SupraSNN: Exploiting Synapse-Level Parallelism in Spiking Neural Network Accelerators through Co-Optimized Mapping and Scheduling
Pith reviewed 2026-06-27 05:20 UTC · model grok-4.3
The pith
SupraSNN decouples synaptic and neuronal computations in an FPGA architecture to run multiple synapse operations in parallel through co-optimized mapping and scheduling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
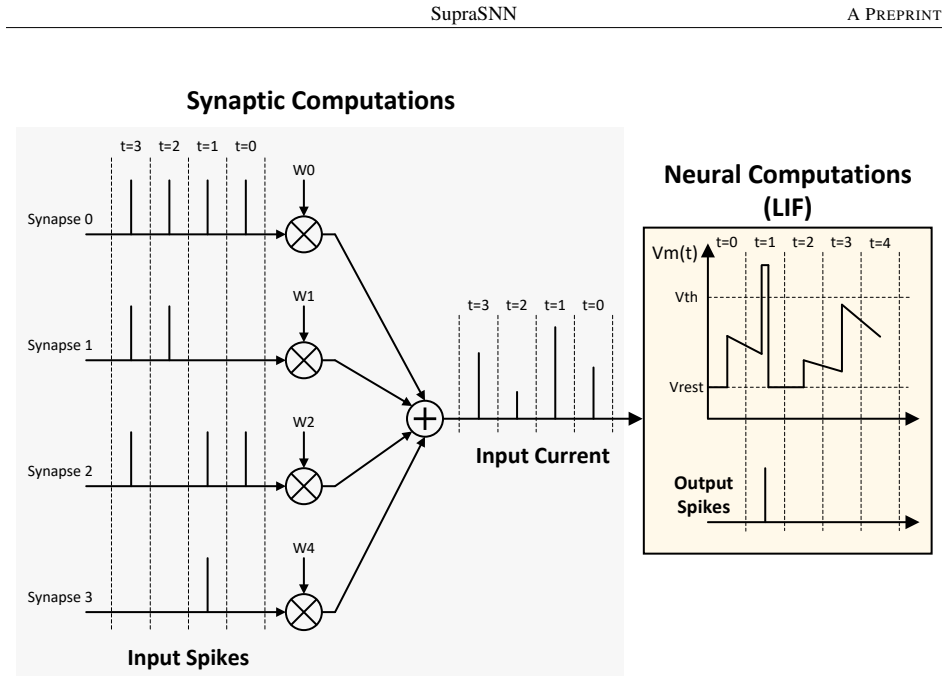
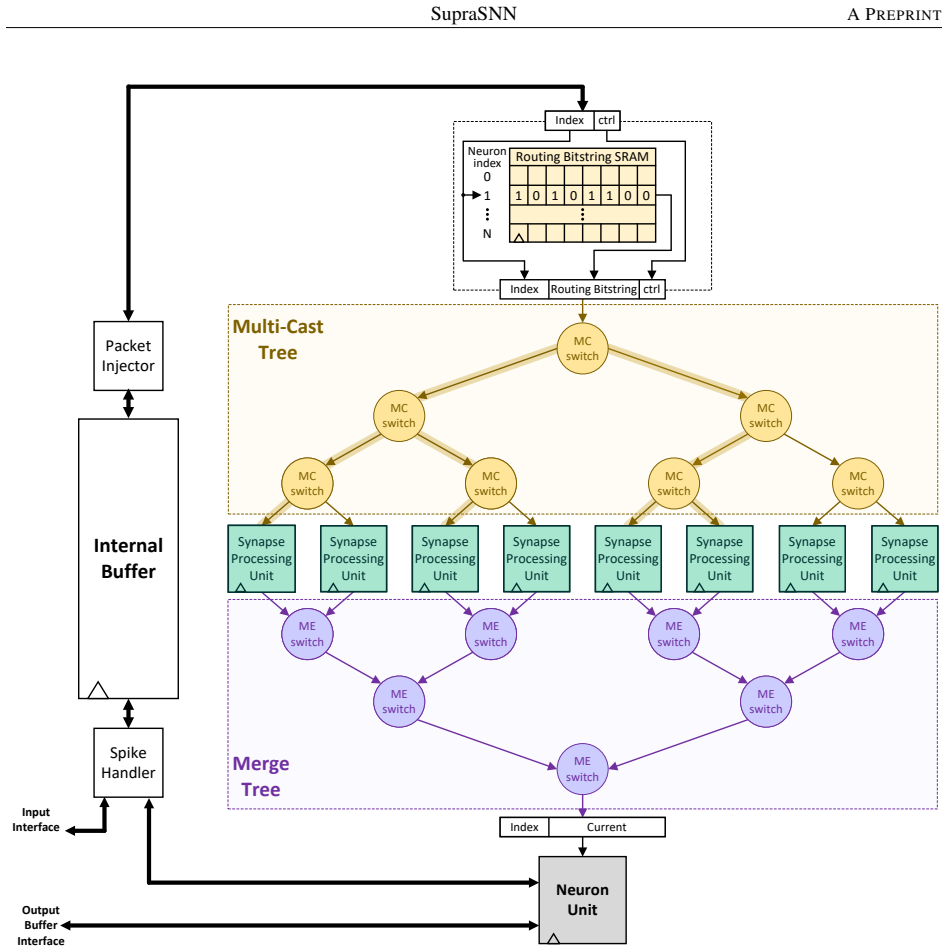
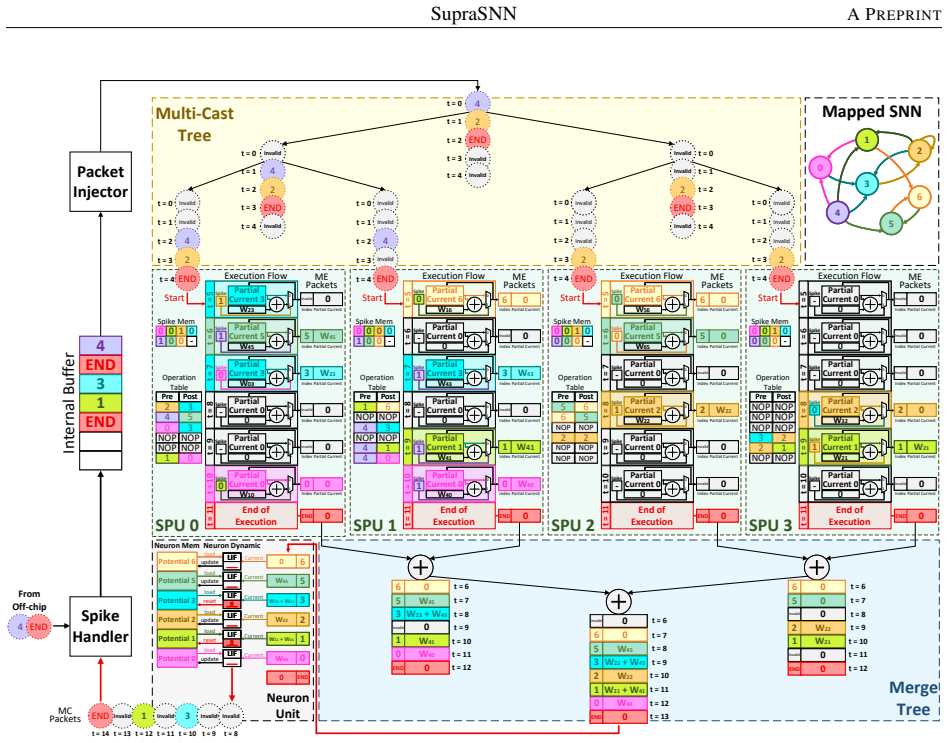
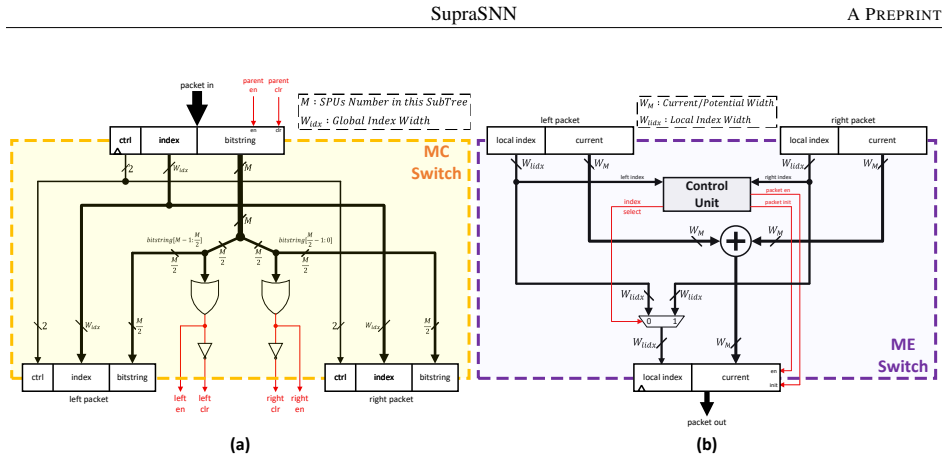
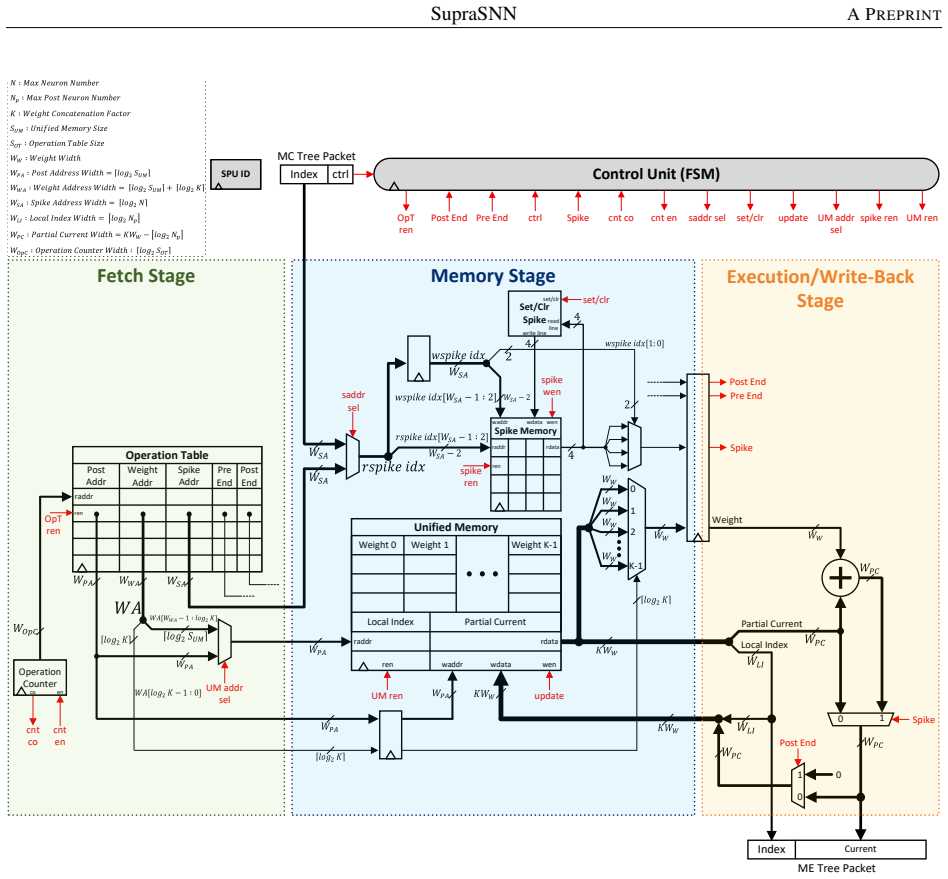
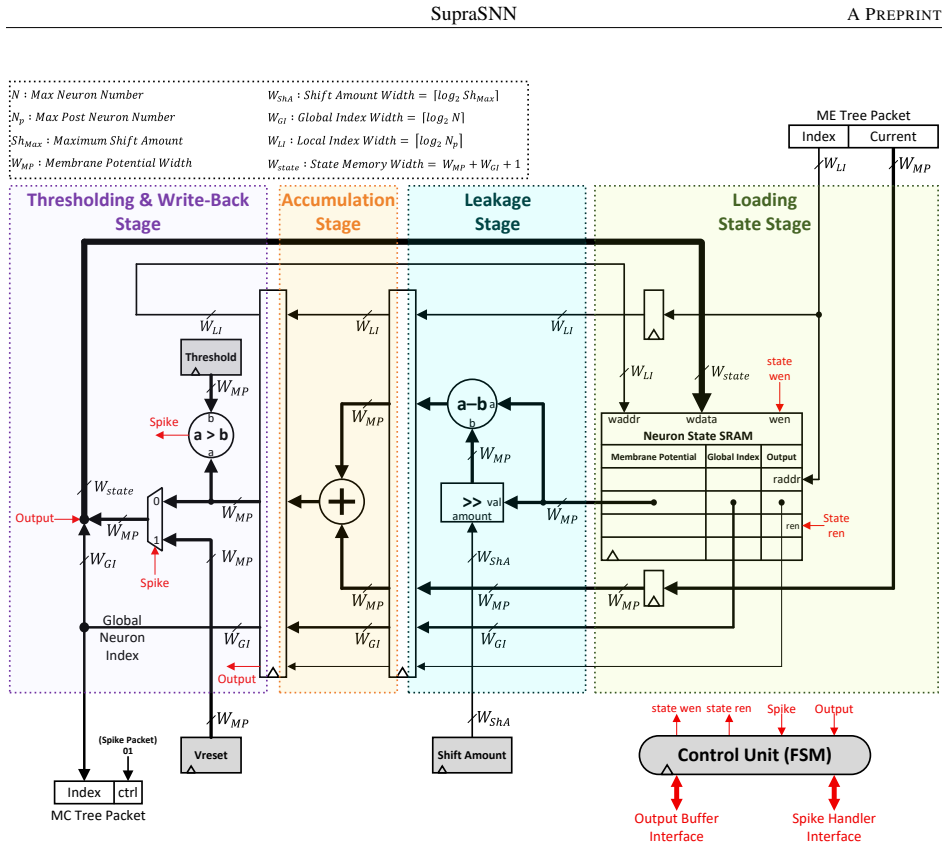
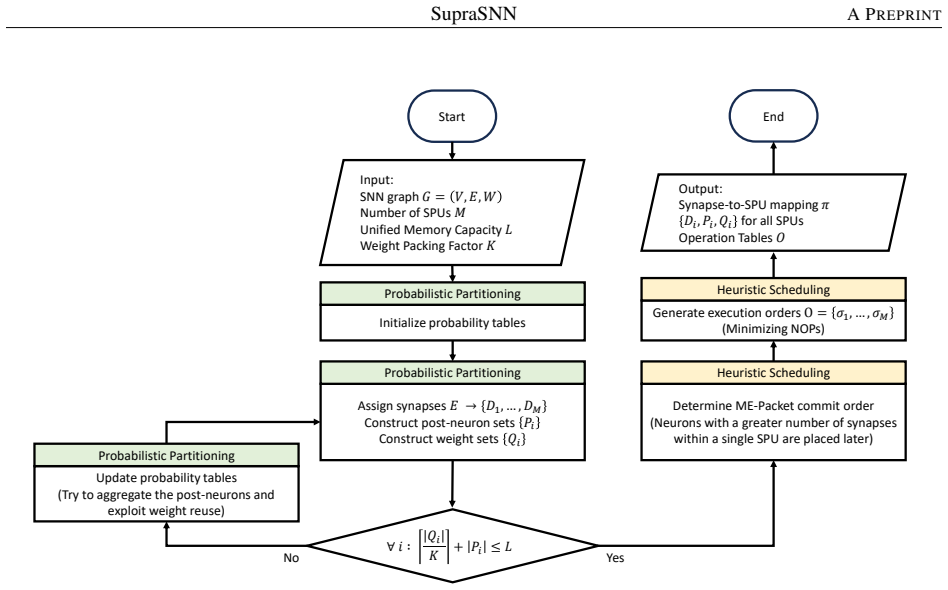
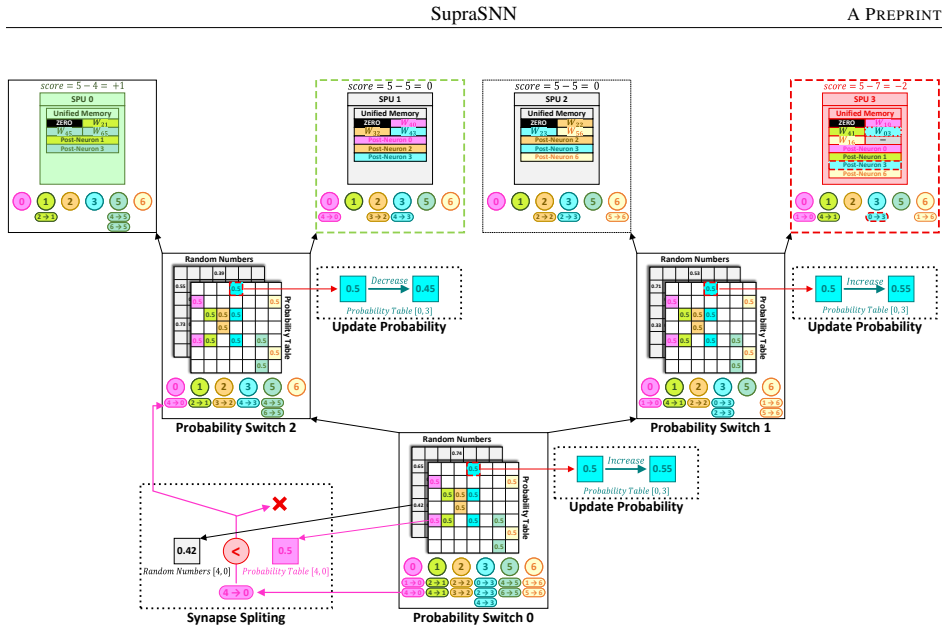
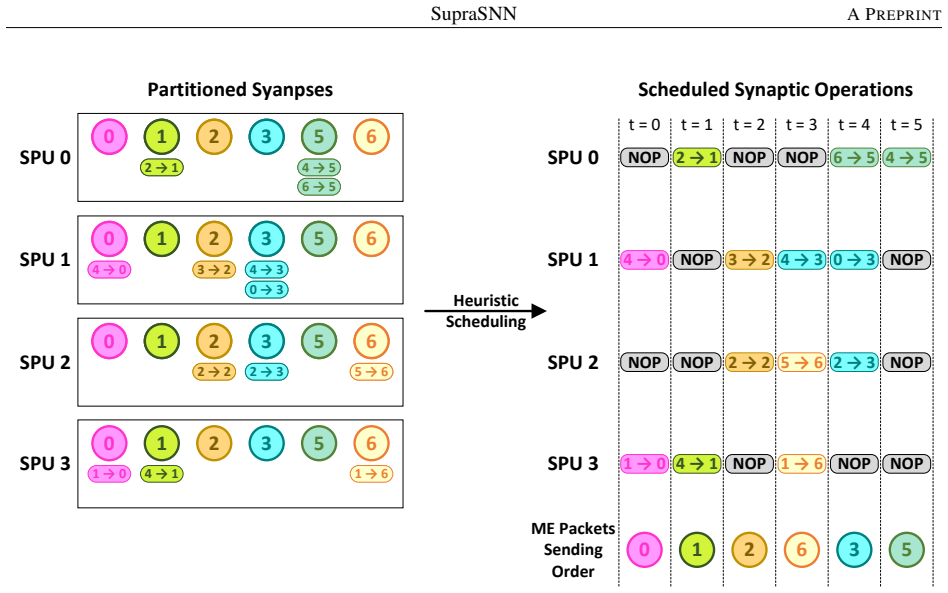
SupraSNN presents a hardware architecture that physically decouples synaptic computations from neuronal state updates, routing spikes through a Multi-Cast Tree to parallel Synapse Processing Units whose outputs are consolidated by a Merge Tree into a single Neuron Unit, with efficacy provided by a partitioning and heuristic scheduling framework that first maps the SNN under memory limits and then orders synaptic executions to maximize throughput and resource utilization.
What carries the argument
The decoupled superscalar-inspired architecture of Multi-Cast Tree, parallel Synapse Processing Units, Merge Tree, and unified Neuron Unit, supported by the partitioning and heuristic scheduling framework.
If this is right
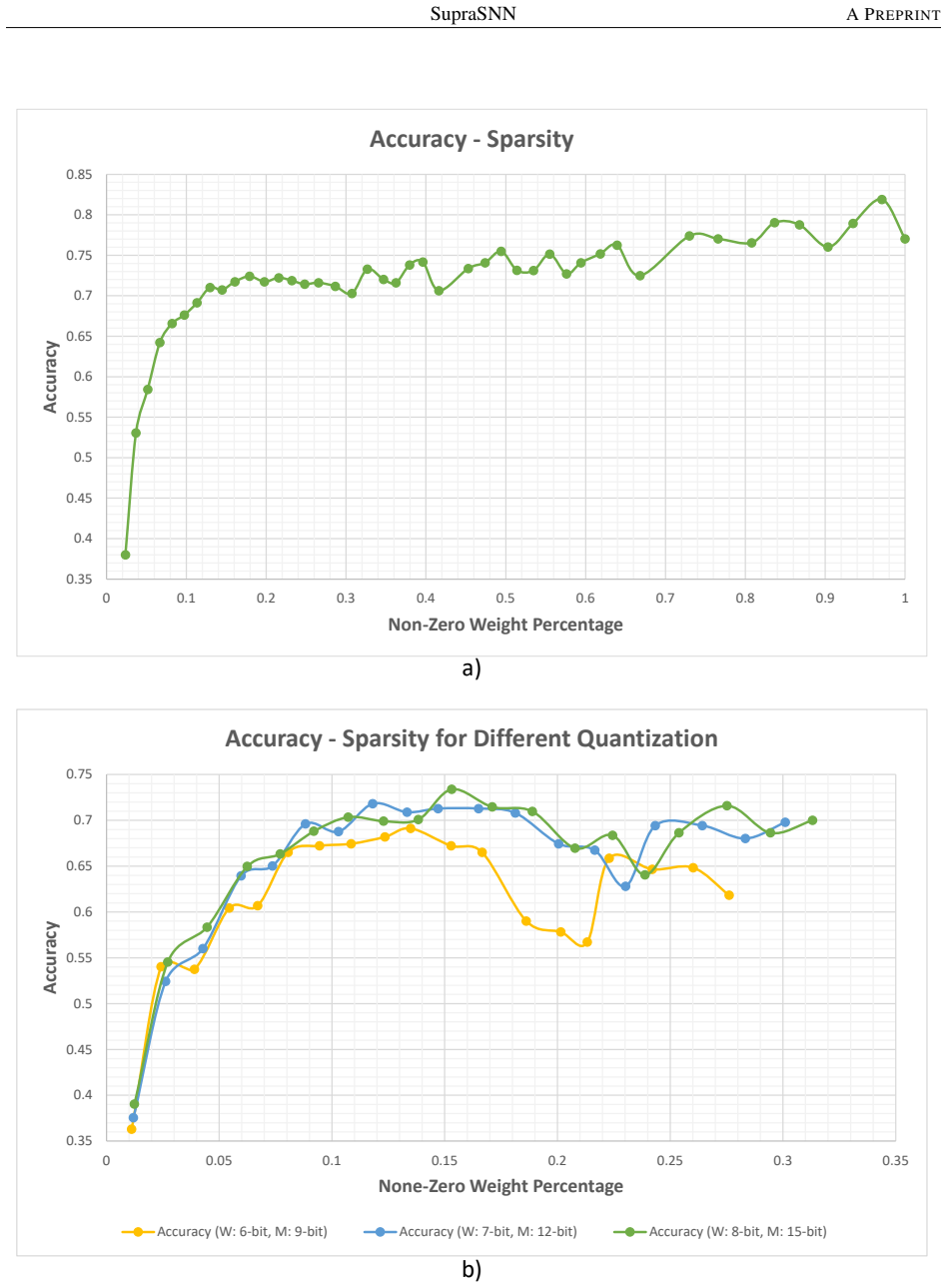
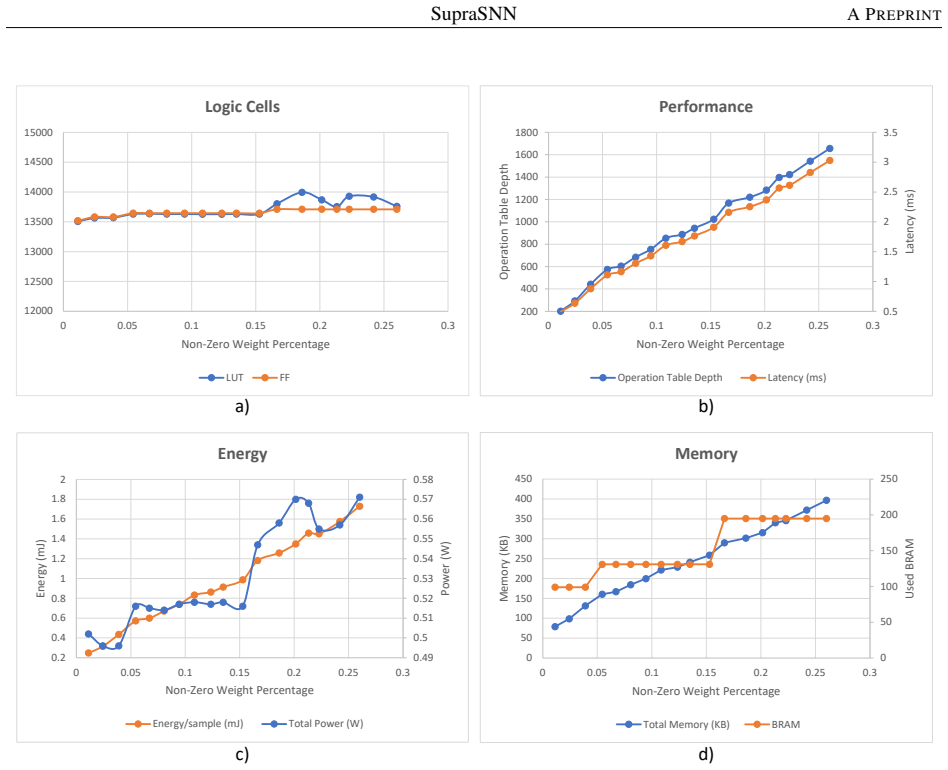
- The architecture reaches 149 microseconds inference latency and 0.025 millijoules per image (0.276 nanojoules per synapse) for a 93.44 percent accurate feedforward SNN on MNIST.
- It delivers 47.6 percent lower latency and 5.6 times better energy efficiency than prior FPGA-based SNN accelerators.
- A recurrent SNN on the Spiking Heidelberg Dataset achieves 1.41 milliseconds latency and 0.77 millijoules per sample at 71.82 percent accuracy on an XC7Z030 device.
- Centralizing neuron dynamics in one unit reduces hardware overhead and avoids duplicating complex state logic across many units.
Where Pith is reading between the lines
- The number of Synapse Processing Units could be increased on larger FPGAs to scale throughput for deeper networks while neuron hardware stays fixed.
- The same separation of event routing from state update could be applied to other sparse, event-driven workloads beyond spiking networks.
- Replacing the heuristic scheduler with an automated search might further improve utilization when memory constraints change.
Load-bearing premise
The partitioning and scheduling framework can map the SNN onto hardware and order synaptic executions to raise throughput and utilization without adding unaccounted overhead from the decoupled units.
What would settle it
Running the same MNIST-trained feedforward SNN on the Xilinx Zynq XC7Z020 and measuring inference latency above 149 microseconds or energy above 0.025 millijoules per image, or finding no improvement over the cited prior FPGA accelerators.
Figures
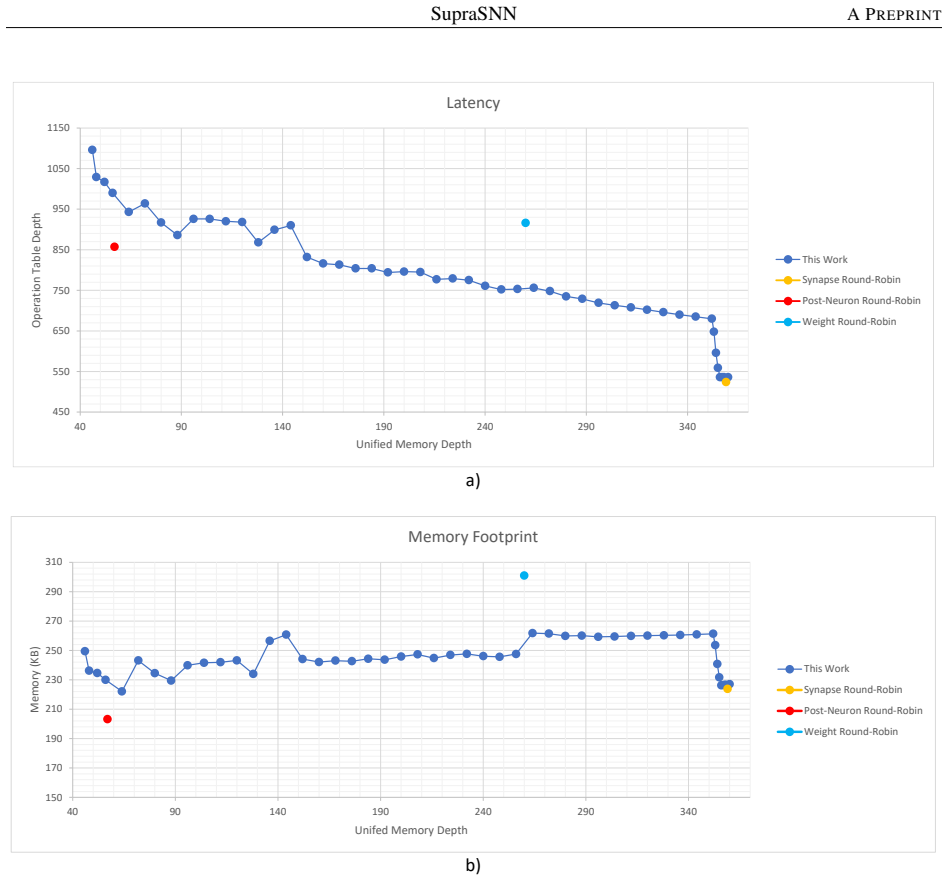
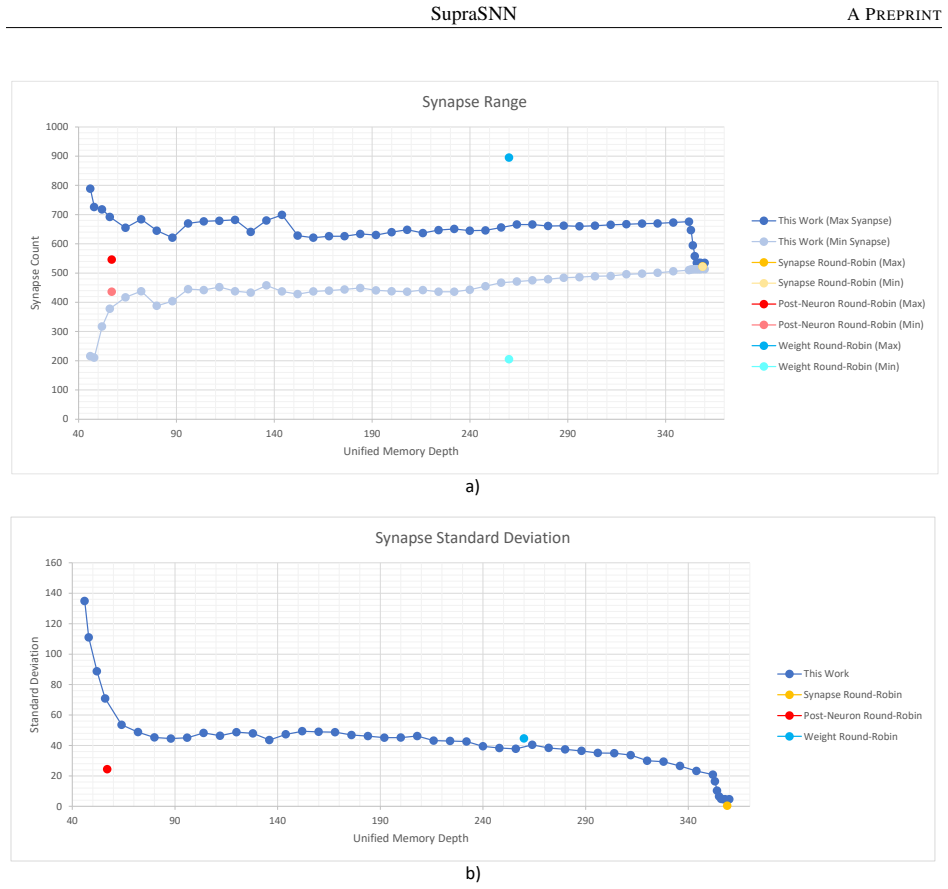
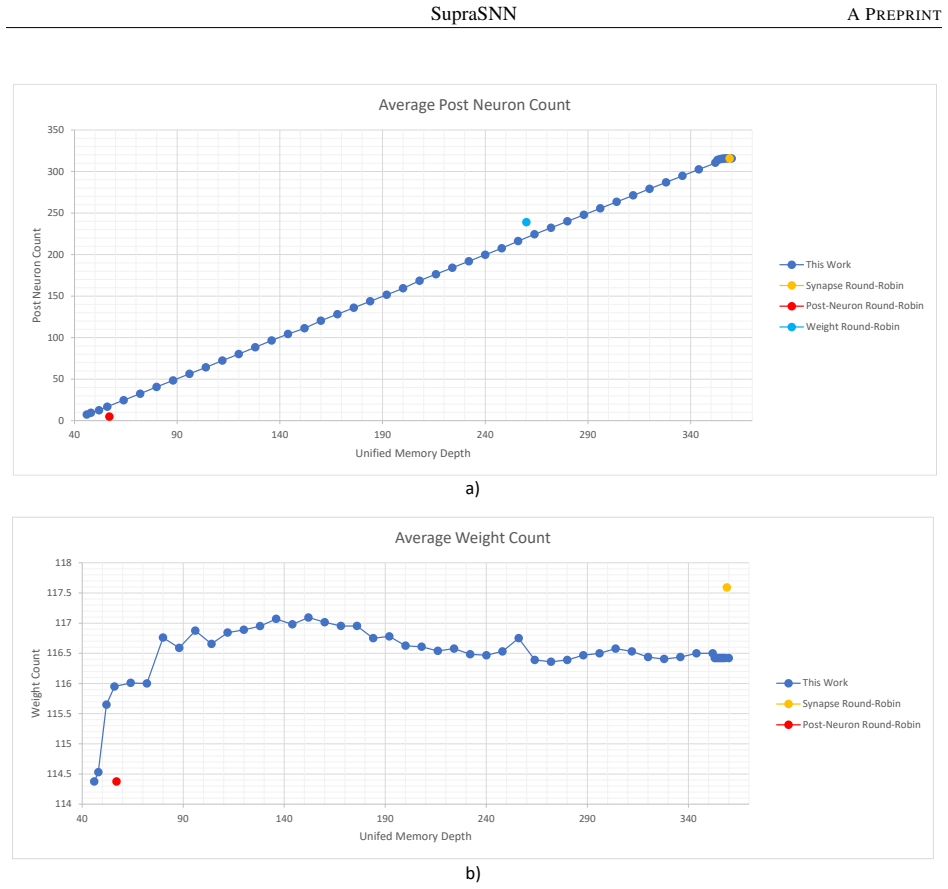
read the original abstract
Spiking Neural Networks (SNNs) offer a brain-inspired path toward highly efficient computation, but their practical deployment is constrained by the challenge of managing and executing their massive parallelism on physical hardware. This problem mirrors the historical challenge in processor design of moving beyond serial execution, a barrier broken by superscalar architectures that dispatch multiple instructions to parallel functional units. Drawing inspiration from this paradigm, we introduce a hardware-software co-design framework that treats synaptic events as parallelizable micro-operations. We present SupraSNN, a superscalar-inspired architecture that achieves high synapse-level parallelism by physically decoupling synaptic and neuronal computations. Within this architecture, a Multi-Cast Tree routes spike data to multiple parallel Synapse Processing Units serve as the computational pipelines, while a Merge Tree consolidates distributed results for processing by a unified Neuron Unit--deliberately centralizing complex neuron state dynamics to mitigate hardware overhead and resource duplication. The efficacy of this architecture is enabled by a sophisticated partitioning and scheduling framework that first maps the SNN onto hardware respecting memory constraints, then heuristic scheduling determines the synaptic execution order, maximizing throughput and resource utilization. Implementing a feedforward SNN trained on MNIST (93.44% accuracy), SupraSNN achieves 149 $\mu s$ inference latency and 0.025 mJ per image (0.276 nJ per synapse) on the Xilinx Zynq XC7Z020 FPGA--delivering 47.6% lower latency and 5.6$\times$ better energy efficiency than prior FPGA-based SNN accelerators. Beyond vision tasks, a recurrent SNN on the Spiking Heidelberg Dataset (71.82% accuracy) achieves 1.41 ms latency and 0.77 mJ per sample on XC7Z030.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SupraSNN, a superscalar-inspired SNN accelerator architecture that decouples synaptic computation (via Multi-Cast Tree and parallel Synapse Processing Units) from neuronal state updates (via Merge Tree and centralized Neuron Unit) to exploit synapse-level parallelism. A co-optimized partitioning and heuristic scheduling framework maps feedforward and recurrent SNNs to FPGA hardware while respecting memory constraints. On a Xilinx Zynq XC7Z020, a MNIST-trained feedforward SNN (93.44% accuracy) achieves 149 μs latency and 0.025 mJ per image (0.276 nJ/synapse), claimed to be 47.6% lower latency and 5.6× more energy-efficient than prior FPGA SNN accelerators; a recurrent SNN on the Spiking Heidelberg Dataset reports 1.41 ms latency and 0.77 mJ per sample on XC7Z030.
Significance. If the overhead attribution holds, the work demonstrates a practical path to high synapse-level parallelism in SNN accelerators on resource-limited FPGAs, with concrete measured results that could influence co-design approaches for event-driven hardware. The explicit FPGA implementation and cross-dataset evaluation provide reproducible baselines for the field.
major comments (2)
- [Evaluation] Evaluation section: The headline claims of 149 μs latency and 0.025 mJ/image (with 47.6% and 5.6× improvements) are presented without a cycle-accurate breakdown or power measurement that isolates overheads from the Multi-Cast Tree routing, Merge Tree consolidation, heuristic scheduling, and buffering in the deliberately decoupled architecture versus an idealized fully-parallel execution. This directly affects whether the gains can be attributed to synapse-level parallelism.
- [Mapping and Scheduling Framework] Scheduling framework description: The heuristic scheduling that determines synaptic execution order after partitioning is described at a high level but lacks quantitative characterization of its runtime overhead, worst-case utilization loss, or comparison against an oracle schedule that would be feasible if memory constraints were ignored.
minor comments (2)
- [Abstract] The abstract states comparisons to 'prior FPGA-based SNN accelerators' without naming the specific baselines or their reported metrics in the same paragraph; this should be clarified for immediate context.
- [Results] Notation for energy per synapse (0.276 nJ per synapse) is introduced without an explicit equation showing how total energy is normalized by synapse count across the network.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The headline claims of 149 μs latency and 0.025 mJ/image (with 47.6% and 5.6× improvements) are presented without a cycle-accurate breakdown or power measurement that isolates overheads from the Multi-Cast Tree routing, Merge Tree consolidation, heuristic scheduling, and buffering in the deliberately decoupled architecture versus an idealized fully-parallel execution. This directly affects whether the gains can be attributed to synapse-level parallelism.
Authors: The reported latency and energy figures are end-to-end measurements obtained from the actual FPGA implementation on the target device, which necessarily incorporate all overheads of the Multi-Cast Tree, Merge Tree, scheduling, and buffering. Direct comparison is made to prior FPGA SNN accelerators that likewise report full-system metrics. We agree that finer-grained attribution would strengthen the paper. In the revised manuscript we add a new subsection (Section 5.4) containing a cycle-accurate breakdown derived from the implemented design and Xilinx power analysis that quantifies the contribution of each architectural component relative to the overall gains. revision: yes
-
Referee: [Mapping and Scheduling Framework] Scheduling framework description: The heuristic scheduling that determines synaptic execution order after partitioning is described at a high level but lacks quantitative characterization of its runtime overhead, worst-case utilization loss, or comparison against an oracle schedule that would be feasible if memory constraints were ignored.
Authors: We acknowledge that the original description of the heuristic was high-level. The revised manuscript expands Section 4.3 with quantitative data: measured host-CPU runtime of the scheduler, observed utilization loss across the evaluated networks, and a comparison against an idealized schedule that relaxes memory constraints (showing the heuristic remains within a modest bound of the oracle). We note that a true memory-ignorant oracle cannot be realized on the resource-limited FPGA, but the added analysis bounds the impact of the memory-aware decisions. revision: yes
Circularity Check
No circularity: empirical FPGA measurements with no fitted predictions or self-referential derivations
full rationale
The paper reports measured latency (149 μs) and energy (0.025 mJ/image) from direct FPGA implementation of a feedforward SNN on MNIST, plus a recurrent SNN on SHD. The architecture description (Multi-Cast Tree, Synapse Processing Units, Merge Tree, partitioning + heuristic scheduling) is presented as a design choice whose efficacy is validated by hardware execution, not by any equation, parameter fit, or self-citation that reduces the reported numbers to the inputs by construction. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the provided text. The central claims rest on external benchmark comparisons and physical measurements rather than internal re-derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Efficient Processing of Spatio-Temporal Data Streams With Spiking Neural Networks,
A. Kugele, T. Pfeil, M. Pfeiffer, and E. Chicca, “Efficient Processing of Spatio-Temporal Data Streams With Spiking Neural Networks,”Frontiers in Neuroscience, vol. 14, art. no. 439, 2020, doi: 10.3389/fnins.2020.00439
-
[2]
J. K. Eshraghian et al., “Training Spiking Neural Networks Using Lessons From Deep Learning,” inProceedings of the IEEE, vol. 111, no. 9, pp. 1016-1054, Sept. 2023, doi: 10.1109/JPROC.2023.3308088
-
[3]
Networks of Spiking Neurons: The Third Generation of Neural Network Models,
W. Maass, “Networks of Spiking Neurons: The Third Generation of Neural Network Models,”Neural Networks, vol. 10, no. 9, pp. 1659–1671, Dec. 1997, doi: 10.1016/S0893-6080(97)00011-7. 27 SupraSNNA PREPRINT
-
[4]
A. Bhattacharjee, R. Yin, A. Moitra, and P. Panda, “Are SNNs Truly Energy-efficient? – A Hardware Perspective,” ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, Republic of, 2024, pp. 13311-13315, doi: 10.1109/ICASSP48485.2024.10448269
-
[5]
A Survey of Neuromorphic Computing and Neural Networks in Hardware
C. D. Schuman et al., “A Survey of Neuromorphic Computing and Neural Networks in Hardware,”arXiv preprint arXiv:1705.06963, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
Analog Memristive Synapse in Spiking Networks Implementing Unsupervised Learning,
E. Covi, S. Brivio, A. Serb, T. Prodromakis, M. Fanciulli, and S. Spiga, “Analog Memristive Synapse in Spiking Networks Implementing Unsupervised Learning,”Frontiers in Neuroscience, vol. 10, art. no. 482, Oct. 2016, doi: 10.3389/fnins.2016.00482
-
[7]
(5) Strakosas, X.; Bongo, M.; Owens, R
E. Chicca, F. Stefanini, C. Bartolozzi, and G. Indiveri, “Neuromorphic Electronic Circuits for Building Au- tonomous Cognitive Systems,” inProceedings of the IEEE, vol. 102, no. 9, pp. 1367-1388, Sept. 2014, doi: 10.1109/JPROC.2014.2313954
-
[8]
S. Moradi, N. Qiao, F. Stefanini, and G. Indiveri, “A Scalable Multicore Architecture With Heterogeneous Memory Structures for Dynamic Neuromorphic Asynchronous Processors (DYNAPs),” inIEEE Transactions on Biomedical Circuits and Systems, vol. 12, no. 1, pp. 106-122, Feb. 2018, doi: 10.1109/TBCAS.2017.2759700
-
[9]
Neurogrid: A Mixed-Analog-Digital Multichip System for Large-Scale Neural Simulations,
B. V . Benjamin et al., “Neurogrid: A Mixed-Analog-Digital Multichip System for Large-Scale Neural Simulations,” inProceedings of the IEEE, vol. 102, no. 5, pp. 699-716, May 2014, doi: 10.1109/JPROC.2014.2313565
-
[10]
M. Davies et al., “Loihi: A Neuromorphic Manycore Processor with On-Chip Learning,” inIEEE Micro, vol. 38, no. 1, pp. 82-99, January/February 2018, doi: 10.1109/MM.2018.112130359
-
[11]
TrueNorth: Design and Tool Flow of a 65 mW 1 Million Neuron Programmable Neurosynaptic Chip,
F. Akopyan et al., “TrueNorth: Design and Tool Flow of a 65 mW 1 Million Neuron Programmable Neurosynaptic Chip,” inIEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 34, no. 10, pp. 1537-1557, Oct. 2015, doi: 10.1109/TCAD.2015.2474396
-
[12]
A deterministic neuromorphic architecture with scalable time synchronization,
C. Li, I. Nabil, and M. Rajit, “A deterministic neuromorphic architecture with scalable time synchronization,” Nature Communications, vol. 16, art. no. 10329, Mar. 2025, doi: 10.1038/s41467-025-65268-z
-
[13]
Scaling mixed-signal neuromorphic processors to 28 nm FD-SOI technologies,
N. Qiao and G. Indiveri, “Scaling mixed-signal neuromorphic processors to 28 nm FD-SOI technologies,”arXiv preprint arXiv:1908.07411v1, 2019
-
[14]
A. Gebregiorgis et al., “Spike-based neuromorphic computing: An overview from bio-inspiration to hard- ware architectures and learning mechanisms,”Microprocessors and Microsystems, art. no. 105421, 2025, doi: 10.1016/j.micpro.2025.105240
-
[15]
Stitch-X: An Accelerator Architecture for Exploiting Unstructured Sparsity in Deep Neural Networks,
C. Lee et al., “Stitch-X: An Accelerator Architecture for Exploiting Unstructured Sparsity in Deep Neural Networks,” inProceedings of the SysML Conference, 2018
2018
-
[16]
Computer Architecture: A Quantitative Approach,
J.L. Hennessy and D.A. Patterson, “Computer Architecture: A Quantitative Approach,” 6th ed., Morgan Kaufmann, 2017
2017
-
[17]
A superscalar architecture to exploit instruction level parallelism,
G. Steven, B. Christianson, R. Collins, R. Potter, and F. Steven, “A superscalar architecture to exploit instruction level parallelism,”Microprocessors and Microsystems, vol. 20, no. 7, pp. 391-400, 1997
1997
-
[18]
SaARSP: An Architecture for Systolic-Array Acceleration of Recurrent Spiking Neural Networks,
J. Lee, W. Zhang, Y . Xie, and P. Li, “SaARSP: An Architecture for Systolic-Array Acceleration of Recurrent Spiking Neural Networks,”ACM Journal on Emerging Technologies in Computing Systems (JETC), vol. 18, no. 4, pp. 1-23, Oct. 2022, doi: 10.1145/3510854
-
[19]
EIE: Efficient Inference Engine on Compressed Deep Neural Network,
S. Han et al., “EIE: Efficient Inference Engine on Compressed Deep Neural Network,” inProceedings of the 43rd ACM/IEEE International Symposium on Computer Architecture (ISCA), vol. 44, no. 3, 2016, pp. 243-254, doi: 10.1145/3007787.3001163
-
[20]
The MNIST database of handwritten digits,
Y . LeCun and C. Cortes, “The MNIST database of handwritten digits,” 1998 [Online]
1998
-
[21]
The Heidelberg Spiking Data Sets for the Systematic Evaluation of Spiking Neural Networks,
B. Cramer, Y . Stradmann, J. Schemmel, and F. Zenke, “The Heidelberg Spiking Data Sets for the Systematic Evaluation of Spiking Neural Networks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 7, pp. 2744–2757, Jul. 2022
2022
-
[22]
Spiking Neuron Models: Single Neurons, Populations, Plasticity,
W. Gerstner and WM. Kistler, “Spiking Neuron Models: Single Neurons, Populations, Plasticity,”Cambridge University Press, 2002
2002
-
[23]
Deep Learning With Spiking Neurons: Opportunities and Challenges,
M. Pfeiffer and T. Pfeil, “Deep Learning With Spiking Neurons: Opportunities and Challenges,”Frontiers in Neuroscience, vol. 12, art. no. 774, Oct. 2018, doi: 10.3389/fnins.2018.00774
-
[24]
K. Roy, A. Jaiswal, and P. Panda, “Towards Spike-Based Machine Intelligence with Neuromorphic Computing,” Nature, vol. 575, pp. 607-617, Nov. 2019, doi: 10.1038/s41586-019-1677-2
-
[25]
Deep learning in spiking neural networks,
A. Tavanaei, M. Ghodrati, SR. Kheradpisheh, T. Masquelier, and A. Maida, “Deep learning in spiking neural networks,”Neural Networks, vol. 111, pp. 47-63, Mar. 2019, doi: 10.1016/j.neunet.2018.12.002. 28 SupraSNNA PREPRINT
-
[26]
Spiking Neural Networks: A Survey,
J. D. Nunes, M. Carvalho, D. Carneiro, and J. S. Cardoso, "Spiking Neural Networks: A Survey," inIEEE Access, vol. 10, pp. 60738-60764, 2022, doi: 10.1109/ACCESS.2022.3179968
-
[27]
Rethinking the Performance Comparison Between SNNs and ANNs,
L. Deng, Y . Wu, X. Hu, et al., “Rethinking the Performance Comparison Between SNNs and ANNs,”Neural Networks, vol. 121, pp. 294-307, 2020
2020
-
[28]
A quantitative description of membrane current and its application to conduction and excitation in nerve,
A. L. Hodgkin and A. F. Huxley, “A quantitative description of membrane current and its application to conduction and excitation in nerve,”Journal of Physiology, vol. 117, no. 4, pp. 500-544, 1952
1952
-
[29]
Simple model of spiking neurons,
E. M. Izhikevich, “Simple model of spiking neurons,”IEEE Transactions on Neural Networks, vol. 14, no. 6, pp. 1569-1572, 2003
2003
-
[30]
A 0.086-mm^2 12.7-pJ/SOP 64k-Synapse 256-Neuron Online- Learning Digital Spiking Neuromorphic Processor in 28-nm CMOS,
C. Frenkel, M. Lefebvre, J.-D. Legat, and D. Bol, “A 0.086-mm^2 12.7-pJ/SOP 64k-Synapse 256-Neuron Online- Learning Digital Spiking Neuromorphic Processor in 28-nm CMOS,”IEEE Transactions on Biomedical Circuits and Systems, vol. 13, no. 1, pp. 145-158, Feb. 2019
2019
-
[31]
Point-to-point connectivity between neuromorphic chips using address events,
K. A. Boahen, “Point-to-point connectivity between neuromorphic chips using address events,”IEEE Transactions on Circuits and Systems II, vol. 47, no. 5, pp. 416-434, 2000
2000
-
[32]
Spiker+: A Framework for the Generation of Efficient Spiking Neural Networks FPGA Accelerators for Inference at the Edge,
A. Carpegna, A. Savino and S. D. Carlo, “Spiker+: A Framework for the Generation of Efficient Spiking Neural Networks FPGA Accelerators for Inference at the Edge,”IEEE Transactions on Emerging Topics in Computing, pp. 1-15, 2024
2024
-
[33]
Mapping Spiking Neural Networks to Neuromorphic Hardware,
A. Balaji et al., “Mapping Spiking Neural Networks to Neuromorphic Hardware,” inIEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 28, no. 1, pp. 76-86, Jan. 2020, doi: 10.1109/TVLSI.2019.2951493
-
[34]
Synapse-Centric Mapping of Cortical Models to the SpiNNaker Neuromorphic Architecture,
J. C. Knight and S. B. Furber, “Synapse-Centric Mapping of Cortical Models to the SpiNNaker Neuromorphic Architecture,”Frontiers in Neuroscience, vol. 10, art. no. 420, Sept. 2016, doi: 10.3389/fnins.2016.00420
-
[35]
SpiNNaker: Mapping neural networks onto a massively-parallel chip multiprocessor,
M. M. Khan et al., “SpiNNaker: Mapping neural networks onto a massively-parallel chip multiprocessor,” in2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 2008, pp. 2849-2856, doi: 10.1109/IJCNN.2008.4634199
-
[36]
A hierachical configuration system for a massively parallel neural hardware platform,
F. Galluppi, S. Davies, A. Rast, T. Sharp, L. A. Plana, and S. Furber, “A hierachical configuration system for a massively parallel neural hardware platform,” inInternational Conference on Computing Frontiers, 2012
2012
-
[37]
MAERI: Enabling Flexible Dataflow Mapping over DNN Accelerators via Reconfigurable Interconnects,
H. Kwon, A. Samajdar, and T. Krishna, “MAERI: Enabling Flexible Dataflow Mapping over DNN Accelerators via Reconfigurable Interconnects,” inProc. 23rd Int. Conf. Architectural Support for Programming Languages and Operating Systems (ASPLOS), pp. 461–475, Mar. 2018
2018
-
[38]
Hardware implementation of spiking neural networks on FPGA,
J. Han, Z. Li,W. Zheng, and Y . Zhang, “Hardware implementation of spiking neural networks on FPGA,”Tsinghua Science and Technology, vol. 25, no. 4, pp. 479–486, Aug. 2020, doi: 10.26599/TST.2019.9010019
-
[39]
FPGA Implementation of Simplified Spiking Neural Network,
S. Gupta, A. Vyas, and G. Trivedi, “FPGA Implementation of Simplified Spiking Neural Network,” in2020 27th IEEE International Conference on Electronics, Circuits and Systems (ICECS), pp. 1–4, Nov. 2020
2020
-
[40]
S. Li, Z. Zhang, R. Mao, J. Xiao, L. Chang and J. Zhou, “A Fast and Energy-Efficient SNN Processor With Adaptive Clock/Event-Driven Computation Scheme and Online Learning,” inIEEE Transactions on Circuits and Systems I: Regular Papers, vol. 68, no. 4, pp. 1543-1552, April 2021, doi: 10.1109/TCSI.2021.3052885
-
[41]
Spiker: an FPGA-optimized Hardware accelerator for Spiking Neural Networks,
A. Carpegna, A. Savino and S. Di Carlo, “Spiker: an FPGA-optimized Hardware accelerator for Spiking Neural Networks,” in2022 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Nicosia, Cyprus, pp. 14-19, 2022, doi: 10.1109/ISVLSI54635.2022.00016. 29
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.