Wild3R: Feed-Forward 3D Gaussian Splatting from Unconstrained Sparse Photo Collection
Pith reviewed 2026-06-27 10:11 UTC · model grok-4.3
The pith
Wild3R produces 3D Gaussian splats from unconstrained sparse photos without per-scene optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
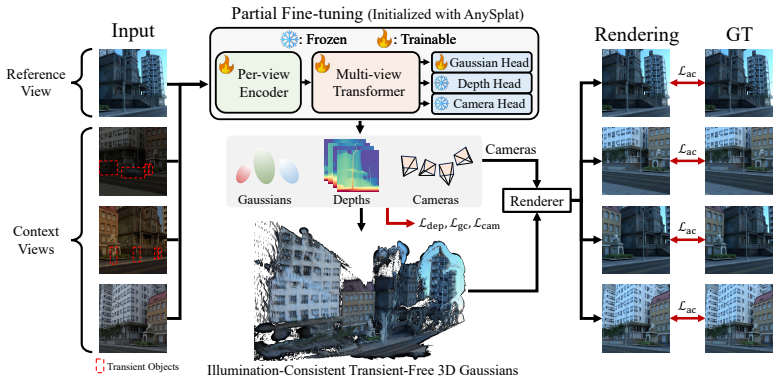
Wild3R is a feed-forward network for 3D Gaussian Splatting that, when trained on the WildCity dataset, learns to generate consistent scene representations from sparse unconstrained photos by conditioning on reference views and removing transient content.
What carries the argument
The WildCity dataset of 200 scenes with 170 lighting conditions and transients, used to train a feed-forward model that enforces appearance consistency across viewpoints while removing transient objects.
If this is right
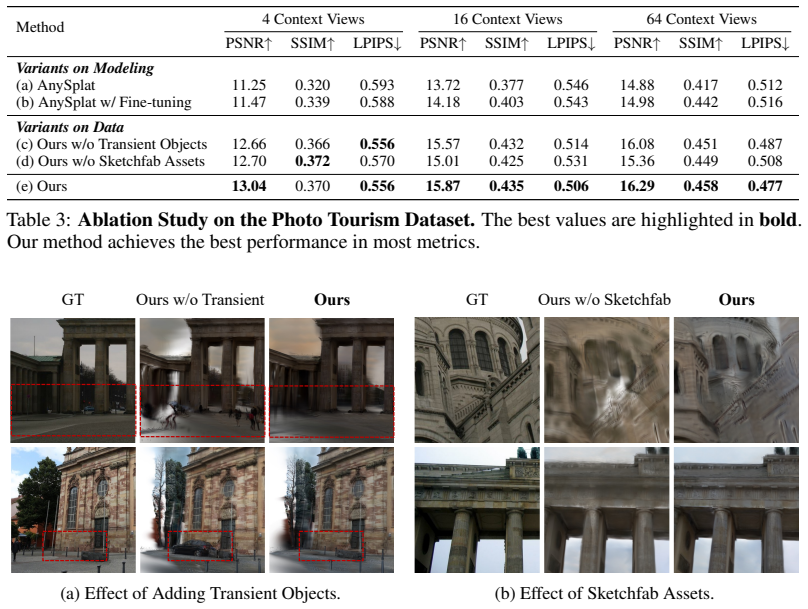
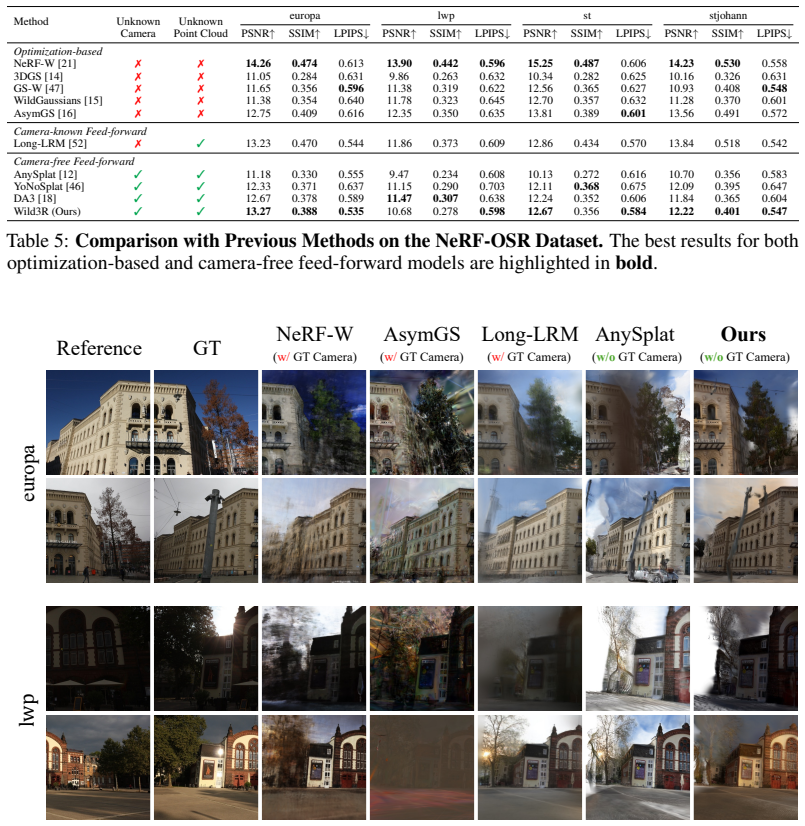
- The method outperforms existing feed-forward 3DGS approaches on real-world sparse collections.
- Results are competitive with traditional per-scene optimization methods.
- The approach removes the need for time-consuming optimization when reconstructing from casual photos.
Where Pith is reading between the lines
- Casual smartphone photos could become sufficient input for usable 3D models without expert capture or long compute.
- The same training strategy of conditioning on references while suppressing transients may transfer to other 3D representations.
- Larger or more diverse scene collections could further reduce remaining gaps with per-scene methods.
Load-bearing premise
The WildCity dataset supplies enough variety in viewpoints, illuminations, and transients at sufficient scale to train a model that generalizes to other real-world photo collections.
What would settle it
A controlled test on a new collection of photos with lighting or transient patterns absent from WildCity where the model produces view-inconsistent appearances or retains moving objects.
Figures







read the original abstract
Feed-forward 3D Gaussian Splatting (3DGS) removes the need for time-consuming per-scene optimization required by traditional 3DGS. However, existing feed-forward approaches struggle with real-world photo collections that include diverse lighting conditions and transient objects. In this paper, we present Wild3R, a feed-forward approach for unconstrained sparse photo collections. The main bottleneck is the lack of training data that provides multiple viewpoints, a variety of illuminations, and transient variations necessary for learning robust scene representations. To address this, we introduce the WildCity dataset, which comprises 200 scenes, 170 lighting conditions, and transient objects, resulting in 337,500 images in total. By leveraging the dataset, our model learns appearance consistency across viewpoints conditioned on reference views, while removing transient content. Extensive experiments demonstrate that our method outperforms existing feed-forward approaches and achieves results competitive with prior per-scene optimization-based methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Wild3R, a feed-forward method for 3D Gaussian Splatting from unconstrained sparse photo collections containing diverse lighting and transient objects. It introduces the WildCity dataset (200 scenes, 170 lighting conditions, transients, 337500 images) to enable learning of viewpoint-conditioned appearance consistency and transient removal, claiming outperformance over existing feed-forward approaches and competitiveness with per-scene optimization methods.
Significance. If the central claims hold with rigorous validation, the work would advance practical feed-forward 3D reconstruction by addressing real-world variations without per-scene optimization, potentially broadening applicability of 3DGS to casual photo collections.
major comments (1)
- [Abstract] Abstract: The claim that WildCity supplies independent multi-view, lighting, and transient variations sufficient for isolating appearance consistency and transient removal in a feed-forward objective is load-bearing for the outperformance and generalization assertions, yet the provided text gives no details on data collection protocol, independence of factors, or supervision signals for transient removal; without these, the training cannot be shown to disentangle the factors as required.
minor comments (1)
- The abstract references 'extensive experiments' demonstrating outperformance but provides no metrics, tables, baselines, or ablation details to allow assessment of whether reported gains are supported by data or affected by post-hoc choices.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for identifying the need for greater clarity in the abstract regarding the WildCity dataset. We address the comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that WildCity supplies independent multi-view, lighting, and transient variations sufficient for isolating appearance consistency and transient removal in a feed-forward objective is load-bearing for the outperformance and generalization assertions, yet the provided text gives no details on data collection protocol, independence of factors, or supervision signals for transient removal; without these, the training cannot be shown to disentangle the factors as required.
Authors: We agree that the abstract is concise and does not itself supply the requested protocol details. The full manuscript (Section 3) describes the WildCity construction: each of the 200 scenes was captured from multiple viewpoints under 170 distinct lighting conditions, with and without transient objects, using a protocol that isolates the three factors through repeated captures of the same geometry. Transient supervision is obtained from paired images of identical viewpoint and lighting that differ only in the presence of transients. We will revise the abstract to add one sentence summarizing this design, thereby making the load-bearing claim more self-contained while remaining within length constraints. revision: yes
Circularity Check
No significant circularity; derivation relies on external dataset and standard training
full rationale
The paper introduces the WildCity dataset as newly collected external data (200 scenes, 170 lighting conditions, transients) to train the feed-forward model for appearance consistency and transient removal. Performance claims rest on experiments comparing against other methods, with no quoted equations or steps showing a result defined in terms of itself, a fitted parameter renamed as prediction, or a load-bearing self-citation chain. The central premise (learning from multi-view/illumination/transient variations) is supported by the dataset's independent collection rather than reducing to internal definitions or prior self-work by construction. This matches the default case of a self-contained paper with no circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. L. Antequera, P. Gargallo, M. Hofinger, S. R. Bulo, Y . Kuang, and P. Kontschieder. Mapillary planet-scale depth dataset. InECCV, 2020
2020
-
[2]
Y . Cabon, N. Murray, and M. Humenberger. Virtual kitti 2.arXiv preprint arXiv:2001.10773, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[3]
X. Chen, Q. Zhang, X. Li, Y . Chen, Y . Feng, X. Wang, and J. Wang. Hallucinated neural radiance fields in the wild. InCVPR, 2022
2022
-
[4]
Couturier
A. Couturier. SceneCity.https://www.cgchan.com/
-
[5]
Dahmani, M
H. Dahmani, M. Bennehar, N. Piasco, L. Roldao, and D. Tsishkou. Swag: Splatting in the wild images with appearance-conditioned gaussians. InECCV, 2024
2024
-
[6]
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner. Scannet: Richly- annotated 3d reconstructions of indoor scenes. InCVPR, 2017
2017
-
[7]
Deitke, D
M. Deitke, D. Schwenk, J. Salvador, L. Weihs, O. Michel, E. VanderBilt, L. Schmidt, K. Ehsani, A. Kembhavi, and A. Farhadi. Objaverse: A universe of annotated 3d objects. InCVPR, 2023
2023
-
[8]
Fridovich-Keil, G
S. Fridovich-Keil, G. Meanti, F. R. Warburg, B. Recht, and A. Kanazawa. K-planes: Explicit radiance fields in space, time, and appearance. InCVPR, 2023
2023
-
[9]
Greff, F
K. Greff, F. Belletti, L. Beyer, C. Doersch, Y . Du, D. Duckworth, D. J. Fleet, D. Gnanapragasam, F. Golemo, C. Herrmann, T. Kipf, A. Kundu, D. Lagun, I. Laradji, H.-T. (Derek)Liu, H. Meyer, Y . Miao, D. Nowrouzezahrai, C. Oztireli, E. Pot, N. Radwan, D. Rebain, S. Sabour, M. S. M. Sajjadi, M. Sela, V . Sitzmann, A. Stone, D. Sun, S. V ora, Z. Wang, T. Wu...
2022
-
[10]
Huang, K
P.-H. Huang, K. Matzen, J. Kopf, N. Ahuja, and J.-B. Huang. Deepmvs: Learning multi-view stereopsis. InCVPR, 2018
2018
-
[11]
Jensen, A
R. Jensen, A. Dahl, G. V ogiatzis, E. Tola, and H. Aanæs. Large scale multi-view stereopsis evaluation. InCVPR, 2014
2014
-
[12]
Jiang, Y
L. Jiang, Y . Mao, L. Xu, T. Lu, K. Ren, Y . Jin, X. Xu, M. Yu, J. Pang, F. Zhao, et al. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.TOG, 2025
2025
-
[13]
Kassab, A
K. Kassab, A. Schnepf, J.-Y . Franceschi, L. Caraffa, J. Mary, and V . Gouet-Brunet. Refinedfields: Radiance fields refinement for planar scene representations.TMLR, 2025
2025
-
[14]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimkühler, and G. Drettakis. 3d gaussian splatting for real-time radiance field rendering. InTOG, 2023
2023
-
[15]
Kulhanek, S
J. Kulhanek, S. Peng, Z. Kukelova, M. Pollefeys, and T. Sattler. WildGaussians: 3D gaussian splatting in the wild. InNeurIPS, 2024
2024
-
[16]
C. Li, Z. Shi, Y . Lu, W. He, and X. Xu. Robust neural rendering in the wild with asymmetric dual 3d gaussian splatting. InNeurIPS, 2025
2025
-
[17]
Li and N
Z. Li and N. Snavely. Megadepth: Learning single-view depth prediction from internet photos. InCVPR, 2018
2018
-
[18]
H. Lin, S. Chen, J. H. Liew, D. Y . Chen, Z. Li, Y . Zhao, S. Peng, H. Guo, X. Zhou, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views. InICLR, 2026. 10
2026
-
[19]
L. Ling, Y . Sheng, Z. Tu, W. Zhao, C. Xin, K. Wan, L. Yu, Q. Guo, Z. Yu, Y . Lu, X. Li, X. Sun, R. Ashok, A. Mukherjee, H. Kang, X. Kong, G. Hua, T. Zhang, B. Benes, and A. Bera. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InCVPR, 2024
2024
-
[20]
I. Liu, L. Chen, Z. Fu, L. Wu, H. Jin, Z. Li, C. M. R. Wong, Y . Xu, R. Ramamoorthi, Z. Xu, and H. Su. Openillumination: A multi-illumination dataset for inverse rendering evaluation on real objects. InNeurIPS, 2023
2023
-
[21]
Martin-Brualla, N
R. Martin-Brualla, N. Radwan, M. S. M. Sajjadi, J. T. Barron, A. Dosovitskiy, and D. Duckworth. Nerf in the wild: Neural radiance fields for unconstrained photo collections. InCVPR, 2021
2021
-
[22]
Mildenhall, P
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. InECCV, 2020
2020
-
[23]
Moreau, R
A. Moreau, R. Shaw, M. Nazarczuk, J. Shin, T. Tanay, Z. Zhang, S. Xu, and E. Pérez-Pellitero. Off the grid: Detection of primitives for feed-forward 3d gaussian splatting. InCVPR, 2026
2026
-
[24]
X. Pan, N. Charron, Y . Yang, S. Peters, T. Whelan, C. Kong, O. Parkhi, R. Newcombe, and C. Y . Ren. Aria digital twin: A new benchmark dataset for egocentric 3d machine perception. In ICCV, 2023
2023
-
[25]
F. Pei, J. Bai, X. Feng, Z. Bi, K. Zhou, and H. Wu. Opensubstance: A high-quality measured dataset of multi-view and -lighting images and shapes. InICCV, 2025
2025
-
[26]
Reizenstein, R
J. Reizenstein, R. Shapovalov, P. Henzler, L. Sbordone, P. Labatut, and D. Novotny. Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. In ICCV, 2021
2021
-
[27]
Roberts, J
M. Roberts, J. Ramapuram, A. Ranjan, A. Kumar, M. A. Bautista, N. Paczan, R. Webb, and J. M. Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InICCV, 2021
2021
-
[28]
Rudnev, M
V . Rudnev, M. Elgharib, W. Smith, L. Liu, V . Golyanik, and C. Theobalt. Nerf for outdoor scene relighting. InECCV, 2022
2022
-
[29]
J. L. Schönberger and J.-M. Frahm. Structure-from-Motion Revisited. InCVPR, 2016
2016
-
[30]
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
B. Smart, C. Zheng, I. Laina, and V . A. Prisacariu. Splatt3r: Zero-shot gaussian splatting from uncalibrated image pairs.arXiv preprint arXiv:2408.13912, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Snavely, S
N. Snavely, S. M. Seitz, and R. Szeliski. Photo tourism: exploring photo collections in 3d.TOG, 2006
2006
-
[32]
The Replica Dataset: A Digital Replica of Indoor Spaces
J. Straub, T. Whelan, L. Ma, Y . Chen, E. Wijmans, S. Green, J. J. Engel, R. Mur-Artal, C. Ren, S. Verma, A. Clarkson, M. Yan, B. Budge, Y . Yan, X. Pan, J. Yon, Y . Zou, K. Leon, N. Carter, J. Briales, T. Gillingham, E. Mueggler, L. Pesqueira, M. Savva, D. Batra, H. M. Strasdat, R. D. Nardi, M. Goesele, S. Lovegrove, and R. Newcombe. The replica dataset:...
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[33]
J. Sun, X. Chen, Q. Wang, Z. Li, H. Averbuch-Elor, X. Zhou, and N. Snavely. Neural 3d reconstruction in the wild. InSIGGRAPH, 2022
2022
-
[34]
A. Szot, A. Clegg, E. Undersander, E. Wijmans, Y . Zhao, J. Turner, N. Maestre, M. Mukadam, D. Chaplot, O. Maksymets, A. Gokaslan, V . V ondrus, S. Dharur, F. Meier, W. Galuba, A. Chang, Z. Kira, V . Koltun, J. Malik, M. Savva, and D. Batra. Habitat 2.0: Training home assistants to rearrange their habitat. InNeurIPS, 2021
2021
-
[35]
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican, et al. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Toschi, R
M. Toschi, R. De Matteo, R. Spezialetti, D. De Gregorio, L. Di Stefano, and S. Salti. Relight my nerf: A dataset for novel view synthesis and relighting of real world objects. InCVPR, 2023. 11
2023
-
[37]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. Vggt: Visual geometry grounded transformer. InCVPR, 2025
2025
-
[38]
J. Wang, Q. Hu, C. Bao, Y . Zhu, H. Bao, Z. Cui, and G. Zhang. Lightcity: An urban dataset for outdoor inverse rendering and reconstruction under multi-illumination conditions. InICCV, 2025
2025
-
[39]
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud. Dust3r: Geometric 3d vision made easy. InCVPR, 2024
2024
-
[40]
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity.TIP, 2004
2004
-
[41]
Wu and T
L. Wu and T. Zhang. Wildsplatting: Unposed incremental 3d gaussian splatting reconstruction in the wild. InVRCAI, 2025
2025
-
[42]
H. Xia, Y . Fu, S. Liu, and X. Wang. Rgbd objects in the wild: Scaling real-world 3d object learning from rgb-d videos. InCVPR, 2024
2024
-
[43]
J. Xu, Y . Mei, and V . M. Patel. Wild-gs: Real-time novel view synthesis from unconstrained photo collections. InNeurIPS, 2024
2024
-
[44]
Y . Yang, S. Zhang, Z. Huang, Y . Zhang, and M. Tan. Cross-ray neural radiance fields for novel-view synthesis from unconstrained image collections. InICCV, 2023
2023
-
[45]
Y . Yao, Z. Luo, S. Li, J. Zhang, Y . Ren, L. Zhou, T. Fang, and L. Quan. Blendedmvs: A large-scale dataset for generalized multi-view stereo networks. InCVPR, 2020
2020
-
[46]
B. Ye, B. Chen, H. Xu, D. Barath, and M. Pollefeys. Yonosplat: You only need one model for feedforward 3d gaussian splatting. InICLR, 2026
2026
-
[47]
Zhang, C
D. Zhang, C. Wang, W. Wang, P. Li, M. Qin, and H. Wang. Gaussian in the wild: 3d gaussian splatting for unconstrained image collections. InECCV, 2024
2024
-
[48]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018
2018
-
[49]
Zhang, J
S. Zhang, J. Wang, Y . Xu, N. Xue, C. Rupprecht, X. Zhou, Y . Shen, and G. Wetzstein. Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views. In CVPR, 2025
2025
-
[50]
Zhang, X
X. Zhang, X. Zheng, Y . Yin, T. Zhao, K. Tang, M. B. Mi, Z. Xu, and D. Z. Chen. Anchorsplat: Feed-forward 3d gaussian splatting with 3d geometric priors. InCVPR, 2026
2026
-
[51]
Zheng, A
Y . Zheng, A. W. Harley, B. Shen, G. Wetzstein, and L. J. Guibas. Pointodyssey: A large-scale synthetic dataset for long-term point tracking. InICCV, 2023
2023
-
[52]
Ziwen, H
C. Ziwen, H. Tan, K. Zhang, S. Bi, F. Luan, Y . Hong, L. Fuxin, and Z. Xu. Long-lrm: Long-sequence large reconstruction model for wide-coverage gaussian splats. InICCV, 2025. 12 A Implementation Details Scene and Camera Setup.During the manual selection of buildings for scene generation, we generally maintained a distance of at least 20 meters between the...
2025
-
[53]
Please addt p,t v,t s,t b, while maintaining the geometry and lightness/darkness
If there are roads where people and cars can be placed, we use: “Please addt p,t v,t s,t b, while maintaining the geometry and lightness/darkness.”
-
[54]
Please add ˜tb, while maintaining the geometry and lightness/darkness
If not, we use: “Please add ˜tb, while maintaining the geometry and lightness/darkness.” where the words tp, tv, ts, tb, and ˜tb are sampled from Tp, Tv, Ts, Tb, and eTb as in Table 4, respectively. We classify each image into the two types above, using another variant of Gemini (gemini-3-flash-preview) with a predefined promptq, as shown in Table 4. Vali...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.