Towards Robust Training in NNGPT AutoML Pipeline: A Loss-Optimizer Pairing Selection Study
Pith reviewed 2026-06-26 17:44 UTC · model grok-4.3
The pith
No single loss-optimizer pairing works best across all neural network architectures and datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
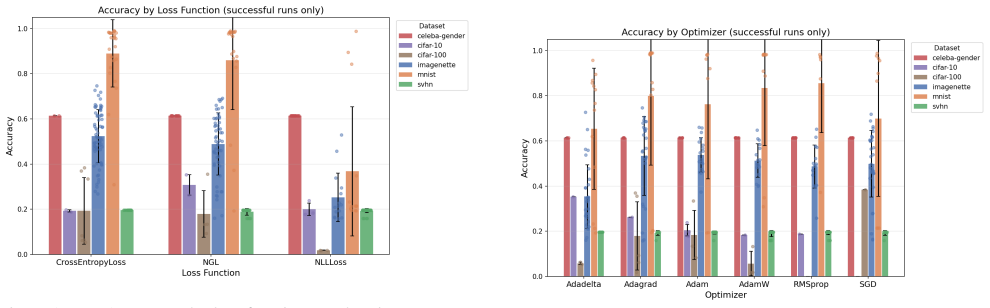
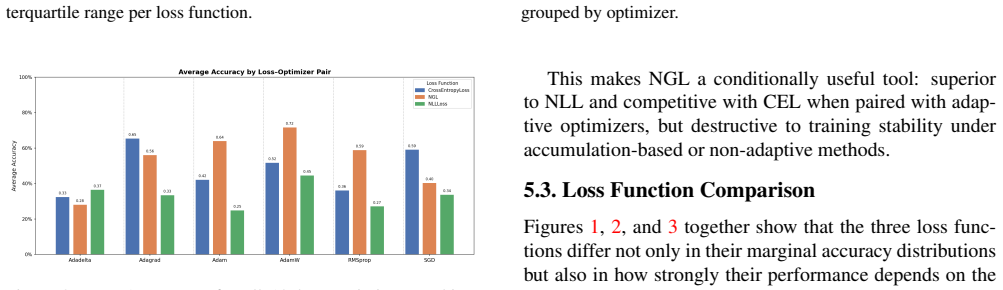
No pairing of loss function and optimizer is universally best. When eighteen pairings are applied to thirty-three architectures under identical hyperparameters, cross-entropy loss combined with Adam or AdamW delivers the most consistent accuracy across architecture families and datasets. The genetically evolved NGL loss performs comparably to cross-entropy on convolutional classifiers but only when paired with adaptive optimizers; it loses ground when used with SGD or accumulation-based methods. Adagrad and Adadelta remain weak regardless of loss under the fixed-hyperparameter regime.
What carries the argument
The exhaustive grid of loss-optimizer pairings applied uniformly to a heterogeneous pool of architectures under fixed hyperparameters.
If this is right
- Automated pipelines can default to cross-entropy with Adam or AdamW for broad robustness without per-architecture retuning.
- NGL loss can substitute for cross-entropy on standard convolutional models when adaptive optimizers are available.
- Adagrad and Adadelta need separate learning-rate tuning to become competitive with other optimizers.
- Architecture search should treat loss-optimizer selection as a variable rather than a fixed recipe.
Where Pith is reading between the lines
- The performance gap between pairings may grow or shrink with network depth or connectivity patterns not tested here.
- Allowing each pairing its own hyperparameter schedule could change which combination ranks highest, suggesting a joint search over loss, optimizer, and schedule.
- The same pairing study on non-image tasks would show whether the robustness of Adam pairings is specific to image classification.
Load-bearing premise
That holding every hyperparameter fixed across pairings isolates the effect of the loss-optimizer choice and produces fair comparisons.
What would settle it
Re-running the 594 trainings with learning-rate and schedule values tuned separately for each pairing and checking whether the ranking of top combinations stays the same.
Figures
read the original abstract
The choice of loss function and optimizer is an important decision, that shapes further model training. Yet automated architecture search pipelines (AutoML) benefits significantly more from the optimal pairing selection and vice versa. This paper investigates whether a single recipe is sufficient for heterogeneous architecture pools, or whether the optimal pairing varies across structurally diverse models. We conduct a systematic empirical study of all $3 \times 6 = 18$ combinations of six optimizers (SGD+Momentum, Adam, AdamW, RMSprop, Adagrad, Adadelta), paired with three loss functions: Cross-Entropy (CEL), Negative Log-Likelihood (NLL), and the recently introduced genetically evolved NGL loss across the base models presented in LEMUR heterogeneous architecture pool on six image classification datasets (CelebA-Gender, CIFAR-10, CIFAR-100, ImageNette, MNIST, SVHN). The 18 loss-optimizer configurations are applied to each of the 33 compatible base architectures taken from the LEMUR pool, resulting in 594 variants that were generated fully automatically by a source-level injection pipeline and evaluated under fixed hyperparameters, ensuring that observed accuracy differences are attributable solely to the loss-optimizer pairing. Our results confirm that no single pairing is universally optimal. Cross-Entropy with Adam or AdamW is the most robust choice across architecture families and datasets. NGL is a competitive alternative to CEL on standard convolutional classifiers, but only when paired with adaptive optimizers; it degrades substantially with SGD or accumulation-based methods. Adagrad and Adadelta consistently underperform under fixed hyperparameters regardless of loss function, highlighting their sensitivity to learning rate tuning. These findings provide actionable guidance for loss-optimizer selection within NNGPT Framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a large-scale empirical study (594 runs) of 18 loss-optimizer pairings (Cross-Entropy, NLL, NGL losses with SGD+Momentum, Adam, AdamW, RMSprop, Adagrad, Adadelta) applied to 33 architectures from the LEMUR pool across six image-classification datasets. All runs use a single fixed-hyperparameter protocol. The central claim is that no pairing is universally optimal; Cross-Entropy with Adam or AdamW is the most robust across architecture families and datasets, while NGL is competitive only with adaptive optimizers on standard convolutional models and Adagrad/Adadelta underperform under the fixed protocol.
Significance. If the attribution to pairings holds, the work supplies concrete, actionable guidance for loss-optimizer selection inside NNGPT-style AutoML pipelines and demonstrates that a single recipe is insufficient for heterogeneous architecture pools. The scale (33 architectures, 6 datasets) and explicit fixed-hyperparameter design are strengths that reduce confounding relative to per-pairing tuning studies.
major comments (2)
- [Abstract] Abstract: The claim that 'observed accuracy differences are attributable solely to the loss-optimizer pairing' under a uniform fixed-hyperparameter protocol is load-bearing for the robustness conclusion, yet the paper itself notes Adagrad and Adadelta's sensitivity to learning-rate choice. Without explicit justification or ablation showing that the chosen hyperparameter set is neutral across all six optimizers, performance gaps may partly reflect hyperparameter mismatch rather than intrinsic pairing quality, weakening the 'most robust across architecture families' assertion.
- [Abstract] Abstract and experimental protocol: No variance estimates, statistical significance tests, number of epochs, or early-stopping criteria are reported. This leaves the central claim that CEL+Adam/AdamW is 'most robust' only partially supported, as it is impossible to determine whether reported accuracy differences exceed run-to-run variability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'observed accuracy differences are attributable solely to the loss-optimizer pairing' under a uniform fixed-hyperparameter protocol is load-bearing for the robustness conclusion, yet the paper itself notes Adagrad and Adadelta's sensitivity to learning-rate choice. Without explicit justification or ablation showing that the chosen hyperparameter set is neutral across all six optimizers, performance gaps may partly reflect hyperparameter mismatch rather than intrinsic pairing quality, weakening the 'most robust across architecture families' assertion.
Authors: We agree that the fixed-hyperparameter protocol is central to our attribution claim and that the manuscript already flags Adagrad/Adadelta sensitivity. The protocol deliberately uses a single set of defaults to isolate pairing effects across 594 runs rather than per-pairing tuning. In revision we will (i) detail the exact hyperparameter values and their literature basis in a new experimental-setup subsection and (ii) add an explicit limitations paragraph stating that the observed gaps for Adagrad/Adadelta may partly reflect LR mismatch. We will also qualify the abstract claim to read “under the fixed protocol.” This is a partial revision; a full ablation across all optimizers remains outside the current experimental budget. revision: partial
-
Referee: [Abstract] Abstract and experimental protocol: No variance estimates, statistical significance tests, number of epochs, or early-stopping criteria are reported. This leaves the central claim that CEL+Adam/AdamW is 'most robust' only partially supported, as it is impossible to determine whether reported accuracy differences exceed run-to-run variability.
Authors: We acknowledge the reporting gap. The original runs used a fixed epoch budget with validation-based early stopping, but these details were omitted. We will add a concise training-protocol paragraph specifying the epoch count and stopping rule. However, each of the 594 configurations was executed only once to keep the study tractable; therefore variance estimates and significance tests cannot be supplied without new multi-seed experiments. The revision will explicitly list this as a limitation of the present design. revision: partial
- Variance estimates and statistical significance tests cannot be provided from the existing single-run data; additional multi-seed experiments would be required.
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential reductions
full rationale
The paper conducts a large-scale empirical sweep of 18 loss-optimizer pairings across 33 architectures and 6 datasets under fixed hyperparameters, reporting direct accuracy measurements. No equations, derivations, fitted parameters renamed as predictions, or self-citations are invoked to justify any central result. The claim that CEL+Adam/AdamW is most robust follows from the tabulated experimental outcomes rather than from any definitional equivalence or imported uniqueness theorem. The methodological choice of fixed hyperparameters is a standard experimental control and does not create a circular reduction; it is an assumption whose validity can be assessed externally. Consequently the derivation chain contains no load-bearing step that collapses to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard neural-network training assumptions (i.i.d. samples, gradient-based optimization, fixed random seeds) hold and produce comparable runs when only loss and optimizer differ.
Reference graph
Works this paper leans on
-
[1]
Nada Aboudeshish, Dmitry Ignatov, and Radu Timofte. AUGMENTGEST: Can random data cropping augmentation boost gesture recognition performance?arXiv preprint, arXiv:2506.07216, 2025. 1
arXiv 2025
-
[2]
Santosh Premi Adhikari, Radu Timofte, and Dmitry Ignatov. Delta-based neural architecture search: LLM fine-tuning via code diffs.arXiv preprint arXiv:2605.04903, 2026. 1
Pith/arXiv arXiv 2026
-
[3]
Next generation loss function for image classification, 2024
Shakhnaz Akhmedova and Nils K ¨orber. Next generation loss function for image classification, 2024. 1, 2
2024
-
[4]
Shallue, Zachary Nado, Jaehoon Lee, Chris J
Dami Choi, Christopher J. Shallue, Zachary Nado, Jaehoon Lee, Chris J. Maddison, and George E. Dahl. On empirical comparisons of optimizers for deep learning, 2020. 3, 6
2020
-
[5]
On the algorithmic imple- mentation of multiclass kernel-based vector machines, 2001
Koby Crammer and Yoram Singer. On the algorithmic imple- mentation of multiclass kernel-based vector machines, 2001. 2
2001
-
[6]
AI on the edge: An automated pipeline for PyTorch-to-Android deployment and benchmarking.Preprints, 2025
Saif U Din, Muhammad Ahsan Hussain, Mohsin Ikram, Dmitry Ignatov, and Radu Timofte. AI on the edge: An automated pipeline for PyTorch-to-Android deployment and benchmarking.Preprints, 2025. 1
2025
-
[7]
Duchi, Elad Hazan, and Yoram Singer
John C. Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic opti- mization, 2011. 3
2011
-
[8]
Enhancing LLM-based neural network generation: Few-shot prompting and efficient vali- dation for automated architecture design
Raghuvir Duvvuri, Chandini Vysyaraju, Avi Goyal, Dmitry Ignatov, and Radu Timofte. Enhancing LLM-based neural network generation: Few-shot prompting and efficient vali- dation for automated architecture design. InProceedings of 6 the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2026. to appear. 1
2026
-
[9]
LEMUR neural net- work dataset: Towards seamless AutoML.arXiv preprint, arXiv:2504.10552, 2025
Arash Torabi Goodarzi, Roman Kochnev, Waleed Khalid, Furui Qin, Tolgay Atinc Uzun, Yashkumar Sanjaybhai Dhameliya, Yash Kanubhai Kathiriya, Zofia Antonina Ben- tyn, Dmitry Ignatov, and Radu Timofte. LEMUR neural net- work dataset: Towards seamless AutoML.arXiv preprint, arXiv:2504.10552, 2025. 1, 2, 3
Pith/arXiv arXiv 2025
-
[10]
Deep learning, 2016
Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep learning, 2016. 3
2016
-
[11]
Resource- efficient iterative LLM-based NAS with feedback memory
Xiaojie Gu, Dmitry Ignatov, and Radu Timofte. Resource- efficient iterative LLM-based NAS with feedback memory. arXiv preprint, arXiv:2603.12091, 2026. 3
arXiv 2026
-
[12]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016. 3
2016
-
[13]
Krunal Jesani, Dmitry Ignatov, and Radu Timofte. LLM as a neural architect: Controlled generation of image cap- tioning models under strict API contracts.arXiv preprint, arXiv:2512.14706, 2025. 1
arXiv 2025
-
[14]
Real image denoising with knowledge distillation for high-performance mobile NPUs
Faraz Kayani, Sarmad Kayani, Asad Ahmed, Radu Timofte, and Dmitry Ignatov. Real image denoising with knowledge distillation for high-performance mobile NPUs. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2026. to appear. 1
2026
-
[15]
Waleed Khalid, Dmitry Ignatov, and Radu Timofte. A retrieval-augmented generation approach to extracting al- gorithmic logic from neural networks.arXiv preprint, arXiv:2512.04329, 2025. 1
Pith/arXiv arXiv 2025
-
[16]
From memorization to creativity: LLM as a designer of novel neu- ral architectures
Waleed Khalid, Dmitry Ignatov, and Radu Timofte. From memorization to creativity: LLM as a designer of novel neu- ral architectures. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition Work- shops (CVPRW), 2026. to appear. 3
2026
-
[17]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2015. 3
2015
-
[18]
Roman Kochnev, Arash Torabi Goodarzi, Zofia Antonina Bentyn, Dmitry Ignatov, and Radu Timofte. Optuna vs code llama: Are LLMs a new paradigm for hyperparameter tun- ing? InProceedings of the IEEE/CVF International Confer- ence on Computer Vision Workshops (ICCVW), pages 5664– 5674, 2025. 1, 2, 3, 4
2025
-
[19]
NNGPT: Rethinking AutoML with large language models
Roman Kochnev, Waleed Khalid, Tolgay Atinc Uzun, Xi Zhang, Yashkumar Sanjaybhai Dhameliya, Furui Qin, Chan- dini Vysyaraju, Raghuvir Duvvuri, Avi Goyal, Dmitry Igna- tov, and Radu Timofte. NNGPT: Rethinking AutoML with large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2026. to app...
2026
-
[20]
Solomon Kullback and Richard A. Leibler. On information and sufficiency, 1951. 2
1951
-
[21]
MobileAgeNet: Lightweight facial age estimation for mobile deployment
Arun Kumar, Aswathy Baiju, Radu Timofte, and Dmitry Ig- natov. MobileAgeNet: Lightweight facial age estimation for mobile deployment. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition Work- shops (CVPRW), 2026. to appear. 1
2026
-
[22]
Decoupled weight decay regularization, 2019
Igor Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. 3
2019
-
[23]
Cross-entropy loss functions: Theoretical analysis and applications, 2023
Yiyi Mao and Mehryar Mohri. Cross-entropy loss functions: Theoretical analysis and applications, 2023. 2
2023
-
[24]
Yash Mittal, Dmitry Ignatov, and Radu Timofte. Prepara- tion of fractal-inspired computational architectures for ad- vanced large language model analysis.arXiv preprint, arXiv:2511.07329, 2025. 1
Pith/arXiv arXiv 2025
-
[25]
Pytorch: An im- perative style, high-performance deep learning library, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An im- perative style, high-performance deep learning library, 2019. 2
2019
-
[26]
Boris T. Polyak. Some methods of speeding up the conver- gence of iteration methods, 1964. 3
1964
-
[27]
Usha Shrestha, Dmitry Ignatov, and Radu Timofte. From brute force to semantic insight: Performance-guided data transformation design with LLMs.arXiv preprint, arXiv:2601.03808, 2026. 1
arXiv 2026
-
[28]
Lecture 6.5 — rm- sprop: Divide the gradient by a running average of its recent magnitude, 2012
Tijmen Tieleman and Geoffrey Hinton. Lecture 6.5 — rm- sprop: Divide the gradient by a running average of its recent magnitude, 2012. 3
2012
-
[29]
Closed-loop LLM discovery of non-standard channel priors in vision models
Tolgay Atinc Uzun, Dmitry Ignatov, and Radu Timofte. Closed-loop LLM discovery of non-standard channel priors in vision models. InProceedings of the International Con- ference on Pattern Recognition (ICPR), 2026. to appear. 1
2026
-
[30]
LEMUR 2: Unlocking neural net- work diversity for AI
Tolgay Atinc Uzun, Waleed Khalid, Saif U Din, Sai Re- vanth Mulukuledu, Akashdeep Singh, Chandini Vysyaraju, Raghuvir Duvvuri, Avi Goyal, Yashkumar Rajeshbhai Lukhi, Ahsan Hussain, Krunal Jesani, Usha Shrestha, Yash Mittal, Roman Kochnev, Pritam Kadam, Mohsin Ikram, Harsh Rameshbhai Moradiya, Alice Arslanian, Dmitry Ig- natov, and Radu Timofte. LEMUR 2: U...
2026
-
[31]
Matthew D. Zeiler. Adadelta: An adaptive learning rate method, 2012. 3 7
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.