T-VSS: Test-Time Visual Subspace Steering for Adversarial Robustness of Vision-Language Models
Pith reviewed 2026-06-26 09:20 UTC · model grok-4.3
The pith
T-VSS improves adversarial robustness in vision-language models by directly correcting attacked visual features inside a sample-specific low-rank subspace.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
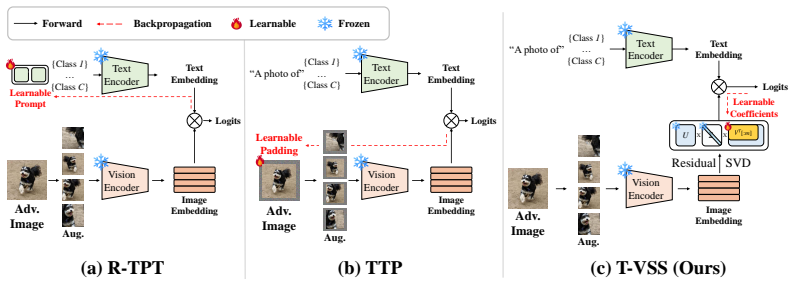
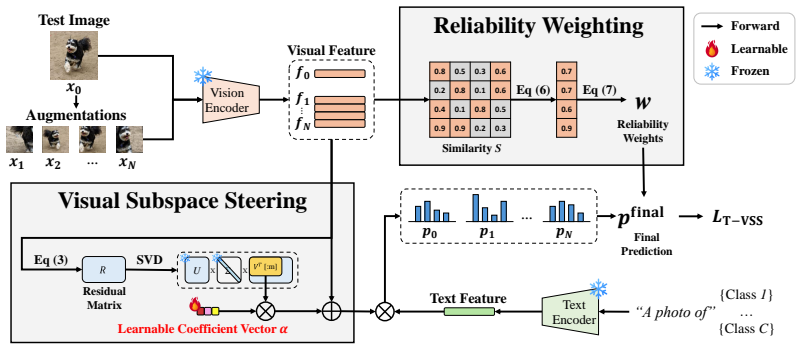
T-VSS first constructs a sample-specific low-rank subspace from multi-view feature residuals anchored at the attacked image. It then learns a shared feature correction within this subspace through reliability-weighted entropy minimization. By restricting updates to this compact visual geometry, the method steers corrupted features toward more stable and discriminative outputs while avoiding noisy full-space changes.
What carries the argument
The sample-specific low-rank subspace constructed from multi-view feature residuals, which serves as the constrained space for learning a shared feature correction via reliability-weighted entropy minimization.
If this is right
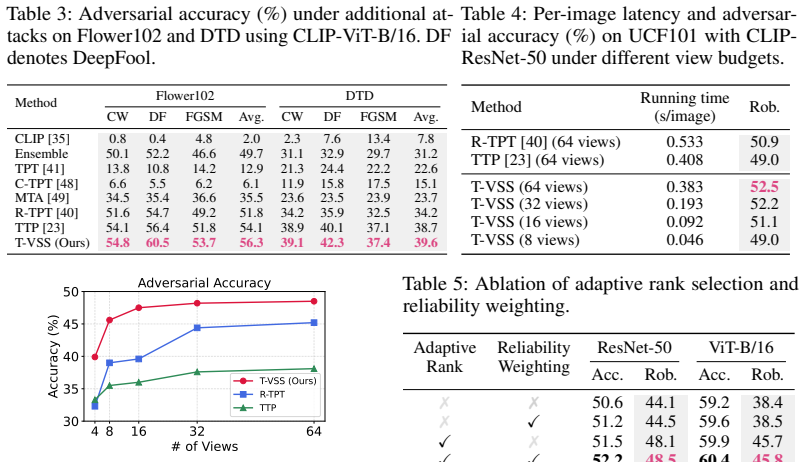
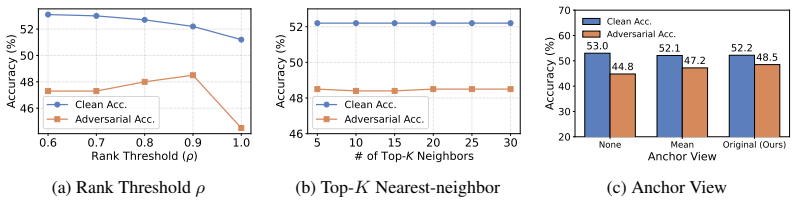
- Adversarial robustness improves on fine-grained classification, ImageNet, and out-of-distribution ImageNet tasks.
- Clean accuracy remains competitive with non-adapted models.
- Test-time computation stays lower than prior adaptation techniques that optimize prompts or pixels.
- No model retraining is required, preserving the original zero-shot capability.
Where Pith is reading between the lines
- The subspace idea could extend to other vision tasks where feature residuals are easy to collect, such as object detection under domain shift.
- Combining the visual subspace correction with existing prompt tuning might produce additive robustness gains without extra training.
- If the low-rank assumption holds across different vision-language architectures, the method offers a modular plug-in for deployed models.
- A direct test would measure whether the subspace dimension chosen at test time correlates with attack strength on held-out perturbations.
Load-bearing premise
That constructing a low-rank subspace from the attacked image's multi-view residuals and minimizing weighted entropy inside it will produce more stable and accurate predictions than full-space or indirect adaptations.
What would settle it
On the fine-grained, ImageNet, or ImageNet-OOD benchmarks, if T-VSS shows no gain in robust accuracy over prompt-based or input-space baselines while clean accuracy stays the same or drops, the value of the subspace constraint would be refuted.
Figures
read the original abstract
Vision-language models (VLMs) achieve strong zero-shot recognition, but they remain highly vulnerable to adversarial perturbations. Recent test-time adaptations improve robustness without retraining, but they do not directly adapt the corrupted visual representation itself. Prompt-based methods adapt the learnable text prompts, while input-space methods optimize pixels or padding at test time. These approaches can improve predictions, but they do so through an indirect and expensive optimization path. We propose Test-time Visual Subspace Steering (T-VSS), a lightweight defense that performs test-time adaptation directly in the visual feature space. T-VSS first builds a sample-specific low-rank subspace from multi-view feature residuals anchored at the attacked image. It then learns a shared feature correction within this subspace using reliability-weighted entropy minimization. By constraining adaptation to a compact visual geometry, T-VSS steers attacked features toward more stable and discriminative predictions while avoiding noisy full-space updates. Experiments on fine-grained, ImageNet, and ImageNet-OOD benchmarks show that T-VSS improves adversarial robustness while maintaining competitive clean accuracy and better efficiency than prior test-time adaptations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Test-time Visual Subspace Steering (T-VSS) for improving adversarial robustness of vision-language models. It constructs a sample-specific low-rank subspace from multi-view feature residuals anchored at the attacked image, then optimizes a shared feature correction inside this subspace via reliability-weighted entropy minimization. The central claim is that this constrained adaptation steers corrupted visual features toward stable, discriminative predictions more directly and efficiently than prompt-based or input-space test-time methods, with experiments on fine-grained, ImageNet, and ImageNet-OOD benchmarks showing gains in robustness while preserving clean accuracy.
Significance. If the central claim holds, T-VSS offers a lightweight, geometry-constrained alternative to full-space or indirect test-time adaptations for VLMs. The explicit use of a low-rank visual subspace and reliability weighting could improve efficiency and stability over prior approaches; the paper's emphasis on direct feature-space correction is a clear conceptual contribution if the subspace construction is shown to be effective.
major comments (2)
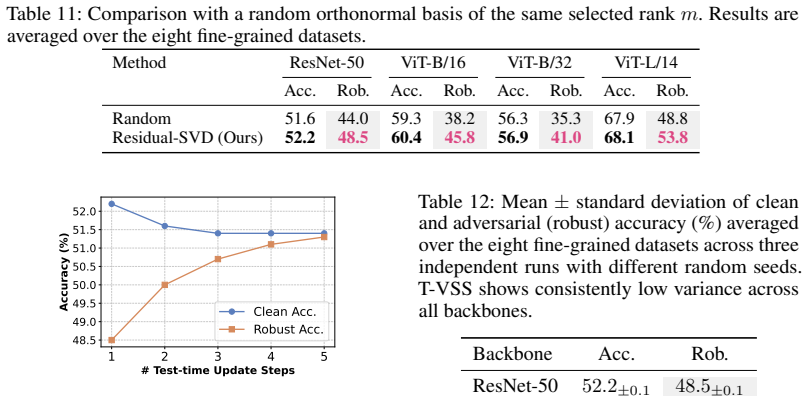
- [§3.2] §3.2 (subspace construction): the claim that multi-view feature residuals anchored at the attacked image yield directions useful for counteracting adversarial shifts is load-bearing but unsupported by analysis. Standard augmentations typically capture semantic/photometric variation rather than the small, model-specific adversarial direction; without a demonstration (e.g., via cosine similarity between residual basis vectors and known perturbation directions or ablation on subspace rank), the subsequent entropy minimization cannot be guaranteed to steer toward robustness.
- [§4] §4 (experiments): the reported robustness gains on ImageNet and OOD sets must be accompanied by controls showing that the subspace basis actually contains corrective components. If the multi-view residuals are generated only by standard augmentations, the improvement could be explained by generic test-time entropy minimization rather than the claimed visual-subspace mechanism; an ablation removing the low-rank constraint or replacing residuals with random vectors would isolate this.
minor comments (2)
- Notation for the reliability weight and the entropy term should be defined explicitly with equation numbers rather than inline prose.
- Figure 2 (method overview) would benefit from an explicit arrow or label showing how the low-rank projection is applied during the entropy minimization step.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the subspace construction and the need for isolating controls. We address each major comment below and will revise the manuscript accordingly to provide stronger empirical support.
read point-by-point responses
-
Referee: [§3.2] §3.2 (subspace construction): the claim that multi-view feature residuals anchored at the attacked image yield directions useful for counteracting adversarial shifts is load-bearing but unsupported by analysis. Standard augmentations typically capture semantic/photometric variation rather than the small, model-specific adversarial direction; without a demonstration (e.g., via cosine similarity between residual basis vectors and known perturbation directions or ablation on subspace rank), the subsequent entropy minimization cannot be guaranteed to steer toward robustness.
Authors: We acknowledge that direct geometric evidence would strengthen the interpretation. In the revised manuscript we will add (i) cosine-similarity analysis between the residual basis vectors and the known adversarial perturbation directions on the ImageNet and fine-grained evaluation sets (where clean images are available for post-hoc analysis) and (ii) an ablation varying subspace rank k. These additions will quantify whether the constructed directions align with corrective components beyond generic augmentation effects. revision: yes
-
Referee: [§4] §4 (experiments): the reported robustness gains on ImageNet and OOD sets must be accompanied by controls showing that the subspace basis actually contains corrective components. If the multi-view residuals are generated only by standard augmentations, the improvement could be explained by generic test-time entropy minimization rather than the claimed visual-subspace mechanism; an ablation removing the low-rank constraint or replacing residuals with random vectors would isolate this.
Authors: We agree that such isolating controls are required. The revised version will include two new ablations: (1) replacing the residual-derived basis with random vectors of identical dimension and rank, and (2) performing the same entropy minimization without the low-rank constraint (full feature space). Results on the same ImageNet and OOD benchmarks will be reported to demonstrate the specific contribution of the subspace construction. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces T-VSS as a novel algorithmic procedure: constructing a sample-specific low-rank subspace from multi-view feature residuals and performing reliability-weighted entropy minimization within it. No equations, claims, or steps in the provided abstract or description reduce by construction to fitted inputs, self-definitions, or self-citation chains. The method is presented as an independent test-time adaptation technique without renaming known results or smuggling ansatzes via citations. The derivation is self-contained as an engineering proposal rather than a tautological reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multi-view feature residuals can form a useful low-rank subspace for correction
- domain assumption Reliability-weighted entropy minimization improves prediction stability
Reference graph
Works this paper leans on
-
[1]
Synthesizing robust adversarial examples
Anish Athalye, Logan Engstrom, Andrew Ilyas, and Kevin Kwok. Synthesizing robust adversarial examples. InProc. ICML, pages 284–293, 2018
2018
-
[2]
Recent advances in adversarial training for adversarial robustness
Tao Bai, Jinqi Luo, Jun Zhao, Bihan Wen, and Qian Wang. Recent advances in adversarial training for adversarial robustness. InIJCAI, pages 4312–4321, 2021. Survey Track
2021
-
[3]
Towards evaluating the robustness of neural networks
Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. InProc. S&P, 2017
2017
-
[4]
Vlp: A survey on vision-language pre-training.Machine Intelligence Research, 20(1):38–56, 2023
Fei-Long Chen, Du-Zhen Zhang, Ming-Lun Han, Xiu-Yi Chen, Jing Shi, Shuang Xu, and Bo Xu. Vlp: A survey on vision-language pre-training.Machine Intelligence Research, 20(1):38–56, 2023
2023
-
[5]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InProc. CVPR, pages 3606–3613, 2014
2014
-
[6]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
Francesco Croce and Matthias Hein. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. InProc. ICML, pages 2206–2216, 2020
2020
-
[7]
Agft: Alignment-guided fine-tuning for zero-shot adversarial robustness of vision-language models.Proc
Yubo Cui, Xianchao Guan, Zijun Xiong, and Zheng Zhang. Agft: Alignment-guided fine-tuning for zero-shot adversarial robustness of vision-language models.Proc. CVPR, 2026
2026
-
[8]
Dafnis and Dimitris N
Konstantinos M. Dafnis and Dimitris N. Metaxas. Test-time spectrum-aware latent steering for zero-shot generalization in vision-language models. InProc. NeurIPS, 2025
2025
-
[9]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InProc. CVPR, pages 248–255, 2009
2009
-
[10]
Robust physical-world attacks on deep learning visual classification
Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song. Robust physical-world attacks on deep learning visual classification. InProc. CVPR, pages 1625–1634, 2018
2018
-
[11]
Clip-guided generative networks for transferable targeted adversarial attacks
Hao Fang, Jiawei Kong, Bin Chen, Tao Dai, Hao Wu, and Shu-Tao Xia. Clip-guided generative networks for transferable targeted adversarial attacks. InProc. ECCV, pages 1–19, 2024
2024
-
[12]
Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories
Li Fei-Fei, Rob Fergus, and Pietro Perona. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. InProc. CVPR Workshops, pages 178–178, 2004
2004
-
[13]
Adversarial attacks on medical machine learning.Science, 363(6433):1287–1289, 2019
Samuel G Finlayson, John D Bowers, Joichi Ito, Jonathan L Zittrain, Andrew L Beam, and Isaac S Kohane. Adversarial attacks on medical machine learning.Science, 363(6433):1287–1289, 2019
2019
-
[14]
Explaining and harnessing adversarial examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. InProc. ICLR, 2015
2015
-
[15]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226, 2019
2019
-
[16]
The many faces of robustness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. InProc. ICCV, pages 8340–8349, 2021
2021
-
[17]
Augmix: A simple data processing method to improve robustness and uncertainty
Dan Hendrycks, Norman Mu, Ekin D Cubuk, Barret Zoph, Justin Gilmer, and Balaji Lakshminarayanan. Augmix: A simple data processing method to improve robustness and uncertainty. InProc. ICLR, 2020
2020
-
[18]
Natural adversarial examples
Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Song. Natural adversarial examples. InProc. CVPR, pages 15262–15271, 2021
2021
-
[19]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. InProc. ICCV Workshops, pages 554–561, 2013
2013
-
[20]
Adversarial examples in the physical world
Alexey Kurakin, Ian J Goodfellow, and Samy Bengio. Adversarial examples in the physical world. In Artificial intelligence safety and security, pages 99–112. Chapman and Hall/CRC, 2018
2018
-
[21]
One prompt word is enough to boost adversarial robustness for pre-trained vision-language models
Lin Li, Haoyan Guan, Jianing Qiu, and Michael Spratling. One prompt word is enough to boost adversarial robustness for pre-trained vision-language models. InProc. CVPR, 2024. 10
2024
-
[22]
Language-driven anchors for zero-shot adversarial robustness
Xiao Li, Wei Zhang, Yining Liu, Zhanhao Hu, Bo Zhang, and Xiaolin Hu. Language-driven anchors for zero-shot adversarial robustness. InProc. CVPR, pages 24686–24695, 2024
2024
-
[23]
Ttp: Test-time padding for adversarial detection and robust adaptation on vision-language models.Proc
Zhiwei Li, Yitian Pang, Weining Wang, Zhenan Sun, and Qi Li. Ttp: Test-time padding for adversarial detection and robust adaptation on vision-language models.Proc. CVPR, 2026
2026
-
[24]
Adversarial attacks already tell the answer: Directional bias-guided test-time defense for vision-language models
Liangsheng Liu, Si Chen, Jiamin Wu, Weiwei Feng, Zhixin Cheng, Xiaotian Yin, Wenfei Yang, and Tianzhu Zhang. Adversarial attacks already tell the answer: Directional bias-guided test-time defense for vision-language models. InProc. ICLR, 2026
2026
-
[25]
TTT++: When does self-supervised test-time training fail or thrive? InProc
Yuejiang Liu, Parth Kothari, Bastien Germain van Delft, Baptiste Bellot-Gurlet, Taylor Mordan, and Alexandre Alahi. TTT++: When does self-supervised test-time training fail or thrive? InProc. NeurIPS, 2021
2021
-
[26]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. InProc. ICLR, 2018
2018
-
[27]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine-grained visual classification of aircraft.arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[28]
Understanding zero-shot adversarial robustness for large-scale models
Chengzhi Mao, Scott Geng, Junfeng Yang, Xin Wang, and Carl V ondrick. Understanding zero-shot adversarial robustness for large-scale models. InProc. ICLR, 2023
2023
-
[29]
Universal adversar- ial perturbations
Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, Omar Fawzi, and Pascal Frossard. Universal adversar- ial perturbations. InProc. CVPR, 2017
2017
-
[30]
Deepfool: a simple and accurate method to fool deep neural networks
Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, and Pascal Frossard. Deepfool: a simple and accurate method to fool deep neural networks. InProc. CVPR, pages 2574–2582, 2016
2016
-
[31]
Zachary Nado, Shreyas Padhy, D Sculley, Alexander D’Amour, Balaji Lakshminarayanan, and Jasper Snoek. Evaluating prediction-time batch normalization for robustness under covariate shift.arXiv preprint arXiv:2006.10963, 2020
-
[32]
Diffusion models for adversarial purification
Weili Nie, Brandon Guo, Yujia Huang, Chaowei Xiao, Arash Vahdat, and Anima Anandkumar. Diffusion models for adversarial purification. InProc. ICML, 2022
2022
-
[33]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. InProc. ICVGIP, pages 722–729, 2008
2008
-
[34]
Cats and dogs
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. InProc. CVPR, pages 3498–3505, 2012
2012
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InProc. ICML, 2021
2021
-
[36]
Do imagenet classifiers generalize to imagenet? InProc
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to imagenet? InProc. ICML, pages 5389–5400, 2019
2019
-
[37]
Overfitting in adversarially robust deep learning
Leslie Rice, Eric Wong, and Zico Kolter. Overfitting in adversarially robust deep learning. InProc. ICML, pages 8093–8104, 2020
2020
-
[38]
Robust clip: Unsupervised adversarial fine-tuning of vision embeddings for robust large vision-language models
Christian Schlarmann, Naman Deep Singh, Francesco Croce, and Matthias Hein. Robust clip: Unsupervised adversarial fine-tuning of vision embeddings for robust large vision-language models. InProc. ICML, 2024
2024
-
[39]
Efficient Test-Time Optimization for Depth Completion via Low-Rank Decoder Adaptation
Minseok Seo, Wonjun Lee, Jaehyuk Jang, and Changick Kim. Efficient test-time optimization for depth completion via low-rank decoder adaptation.arXiv preprint arXiv:2603.01765, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
R-tpt: Improving adversarial robustness of vision- language models through test-time prompt tuning
Lijun Sheng, Jian Liang, Zilei Wang, and Ran He. R-tpt: Improving adversarial robustness of vision- language models through test-time prompt tuning. InProc. CVPR, pages 29958–29967, 2025
2025
-
[41]
Test-time prompt tuning for zero-shot generalization in vision-language models
Manli Shu, Weili Nie, De-An Huang, Zhiding Yu, Tom Goldstein, Anima Anandkumar, and Chaowei Xiao. Test-time prompt tuning for zero-shot generalization in vision-language models. InProc. NeurIPS, volume 35, pages 14274–14289, 2022
2022
-
[42]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012. 11
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[43]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale.arXiv preprint arXiv:2303.15389, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Yu Sun, Xiaolong Wang, Liu Zhuang, John Miller, Moritz Hardt, and Alexei A. Efros. Test-time training with self-supervision for generalization under distribution shifts. InProc. ICML, 2020
2020
-
[45]
Learning robust global representations by penalizing local predictive power.Proc
Haohan Wang, Songwei Ge, Zachary Lipton, and Eric P Xing. Learning robust global representations by penalizing local predictive power.Proc. NeurIPS, 32, 2019
2019
-
[46]
Pre-trained model guided fine-tuning for zero-shot adversarial robustness
Sibo Wang, Jie Zhang, Zheng Yuan, and Shiguang Shan. Pre-trained model guided fine-tuning for zero-shot adversarial robustness. InProc. CVPR, pages 24502–24511, 2024
2024
-
[47]
Clip is strong enough to fight back: Test-time counterattacks towards zero-shot adversarial robustness of clip
Songlong Xing, Zhengyu Zhao, and Nicu Sebe. Clip is strong enough to fight back: Test-time counterattacks towards zero-shot adversarial robustness of clip. InProc. CVPR, pages 15172–15182, 2025
2025
-
[48]
C-tpt: Calibrated test-time prompt tuning for vision-language models via text feature dispersion
Hee Suk Yoon, Eunseop Yoon, Joshua Tian Jin Tee, Mark Hasegawa-Johnson, Yingzhen Li, and Chang D Yoo. C-tpt: Calibrated test-time prompt tuning for vision-language models via text feature dispersion. In Proc. ICLR, 2024
2024
-
[49]
On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning? InProc
Maxime Zanella and Ismail Ben Ayed. On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning? InProc. CVPR, pages 23783–23793, 2024
2024
-
[50]
Theoreti- cally principled trade-off between robustness and accuracy
Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric Xing, Laurent El Ghaoui, and Michael Jordan. Theoreti- cally principled trade-off between robustness and accuracy. InProc. ICML, pages 7472–7482, 2019
2019
-
[51]
Jiacheng Zhang, Jinhao Li, Hanxun Huang, Sarah Monazam Erfani, Benjamin I. P. Rubinstein, and Feng Liu. Semantic-aware adversarial fine-tuning for CLIP.Transactions on Machine Learning Research, 2026
2026
-
[52]
Adver- sarial prompt tuning for vision-language models
Jiaming Zhang, Xingjun Ma, Xin Wang, Lingyu Qiu, Jiaqi Wang, Yu-Gang Jiang, and Jitao Sang. Adver- sarial prompt tuning for vision-language models. InProc. ECCV, 2024
2024
-
[53]
Vision-language models for vision tasks: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[54]
Conditional prompt learning for vision-language models
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision-language models. InProc. CVPR, 2022
2022
-
[55]
Learning to prompt for vision-language models.International Journal of Computer Vision, 130(9):2337–2348, 2022
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.International Journal of Computer Vision, 130(9):2337–2348, 2022
2022
-
[56]
Few-shot adversarial prompt learning on vision-language models
Yiwei Zhou, Xiaobo Xia, Zhiwei Lin, Bo Han, and Tongliang Liu. Few-shot adversarial prompt learning on vision-language models. InProc. NeurIPS, volume 37, pages 3122–3156, 2024
2024
-
[57]
Enhancing CLIP robustness via cross-modality alignment
Xingyu Zhu, Beier Zhu, Shuo Wang, Kesen Zhao, and Hanwang Zhang. Enhancing CLIP robustness via cross-modality alignment. InProc. NeurIPS, 2025. 12 Appendix A More Experimental Details 13 A.1 Datasets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 A.2 Source of Baseline Results . . . . . . . . . . . . . . . . . . . . . ....
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.