synweather: Weather observation data synthesis across multiple regions and variables via a general diffusion transformer,” inProceed- ings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 2, 2026, pp. 1346–1354
2026
-
[7]
Wavec2r: Wavelet-driven coarse-to-refined hierarchical learning for radar retrieval,
C. Shi, H. Xu, Y . Li, Y .-L. Wei, Y . Feng, Y . Zhang, and D. Niu, “Wavec2r: Wavelet-driven coarse-to-refined hierarchical learning for radar retrieval,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 11, 2026, pp. 8951–8959
2026
-
[8]
Smaat-unet: Precipitation nowcasting using a small attention-unet architecture,
T. Kevin, “Smaat-unet: Precipitation nowcasting using a small attention-unet architecture,”Pattern Recognit. Lett., vol. 145, pp. 178–186, 2021
2021
-
[9]
H-vmunet: High- order vision mamba unet for medical image segmentation,
R. Wu, Y . Liu, P. Liang, and Q. Chang, “H-vmunet: High- order vision mamba unet for medical image segmentation,” Neurocomputing, p. 129447, 2025
2025
-
[10]
Earthformer: Exploring space-time transformers for earth system forecasting,
Z. Gao, X. Shi, H. Wang, Y . Zhu, Y . B. Wang, M. Li, and D.-Y . Yeung, “Earthformer: Exploring space-time transformers for earth system forecasting,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 35, 2022, pp. 25 390–25 403
2022
-
[12]
Diffcast: A unified framework via residual diffusion for precipitation nowcasting,
D. Yu, X. Li, Y . Ye, B. Zhang, C. Luo, K. Dai, R. Wang, and X. Chen, “Diffcast: A unified framework via residual diffusion for precipitation nowcasting,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 27 758–27 767
2024
-
[13]
arXiv:2301.10343 [cs.LG] https:// arxiv.org/abs/2301.10343 Jonathan Prexl and Michael Schmitt
T. Nguyen, J. Brandstetter, A. Kapoor, J. K. Gupta, and A. Grover, “Climax: A foundation model for weather and climate,”arXiv preprint arXiv:2301.10343, 2023
-
[14]
Fengwu: Pushing the skillful global medium-range weather forecast beyond 10 days lead,
K. Chen, T. Han, J. Gong, L. Bai, F. Ling, J.-J. Luo, X. Chen, L. Ma, T. Zhang, R. Suet al., “Fengwu: Pushing the skillful global medium-range weather forecast beyond 10 days lead,”arXiv preprint arXiv:2304.02948, 2023
-
[15]
Weathergfm: Learning a weather generalist foundation model via in- context learning,
X. Zhao, Z. Zhou, W. Zhang, Y . Liu, X. Chen, J. Gong, H. Chen, B. Fei, S. Chen, W. Ouyanget al., “Weathergfm: Learning a weather generalist foundation model via in- context learning,”arXiv preprint arXiv:2411.05420, 2024
-
[16]
Omni-weather: Unified multimodal foundation model for weather genera- tion and understanding,
Z. Zhou, Y . Pu, X. He, Y . Liu, Y . Chen, J. Gong, X. Zhuang, W. Xu, Q. Cao, S. Tanget al., “Omni-weather: Unified multimodal foundation model for weather genera- tion and understanding,”arXiv preprint arXiv:2512.21643, 2025
-
[17]
Rda-unet: A retrieval model for radar composite reflectivity factor from himawari-8 observations,
Z. Jin, H. Lin, and X. Xu, “Rda-unet: A retrieval model for radar composite reflectivity factor from himawari-8 observations,” inProc. IEEE Int. Conf. High Perform. Comput. Commun. (HPCC), 2023, pp. 994–1000
2023
-
[18]
Intelligent reconstruction of radar composite reflectivity based on satellite observations and deep learning,
J. Zhao, J. Tan, S. Chen, Q. Huang, L. Gao, Y . Li, and C. Wei, “Intelligent reconstruction of radar composite reflectivity based on satellite observations and deep learning,”Remote Sens., vol. 16, no. 2, p. 275, 2024
2024
-
[19]
Diffsr: Learning radar reflectivity syn- thesis via diffusion model from satellite observations,
X. He, Z. Zhou, W. Zhang, X. Zhao, H. Chen, S. Chen, and L. Bai, “Diffsr: Learning radar reflectivity syn- thesis via diffusion model from satellite observations,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[20]
Improving and generalizing flow-based generative models with minibatch optimal transport
A. Tong, N. Malkin, G. Huguet, Y . Zhang, J. Rector- Brooks, K. Fatras, G. Wolf, and Y . Bengio, “Conditional flow matching: Simulation-free dynamic optimal trans- port,”arXiv preprint arXiv:2302.00482, vol. 2, no. 3, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Flowcast: Advancing precipitation nowcasting with conditional flow matching,
B. P. Ribeiro and J. F. Pucer, “Flowcast: Advancing precipitation nowcasting with conditional flow matching,” arXiv preprint arXiv:2511.09731, 2025
-
[22]
Artificial intelligence and numerical weather prediction models: A technical survey,
M. Waqas, U. W. Humphries, B. Chueasa, and A. Wang- wongchai, “Artificial intelligence and numerical weather prediction models: A technical survey,”Natural Hazards Research, vol. 5, no. 2, pp. 306–320, 2025
2025
-
[23]
Aquilon: Towards building multimodal weather llms,
S. Varambally, V . V . Manivannan, Y . Jafari, L. Han, Z. Novack, Z. Xia, S. R. Cachay, S. Eranky, R. Niu, T. Berg-Kirkpatricket al., “Aquilon: Towards building multimodal weather llms,” inICML 2025 Workshop on Assessing World Models
2025
-
[24]
Cllmate: A multimodal benchmark for weather and climate events forecasting,
H. Li, Z. Wang, J. Wang, Y . Wang, A. K. H. Lau, and H. Qu, “Cllmate: A multimodal benchmark for weather and climate events forecasting,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 17 547–17 573
2025
-
[25]
A physics-guided multimodal transformer path to weather and climate sciences,
J. Han, H. Chen, K. Han, X. Huang, Y . Hu, W. Xu, D. Tao, and P. Zhang, “A physics-guided multimodal transformer path to weather and climate sciences,”arXiv preprint arXiv:2504.14174, 2025
-
[26]
Deep learning and foundation models for weather prediction: A survey,
J. Shi, A. Shirali, B. Jin, S. Zhou, W. Hu, R. Rangaraj, S. Wang, J. Han, Z. Wang, U. Lallet al., “Deep learning and foundation models for weather prediction: A survey,” arXiv preprint arXiv:2501.06907, 2025
-
[27]
Foundation models in remote sensing: Evolving from unimodality to multimodality,
D. Hong, C. Li, X. Li, G. Camps-Valls, and J. Chanussot, JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12 “Foundation models in remote sensing: Evolving from unimodality to multimodality,”IEEE Geoscience and Remote Sensing Magazine, 2026
2021
-
[28]
Visionâ˘A¸ Slanguage-guided adaptive cross-modal fusion for multispectral object detection under adverse weather conditions,
Y .-Y . Chen, S.-Y . Jhong, H.-C. Lin, and Y .-C. Wu, “Visionâ˘A¸ Slanguage-guided adaptive cross-modal fusion for multispectral object detection under adverse weather conditions,”IEEE MultiMedia, vol. 32, no. 2, pp. 22–32, 2025
2025
-
[29]
Vl-ur: Vision- language-guided universal restoration of images degraded by adverse weather conditions,
Z. Liu, Y . Lu, H. Yu, and D. Yang, “Vl-ur: Vision- language-guided universal restoration of images degraded by adverse weather conditions,” in2025 IEEE Interna- tional Conference on Multimedia and Expo (ICME), 2025, pp. 1–6
2025
-
[30]
Attriprompt: Class attribute-aware prompt tuning for vision-language model,
Y . Su, X. Liu, Z. Huang, Y . Zhao, R. Hong, and M. Wang, “Attriprompt: Class attribute-aware prompt tuning for vision-language model,”IEEE Transactions on Image Processing, vol. 35, pp. 1395–1407, 2026
2026
-
[31]
Multi- stage knowledge integration of vision-language models for continual learning,
H. Zhang, Z. Ji, J. Liu, Y . Pang, and J. Han, “Multi- stage knowledge integration of vision-language models for continual learning,”IEEE Transactions on Image Processing, vol. 35, pp. 615–628, 2026
2026
-
[32]
Iap: Improving continual learning of vision-language models via instance-aware prompting,
H. Fu, H. Zhao, J. Dong, H. Ding, C. Zhang, and H. Qian, “Iap: Improving continual learning of vision-language models via instance-aware prompting,”IEEE Transactions on Image Processing, vol. 35, pp. 717–731, 2026
2026
-
[33]
Foundation model empowered real-time video conference with semantic communications,
M. Chen, W. Ma, M. Zeng, X. He, J. Xiong, L. Wang, A. Al-Dulaimi, and S. Mumtaz, “Foundation model empowered real-time video conference with semantic communications,”IEEE Transactions on Image Process- ing, vol. 35, pp. 1740–1755, 2026
2026
-
[34]
Mtrag: Multi-target referring and grounding via hybrid semantic-spatial integration,
Y . Ren, J. Du, X. Liu, Q. Su, Y . Deng, and H. Li, “Mtrag: Multi-target referring and grounding via hybrid semantic-spatial integration,”IEEE Transactions on Image Processing, vol. 35, pp. 2167–2181, 2026
2026
-
[35]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Y . Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighan et al., “Training a helpful and harmless assistant with reinforcement learning from human feedback,”arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Rlhf fine-tuning of llms for alignment with implicit user feedback in conversational recommenders,
Z. Yang, A. Sun, Y . Zhao, Y . Yang, D. Li, and C. Zhou, “Rlhf fine-tuning of llms for alignment with implicit user feedback in conversational recommenders,” in2025 4th International Conference on Artificial Intelligence, Internet of Things and Cloud Computing Technology (AIoTC), 2025, pp. 587–591
2025
-
[37]
Optimizing rlhf reward models with fairness constraints,
J. Zhao, Y . Lei, W. Zheng, S. Lai, H. Ding, and C. Zhao, “Optimizing rlhf reward models with fairness constraints,” in2025 5th International Conference on Computer Science and Blockchain (CCSB), 2025, pp. 218–221
2025
-
[38]
Reward hacking in reinforce- ment learning and rlhf: A multidisciplinary examination of vulnerabilities, mitigation strategies, and alignment chal- lenges,
T. Hu, W. Zhu, and Y . Yan, “Reward hacking in reinforce- ment learning and rlhf: A multidisciplinary examination of vulnerabilities, mitigation strategies, and alignment chal- lenges,” in2025 5th Intelligent Cybersecurity Conference (ICSC), 2025, pp. 272–275
2025
-
[39]
Using rlhf to align speech enhancement approaches to mean- opinion quality scores,
A. Kumar, A. Perrault, and D. S. Williamson, “Using rlhf to align speech enhancement approaches to mean- opinion quality scores,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[40]
A review of reinforcement learning for semantic communications,
X. Yan, F. Xiumei, K.-L. A. Yau, X. Zhixin, M. Rui, and Y . Gang, “A review of reinforcement learning for semantic communications,”Journal of Network and Systems Management, vol. 33, no. 3, p. 52, 2025
2025
-
[41]
Training-free group relative policy optimization,
Y . Cai, S. Cai, Y . Shi, Z. Xu, L. Chen, Y . Qin, X. Tan, G. Li, Z. Li, H. Linet al., “Training-free group relative policy optimization,”arXiv preprint arXiv:2510.08191, 2025
-
[42]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Biet al., “Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
Perceptually constrained precipitation nowcasting model,
W. Feng, X. Li, Z. Wu, K. Lin, D. Yu, Y . Ye, and Y . Wang, “Perceptually constrained precipitation nowcasting model,” inForty-second International Conference on Machine Learning, 2025
2025
-
[45]
Sevir: A storm event imagery dataset for deep learning applications in radar and satellite meteorology,
M. Veillette, S. Samsi, and C. Mattioli, “Sevir: A storm event imagery dataset for deep learning applications in radar and satellite meteorology,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 33, 2020, pp. 22 009– 22 019
2020
-
[46]
Aa-transunet: Attention augmented transunet for nowcasting tasks,
Yang, “Aa-transunet: Attention augmented transunet for nowcasting tasks,” inProc. Int. Joint Conf. Neural Netw. (IJCNN), 2022, pp. 01–08
2022
-
[47]
S. Akter, “Generative ai: A pix2pix-gan-based machine learning approach for robust and efficient lung segmenta- tion,”arXiv preprint arXiv:2412.10826, 2024
-
[48]
Mean Flows for One-step Generative Modeling
Z. Geng, M. Deng, X. Bai, J. Z. Kolter, and K. He, “Mean flows for one-step generative modeling,”arXiv preprint arXiv:2505.13447, 2025. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 1 APPENDIX This supplementary material is organised as follows. Ap- pendix A formalises the deterministic rules used to compute the three pixel-verifiable attribut...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Stage I: Semantic Warm-Up Training Details:Stage I trains the conditional flow matching retrieval backbone Uθ with semantic cross-attention, using offline rule-based prompts. The three pixel-verifiable attributes (convective depth, overshooting top, cirrus shield) are computed directly from the satellite imagery, while the two VLM-dependent attributes (cl...
-
[50]
It consists of two phases
Stage II: Policy Optimisation Training Details:Stage II trains a lightweight policy network πϕ (AttributePredictor, ∼1.7M parameters) that maps satellite images to five-attribute semantic prompts. It consists of two phases. a) Phase IIa: Supervised Pre-Training.: πϕ is initialised via cross-entropy loss on VLM annotations (Eq. 8 in main text). In the main...
-
[51]
TASRE Framework:Given M VLM annotation sources {s1, . . . , sM}, TASRE assigns fusion weights proportional to each source’s downstream retrieval performance: wm = exp(CSIm/T) ∑M j=1 exp(CSIj/T) ,(16) where CSIm is the mean CSI score achieved when using source sm’s annotations exclusively with the frozen Stage I backbone, and T is a softmax temperature con...
2021
-
[52]
averaging of VLM confidence scores ConfidenceSelf-reported confidence-weighted fusion TASRETask-aligned CSI-weighted fusion (Eq. 16)
-
[53]
All evaluations use the frozen Stage I backbone on the validation set
VLM Source Reliability Evaluation:Table X reports the per-source CSI scores and the resulting TASRE fusion weights under three temperature settings. All evaluations use the frozen Stage I backbone on the validation set. Key observation:All three VLMs achieve nearly identical CSI scores ( 0.242±0.0004), yielding approximately uniform TASRE weights (∼0.333)...
-
[54]
TABLE X: VLM source reliability measured by downstream CSI and corresponding TASRE weights under different tem- peratures
V3 Ablation Training Configuration:To efficiently com- pare fusion strategies, we use a faster configuration for the ablation runs while keeping the Stage I backbone identical. TABLE X: VLM source reliability measured by downstream CSI and corresponding TASRE weights under different tem- peratures. All three VLMs achieve comparable performance (∼0.242 CSI...
-
[55]
This isolates the effect of annotation source / fusion method from temperature
Experimental Design:The V3 ablation consists of two experiment groups: Experiment 1: Fusion Strategy Comparison (Fixed T= 1.0).We train five independent runs, each using a different fusion strategy from Table IX, all with TASRE temperature T=1.0 . This isolates the effect of annotation source / fusion method from temperature. Experiment 2: TASRE Temperatu...
-
[56]
Mean values are computed over thresholds τ∈ {10,20,25,30,35,40}dBZ
Results and Discussion: a) Experiment 1: Fusion Strategy Comparison.:Ta- ble XII reports the retrieval performance of all five fusion strategies under identical GRPO training (with fast ablation settings). Mean values are computed over thresholds τ∈ {10,20,25,30,35,40}dBZ. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 3 TABLE XII: Fusion strat...
2021
-
[57]
The TASRE weights converge to approximately uniform (∼0.333 each), making TASRE indistinguishable from the Uniform strategy
-
[58]
Temperature has negligible effect on the weight distribu- tion, as exp(CSIm/T)≈exp(CSI m′/T) when the CSI scores are tightly clustered
-
[59]
All five fusion strategies produce functionally equivalent pseudo-labels, since the three annotation sources agree to within noise. These results carry important implications: d) Justification for Single-VLM (V2) as the Main Ex- periment.:Since multi-VLM fusion offers no measurable improvement over single-source Qwen annotations, the added complexity of t...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.