SAOT: Self-Supervised Continual Graph Learning with Structure-Aware Optimal Transport
Pith reviewed 2026-07-02 16:40 UTC · model grok-4.3
The pith
Optimal transport captures global node correspondences to prevent structure distortion in self-supervised continual graph learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
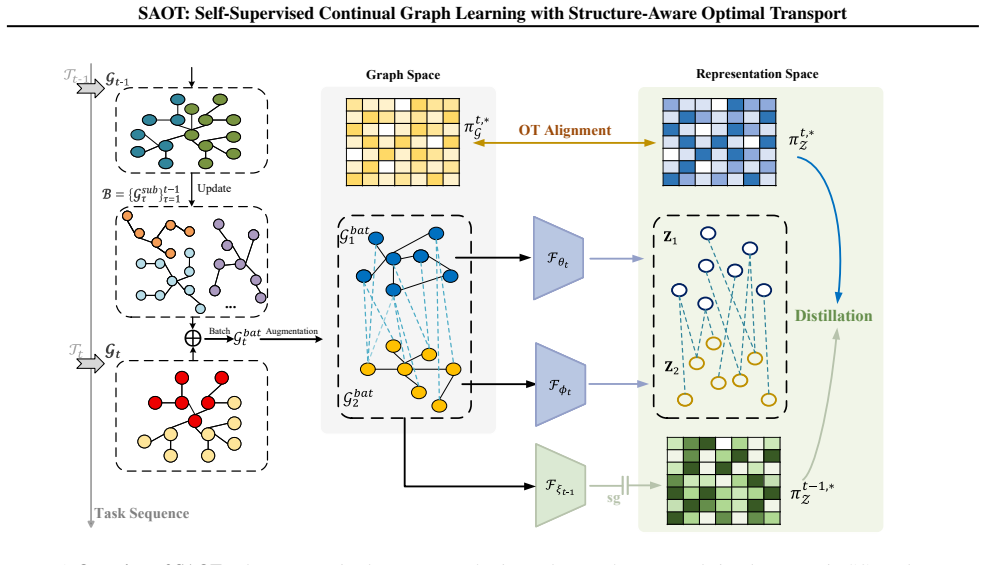
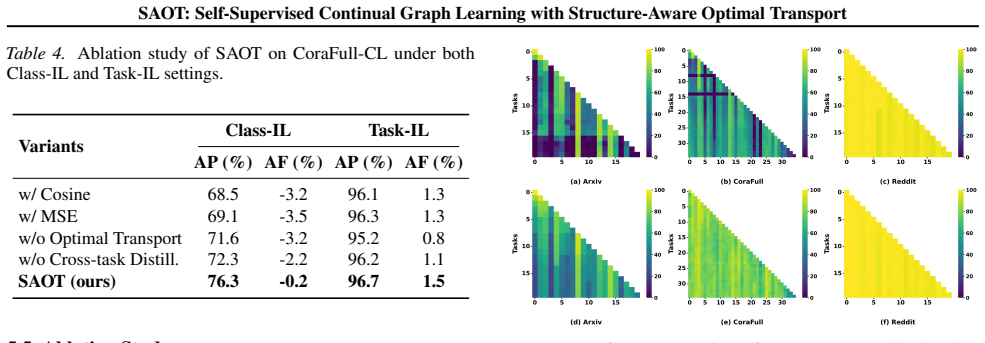
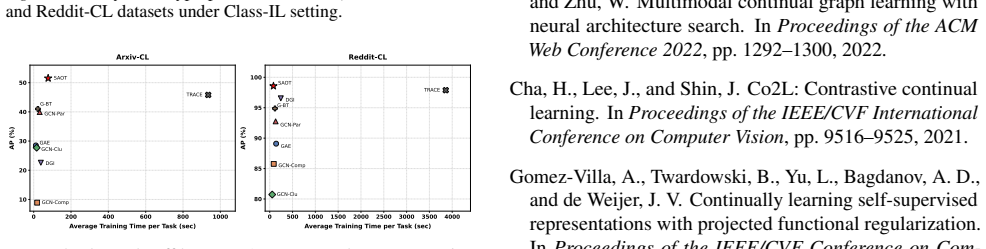
The paper claims that a Structure-Aware Optimal Transport framework, by using optimal transport theory for global inter-node correspondences and a cross-task knowledge distillation mechanism for prior structural knowledge, preserves relational structure in graph representations across sequential tasks and outperforms existing self-supervised CGL baselines on four benchmark datasets.
What carries the argument
The Structure-Aware Optimal Transport (SAOT) framework that applies optimal transport to capture global inter-node correspondences while using cross-task distillation to preserve previous structure.
If this is right
- SAOT maintains global relational structure better than instance-level consistency methods across tasks.
- Performance improves on CoraFull-CL by up to 5 percent and on Products-CL by over 15 percent versus state-of-the-art self-supervised baselines in Class-IL.
- Graph representation learning is enhanced without requiring label supervision in sequential settings.
- The combination of optimal transport and distillation enables successive learning from graph sequences with different tasks.
Where Pith is reading between the lines
- The same global-structure focus could be tested on dynamic graphs from recommendation systems or social networks to check if accuracy gains hold outside the reported benchmarks.
- If optimal transport reliably encodes correspondences, variants might apply to other unsupervised continual settings such as image streams where pairwise relations matter.
- Distillation of structural knowledge might reduce forgetting rates even when task boundaries are soft rather than explicit.
- Direct measurement of correspondence fidelity before and after each task could serve as an internal diagnostic for when the method succeeds.
Load-bearing premise
Instance-level consistency objectives necessarily distort inter-node correspondences under continual learning, and optimal transport plus distillation can reliably capture and maintain global relational structure without labels.
What would settle it
A controlled run on the same benchmarks where inter-node correspondence distortion is measured directly and found absent under instance-level methods, or where SAOT shows no accuracy gain.
Figures
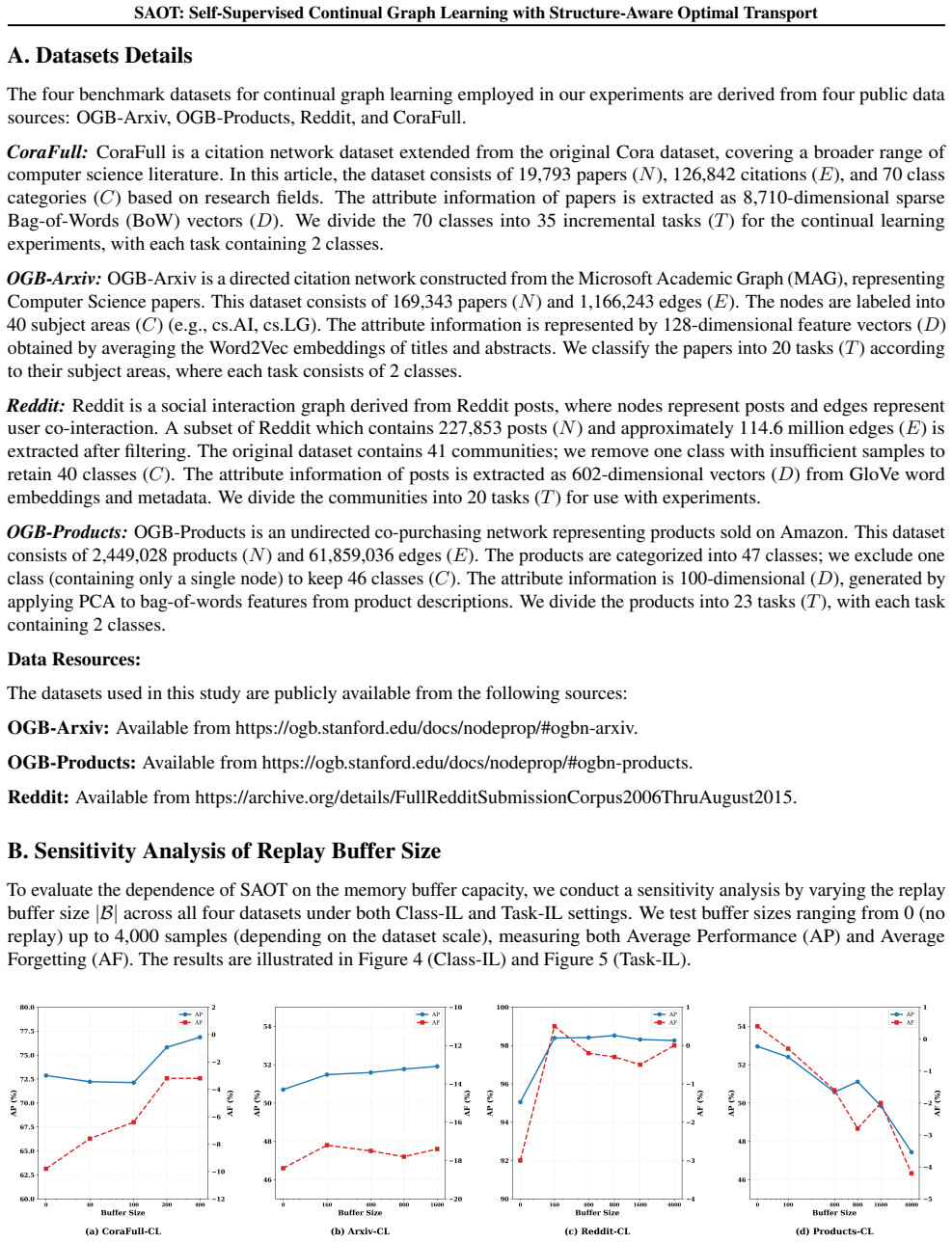
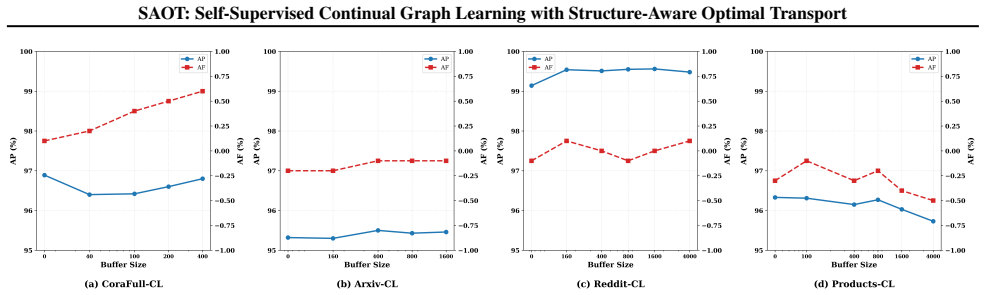
read the original abstract
Self-supervised Continual Graph Learning (CGL) aims to successively learn from a graph sequence with different tasks without label supervision - a paradigm that has attracted widespread attention. Most existing self-supervised CGL methods rely on instance-level consistency objectives that enforce stability of individual node (or node-pair) embeddings. Due to optimizing nodes in isolation, these methods fail to maintain global relational structure, causing inter-node correspondences to progressively distort under continual learning. To this end, we propose a novel Structure-Aware Optimal Transport (SAOT) framework that explicitly captures and preserves relational structure within graph representations across sequential tasks. Specifically, SAOT leverages optimal transport theory to capture global inter-node correspondences, thereby facilitating and enhancing graph representation learning. Simultaneously, SAOT incorporates a cross-task knowledge distillation mechanism to preserve the previous structural knowledge. Extensive experiments on four CGL benchmark datasets demonstrate that SAOT outperforms existing self-supervised baselines. In particular, SAOT achieves significant performance gains, improving average accuracy by up to 5% on CoraFull-CL and over 15% on Products-CL compared with state-of-the-art methods in the Class-IL setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that instance-level consistency objectives in self-supervised continual graph learning (CGL) distort global inter-node correspondences, and proposes SAOT to address this via optimal transport (OT) for capturing global correspondences plus cross-task knowledge distillation to preserve prior structural knowledge. It reports that SAOT outperforms self-supervised baselines, with gains of up to 5% average accuracy on CoraFull-CL and over 15% on Products-CL in the Class-IL setting across four CGL benchmarks.
Significance. If the central claims hold and the OT-derived correspondences can be shown to align with actual graph structure rather than embedding artifacts, the work would offer a concrete mechanism for preserving relational structure in label-free continual graph settings, extending beyond instance-level methods.
major comments (2)
- The provided manuscript text (abstract and description) contains no loss formulations, OT cost definitions, distillation objectives, implementation details, or experimental protocols, so the performance claims cannot be assessed for support by data or derivations.
- The central technical assumption—that OT computed on unsupervised node embeddings reliably recovers and preserves true inter-node correspondences across tasks—is load-bearing but unverified; because the transport cost derives directly from the embeddings themselves, any progressive distortion in those embeddings can produce a self-reinforcing matching that distillation then propagates without independent checks against ground-truth relational structure.
minor comments (1)
- The abstract refers to 'extensive experiments' and specific percentage gains but supplies no table, figure, or protocol details to ground those numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript to improve clarity and address the technical concerns.
read point-by-point responses
-
Referee: The provided manuscript text (abstract and description) contains no loss formulations, OT cost definitions, distillation objectives, implementation details, or experimental protocols, so the performance claims cannot be assessed for support by data or derivations.
Authors: We agree that the abstract and high-level description lack explicit formulations. The full manuscript details the OT cost (derived from embedding similarities), the structure-aware transport objective, the cross-task distillation loss, and the experimental protocols across the four benchmarks in Sections 3 and 4. We will add a concise summary of the key loss functions and OT definitions to the introduction or a new preliminary section in the revision. revision: yes
-
Referee: The central technical assumption—that OT computed on unsupervised node embeddings reliably recovers and preserves true inter-node correspondences across tasks—is load-bearing but unverified; because the transport cost derives directly from the embeddings themselves, any progressive distortion in those embeddings can produce a self-reinforcing matching that distillation then propagates without independent checks against ground-truth relational structure.
Authors: This is a substantive concern about potential circularity in the OT matching. SAOT jointly optimizes embeddings and the transport plan with a structure-aware cost, and distillation transfers prior transport plans to mitigate drift. While the self-supervised setting precludes direct ground-truth correspondence checks, the reported gains (up to 5% on CoraFull-CL and 15% on Products-CL) across multiple datasets provide supporting evidence. We will expand the discussion of this assumption, include sensitivity analysis on embedding quality, and note limitations in the revised version. revision: partial
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description frame SAOT as an application of established optimal transport theory to capture global correspondences, combined with a separate cross-task distillation step for knowledge preservation. No equations, self-citations, or derivations are quoted that reduce a claimed prediction or result to a fitted parameter or input by construction. The method is presented as leveraging external mathematical tools rather than self-defining its outputs, rendering the derivation chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yu , title =
Zonghan Wu and Shirui Pan and Fengwen Chen and Guodong Long and Chengqi Zhang and Philip S. Yu , title =. IEEE Transactions on Neural Networks and Learning Systems , year =
-
[2]
Hamilton and Z
W. Hamilton and Z. Ying and J. Leskovec , title =. 2017 , booktitle =
2017
-
[3]
Kipf and Max Welling , title =
Thomas N. Kipf and Max Welling , title =. 2017 , booktitle =
2017
-
[4]
Graph Attention Networks , year =
Petar Veli. Graph Attention Networks , year =. Proceedings of the 6th International Conference on Learning Representations (ICLR 2018) , address =
2018
-
[5]
Wang and G
J. Wang and G. Song and Y. Wu and L. Wang , title =. 2020 , pages =
2020
-
[6]
Zhou and C
F. Zhou and C. Cao , title =. 2021 , pages =
2021
-
[7]
Advances in Neural Information Processing Systems , publisher =
Xikun Zhang and Dongjin Song and Dacheng Tao , title =. Advances in Neural Information Processing Systems , publisher =. 2022 , pages =
2022
-
[8]
McCloskey and N
M. McCloskey and N. J. Cohen. Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem. Psychology of Learning and Motivation. 1989
1989
-
[9]
Goodfellow and Mehdi Mirza and Da Xiao and Aaron Courville and Yoshua Bengio , title =
Ian J. Goodfellow and Mehdi Mirza and Da Xiao and Aaron Courville and Yoshua Bengio , title =. 2014 , booktitle =
2014
-
[10]
Rusu and Kieran Milan and John Quan and Tiago Ramalho and Agnieszka Grabska-Barwinska and Demis Hassabis and Claudia Clopath and Dharshan Kumaran and Raia Hadsell , title =
James Kirkpatrick and Razvan Pascanu and Neil Rabinowitz and Joel Veness and Guillaume Desjardins and Andrei A. Rusu and Kieran Milan and John Quan and Tiago Ramalho and Agnieszka Grabska-Barwinska and Demis Hassabis and Claudia Clopath and Dharshan Kumaran and Raia Hadsell , title =. Proceedings of the National Academy of Sciences , year =
-
[11]
Liu and Y
H. Liu and Y. Yang and X. Wang , title =. 2021 , pages =
2021
-
[12]
Zhang and D
X. Zhang and D. Song and D. Tao , title =. Proceedings of the 2022 IEEE International Conference on Data Mining , publisher =. 2022 , pages =
2022
-
[13]
Peyr \'e and M
G. Peyr \'e and M. Cuturi. Computational Optimal Transport: With Applications to Data Science. 2019
2019
-
[14]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining , volume =
Zhen Peng and Xu Hua and Jingchen Hao and Qika Lin and Bo Dong and Chao Shen , title =. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining , volume =. 2025 , pages =
2025
-
[15]
Cai and X
J. Cai and X. Wang and C. Guan and Y. Tang and J. Xu and B. Zhong and W. Zhu , title =. 2022 , pages =
2022
-
[16]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year =
Xikun Zhang and Dongjin Song and Dacheng Tao , title =. IEEE Transactions on Pattern Analysis and Machine Intelligence , year =
-
[17]
Proceedings of the 2023 IEEE International Conference on Data Mining , publisher =
Yilun Liu and Ruihong Qiu and Zi Huang , title =. Proceedings of the 2023 IEEE International Conference on Data Mining , publisher =. 2023 , pages =
2023
-
[18]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , publisher =
Xikun Zhang and Dongjin Song and Yixin Chen and Dacheng Tao , title =. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , publisher =. 2024 , pages =
2024
-
[19]
Yu , title =
Li Sun and Junda Ye and Hao Peng and Feiyang Wang and Philip S. Yu , title =. 2023 , pages =
2023
-
[20]
Variational Graph Auto-Encoders
Thomas N. Kipf and Max Welling , title =. 2016 , archivePrefix =. 1611.07308 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[21]
You and T
Y. You and T. Chen and Y. Sui and T. Chen and Z. Wang and Y. Shen , title =. 2020 , pages =
2020
-
[22]
Deep Graph Infomax , year =
Petar Veli. Deep Graph Infomax , year =. Proceedings of the 7th International Conference on Learning Representations (ICLR 2019) , address =
2019
-
[23]
Wei Jin and Tyler Derr and Haochen Liu and Yiqi Wang and Suhang Wang and Zitao Liu and Jiliang Tang , title =. 2020 , archivePrefix =. 2006.10141 , primaryClass =
-
[24]
Deep graph contrastive representation learning.CoRR, abs/2006.04131,
Yanqiao Zhu and Yichen Xu and Feng Yu and Qiang Liu and Shu Wu and Liang Wang , title =. 2020 , archivePrefix =. 2006.04131 , primaryClass =
-
[25]
Dyer and R
Shantanu Thakoor and Corentin Tallec and Mohammad Gheshlaghi Azar and Mehdi Azabou and Eva L. Dyer and R. Large-Scale Representation Learning on Graphs via Bootstrapping , year =
-
[26]
Chawla , title =
Piotr Bielak and Tomasz Kajdanowicz and Nitesh V. Chawla , title =. Knowledge-Based Systems , year =
-
[27]
2022 , pages =
Namkyeong Lee and Junseok Lee and Chanyoung Park , title =. 2022 , pages =
2022
-
[28]
2023 , pages =
Yejiang Wang and Yuhai Zhao and Daniel Zhengkui Wang and Ling Li , title =. 2023 , pages =
2023
-
[29]
Han and Z
X. Han and Z. Feng and Y. Ning , title =. Advances in Neural Information Processing Systems , address =. 2024 , pages =
2024
-
[30]
IEEE Transactions on Knowledge and Data Engineering , year =
Yilun Liu and Ruihong Qiu and Yanran Tang and Hongzhi Yin and Zi Huang , title =. IEEE Transactions on Knowledge and Data Engineering , year =
-
[31]
You and T
Y. You and T. Chen and Z. Wang and Y. Shen , title =. International Conference on Machine Learning , address =. 2020 , pages =
2020
-
[32]
Li and Y
J. Li and Y. Wang and P. Zhu and W. Lin and Q. Hu , title =. Advances in Neural Information Processing Systems , address =. 2024 , pages =
2024
-
[33]
D. P. Kingma and J. Ba , title =. Proceedings of the 3rd International Conference on Learning Representations , address =. 2015 , pages =
2015
-
[34]
Vayer and N
T. Vayer and N. Courty and R. Tavenard and R. Flamary , title =. Proceedings of the International Conference on Machine Learning , address =. 2019 , pages =
2019
-
[35]
Lee and H
H. Lee and H. Cho and H. Kim and D. Kim and D. Min and J. Choo and C. Lyle , title =. Forty-first International Conference on Machine Learning , address =. 2024 , pages =
2024
-
[36]
Babakniya and Z
S. Babakniya and Z. Fabian and C. He and M. Soltanolkotabi and S. Avestimehr , title =. Advances in Neural Information Processing Systems , address =. 2024 , pages =
2024
-
[37]
Gomez-Villa and B
A. Gomez-Villa and B. Twardowski and K. Wang and J. Van de Weijer , title =. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , address =. 2024 , pages =
2024
-
[38]
Foundations of Computational Mathematics , year =
Facundo M. Foundations of Computational Mathematics , year =
-
[39]
Gomez-Villa and B
A. Gomez-Villa and B. Twardowski and L. Yu and A. D. Bagdanov and J. Van de Weijer , title =. 2022 , pages =
2022
-
[40]
2021 , pages =
Hyuntak Cha and Jaeho Lee and Jinwoo Shin , title =. 2021 , pages =
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.