Exploring the Semantic Gap in Agentic Data Systems: A Formative Study of Operationalization Failures in Analytical Workflows
Pith reviewed 2026-07-02 03:03 UTC · model grok-4.3
The pith
Agentic data systems encounter a semantic gap that causes recurring operationalization failures in analytical workflows despite successful execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
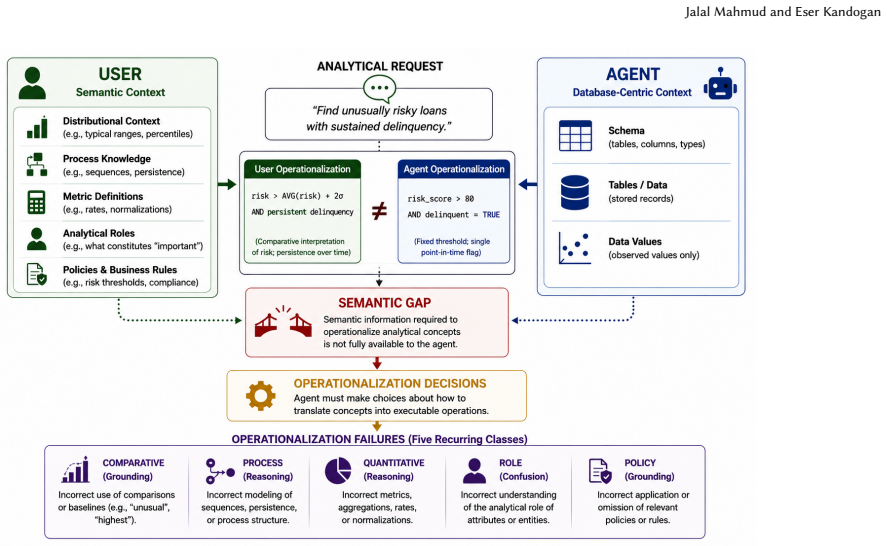
Across 236 analytical intents spanning finance, human resources, and public safety domains, 153 recurring failures occur despite successful workflow generation and execution. These failures fall into five classes: comparative grounding, process reasoning, quantitative reasoning, role confusion, and policy grounding. The findings indicate a semantic gap between user-level analytical concepts and the information available to workflow-generation systems.
What carries the argument
The formative study that identifies and classifies operationalization failures in agent-generated analytical workflows into five recurring classes based on cross-domain analysis.
Load-bearing premise
The 236 analytical intents selected and the manual classification into five failure classes are representative of typical analytical work and free from significant bias.
What would settle it
Conducting the same study with a larger or differently sampled set of intents that results in a substantially lower rate of failures or a different set of dominant classes.
Figures
read the original abstract
Large language models (LLMs) are increasingly used to generate queries, invoke tools, and construct analytical workflows. Although recent advances have substantially improved workflow generation and execution, the semantic information required to operationalize analytical concepts often lies beyond what is explicitly represented in database schemas and data values. We present a cross-domain formative study of operationalization failures in agent-generated analytical workflows. Across 236 analytical intents spanning finance, human resources, and public safety domains, we identify 153 recurring failures despite successful workflow generation and execution. Our analysis reveals five recurring classes of failures: comparative grounding, process reasoning, quantitative reasoning, role confusion, and policy grounding. These findings suggest a semantic gap between user-level analytical concepts and the information available to workflow-generation systems. More broadly, they raise questions about the admissibility of analytical operations and suggest that future agentic data systems may require richer semantic representations to bridge the gap between analytical intent and executable computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a cross-domain formative study of operationalization failures in LLM-generated analytical workflows. Across 236 analytical intents from finance, human resources, and public safety, it identifies 153 recurring failures despite successful workflow generation and execution, classifying them into five classes: comparative grounding, process reasoning, quantitative reasoning, role confusion, and policy grounding. The work argues this reveals a semantic gap between user-level analytical concepts and information available to workflow-generation systems.
Significance. If the observational findings hold with proper validation, the enumeration of five concrete failure classes would be a useful contribution to database systems and agentic AI research. It supplies domain-spanning examples of where schema and data values alone are insufficient for analytical intent, which could guide requirements for richer semantic layers in future agentic data systems.
major comments (2)
- [Abstract] Abstract: the central claim rests on counts (236 intents, 153 failures) and a five-class taxonomy, yet the text supplies no description of intent sampling or generation protocol, workflow execution verification, or how failures were identified and annotated. This directly undermines the ability to evaluate whether the observed recurrence reflects properties of agentic systems or curation choices.
- [Methods] The manuscript reports a manual classification into the five failure classes but provides no inter-rater reliability metrics, blinding procedure, or annotation guidelines. Without these, the reproducibility of the taxonomy cannot be assessed and the claim that the classes are 'recurring' remains unsupported.
minor comments (2)
- [Abstract] The abstract lists the three domains but does not indicate how many intents per domain; adding this breakdown would improve transparency of the cross-domain claim.
- Terminology such as 'operationalization failures' and 'semantic gap' is introduced without a concise definition or reference to prior usage in the agentic-systems literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for greater methodological transparency. We address the two major comments point by point below and will revise the manuscript to supply the requested details on sampling, execution verification, and annotation procedures.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim rests on counts (236 intents, 153 failures) and a five-class taxonomy, yet the text supplies no description of intent sampling or generation protocol, workflow execution verification, or how failures were identified and annotated. This directly undermines the ability to evaluate whether the observed recurrence reflects properties of agentic systems or curation choices.
Authors: We agree the abstract is concise and omits these details. The full manuscript contains a Methods section that describes intent collection from domain experts, the LLM agent workflow generation protocol, successful execution verification on the target databases, and the manual identification of failures. To improve accessibility, we will revise the abstract to include a brief study-design summary and expand the Methods section with explicit sampling and verification protocols. revision: yes
-
Referee: [Methods] The manuscript reports a manual classification into the five failure classes but provides no inter-rater reliability metrics, blinding procedure, or annotation guidelines. Without these, the reproducibility of the taxonomy cannot be assessed and the claim that the classes are 'recurring' remains unsupported.
Authors: We acknowledge that inter-rater reliability metrics, blinding procedures, and annotation guidelines are not currently reported. Classification was performed collaboratively by the authors through iterative discussion. We will revise the Methods section to describe the annotation process in detail, include the guidelines as supplementary material, and note the lack of formal IRR metrics as a limitation of the formative study design. revision: yes
Circularity Check
No circularity: empirical formative study with no derivations or fitted predictions
full rationale
The paper is a cross-domain formative study that collects 236 analytical intents, observes 153 failures, and manually classifies them into five categories. No equations, parameters, predictions, or derivations are present. The central claims rest on direct reporting of observed patterns rather than any reduction of outputs to inputs by construction, self-citation chains, or ansatzes. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ziawasch Abedjan, Lukasz Golab, and Felix Naumann. 2015. Profiling relational data: a survey.The VLDB Journal24, 4 (2015), 557–581
2015
-
[2]
City of New York. 2023. NYC Motor Vehicle Collisions. https://www.kaggle. com/datasets/new-york-city/motor-vehicle-collisions. Accessed: 2026-02-17
2023
-
[3]
E. F. Codd, S. B. Codd, and C. T. Salley. 1993.Providing OLAP (On-Line Analytical Processing) to User-Analysts: An IT Mandate. Technical Report. E. F. Codd and Associates
1993
-
[4]
Xiang Deng, Huan Sun, Alyssa Lees, You Wu, and Cong Yu. 2020. TURL: Ta- ble Understanding through Representation Learning.Proceedings of the VLDB Endowment14, 3 (2020), 307–319. https://doi.org/10.14778/3430915.3430921
-
[5]
Avrilia Floratou, Fotis Psallidas, Fuheng Zhao, Shaleen Deep, Gunther Hagleither, Wangda Tan, Joyce Cahoon, Rana Alotaibi, Jordan Henkel, Abhik Singla, Alex van Grootel, Brandon Chow, Kai Deng, Katherine Lin, Marcos Campos, Venkatesh Emani, Vivek Pandit, Victor Shnayder, Wenjing Wang, and Carlo Curino. 2024. NL2SQL is a Solved Problem... Not!. InConferenc...
2024
-
[6]
Jonathan Herzig, Pawel Krzysztof Nowak, Thomas Müller, Francesco Piccinno, and Julian Martin Eisenschlos. 2020. TaPas: Weakly Supervised Table Parsing Exploring the Semantic Gap in Agentic Data Systems: A Formative Study of Operationalization Failures in Analytical Workflows via Pre-training. InProceedings of the 58th Annual Meeting of the Association for...
- [7]
-
[8]
Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav San- thanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2024. DSPy: Compiling Declarative Language Model Calls into State-of-the-Art Pipelines. In International Conference on Learning Representations (ICLR)
2024
-
[9]
2013.The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling(3rd ed.)
Ralph Kimball and Margy Ross. 2013.The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling(3rd ed.). Wiley
2013
-
[10]
Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, Hongjin Su, Zhaoqing Suo, Hongcheng Gao, Wenjing Hu, Pengcheng Yin, Victor Zhong, Caiming Xiong, Ruoxi Sun, Qian Liu, Sida Wang, and Tao Yu. 2025. Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Work- flows. InInternational Conference on Learning Representations (...
2025
-
[11]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin Chang, Fei Huang, Reynold Cheng, and Yongbin Li. 2023. Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs. InAdvances in Neural Information Proces...
2023
-
[12]
LinkedIn. [n.d.]. DataHub: The Metadata Platform for the Modern Data Stack. https://datahubproject.io/. Open-source project documentation
-
[13]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Ao- han Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. 2024. AgentBench: Eval- uating LLMs as Agents. InThe Twelfth International Conference on ...
2024
-
[14]
Yifu Liu, Yin Zhu, Yingqi Gao, Zhiling Luo, Xiaoxia Li, Xiaorong Shi, Yuntao Hong, Jinyang Gao, Yu Li, Bolin Ding, and Jingren Zhou. 2025. XiYan-SQL: A Novel Multi-Generator Framework for Text-to-SQL.IEEE Transactions on Knowledge and Data Engineering (TKDE)(2025)
2025
-
[15]
Lyft Engineering. [n.d.]. Amundsen: A Data Discovery and Metadata Engine. https://www.amundsen.io/. Project documentation and blog posts
-
[16]
OpenMetadata. 2025. OpenMetadata: An Open Standard for Metadata. https: //github.com/open-metadata/OpenMetadata. Accessed: 2026-06-03
2025
-
[17]
Mohammadreza Pourreza, Hailong Li, Ruoxi Sun, Yeounoh Chung, Shayan Talaei, Gaurav Tarlok Kakkar, Yu Gan, Amin Saberi, Fatma Ozcan, and Sercan O. Arik
-
[18]
InInternational Conference on Learning Representations (ICLR)
CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL. InInternational Conference on Learning Representations (ICLR)
- [19]
-
[20]
S. S. Stevens. 1946. On the theory of scales of measurement.Science103, 2684 (1946), 677–680
1946
-
[21]
Narasimhan
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik R. Narasimhan. 2025. 𝜏- bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. In International Conference on Learning Representations (ICLR). https://openreview. net/forum?id=roNSXZpUDN
2025
-
[22]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR)
2023
-
[23]
Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Sebastian Riedel. 2020. TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data. InProceedings of the 58th Annual Meeting of the Association for Computa- tional Linguistics (ACL). Association for Computational Linguistics, 8413–8426. https://doi.org/10.18653/v1/2020.acl-main.745
-
[24]
Tao Yu, Chien-Sheng Wu, Xi Victoria Lin, Bailin Wang, Yi Chern Tan, Xinyi Yang, Dragomir Radev, Richard Socher, and Caiming Xiong. 2021. GraPPa: Grammar- Augmented Pre-Training for Table Semantic Parsing. InInternational Conference on Learning Representations (ICLR). https://openreview.net/forum?id=kyaIeYj4zZ
2021
-
[25]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. 2018. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Proces...
2018
- [26]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.