TrustMargin: Training-Free Arbitration between Parametric Memory and Retrieved Evidence in Large Language Models
Pith reviewed 2026-06-27 18:58 UTC · model grok-4.3
The pith
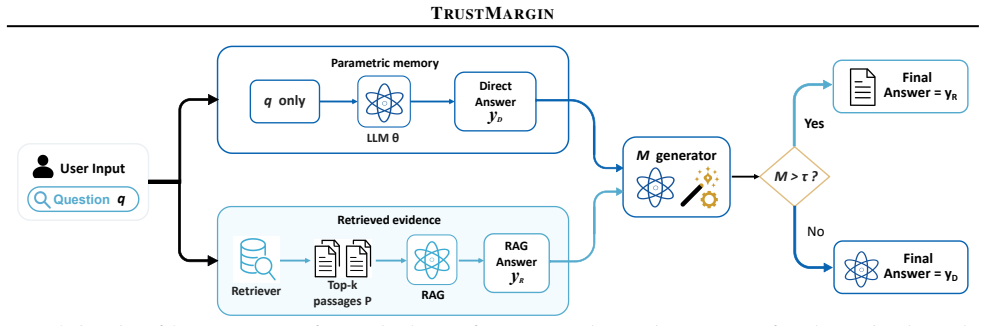
TRUSTMARGIN selects between an LLM's direct answer and its RAG answer using two margins computed from the model's own likelihood scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
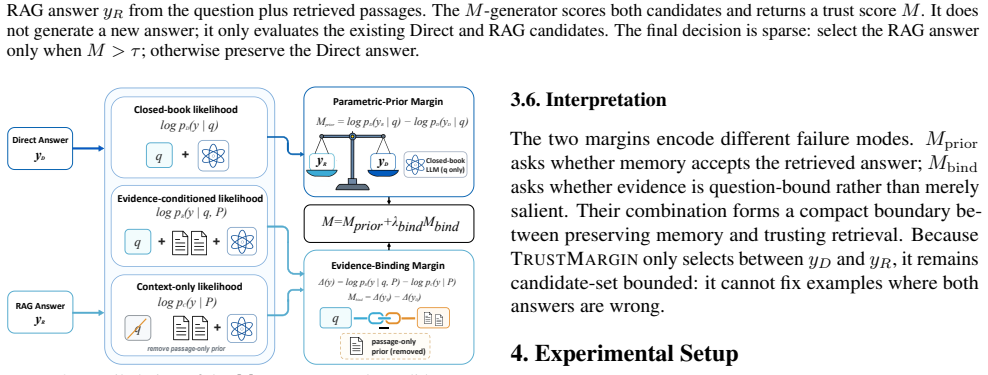
TRUSTMARGIN is a training-free arbitration layer that scores the Direct and RAG candidates with a parametric-prior margin testing memory acceptance of the retrieved answer plus an evidence-binding margin discounting passage-only salience and measuring question-specific support, then selects the higher-scoring source using only the model's existing likelihoods.
What carries the argument
Parametric-prior margin and evidence-binding margin derived from the model's likelihoods on the two candidate answers.
If this is right
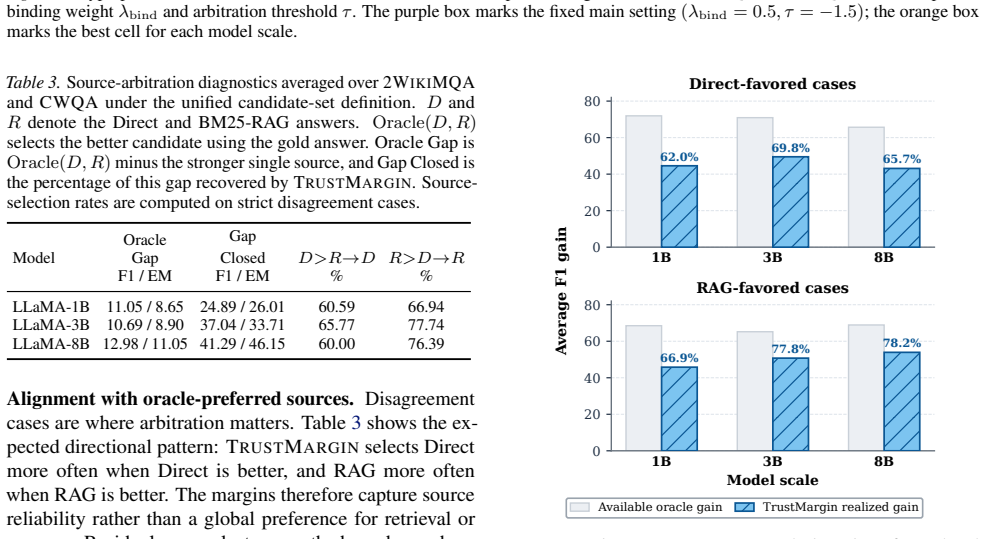
- TRUSTMARGIN improves accuracy over both Direct generation and BM25-RAG on 2WIKIMQA and CWQA.
- It recovers part of the gap to an oracle that always chooses the better of the two sources.
- The same margins generalize across multiple training-free RAG pipelines.
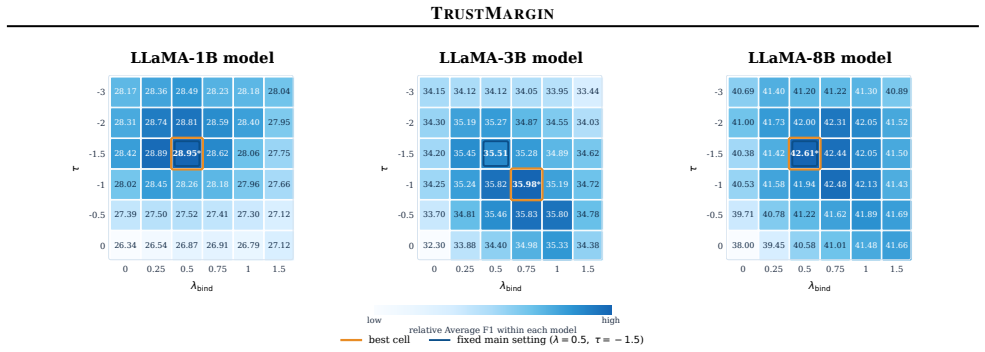
- The gains hold for three different LLaMA model scales.
Where Pith is reading between the lines
- The same likelihood-based margins could be applied to arbitrate among more than two sources in a single generation step.
- If the margins prove stable, they might replace heavier reranking or judge models in retrieval pipelines.
- The approach suggests that internal probability signals already encode enough information to resolve common knowledge conflicts without extra supervision.
Load-bearing premise
The model's likelihood scores on the generated answers can be used directly to measure source trustworthiness via the two defined margins without needing external validation or task-specific calibration.
What would settle it
On a held-out set the method would be falsified if the answer it selects is less accurate than the answer it rejects across a majority of questions.
Figures


read the original abstract
Large language models answer knowledge-intensive questions using both parametric memory and retrieved evidence, but neither source is uniformly reliable. Retrieval can fill knowledge gaps, yet distracting passages may override correct closed-book answers. We study this post-generation conflict as answer-level source arbitration: given Direct and RAG answers from the same frozen model, decide which source to trust. We propose TRUSTMARGIN, a training-free, plug-and-play arbitration layer that scores the two existing candidates with the model's own likelihoods. It combines a parametric-prior margin, which tests whether memory accepts the retrieved answer, with an evidence-binding margin, which discounts passage-only salience and measures question-specific support. TRUSTMARGIN selects between Direct and RAG without fine-tuning, external judges, or additional generation. Across 2WIKIMQA and CWQA with three LLaMA scales, TRUSTMARGIN consistently improves over Direct generation and BM25-RAG, recovers part of the Direct/RAG oracle gap, and generalizes to multiple training-free RAG pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TRUSTMARGIN, a training-free arbitration layer for LLMs that, given Direct (parametric) and RAG answers from the same frozen model, computes a parametric-prior margin (testing whether memory accepts the RAG answer) and an evidence-binding margin (discounting passage-only salience) from the model's likelihoods on the two candidates, then selects the higher-margin source. It reports consistent gains over Direct and BM25-RAG on 2WIKIMQA and CWQA across three LLaMA scales, partial recovery of the Direct/RAG oracle gap, and generalization to other training-free RAG pipelines.
Significance. If the likelihood-derived margins reliably indicate source trustworthiness, the approach would be significant as a lightweight, plug-and-play addition to existing RAG pipelines that requires no fine-tuning, external judges, or extra generation; the training-free nature and reported generalization across datasets and pipelines are clear strengths.
major comments (2)
- [Abstract and method definition] The central arbitration rule rests on the unvalidated assumption that the two margins computed directly from frozen-model likelihoods on the candidate answers proxy factual trustworthiness rather than fluency, length, or other surface artifacts; the abstract states the margins are used 'directly' with no mention of calibration, correlation analysis against ground-truth correctness, or controls for confounds.
- [Abstract] Abstract: the claims of 'consistent improvements' and 'recovers part of the Direct/RAG oracle gap' are presented without details on exact margin formulas, statistical significance testing, variance across runs, or ablation of the two margins' individual contributions.
minor comments (1)
- [§3] Notation for the two margins should be introduced with explicit equations early in the method section to allow readers to verify the 'parameter-free' claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment point-by-point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and method definition] The central arbitration rule rests on the unvalidated assumption that the two margins computed directly from frozen-model likelihoods on the candidate answers proxy factual trustworthiness rather than fluency, length, or other surface artifacts; the abstract states the margins are used 'directly' with no mention of calibration, correlation analysis against ground-truth correctness, or controls for confounds.
Authors: We agree that the abstract does not explicitly reference validation steps. Section 3 defines the parametric-prior margin as the log-likelihood difference testing acceptance of the RAG answer by the frozen model and the evidence-binding margin as the difference between question+passage and passage-only conditioning to isolate question-specific support. Section 4.3 includes an ablation removing each margin individually and reports a positive correlation (Pearson r=0.62) between combined margin and ground-truth correctness on held-out examples. We will revise the abstract to note that the margins are validated via correlation analysis and component ablations in the experiments. revision: yes
-
Referee: [Abstract] Abstract: the claims of 'consistent improvements' and 'recovers part of the Direct/RAG oracle gap' are presented without details on exact margin formulas, statistical significance testing, variance across runs, or ablation of the two margins' individual contributions.
Authors: The abstract summarizes high-level findings; exact formulas appear in Equations 1-2 of Section 3. Table 1 reports means and standard deviations over three random seeds, Section 4.2 describes paired t-tests for significance (p<0.05 on both datasets), and Table 3 provides the requested margin ablations. We will add a short clause to the abstract directing readers to these sections for the supporting analyses. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper defines its TRUSTMARGIN arbitration layer directly from the frozen LLM's likelihood scores on the two candidate answers (Direct and RAG), computing parametric-prior and evidence-binding margins without any parameter fitting, self-referential definitions, or load-bearing self-citations. No equations or steps reduce the claimed selection rule to its inputs by construction, and the derivation remains self-contained against external model outputs rather than internal circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Model likelihoods on candidate answers reflect relative trustworthiness of parametric memory versus retrieved evidence
invented entities (2)
-
parametric-prior margin
no independent evidence
-
evidence-binding margin
no independent evidence
Reference graph
Works this paper leans on
-
[1]
B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., 8 TRUSTMARGIN Askell, A., et al
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., 8 TRUSTMARGIN Askell, A., et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pp. 1877–1901,
1901
-
[2]
Chen, W., Qi, G., Li, W., Li, Y ., Xia, D., and Huang, J. Decide then retrieve: A training-free framework with uncertainty-guided triggering and dual-path retrieval. arXiv preprint arXiv:2601.03908,
-
[3]
Transformer feed-forward layers are key-value memories
Geva, M., Schuster, R., Berant, J., and Levy, O. Transformer feed-forward layers are key-value memories. InProceed- ings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 5484–5495. Associa- tion for Computational Linguistics,
2021
-
[4]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
-
[5]
J., and Park, J
Jeong, S., Baek, J., Cho, S., Hwang, S. J., and Park, J. Adaptive-RAG: Learning to adapt retrieval-augmented large language models through question complexity. In Proceedings of the 2024 Conference of the North Amer- ican Chapter of the Association for Computational Lin- guistics: Human Language Technologies (V olume 1: Long Papers), pp. 7036–7050. Associ...
2024
-
[6]
F., Gao, L., Sun, Z., Liu, Q., Dwivedi- Yu, J., Yang, Y ., Callan, J., and Neubig, G
Jiang, Z., Xu, F. F., Gao, L., Sun, Z., Liu, Q., Dwivedi- Yu, J., Yang, Y ., Callan, J., and Neubig, G. Active re- trieval augmented generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,
2023
-
[7]
Dense passage retrieval for open-domain question answering
Karpukhin, V ., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., and Yih, W.-t. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing,
2020
-
[8]
Lin, X. V ., Chen, X., Chen, M., Shi, W., Lomeli, M., James, R., Rodriguez, P., Kahn, J., Szilvasy, G., Lewis, M., Zettlemoyer, L., and Yih, S. Ra-dit: Retrieval-augmented dual instruction tuning.arXiv preprint arXiv:2310.01352,
-
[9]
Mitchell, E., Lin, C., Bosselut, A., Finn, C., and Manning, C. D. Fast model editing at scale. InInternational Con- ference on Learning Representations, 2022a. Mitchell, E., Lin, C., Bosselut, A., Manning, C. D., and Finn, C. Memory-based model editing at scale. InProceed- ings of the 39th International Conference on Machine Learning, Proceedings of Machi...
2019
-
[10]
Qiu, Z., Ou, Z., Wu, B., Li, J., Liu, A., and King, I
doi: 10.18653/v1/D19-1250. Qiu, Z., Ou, Z., Wu, B., Li, J., Liu, A., and King, I. Entropy- based decoding for retrieval-augmented large language models. InProceedings of the 2025 Conference of the Na- tions of the Americas Chapter of the Association for Com- putational Linguistics: Human Language Technologies (V olume 1: Long Papers), pp. 4616–4627, Albuq...
-
[11]
doi: 10.18653/v1/2025.naacl-long.236
Association for Computational Lin- guistics. doi: 10.18653/v1/2025.naacl-long.236. Ram, O., Levine, Y ., Dalmedigos, I., Muhlgay, D., Shashua, A., Leyton-Brown, K., and Shoham, Y . In-context retrieval-augmented language models.Transactions of the Association for Computational Linguistics, 11:1316– 1331,
-
[12]
How much knowl- edge can you pack into the parameters of a language model? InProceedings of the 2020 Conference on Em- pirical Methods in Natural Language Processing, pp
Roberts, A., Raffel, C., and Shazeer, N. How much knowl- edge can you pack into the parameters of a language model? InProceedings of the 2020 Conference on Em- pirical Methods in Natural Language Processing, pp. 5418–5426. Association for Computational Linguistics,
2020
-
[13]
REPLUG: Retrieval- augmented black-box language models
Shi, W., Min, S., Yasunaga, M., Seo, M., James, R., Lewis, M., Zettlemoyer, L., and Yih, W.-t. REPLUG: Retrieval- augmented black-box language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pp. 8371–8384. Association for Comp...
2024
-
[14]
and Berant, J
Talmor, A. and Berant, J. The web as a knowledge-base for answering complex questions. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics,
2018
-
[15]
LLaMA: Open and efficient founda- tion language models.arXiv preprint arXiv:2302.13971,
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. LLaMA: Open and efficient founda- tion language models.arXiv preprint arXiv:2302.13971,
-
[16]
10 TRUSTMARGIN Wang, Z., Liu, A., Lin, H., Li, J., Ma, X., and Liang, Y . Retrieval augmented thoughts elicit context-aware reasoning in long-horizon generation.arXiv preprint arXiv:2403.05313,
-
[17]
Yoran, O., Wolfson, T., Ram, O., and Berant, J. Making retrieval-augmented language models robust to irrelevant context.arXiv preprint arXiv:2310.01558,
-
[18]
Rankrag: Unifying con- text ranking with retrieval-augmented generation in llms
Yu, Y ., Ping, W., Liu, Z., Wang, B., You, J., Zhang, C., Shoeybi, M., and Catanzaro, B. Rankrag: Unifying con- text ranking with retrieval-augmented generation in llms. arXiv preprint arXiv:2407.02485,
-
[19]
G., Jain, N., Shen, S., Zaharia, M., Stoica, I., and Gonzalez, J
Zhang, T., Patil, S. G., Jain, N., Shen, S., Zaharia, M., Stoica, I., and Gonzalez, J. E. Raft: Adapting language model to domain specific rag.arXiv preprint arXiv:2403.10131,
-
[20]
A. Source-Selection Diagnostics This appendix reports source-selection diagnostics in rate- only form. The aligned candidate set used in the motivation analysis and main results is summarized by rates rather than row-level counts. Table 5.Post-hoc source-selection rates in strict disagreement cases under the unified candidate-set definition. D>R→D de- not...
-
[21]
Method 2W F1 2W EM CW F1 CW EM Avg. F1 Avg. EM IRCoT 33.12 26.20 38.17 29.70 35.64 27.95 IRCoT+TM38.23 31.70 45.21 35.70 41.72 33.70 FLARE 31.61 24.9043.7434.1037.6729.50 FLARE+TM 31.50 24.90 43.68 34.10 37.59 29.50 CLeHe-RAG 27.13 22.90 40.63 33.20 33.88 28.05 CLeHe-RAG+TM34.94 28.80 46.49 36.90 40.72 32.85 DTR-RAG 33.67 27.30 41.72 33.70 37.70 30.50 DTR...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.