Securing LLM-Agent Long-Term Memory Against Poisoning: Non-Malleable, Origin-Bound Authority with Machine-Checked Guarantees
Pith reviewed 2026-06-25 23:38 UTC · model grok-4.3
The pith
Write-time origin binding with non-malleable authority is necessary and sufficient to block memory poisoning in LLM agents even under laundering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
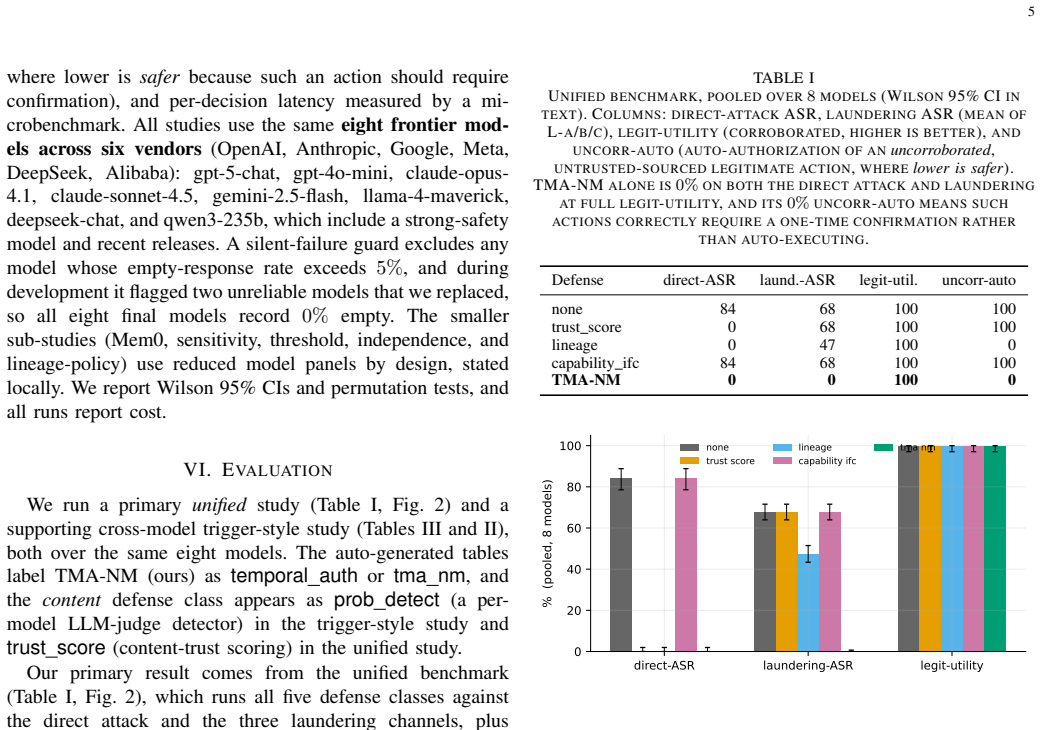
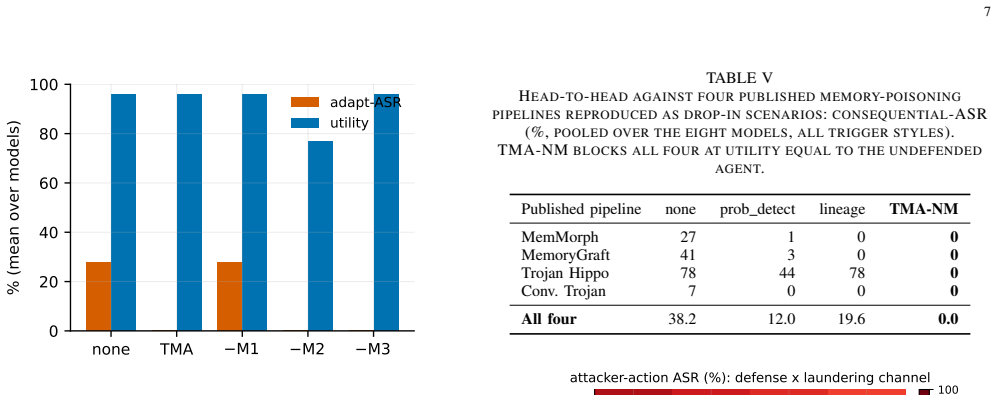
No content- or lineage-based defense is sound under laundering (T1), write-time origin binding is necessary (T2), and non-malleable origin-bound authority with Sybil-resistant corroboration-gated elevation is sufficient (T3). TMA-NM instantiates non-malleable information-flow control for LLM-agent memory and reaches 0% attack success on both direct and laundering attacks across all tested models and channels at full legitimate utility.
What carries the argument
TMA-NM (Tamper-evident Memory Authority, Non-Malleable), which enforces write-time origin binding and applies non-malleable information-flow control to prevent laundering of memory authority.
If this is right
- Existing content- and lineage-based defenses reach up to 68% success on laundering attacks.
- TMA-NM blocks both direct poisoning and laundering across eight frontier models.
- Legitimate agent utility remains unchanged under the new authority mechanism.
- Machine-checked TLA+ specifications confirm the separation theorems for the memory pipeline.
Where Pith is reading between the lines
- The same origin-binding principle could apply to other forms of persistent state that agents accumulate across sessions.
- Agent frameworks may need to expose explicit write-time origin metadata rather than relying on post-hoc trust scoring.
- Production deployments could adopt corroboration gating as a default for any memory that can trigger external actions.
Load-bearing premise
The TLA+ models accurately capture the full write-retrieve-act pipeline and all relevant laundering channels in real LLM agents, and the cross-model benchmark is representative without unstated exclusions or model-specific artifacts that would alter the 0% result.
What would settle it
Observing a laundering channel or attack vector that produces non-zero success against TMA-NM in an expanded set of models or real agent deployments would falsify the sufficiency claim.
Figures


read the original abstract
LLM agents increasingly rely on persistent long-term memory, which creates a critical vulnerability that we study here: memory poisoning. An adversary can store untrusted content in one session that later steers a consequential action, such as a payment, a setting change, or data exfiltration, in a future session. Existing defenses base a memory item's authority to act on either its content (detection or trust-scoring) or its derivation history (lineage). We show that both signals are malleable. An attacker can launder an untrusted origin through three channels specific to LLM agents: the agent's own summarization, a trusted-tool echo, and manufactured corroboration. Each makes the content look benign and breaks or flips its derivation edge to ``trusted.'' We formalize malleability for the memory write-retrieve-act pipeline and prove a machine-checked separation theorem. No content- or lineage-based defense is sound under laundering (T1), write-time origin binding is necessary (T2), and non-malleable origin-bound authority with Sybil-resistant corroboration-gated elevation is sufficient (T3). Our construction, TMA-NM (Tamper-evident Memory Authority, Non-Malleable), instantiates non-malleable information-flow control (IFC) for LLM-agent memory. A cross-defense, cross-attack, and cross-model benchmark over eight frontier models shows that existing defenses fail exactly where the theory predicts (up to 68% laundering attack-success), while TMA-NM reaches 0% attack success on both direct and laundering attacks across all models and channels, at full legitimate utility. We release the benchmark, harness, and machine-checked TLA+ models to support reproducibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that content- and lineage-based defenses against memory poisoning in LLM-agent long-term memory are unsound because an adversary can launder untrusted origins through three agent-specific channels (summarization, trusted-tool echo, manufactured corroboration). It proves via machine-checked TLA+ theorems that no such defense is sound under laundering (T1), write-time origin binding is necessary (T2), and non-malleable origin-bound authority with Sybil-resistant corroboration-gated elevation (TMA-NM) is sufficient (T3). A cross-model benchmark over eight frontier models reports that existing defenses reach up to 68% laundering attack success while TMA-NM achieves 0% on both direct and laundering attacks at full legitimate utility; the TLA+ models, benchmark harness, and code are released.
Significance. If the TLA+ models faithfully capture the write-retrieve-act pipeline and the benchmark is representative, the work supplies the first machine-checked separation theorems for this vulnerability class together with a concrete, non-malleable construction that demonstrably blocks the modeled attacks. The explicit release of the TLA+ specifications and reproducible harness is a clear strength that enables external verification and extension.
major comments (2)
- [TLA+ models and theorems T1–T3] TLA+ models (theorems T1–T3): the separation results rest on a state-machine abstraction of the LLM that enumerates exactly three laundering channels. The manuscript must explicitly argue why this abstraction is complete with respect to real frontier-model behaviors (e.g., multi-hop tool chaining, implicit retrieval-triggered rewriting, or nondeterministic output that bypasses modeled edges); without such justification the necessity claim (T2) and sufficiency claim (T3) remain conditional on the modeled channels only.
- [Benchmark evaluation] Benchmark section: the abstract states 0% attack success for TMA-NM and up to 68% for baselines across eight models, yet the main text must report the exact number of trials per (model, attack, channel) cell, the precise laundering implementations, and whether any runs were excluded post-hoc. Absent these details the empirical support for the “0% across all models and channels” claim cannot be assessed for robustness.
minor comments (2)
- [Evaluation metrics] The utility metric (“full legitimate utility”) is referenced but not defined with concrete success criteria or measurement protocol; add an explicit definition and table of per-task utility numbers.
- [Formal model] Notation for the three laundering channels is introduced in the abstract but should be given a single, consistently used label (e.g., L1–L3) in the formal model section to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the manuscript as indicated.
read point-by-point responses
-
Referee: [TLA+ models and theorems T1–T3] TLA+ models (theorems T1–T3): the separation results rest on a state-machine abstraction of the LLM that enumerates exactly three laundering channels. The manuscript must explicitly argue why this abstraction is complete with respect to real frontier-model behaviors (e.g., multi-hop tool chaining, implicit retrieval-triggered rewriting, or nondeterministic output that bypasses modeled edges); without such justification the necessity claim (T2) and sufficiency claim (T3) remain conditional on the modeled channels only.
Authors: We agree that an explicit argument for the completeness of the three-channel abstraction is needed to support the necessity (T2) and sufficiency (T3) claims. In the revised manuscript we will add a new subsection (Section 4.3) that justifies the abstraction by showing that the three channels correspond to the fundamental operations in the write-retrieve-act pipeline: summarization covers implicit rewriting and retrieval-triggered generation; trusted-tool echo subsumes multi-hop tool chaining and external data ingestion; and manufactured corroboration addresses self-reinforcing or multi-agent feedback loops. We will further note that the TLA+ model already incorporates nondeterminism to capture output variability, and that any unmodeled behavior would still be subject to the same information-flow constraints. While the abstraction cannot anticipate every future model capability, it is complete for the class of behaviors exhibited by current frontier models under the stated pipeline. revision: yes
-
Referee: [Benchmark evaluation] Benchmark section: the abstract states 0% attack success for TMA-NM and up to 68% for baselines across eight models, yet the main text must report the exact number of trials per (model, attack, channel) cell, the precise laundering implementations, and whether any runs were excluded post-hoc. Absent these details the empirical support for the “0% across all models and channels” claim cannot be assessed for robustness.
Authors: We acknowledge that the main text currently presents aggregate results and that the requested per-cell statistics, implementation details, and exclusion criteria should be reported explicitly for robustness assessment. In the revision we will expand Section 6 to include: (i) the exact trial count (50 independent trials per model-attack-channel combination, for a total of 9,600 runs), (ii) precise pseudocode and parameter settings for each laundering channel implementation, and (iii) an explicit statement that no runs were excluded post-hoc. These details already appear in the released benchmark harness and appendix; we will move the key figures and descriptions into the main body. revision: yes
Circularity Check
No circularity; machine-checked TLA+ theorems are externally verifiable and independent of paper claims.
full rationale
The core claims (T1: content/lineage defenses unsound under laundering; T2: origin binding necessary; T3: TMA-NM sufficient) rest on a released TLA+ specification of the write-retrieve-act pipeline and three laundering channels, which is machine-checked and externally reproducible. This satisfies the criterion for independent support via formal verification. No self-definitional reductions, fitted inputs renamed as predictions, load-bearing self-citations, or ansatz smuggling occur. The empirical 0% results validate the modeled attacks without reducing to internal parameter fits. The skeptic concern about model completeness is a correctness issue, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Malleability of content- and lineage-based signals can be formalized for the write-retrieve-act pipeline and separated into necessary and sufficient conditions via T1-T3.
invented entities (1)
-
TMA-NM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Memgpt: Towards llms as operating systems,
C. Packer, S. Wooders, K. Lin, V . Fang, S. G. Patil, I. Stoica, and J. E. Gonzalez, “Memgpt: Towards llms as operating systems,” 2024. [Online]. Available: https://arxiv.org/abs/2310.08560
Pith/arXiv arXiv 2024
-
[2]
Mem0: Building production-ready ai agents with scalable long-term memory,
P. Chhikara, D. Khant, S. Aryan, T. Singh, and D. Yadav, “Mem0: Building production-ready ai agents with scalable long-term memory,”
-
[3]
Available: https://arxiv.org/abs/2504.19413
[Online]. Available: https://arxiv.org/abs/2504.19413
-
[4]
Generative agents: Interactive simulacra of human behavior,
J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” 2023. [Online]. Available: https://arxiv.org/abs/2304.03442
Pith/arXiv arXiv 2023
-
[5]
Memmachine: A ground-truth-preserving memory system for personalized ai agents,
S. Wang, E. Yu, O. Love, T. Zhang, T. Wong, S. Scargall, and C. Fan, “Memmachine: A ground-truth-preserving memory system for personalized ai agents,” 2026. [Online]. Available: https://arxiv.org/abs/2604.04853
Pith/arXiv arXiv 2026
-
[6]
Hidden in memory: Sleeper memory poisoning in llm agents,
S. Pulipaka, S. Hlebik, L. Raghav, S. Abdelnabi, V . Raina, I. Sheth, and M. Fritz, “Hidden in memory: Sleeper memory poisoning in llm agents,” 2026. [Online]. Available: https://arxiv.org/abs/2605.15338
Pith/arXiv arXiv 2026
-
[7]
Sleeper agents: Training deceptive llms that persist through safety training,
E. Hubinger, C. Denison, J. Mu, M. Lambert, M. Tong, M. MacDiarmid, T. Lanham, D. M. Ziegler, T. Maxwell, N. Cheng, A. Jermyn, A. Askell, A. Radhakrishnan, C. Anil, D. Duvenaud, D. Ganguli, F. Barez, J. Clark, K. Ndousse, K. Sachan, M. Sellitto, M. Sharma, N. DasSarma, R. Grosse, S. Kravec, Y . Bai, Z. Witten, M. Favaro, J. Brauner, H. Karnofsky, P. Chris...
Pith/arXiv arXiv 2024
-
[8]
From storage to steering: Memory control flow attacks on llm agents,
Z. Xu, X. Zhu, Y . Yao, M. Xue, and Y . Song, “From storage to steering: Memory control flow attacks on llm agents,” 2026. [Online]. Available: https://arxiv.org/abs/2603.15125
Pith/arXiv arXiv 2026
-
[9]
W. Zou, R. Geng, B. Wang, and J. Jia, “Poisonedrag: Knowledge corruption attacks to retrieval-augmented generation of large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2402.07867
arXiv 2024
-
[10]
Memory injection attacks on llm agents via query-only interaction,
S. Dong, S. Xu, P. He, Y . Li, J. Tang, T. Liu, H. Liu, and Z. Xiang, “Memory injection attacks on llm agents via query-only interaction,”
-
[11]
Available: https://arxiv.org/abs/2503.03704
[Online]. Available: https://arxiv.org/abs/2503.03704
-
[12]
Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases,
Z. Chen, Z. Xiang, C. Xiao, D. Song, and B. Li, “Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases,”
-
[13]
Available: https://arxiv.org/abs/2407.12784
[Online]. Available: https://arxiv.org/abs/2407.12784
-
[14]
Watch out for your agents! investigating backdoor threats to llm-based agents,
W. Yang, X. Bi, Y . Lin, S. Chen, J. Zhou, and X. Sun, “Watch out for your agents! investigating backdoor threats to llm-based agents,” 2024. [Online]. Available: https://arxiv.org/abs/2402.11208
arXiv 2024
-
[15]
K. Chu, “A systematic survey of security threats and defenses in llm-based ai agents: A layered attack surface framework,” 2026. [Online]. Available: https://arxiv.org/abs/2604.23338
Pith/arXiv arXiv 2026
-
[16]
Z. Lin, X. Hao, R. Fu, S. Cui, K. Chen, C. Li, Z. Li, and F. Xiong, “A survey on long-term memory security in llm agents: Attacks, defenses, and governance across the memory lifecycle,” 2026. [Online]. Available: https://arxiv.org/abs/2604.16548
Pith/arXiv arXiv 2026
-
[17]
Memlineage: Lineage-guided enforcement for llm agent memory,
C. Ouyang and R. Hou, “Memlineage: Lineage-guided enforcement for llm agent memory,” 2026. [Online]. Available: https://arxiv.org/abs/ 2605.14421
Pith/arXiv arXiv 2026
-
[18]
Nonmalleable information flow control,
E. Cecchetti, A. C. Myers, and O. Arden, “Nonmalleable information flow control,” inProc. ACM SIGSAC Conf. on Computer and Commu- nications Security (CCS), 2017, arXiv:1708.08596
arXiv 2017
-
[19]
Security analysis of agentic ai communication protocols: A comparative evaluation,
Y . Louck, A. Dvir, and A. Stulman, “Security analysis of agentic ai communication protocols: A comparative evaluation,”ACM Transactions on AI Security and Privacy, 2025
2025
-
[20]
Improving google a2a protocol: Protecting sensitive data and mitigating unintended harms in multi-agent systems,
Y . Louck, A. Stulman, and A. Dvir, “Improving google a2a protocol: Protecting sensitive data and mitigating unintended harms in multi-agent systems,”ACM Transactions on Software Engineering and Methodology, 2025. 12
2025
-
[21]
V . P. Bhardwaj, “Superlocalmemory: Privacy-preserving multi-agent memory with bayesian trust defense against memory poisoning,” 2026. [Online]. Available: https://arxiv.org/abs/2603.02240
arXiv 2026
-
[22]
Memmorph: Tool hijacking in llm agents via memory poisoning,
X. Zhang, Y . Zheng, Z. Xu, K. Zhou, B. Shen, H. Ou, T. Zhang, and K.-Y . Lam, “Memmorph: Tool hijacking in llm agents via memory poisoning,” 2026. [Online]. Available: https://arxiv.org/abs/2605.26154
Pith/arXiv arXiv 2026
-
[23]
Memorygraft: Persistent compromise of llm agents via poisoned experience retrieval,
S. S. Srivastava and H. He, “Memorygraft: Persistent compromise of llm agents via poisoned experience retrieval,” 2025. [Online]. Available: https://arxiv.org/abs/2512.16962
arXiv 2025
-
[24]
Trojan hippo: Weaponizing agent memory for data exfiltration,
D. Das, J. Piet, D. Kaviani, L. Beurer-Kellner, F. Tram `er, and D. Wagner, “Trojan hippo: Weaponizing agent memory for data exfiltration,” 2026. [Online]. Available: https://arxiv.org/abs/2605.01970
Pith/arXiv arXiv 2026
-
[25]
Hijacking agent memory: Stealthy trojan attacks through conversational interaction,
H. Wang, S. Yang, Y . Chen, and P. Liu, “Hijacking agent memory: Stealthy trojan attacks through conversational interaction,” 2026. [Online]. Available: https://arxiv.org/abs/2605.29960
Pith/arXiv arXiv 2026
-
[26]
Defeating prompt injections by design,
E. Debenedetti, I. Shumailov, T. Fan, J. Hayes, N. Carlini, D. Fabian, C. Kern, C. Shi, A. Terzis, and F. Tram `er, “Defeating prompt injections by design,” 2025. [Online]. Available: https://arxiv.org/abs/2503.18813
Pith/arXiv arXiv 2025
-
[27]
Securing ai agents with information-flow control,
M. Costa, B. K ¨opf, A. Kolluri, A. Paverd, M. Russinovich, A. Salem, S. Tople, L. Wutschitz, and S. Zanella-B ´eguelin, “Securing ai agents with information-flow control,” 2025. [Online]. Available: https://arxiv.org/abs/2505.23643
Pith/arXiv arXiv 2025
-
[28]
Ghost in the agent: Redefining information flow tracking for llm agents,
Y . Cai, W. Tang, C. Wen, and S. Qin, “Ghost in the agent: Redefining information flow tracking for llm agents,” 2026. [Online]. Available: https://arxiv.org/abs/2604.23374
Pith/arXiv arXiv 2026
-
[29]
Z. Fei, H. Fei, X. Wang, Y . Yang, P. Gope, B. Sikdar, and Y . Zhang, “Selection integrity for llm graph memory: An accumulability criterion for information-flow-blind retrieval,” 2026. [Online]. Available: https://arxiv.org/abs/2606.12290
Pith/arXiv arXiv 2026
-
[30]
Z. Ji, D. Wu, W. Jiang, P. Ma, Z. Li, Y . Gao, S. Wang, and Y . Li, “Taming various privilege escalation in llm-based agent systems: A mandatory access control framework,” 2026. [Online]. Available: https://arxiv.org/abs/2601.11893
arXiv 2026
-
[31]
N. Acharya and G. K. Gupta, “A formal security framework for mcp-based ai agents: Threat taxonomy, verification models, and defense mechanisms,” 2026. [Online]. Available: https://arxiv.org/abs/ 2604.05969
Pith/arXiv arXiv 2026
-
[32]
Mesh memory protocol: Semantic infrastructure for multi-agent llm systems,
H. Xu, “Mesh memory protocol: Semantic infrastructure for multi-agent llm systems,” 2026. [Online]. Available: https://arxiv.org/abs/2604.19540
Pith/arXiv arXiv 2026
-
[33]
Memory poisoning attack and defense on memory based llm-agents,
B. D. Sunil, I. Sinha, P. Maheshwari, S. Todmal, S. Mallik, and S. Mishra, “Memory poisoning attack and defense on memory based llm-agents,” 2026. [Online]. Available: https://arxiv.org/abs/2601.05504
arXiv 2026
-
[34]
Drunkagent: Stealthy memory corruption in llm-powered recommender agents,
S. Yang, Z. Hu, X. Li, C. Wang, T. Yu, X. Xu, L. Zhu, and L. Yao, “Drunkagent: Stealthy memory corruption in llm-powered recommender agents,” 2025. [Online]. Available: https://arxiv.org/abs/2503.23804
arXiv 2025
-
[35]
Trustrag: Enhancing robustness and trustworthiness in retrieval-augmented generation,
H. Zhou, K.-H. Lee, Z. Zhan, Y . Chen, Z. Li, Z. Wang, H. Haddadi, and E. Yilmaz, “Trustrag: Enhancing robustness and trustworthiness in retrieval-augmented generation,” 2025. [Online]. Available: https://arxiv.org/abs/2501.00879
arXiv 2025
-
[36]
J. Qian, “Visual inception: Compromising long-term planning in agentic recommenders via multimodal memory poisoning,” 2026. [Online]. Available: https://arxiv.org/abs/2604.16966
Pith/arXiv arXiv 2026
-
[37]
Integrity considerations for secure computer systems,
K. J. Biba, “Integrity considerations for secure computer systems,” Technical Report MTR-3153 / ESD-TR-76-372, The MITRE Corporation, 1977
1977
-
[38]
A comparison of commercial and military computer security policies,
D. D. Clark and D. R. Wilson, “A comparison of commercial and military computer security policies,” inProc. IEEE Symp. on Security and Privacy (S&P), 1987, pp. 184–194
1987
-
[39]
A lattice model of secure information flow,
D. E. Denning, “A lattice model of secure information flow,”Commu- nications of the ACM, vol. 19, no. 5, pp. 236–243, 1976
1976
-
[40]
A decentralized model for information flow control,
A. C. Myers and B. Liskov, “A decentralized model for information flow control,” inProc. ACM Symp. on Operating Systems Principles (SOSP), 1997, pp. 129–142
1997
-
[41]
The sybil attack,
J. R. Douceur, “The sybil attack,” inProc. 1st Int. Workshop on Peer- to-Peer Systems (IPTPS), LNCS 2429, 2002, pp. 251–260
2002
-
[42]
The foundations for provenance on the web,
L. Moreau, “The foundations for provenance on the web,”Foundations and Trends in Web Science, vol. 2, no. 2–3, pp. 99–241, 2010. APPENDIXA BASELINEFIDELITY Each baseline is thestrongest faithfulinstance of its defense class, and its authorization rule is deterministic and reproduced verbatim from the released harness. •noneauthorizes every action (undefen...
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.