Improving Robotic Imitation Learning via Trajectory Standardization
Pith reviewed 2026-06-26 08:35 UTC · model grok-4.3
The pith
ISR resamples demonstration trajectories to equal information distances rather than uniform time intervals, raising imitation learning success rates by about 25%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
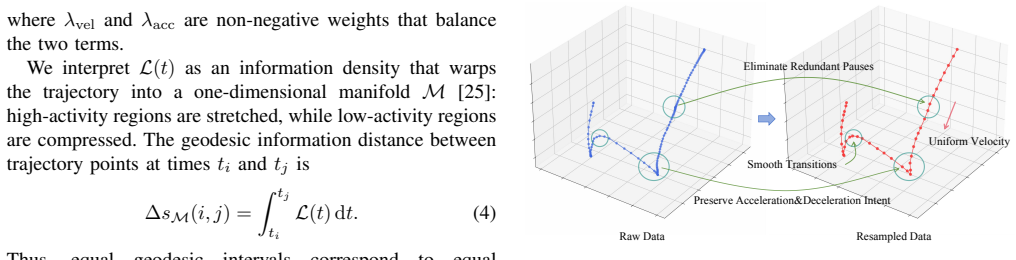
The central claim is that by constructing an information-intensity field from velocity and acceleration norms and performing geodesic-equidistant parameterization on an information-modulated Riemannian manifold, ISR produces resampled trajectories that enable higher success rates in learned robotic policies compared to time-uniform methods.
What carries the argument
The Information-Standardized Trajectory Resampling (ISR) method, which uses velocity and acceleration norms to build an information-intensity field and then applies geodesic-equidistant parameterization on the resulting Riemannian manifold.
If this is right
- ISR-processed trajectories lead to about 25% higher task success rates in imitation learning policies.
- Both the size of the training dataset and the computational cost of training are reduced.
- Performance gains hold across datasets collected by different human operators.
- The resampling better removes speed-induced irregularities and redundant pauses than time-based downsampling.
Where Pith is reading between the lines
- Applying ISR preprocessing could improve other learning-from-demonstration techniques that rely on trajectory data.
- The method's reliance on velocity and acceleration suggests potential benefits in tasks with varying dynamics or contact forces.
- One could test whether ISR helps in transferring policies between different robot embodiments.
- Extending the information field to include visual or tactile features might further enhance trajectory standardization.
Load-bearing premise
Constructing the information-intensity field from velocity and acceleration norms and using geodesic-equidistant parameterization on the manifold will yield trajectories that produce superior learned policies.
What would settle it
If experiments using time-uniform downsampling or other resampling strategies on the same datasets achieve similar or higher success rates than ISR, the benefit of the information-based approach would be falsified.
Figures




read the original abstract
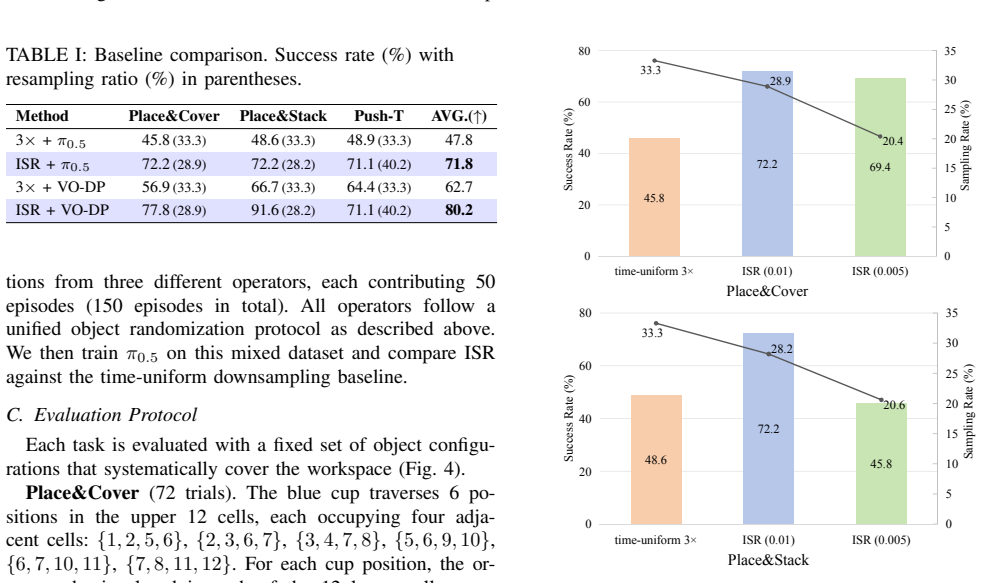
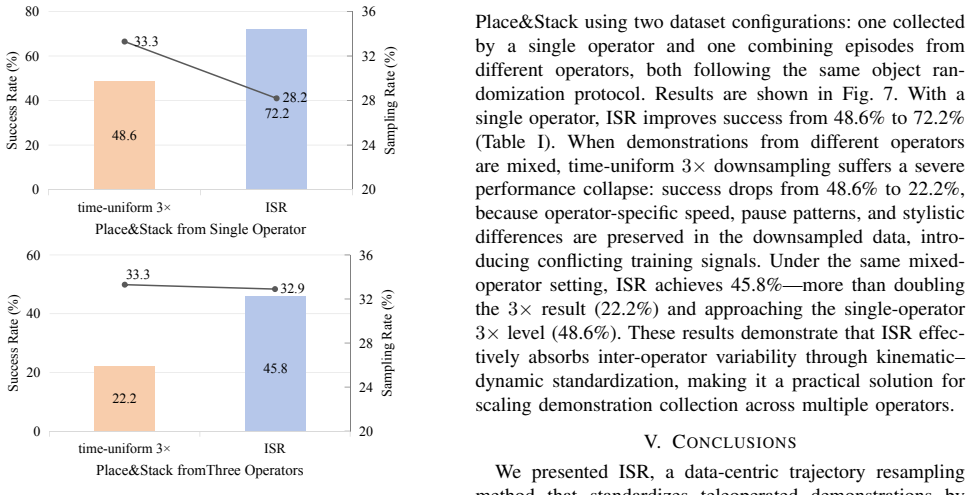
Imitation learning for robotic manipulation relies on large sets of human demonstration trajectories, which are often noisy and temporally irregular due to variable operator speed, intermittent pauses, and inconsistent action density. A common preprocessing strategy is time-uniform downsampling to shorten sequences, but it cannot effectively remove speed-induced non-uniformity or redundant pauses. This mismatch degrades data quality and hinders policy learning. To address this issue, we propose Information-Standardized Trajectory Resampling (ISR), an offline preprocessing method for effective imitation learning. ISR resamples each trajectory by enforcing approximately equal information distance between adjacent points. Specifically, we map trajectories onto an information-modulated Riemannian manifold and perform geodesic-equidistant parameterization. We construct an information-intensity field from velocity and acceleration norms: the velocity term removes small-motion redundancy, while the acceleration term preserves high-curvature and fine-manipulation phases. We evaluate ISR on three real-world manipulation tasks with mainstream imitation learning policies. Compared with the baseline time-uniform 3x downsampling, ISR improves task success rates by about 25%, remains robust across datasets collected from different operators, and reduces both dataset size and training cost. The code and videos are publicly available at https://d-robotics-ai-lab.github.io/isr.page.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Information-Standardized Trajectory Resampling (ISR), an offline preprocessing technique for robotic imitation learning. ISR constructs an information-intensity field from velocity and acceleration norms, maps each demonstration trajectory onto an information-modulated Riemannian manifold, and performs geodesic-equidistant parameterization to enforce approximately equal information distance between resampled points. The central empirical claim is that ISR yields roughly 25% higher task success rates than time-uniform 3× downsampling on three real-world manipulation tasks, while remaining robust across operators and reducing both dataset size and training cost.
Significance. If the reported gains are reproducible and statistically supported, ISR would constitute a practical, algorithm-agnostic contribution to imitation learning by addressing speed-induced non-uniformity in human demonstrations. The public release of code and videos strengthens the potential for adoption and further validation.
major comments (2)
- The abstract (and presumably the evaluation section) reports an approximately 25% success-rate improvement without error bars, number of evaluation trials per task, dataset sizes, or any statistical significance tests. This omission is load-bearing for the central claim, as it prevents assessment of whether the gain is reliable or could arise from variance in policy training or task execution.
- §3 (Method): the construction of the information-intensity field and the subsequent geodesic-equidistant parameterization on the Riemannian manifold are described at a high level; without explicit equations for the metric tensor, the weighting between velocity and acceleration terms, or pseudocode for the resampling procedure, the method cannot be independently verified or reproduced from the given description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of empirical reporting and methodological clarity that we will address in the revision.
read point-by-point responses
-
Referee: The abstract (and presumably the evaluation section) reports an approximately 25% success-rate improvement without error bars, number of evaluation trials per task, dataset sizes, or any statistical significance tests. This omission is load-bearing for the central claim, as it prevents assessment of whether the gain is reliable or could arise from variance in policy training or task execution.
Authors: We agree that these details are necessary to substantiate the central empirical claim. In the revised manuscript we will add error bars to all reported success rates, explicitly state the number of evaluation trials per task and the dataset sizes, and include statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests) comparing ISR against the time-uniform baseline. These additions will appear in the evaluation section and, space permitting, will be summarized in the abstract. revision: yes
-
Referee: §3 (Method): the construction of the information-intensity field and the subsequent geodesic-equidistant parameterization on the Riemannian manifold are described at a high level; without explicit equations for the metric tensor, the weighting between velocity and acceleration terms, or pseudocode for the resampling procedure, the method cannot be independently verified or reproduced from the given description.
Authors: We acknowledge that greater mathematical detail is required for reproducibility. The revised version will include the explicit definition of the information-intensity field, the form of the metric tensor on the information-modulated Riemannian manifold, the precise weighting coefficients applied to the velocity and acceleration norms, and pseudocode for the full ISR resampling procedure. These will be placed in §3 or a dedicated appendix. revision: yes
Circularity Check
No significant circularity; method is standalone preprocessing with empirical validation
full rationale
The paper defines ISR as an offline resampling procedure that constructs an information-intensity field from velocity/acceleration norms and performs geodesic-equidistant parameterization on an information-modulated Riemannian manifold. This is presented as a fixed algorithmic pipeline, not derived from or fitted to the target policy performance. The central claim (approximately 25% success-rate improvement over time-uniform 3x downsampling) is an external empirical result on three real-world tasks, not a quantity forced by construction from the preprocessing equations themselves. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core steps; the derivation chain is self-contained and externally falsifiable via the reported task-success metrics.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Trajectories can be represented on an information-modulated Riemannian manifold where geodesic distance measures information content.
- domain assumption Velocity and acceleration norms sufficiently capture information intensity for manipulation tasks.
Reference graph
Works this paper leans on
-
[1]
X. Tan, Y . Yang, P. Ye, J. Zheng, B. Bai, X. Wang, J. Hao, and T. Chen, “Think Twice, Act Once: Token-aware compression and action reuse for efficient inference in vision-language-action models,” arXiv preprint arXiv:2505.21200, 2025
-
[2]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” inProceedings of Robotics: Science and Systems, 2023
2023
-
[3]
Diffusion Policy: Visuomotor policy learning via action diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion Policy: Visuomotor policy learning via action diffusion,” in Proceedings of Robotics: Science and Systems, 2023
2023
-
[4]
RDT-1B: a diffusion foundation model for bimanual ma- nipulation,
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu, “RDT-1B: a diffusion foundation model for bimanual ma- nipulation,” inInternational Conference on Learning Representations, 2025, pp. 29 982–30 009. 1https://github.com/Physical-Intelligence/openpi 2https://github.com/D-Robotics-AI-Lab/DRRM
2025
-
[5]
Q. Liet al., “CogACT: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation,”arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
FlowPolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipulation,
Q. Zhang, Z. Liu, H. Fan, G. Liu, B. Zeng, and S. Liu, “FlowPolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipulation,” inProceedings of the AAAI Con- ference on Artificial Intelligence, vol. 39, no. 14, 2025, pp. 14 754– 14 762
2025
-
[7]
π 0.5: a vision-language-action model with open- world generalization,
K. Blacket al., “π 0.5: a vision-language-action model with open- world generalization,” inProceedings of The 9th Conference on Robot Learning. PMLR, 2025, pp. 17–40
2025
-
[8]
Fighting copycat agents in behavioral cloning from observation histories,
C. Wen, J. Lin, T. Darrell, D. Jayaraman, and Y . Gao, “Fighting copycat agents in behavioral cloning from observation histories,” Advances in Neural Information Processing Systems, vol. 33, pp. 2564–2575, 2020
2020
-
[9]
Eliciting compatible demonstrations for multi-human imitation learning,
K. Gandhi, S. Karamcheti, M. Liao, and D. Sadigh, “Eliciting compatible demonstrations for multi-human imitation learning,” in Proceedings of The 6th Conference on Robot Learning. PMLR, 2023, pp. 1981–1991
2023
-
[10]
Towards balanced behavior cloning from imbalanced datasets,
S. Parekh, H. Nemlekar, and D. P. Losey, “Towards balanced behavior cloning from imbalanced datasets,”Autonomous Robots, vol. 50, no. 1, p. 9, 2026
2026
-
[11]
What matters for adversarial imitation learning?
M. Orsini, A. Raichuk, L. Hussenot, D. Vincent, R. Dadashi, S. Girgin, M. Geist, O. Bachem, O. Pietquin, and M. Andrychowicz, “What matters for adversarial imitation learning?”Advances in Neural In- formation Processing Systems, vol. 34, pp. 14 656–14 668, 2021
2021
-
[12]
What matters in learning from offline human demonstrations for robot manipu- lation,
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın, “What matters in learning from offline human demonstrations for robot manipu- lation,” inProceedings of the 5th Conference on Robot Learning. PMLR, 2022, pp. 1678–1690
2022
-
[13]
Vision- language-action models for robotics: A review towards real-world applications,
K. Kawaharazuka, J. Oh, J. Yamada, I. Posner, and Y . Zhu, “Vision- language-action models for robotics: A review towards real-world applications,”IEEE Access, vol. 13, pp. 162 467–162 504, 2025
2025
-
[14]
Arc-length- based warping for robot skill synthesis from multiple demonstrations,
G. Braglia, D. Tebaldi, A. E. Lazzaretti, and L. Biagiotti, “Arc-length- based warping for robot skill synthesis from multiple demonstrations,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025, pp. 8111–8118
2025
-
[15]
Waypoint-based imitation learning for robotic manipulation,
L. X. Shi, A. Sharma, T. Z. Zhao, and C. Finn, “Waypoint-based imitation learning for robotic manipulation,” inProceedings of The 7th Conference on Robot Learning. PMLR, 2023, pp. 2195–2209
2023
-
[16]
VO-DP: Semantic-geometric adaptive diffusion policy for vision-only robotic manipulation,
Z. Ni, Y . He, L. Qian, J. Mao, F. Fu, W. Sui, H. Su, J. Peng, Z. Wang, and B. He, “VO-DP: Semantic-geometric adaptive diffusion policy for vision-only robotic manipulation,”arXiv preprint arXiv:2510.15530, 2025
-
[17]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” inProceedings of the fourteenth international conference on artificial intelligence and statistics, 2011, pp. 627–635
2011
-
[18]
HYDRA: Hybrid robot actions for imitation learning,
S. Belkhale, Y . Cui, and D. Sadigh, “HYDRA: Hybrid robot actions for imitation learning,” inProceedings of The 7th Conference on Robot Learning. PMLR, 2023, pp. 2113–2133
2023
-
[19]
View: Visual imitation learning with waypoints,
A. Jonnavittula, S. Parekh, and D. P. Losey, “View: Visual imitation learning with waypoints,”Autonomous Robots, vol. 49, no. 1, p. 5, 2025
2025
-
[20]
Waypoint-based rein- forcement learning for robot manipulation tasks,
S. A. Mehta, S. Habibian, and D. P. Losey, “Waypoint-based rein- forcement learning for robot manipulation tasks,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024, pp. 541–548
2024
-
[21]
KeyWorld: Key frame rea- soning enables effective and efficient world models,
S. Li, Q. Hao, Y . Shang, and Y . Li, “KeyWorld: Key frame rea- soning enables effective and efficient world models,”arXiv preprint arXiv:2509.21027, 2025
-
[22]
Algorithms for the reduction of the number of points required to represent a digitized line or its caricature,
D. H. Douglas and T. K. Peucker, “Algorithms for the reduction of the number of points required to represent a digitized line or its caricature,”Cartographica: the international journal for geographic information and geovisualization, vol. 10, no. 2, pp. 112–122, 1973
1973
-
[23]
Spatiotemporal compression techniques for moving point objects,
N. Meratnia and R. A. de By, “Spatiotemporal compression techniques for moving point objects,” inInternational Conference on Extending Database Technology, 2004, pp. 765–782
2004
-
[24]
Trajectory clustering: a partition- and-group framework,
J.-G. Lee, J. Han, and K.-Y . Whang, “Trajectory clustering: a partition- and-group framework,” inProceedings of the 2007 ACM SIGMOD international conference on Management of data, 2007, pp. 593–604
2007
-
[25]
D. E. Blair,Riemannian Geometry of Contact and Symplectic Mani- folds, 2nd ed., ser. Progress in Mathematics. Boston, MA: Birkh ¨auser Boston, 2010, vol. 203
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.