Efficient Traffic Prediction at Scale: A Systematic Study of STGCN Architectural Depth
Pith reviewed 2026-06-27 17:31 UTC · model grok-4.3
The pith
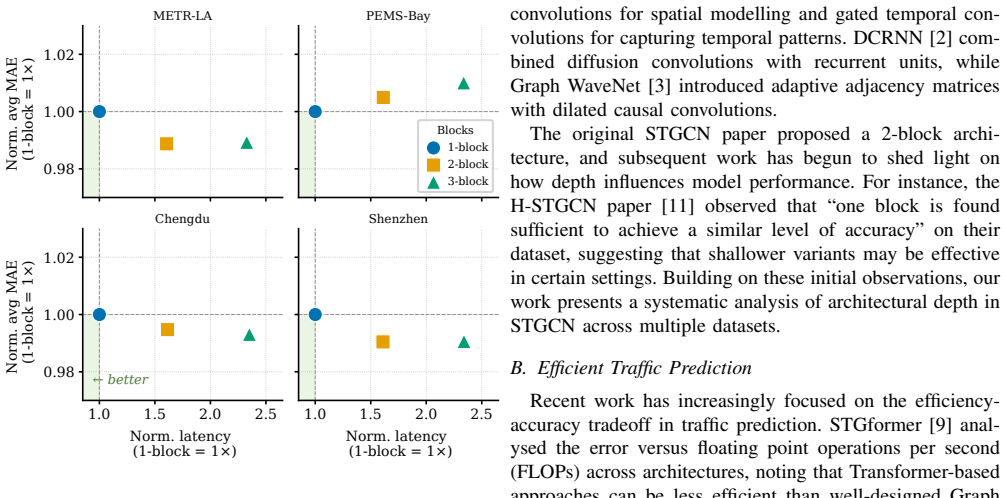
The standard two-block STGCN is over-parameterized, as the single-block version matches its accuracy on short-term traffic forecasts while cutting CPU latency by 61 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The single-block STGCN architecture achieves optimal performance for short-term prediction on three of four datasets while incurring only marginal degradation at longer horizons, whereas the two-block variant incurs 61 percent higher CPU inference latency and 37 percent lower throughput, and the three-block architecture offers no favorable tradeoff.
What carries the argument
STGCN block variants, specifically the 1-block, 2-block, and 3-block configurations compared under identical training and evaluation conditions.
If this is right
- For short-term traffic prediction the one-block model can replace the standard two-block design in most cases.
- The added computational cost of extra blocks is not justified by accuracy gains on the tested data.
- Practitioners can reduce inference latency substantially by adopting the lighter architecture in resource-limited ITS deployments.
- New efficiency methods should be benchmarked against the one-block baseline to avoid overstating improvements.
Where Pith is reading between the lines
- The same pattern of diminishing returns from added blocks may appear in other spatio-temporal graph models beyond STGCN.
- An adaptive choice of block count based on forecast horizon could yield further efficiency without changing the core architecture.
- This finding points to a broader opportunity to test whether default depths in graph time-series models are routinely excessive.
Load-bearing premise
The four traffic datasets are representative enough that performance differences can be attributed to block depth rather than dataset quirks or training details.
What would settle it
A new traffic dataset on which the two-block model consistently beats the one-block by more than 2 percent relative error at every horizon, while keeping the same latency penalty, would falsify the over-parameterization claim.
Figures
read the original abstract
Spatio-temporal graph neural networks (STGNNs) have become the dominant approach for traffic prediction, yet their computational requirements pose challenges for practical deployment in intelligent transportation systems (ITS). While recent work has proposed efficient alternatives to STGNNs, a fundamental question remains unexplored: are these architectures themselves over-parameterised? We examine this question using the Spatio-Temporal Graph Convolutional Network (STGCN), one of the most widely adopted models in this domain. Through systematic experiments across four diverse traffic datasets, we compare 1-block, 2-block (standard), and 3-block STGCN variants. Our findings reveal that the single-block architecture achieves optimal performance for short-term prediction (10 mins) on three of four datasets, while incurring only marginal degradation ($\leq$1.8% relative error) at longer horizons. Crucially, the 2-block variant incurs 61% higher CPU inference latency and 37% lower throughput relative to 1-block -- substantial overhead for resource-constrained ITS deployment. The 3-block architecture offers no favourable tradeoff, more than doubling computational cost for $<$0.5% relative improvement. These results suggest that the default 2-block STGCN may be over-parameterised for many applications, with implications for both practitioners deploying traffic prediction systems and researchers benchmarking efficiency-focused methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a systematic empirical comparison of 1-block, 2-block (standard), and 3-block variants of the Spatio-Temporal Graph Convolutional Network (STGCN) on four traffic datasets. It claims that the single-block architecture achieves optimal short-term (10 min) prediction performance on three of four datasets, with only marginal degradation (≤1.8% relative error) at longer horizons, while the 2-block variant incurs 61% higher CPU inference latency and 37% lower throughput; the 3-block variant offers no favorable tradeoff.
Significance. If the performance differences can be causally attributed to architectural depth under controlled conditions, the result would be significant for efficient deployment of traffic prediction in intelligent transportation systems, indicating that default STGCN configurations may be over-parameterized and providing concrete efficiency baselines for future work on resource-constrained models.
major comments (2)
- [Abstract / Experimental Setup] Abstract and experimental description: the reported optimality of the 1-block model and the efficiency gaps rest on the assumption that the 1/2/3-block variants were trained and evaluated under identical conditions (shared hyperparameters, data splits, optimizer settings, and early-stopping criteria). No explicit confirmation or methods subsection verifies this shared protocol, which is load-bearing for attributing differences to depth rather than confounding factors.
- [Abstract] Abstract: quantitative outcomes (performance, latency, throughput) are presented without statistical significance tests, error bars, standard deviations across multiple runs, or details on hyperparameter controls and data preprocessing, leaving the central empirical claims only partially supported.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to strengthen the presentation of our experimental protocol and results.
read point-by-point responses
-
Referee: [Abstract / Experimental Setup] Abstract and experimental description: the reported optimality of the 1-block model and the efficiency gaps rest on the assumption that the 1/2/3-block variants were trained and evaluated under identical conditions (shared hyperparameters, data splits, optimizer settings, and early-stopping criteria). No explicit confirmation or methods subsection verifies this shared protocol, which is load-bearing for attributing differences to depth rather than confounding factors.
Authors: We confirm that the 1-block, 2-block, and 3-block STGCN variants were trained and evaluated under fully identical conditions, including the same hyperparameters, data splits, optimizer settings, and early-stopping criteria. This shared protocol is described in the experimental setup section of the manuscript. To make the shared conditions fully explicit and address the concern, we will add a dedicated subsection in the Methods explicitly verifying the identical training and evaluation protocol across variants. revision: yes
-
Referee: [Abstract] Abstract: quantitative outcomes (performance, latency, throughput) are presented without statistical significance tests, error bars, standard deviations across multiple runs, or details on hyperparameter controls and data preprocessing, leaving the central empirical claims only partially supported.
Authors: Details on hyperparameter controls and data preprocessing are already provided in the experimental section. We acknowledge that the current version does not report error bars, standard deviations from multiple runs, or formal statistical significance tests. We will add these elements (standard deviations across runs and significance testing where appropriate) to the revised manuscript to more robustly support the quantitative claims. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivations
full rationale
The paper conducts direct experimental comparisons of 1-block, 2-block, and 3-block STGCN variants across four traffic datasets, reporting measured performance (MAE/RMSE) and efficiency metrics (latency, throughput). No equations, predictions, or first-principles derivations are present that could reduce to fitted inputs or self-citations by construction. All claims rest on observed differences under the stated experimental protocol, making the work self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Traffic networks exhibit spatial dependencies capturable by graph convolutions and temporal dependencies capturable by 1D convolutions.
Reference graph
Works this paper leans on
-
[1]
Spatio-temporal graph convolutional networks: a deep learning framework for traffic forecasting,
B. Yu, H. Yin, and Z. Zhu, “Spatio-temporal graph convolutional networks: a deep learning framework for traffic forecasting,” in Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, July 2018, pp. 3634–3640
2018
-
[2]
Diffusion convolutional recurrent neural network: data-driven traffic forecasting,
Y . Li, R. Yu, C. Shahabi, and Y . Liu, “Diffusion convolutional recurrent neural network: data-driven traffic forecasting,” inInternational Conference on Learning Representations (ICLR), 2018. [Online]. Available: https://openreview.net/forum?id=SJiHXGW AZ
2018
-
[3]
Graph wavenet for deep spatial-temporal graph modeling,
Z. Wu, S. Pan, G. Long, J. Jiang, and C. Zhang, “Graph wavenet for deep spatial-temporal graph modeling,” inProceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI), Macao, China, August 2019, pp. 1907–1913
2019
-
[4]
Graph neural network for traffic forecasting: a survey,
W. Jiang and J. Luo, “Graph neural network for traffic forecasting: a survey,”Expert Systems with Applications, vol. 207, p. 117921, 2022
2022
-
[5]
Evaluations of the connected vehicle and automation initiatives,
Federal Highway Administration, “Evaluations of the connected vehicle and automation initiatives,” U.S. Department of Transportation, Tech. Rep. FHW A-HRT-17-007, 2017. [Online]. Available: fhwa.dot.gov/publications/research/randt/evaluations/17007/
2017
-
[6]
Citywide traffic volume estimation using trajectory data,
X. Zhan, Y . Zheng, X. Yi, and S. V . Ukkusuri, “Citywide traffic volume estimation using trajectory data,”IEEE Transactions on Knowledge and Data Engineering, vol. 29, no. 2, pp. 272–285, 2017
2017
-
[7]
Real time urban traffic prediction using RFID and a hybrid LSTM random forest model,
O. Khattab, B. Saravana Balaji, F. Alghadhoori, F. AlMazyad, M. Al- Dousari, A. Al-Ameeri, and M. O. Al-Kadri, “Real time urban traffic prediction using RFID and a hybrid LSTM random forest model,” Scientific Reports, vol. 15, no. 1, p. 43722, 2025
2025
-
[8]
Do we really need graph neural networks for traffic forecasting?
X. Liu, Y . Liang, C. Huang, H. Hu, Y . Cao, B. Hooi, and R. Zim- mermann, “Do we really need graph neural networks for traffic forecasting?”arXiv preprint arXiv:2301.12603, 2023
-
[9]
STGformer: efficient spatiotemporal graph transformer for traffic forecasting,
H. Wang, J. Chen, T. Pan, Z. Dong, L. Zhang, R. Jiang, and X. Song, “STGformer: efficient spatiotemporal graph transformer for traffic forecasting,”arXiv preprint arXiv:2410.00385, 2024
-
[10]
Efficient traffic prediction through spatio-temporal distillation,
Q. Zhang, X. Gao, H. Wang, S. M. Yiu, and H. Yin, “Efficient traffic prediction through spatio-temporal distillation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 1, 2025, pp. 1093–1101
2025
-
[11]
R. Dai, S. Xu, Q. Gu, C. Ji, and K. Liu, “Hybrid spatio- temporal graph convolutional network: improving traffic prediction with navigation data,” inProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD), Virtual Event, CA, USA, 2020, pp. 3074–3082. [Online]. Available: https://doi.org/10.1145/3394486.3403358
-
[12]
LargeST: a benchmark dataset for large-scale traffic forecasting,
X. Liu, Y . Xia, Y . Liang, J. Hu, Y . Wang, L. Bai, C. Huang, Z. Liu, B. Hooi, and R. Zimmermann, “LargeST: a benchmark dataset for large-scale traffic forecasting,”Advances in Neural Information Processing Systems, vol. 36, pp. 75 354–75 371, 2023
2023
-
[13]
X. Luo, C. Zhu, D. Zhang, and Q. Li, “STG4Traffic: A survey and benchmark of spatial-temporal graph neural networks for traffic prediction,”arXiv preprint arXiv:2307.00495, 2023
-
[14]
A survey on modern deep neural network for traffic prediction: trends, methods and challenges,
D. A. Tedjopurnomo, Z. Bao, B. Zheng, F. M. Choudhury, and A. K. Qin, “A survey on modern deep neural network for traffic prediction: trends, methods and challenges,”IEEE Transactions on Knowledge and Data Engineering, vol. 34, no. 4, pp. 1544–1561, 2022
2022
-
[15]
PyTorch: an imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “PyTorch: an imperative style, high-performance deep learning library,”Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[16]
THOP: PyTorch-OpCounter,
L. Zhu, “THOP: PyTorch-OpCounter,” 2018. [Online]. Available: https://github.com/Lyken17/pytorch-OpCounter
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.