Large language models selectively converge with human-shared neural semantic representations
Pith reviewed 2026-06-27 07:50 UTC · model grok-4.3
The pith
LLMs approximate the neural semantics shared between human speakers and listeners in a selective, dimension-dependent manner.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Both human- and LLM-derived semantic spaces explained speaker-listener neural synchronization beyond acoustic and phonological features, yet comparable overall prediction concealed systematic differences in representational geometry. Larger LLMs aligned more closely and showed greater overlap with humans in semantic structure and neural synchronization, but this alignment remained incomplete and dimension-dependent, with the largest divergences on dimensions tied to agency, affect, and social experience.
What carries the argument
dimension-resolved interbrain encoding model that tests whether ratings along ten semantic dimensions explain measured speaker-listener neural synchronization in MEG data beyond low-level acoustic and phonological predictors.
If this is right
- Shared neural semantics during communication form a multidimensional structure rather than one global signal.
- The strength of speaker-listener neural alignment predicts individual differences in story comprehension.
- Increasing model size or capability narrows the gap between LLM and human semantic representations.
- Dimensions grounded in social experience, emotion, and agency remain only partially captured even by the largest models tested.
Where Pith is reading between the lines
- Training procedures that emphasize social and affective language data could reduce the observed divergences on those dimensions.
- Embodied or interactive training signals may be required for LLMs to match human neural responses on agency-related features.
- The same modeling approach could be applied to other communicative tasks such as dialogue or instruction following to test whether selectivity persists.
Load-bearing premise
The ten chosen semantic dimensions and the interbrain encoding model correctly isolate shared semantic structure from acoustic and phonological contributions.
What would settle it
Re-running the encoding analysis with only acoustic and phonological features yields prediction accuracy equal to or higher than the version that adds the ten semantic dimensions from either humans or LLMs.
Figures
read the original abstract
Interpersonal communication requires building shared semantics that enable listeners to understand speakers' meanings from their unfolding language, but the dimensional structure of this shared neural representation remains unclear. LLMs increasingly approximate human language capability and neural responses, raising the question of whether they capture the same semantic structure shared between human brains. Here, we combined storytelling-listening pseudo-hyperscanning MEG with dimension-resolved interbrain encoding modeling to compare human- and LLM-derived accounts of shared neural semantic representations. Content words from the speaker's narratives were rated by humans and five recent LLMs along ten semantic dimensions (i.e., perception, motor, space, time, socialness, animacy, emotion, attention, causality, and drive). We tested whether these dimensions explained speaker-listener neural synchronization (NS) beyond acoustic and phonological features. Both human- and LLM-derived semantic spaces explained NS, but these shared semantics are better characterized as a multidimensional neural structure rather than a single global signal. These patterns also predicted individual differences in listeners' story comprehension, linking neural alignment to cognition. However, comparable overall prediction concealed systematic differences in representational geometry. Larger LLMs aligned more closely and showed greater overlap with humans in semantic structure and NS, but this was incomplete and dimension-dependent. The largest divergences emerged for dimensions closely tied to agency, affect, and social experience. These findings show that LLMs capture substantial components of human shared neural semantics, but their alignment is selective. Larger or more capable models improve the approximation, whereas socially and affectively grounded dimensions are captured only partially.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript combines MEG pseudo-hyperscanning during narrative storytelling-listening with dimension-resolved interbrain encoding models. Content words are rated by humans and five LLMs on ten semantic dimensions (perception, motor, space, time, socialness, animacy, emotion, attention, causality, drive). The central claim is that both human- and LLM-derived ratings explain speaker-listener neural synchronization (NS) beyond acoustic and phonological features, that the shared semantics form a multidimensional rather than global structure, that this alignment predicts individual differences in comprehension, and that larger LLMs converge more closely with human neural geometry but remain incomplete and dimension-selective, with largest gaps on agency-, affect-, and social-related dimensions.
Significance. If the encoding-model results hold after proper controls, the work supplies a neural benchmark showing selective rather than uniform convergence between LLMs and human shared semantic representations. The dimension-specific analysis and cross-model-size comparison provide a concrete, falsifiable framework for quantifying representational alignment; the reported link between NS and comprehension scores adds behavioral grounding. These elements would be of interest to both cognitive neuroscience and AI alignment research.
major comments (2)
- [Methods (encoding model)] Methods (dimension-resolved interbrain encoding model): The claim that the ten semantic dimensions explain NS beyond acoustic and phonological features is load-bearing for the selective-alignment conclusion. The manuscript must report incremental variance explained (e.g., ΔR² or partial R²) after acoustic/phonological controls, together with checks that rating dimensions are not collinear with low-level features such as duration or pitch; absent these results, residual acoustic leakage could artifactually inflate apparent semantic overlap.
- [Results (model comparisons)] Results (LLM vs. human geometry comparison): The assertion of systematic, dimension-dependent divergences (especially for social/affective dimensions) requires per-dimension quantitative metrics—e.g., cosine similarity of rating vectors, model-specific beta weights in the encoding model, or cross-validated prediction accuracies—accompanied by statistical tests. The abstract’s summary of “comparable overall prediction concealed systematic differences” cannot be evaluated without these numbers.
minor comments (1)
- [Abstract] Abstract: No sample size, participant count, or statistical threshold is stated, making it impossible to gauge the reliability of the reported effects from the summary alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify areas where additional quantitative detail would strengthen the manuscript. We address each below and commit to revisions that directly incorporate the requested metrics and controls.
read point-by-point responses
-
Referee: [Methods (encoding model)] Methods (dimension-resolved interbrain encoding model): The claim that the ten semantic dimensions explain NS beyond acoustic and phonological features is load-bearing for the selective-alignment conclusion. The manuscript must report incremental variance explained (e.g., ΔR² or partial R²) after acoustic/phonological controls, together with checks that rating dimensions are not collinear with low-level features such as duration or pitch; absent these results, residual acoustic leakage could artifactually inflate apparent semantic overlap.
Authors: We agree that explicit incremental variance metrics are necessary to support the claim. The manuscript already includes acoustic/phonological controls in the encoding models, but does not report ΔR² or partial R² values. We will add these statistics (both for human and LLM-derived ratings) in a new supplementary table, together with variance inflation factor (VIF) checks confirming that the ten semantic dimensions are not collinear with the low-level acoustic features. This revision will be placed in the Methods and Results sections. revision: yes
-
Referee: [Results (model comparisons)] Results (LLM vs. human geometry comparison): The assertion of systematic, dimension-dependent divergences (especially for social/affective dimensions) requires per-dimension quantitative metrics—e.g., cosine similarity of rating vectors, model-specific beta weights in the encoding model, or cross-validated prediction accuracies—accompanied by statistical tests. The abstract’s summary of “comparable overall prediction concealed systematic differences” cannot be evaluated without these numbers.
Authors: The manuscript reports overall prediction accuracies and notes dimension-dependent patterns, but does not supply the requested per-dimension quantitative metrics or accompanying statistical tests. We will add (i) cosine similarities between human and LLM rating vectors per dimension, (ii) dimension-specific beta weights from the encoding models, and (iii) cross-validated prediction accuracies broken down by dimension, each accompanied by appropriate statistical tests (paired t-tests or repeated-measures ANOVA with correction). These additions will be presented in a new figure and table in the Results section, allowing direct evaluation of the selective-alignment claim. revision: yes
Circularity Check
No circularity; empirical comparisons independent of inputs
full rationale
The paper is an empirical study that collects human and LLM ratings on ten semantic dimensions for content words, then applies a dimension-resolved interbrain encoding model to test whether these ratings explain speaker-listener neural synchronization beyond acoustic and phonological controls. No mathematical derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The reader's assessment correctly notes the absence of equations or derivations, and the comparison between human and LLM accounts is not constructed to be equivalent to the neural synchronization measure itself. Methodological questions about feature isolation or variance partitioning are validity concerns, not reductions of the claimed result to its own inputs by definition or self-reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MEG signals during storytelling-listening reflect semantic content that can be linearly decoded from word-level ratings
Reference graph
Works this paper leans on
-
[1]
he remaining neural components were then projected back to sensor space to obtain cleaned MEG data. To align the MEG signals with the speech stream, we recorded the audio not only with the microphone described above (48 kHz sampling rate) but also via a dedicated analog channel within the MEG system (1000 Hz). Although the MEG analog channel could not pre...
2012
-
[2]
Subject-specific head models were derived from T1-weighted MRI data using FreeSurfer v7.4.0 and implemented a single-layer boundary element model (BEM) (Fuchs et al., 2002)
under Python 3.11.6. Subject-specific head models were derived from T1-weighted MRI data using FreeSurfer v7.4.0 and implemented a single-layer boundary element model (BEM) (Fuchs et al., 2002). MEG sensors were co-registered to MRI by aligning anatomical fiducials (nasion and bilateral preauricular points). The forward solution computed sensor-level magn...
2002
-
[3]
Downstream analyses were restricted to 196 parcels within speech production and comprehension networks (Fig
Individual source estimates were morphed to the fsaverage template and parcellated using Schaefer’s 1000-parcel atlas (Schaefer et al., 2018). Downstream analyses were restricted to 196 parcels within speech production and comprehension networks (Fig. S2): inferior frontal gyrus (IFG; L:10/R:13), pre/postcentral gyri (Pre/PostCG; L:15/R:14), supramarginal...
2018
-
[4]
following a standardized feature-labeling protocol. Furthermore, one acoustic feature (combination of acoustic envelopes and onsets), two phonetic features (consonant onsets and vowel onsets), two pitch features (F0 height and change) and one tonal feature (tone categories) were included as features of non-interest in the following analysis of semantic fe...
2026
-
[5]
今天我要说一个关于父亲的故事
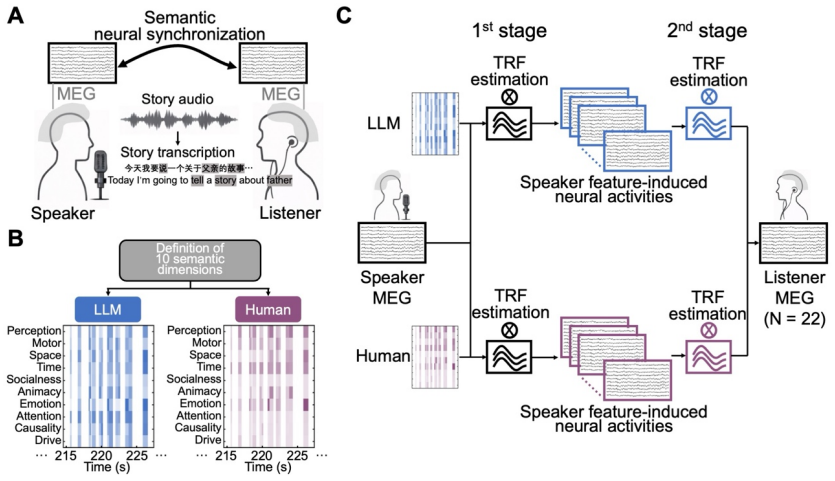
Experimental design and analysis framework for speaker-listener shared neural representations across 10 semantic dimensions. (A) MEG experimental setup. MEG recordings were obtained from a speaker narrating eight stories in Mandarin Chinese (example sentence shown: “今天我要说一个关于父亲的故事” / “Today I’m going to tell a story about father”). The recorded audio clip...
2016
-
[6]
For each model condition, including the five LLMs and human ratings, we organized the data into dimension-wise matrices
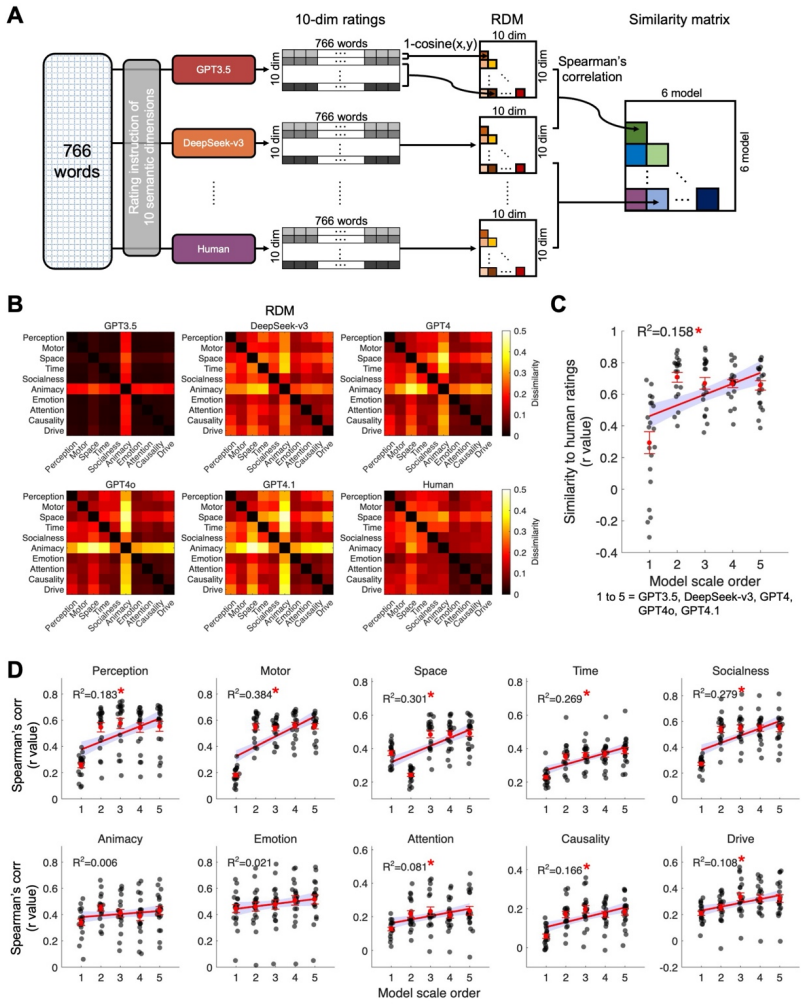
was used to quantify the correspondence between the dimensional structure of semantic ratings and semantic NS patterns across LLMs and human ratings. For each model condition, including the five LLMs and human ratings, we organized the data into dimension-wise matrices. For the rating analysis, the matrix contained semantic ratings for 766 content words a...
2000
-
[7]
This indicates that each NS pattern was aligned to a template derived from averaging across all models and speaker-listener pairs
of 18 all ones. This indicates that each NS pattern was aligned to a template derived from averaging across all models and speaker-listener pairs. The distance between two NS patterns is defined as the sum of the squared differences between them. Statistical analysis To assess the statistical significance of each LLM’s or human’s ability to explain NS, we...
1994
-
[8]
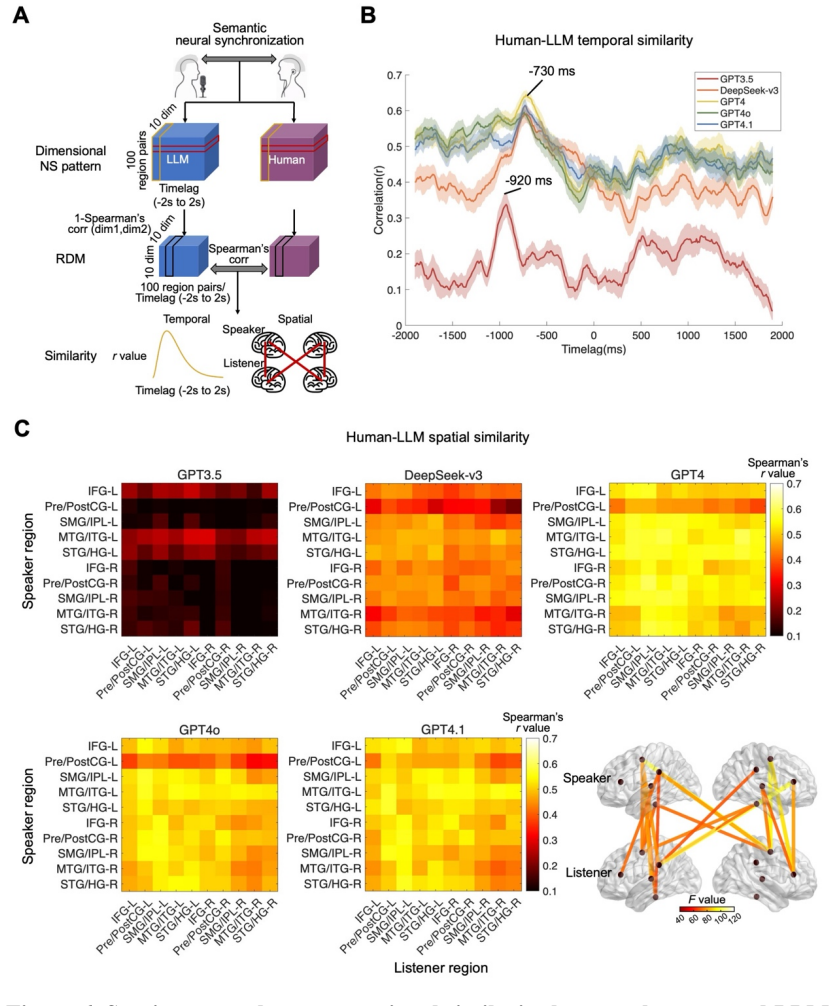
(A) Searchlight RSA framework for quantifying human-LLM similarity in dimensional NS patterns
Spatiotemporal representational similarity between human- and LLM-derived semantic NS. (A) Searchlight RSA framework for quantifying human-LLM similarity in dimensional NS patterns. For each model, TRF weights for 10 semantic dimensions were used to construct RDMs, separately for each time point and each speaker-listener region pair. Human-LLM similarity ...
1950
-
[9]
(A) Prediction of listeners’ comprehension from overall semantic NS patterns combining all 10 dimensions
Semantic NS patterns predicted listeners’ story comprehension. (A) Prediction of listeners’ comprehension from overall semantic NS patterns combining all 10 dimensions. Dots indicate R² values from 10,000 bootstrapped 10-fold cross-validation runs; horizontal lines mark significant pairwise differences. (B) Dimension-specific prediction performance for LL...
2023
-
[10]
and with broader work on mental-state attribution and social cognition (Frith & Frith, 2010; Saxe & Kanwisher, 2003). LLMs can learn many animacy-related properties and regularities from text, but these representations may not fully reproduce the socially grounded inferences that shape human semantic alignment. Socialness provides a particularly informati...
Pith/arXiv arXiv 2010
-
[11]
https://doi.org/10.3389/fnhum.2016.00604 48 Dale, A. M., Liu, A. K., Fischl, B. R., Buckner, R. L., Belliveau, J. W., Lewine, J. D., & Halgren, E. (2000). Dynamic Statistical Parametric Mapping: Combining fMRI and MEG for High-Resolution Imaging of Cortical Activity. Neuron, 26(1), 55–67. https://doi.org/https://doi.org/10.1016/S0896-6273(00)81138-1 Du, C...
-
[12]
Jung-Beeman, M. (2005). Bilateral brain processes for comprehending natural language. Trends in cognitive sciences, 9(11), 512–518. Karunathilake, I. D., Kulasingham, J. P., & Simon, J. Z. (2023). Neural tracking measures of speech intelligibility: Manipulating intelligibility while keeping acoustics unchanged. Proceedings of the National Academy of Scien...
2005
-
[13]
Kendall, D. G. (1989). A survey of the statistical theory of shape. Statistical Science, 4(2), 87–99. Koolagudi, S. G., & Rao, K. S. (2012). Emotion recognition from speech: a review. International journal of speech technology, 15(2), 99–117. Kousta, S.-T., Vigliocco, G., Vinson, D. P., Andrews, M., & Del Campo, E. (2011). The representation of abstract w...
1989
-
[14]
Kriegeskorte, N., Mur, M., & Bandettini, P. A. (2008). Representational similarity analysis-connecting the branches of systems neuroscience. Frontiers in systems neuroscience, 2,
2008
-
[15]
K., Allefeld, C., & Haynes, J.-D
Kuhlen, A. K., Allefeld, C., & Haynes, J.-D. (2012). Content-specific coordination of listeners' to speakers' EEG during communication. Frontiers in human neuroscience, 6,
2012
-
[16]
G., Wang, L., & Bastiaansen, M
Lewis, A. G., Wang, L., & Bastiaansen, M. (2015). Fast oscillatory dynamics during language comprehension: Unification versus maintenance and prediction? Brain and Language, 148, 51–63. Li, Z., Hong, B., Nolte, G., Engel, A. K., & Zhang, D. (2024). Speaker–listener neural coupling correlates with semantic and acoustic features of naturalistic speech. Soci...
Pith/arXiv arXiv 2015
-
[17]
Pulvermüller, F. (2005). Brain mechanisms linking language and action. Nature reviews neuroscience, 6(7), 576–582. Pulvermüller, F., & Fadiga, L. (2010). Active perception: sensorimotor circuits as a cortical basis for language. Nature reviews neuroscience, 11(5), 351–360. Radvansky, G. A., & Zacks, J. M. (2014). Event cognition. Oxford University Press. ...
-
[18]
Váša, F., & Mišić, B. (2022). Null models in network neuroscience. Nature reviews neuroscience, 23(8), 493–504. Vigário, R., Sarela, J., Jousmiki, V., Hamalainen, M., & Oja, E. (2002). Independent component approach to the analysis of EEG and MEG recordings. IEEE transactions on biomedical engineering, 47(5), 589–593. Vigliocco, G., Kousta, S.-T., Della R...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.