Show, Don't Ask: Generative Visual Disambiguation for Composed Image Retrieval with Turn-Valid Coverage
Pith reviewed 2026-06-26 21:43 UTC · model grok-4.3
The pith
CLARA resolves ambiguous composed image retrieval by showing visual prototypes and reweighting calibration for turn-valid conformal coverage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
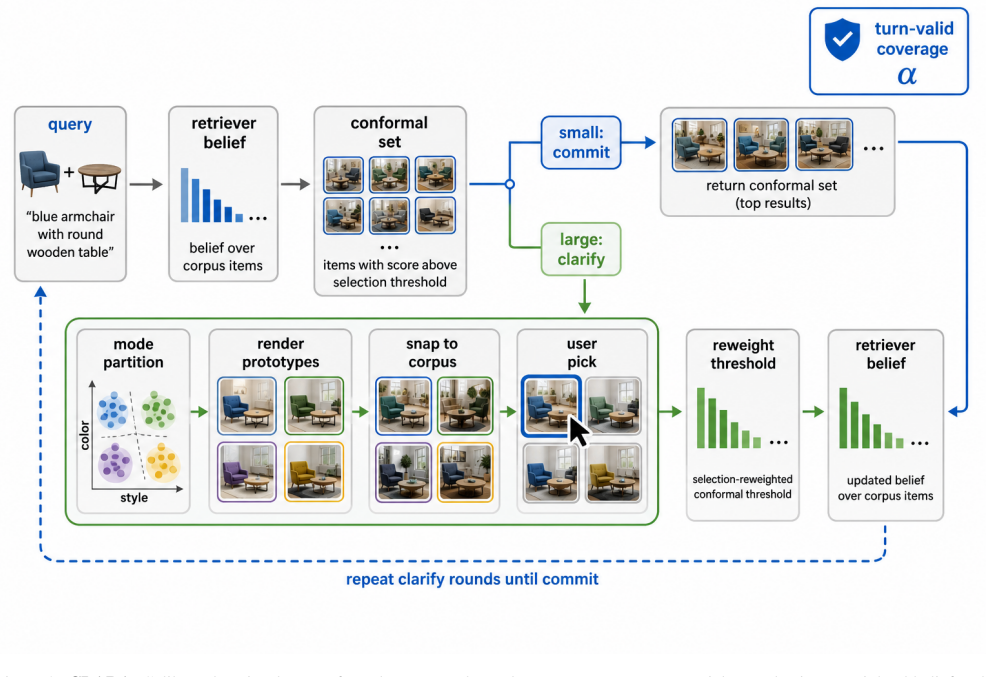
The paper establishes that showing users a constrained panel of real corpus prototype images, combined with likelihood-ratio reweighting of calibration data upon selection, enables a clarification framework for composed image retrieval that preserves conformal coverage guarantees across multiple turns while outperforming text-based questioning in efficiency and effectiveness for fine-grained visual ambiguities.
What carries the argument
Likelihood-ratio reweighting induced by user prototype selection, applied to maintain conformal prediction coverage in successive interaction rounds.
If this is right
- Matches single-turn state-of-the-art retrieval performance in multi-turn use.
- Maintains nominal coverage across interaction rounds.
- Finds the intended target in fewer rounds than strong text-question baselines.
- Shows particular advantage when ambiguity involves viewpoint or fine-grained attributes.
Where Pith is reading between the lines
- The reweighting technique could apply to conformal prediction in other interactive systems with sequential user feedback.
- Visual prototype panels may improve efficiency in non-retrieval tasks involving ambiguous visual queries.
- The real-corpus constraint avoids coverage inflation but limits use of generative models for prototypes.
Load-bearing premise
The likelihood-ratio reweighting of calibration data induced by the user's prototype selection preserves the conformal coverage guarantee across multiple interaction rounds.
What would settle it
Observing that the fraction of times the true target is covered falls below the nominal level after the first round in repeated experiments on the benchmarks would falsify the turn-valid coverage property.
Figures

read the original abstract
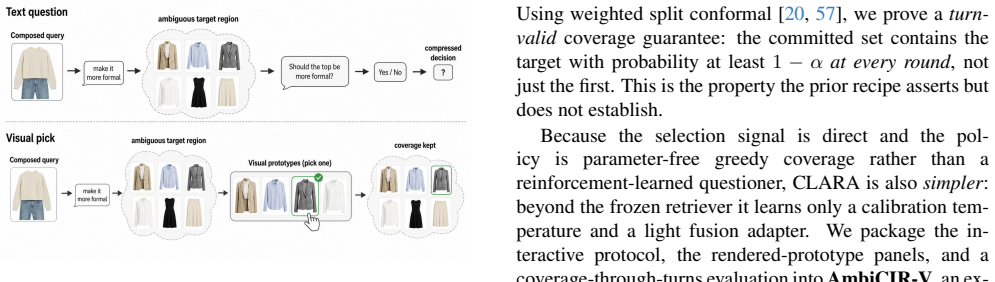
Composed image retrieval (CIR) uses a reference image and a text modification to search for a target image. However, such queries often describe several possible images rather than one exact target, making the user's intent ambiguous. Recent methods address this by using conformal prediction to estimate ambiguity and by asking users clarifying text questions. However, these methods have two limitations: their coverage guarantee only holds at the first interaction, and text questions are often insufficient for resolving fine-grained visual differences such as appearance, attributes, or viewpoint. We propose CLARA, a clarification framework that resolves ambiguity by showing users a small panel of visual alternatives. Instead of answering text questions, the user simply selects the prototype image closest to the intended target. This provides a direct visual signal and avoids relying on a model to predict the user's answer. To maintain valid conformal guarantees across multiple interaction rounds, CLARA reweights calibration using the likelihood ratio induced by the user's selection. The displayed prototypes are also constrained to represent the current candidate set and are snapped to real corpus images, ensuring that generated images cannot artificially improve coverage. Experiments on open-domain and fashion benchmarks show that CLARA matches single-turn state-of-the-art retrieval performance, maintains nominal coverage across interaction rounds, and finds the intended target in fewer rounds than strong text-question baselines. Its advantage is especially clear when ambiguity involves viewpoint or fine-grained attributes, where visual clarification is more effective than textual questioning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CLARA, a clarification framework for composed image retrieval that replaces text questions with visual prototype panels selected by the user. It claims to maintain conformal prediction coverage across multiple interaction rounds via likelihood-ratio reweighting of calibration scores induced by the prototype choice, with prototypes constrained to the current candidate set and snapped to real corpus images. Experiments on open-domain and fashion benchmarks are reported to match single-turn SOTA retrieval performance, preserve nominal coverage, and reach the target in fewer rounds than text-question baselines, with particular gains on viewpoint and fine-grained attribute ambiguities.
Significance. If the turn-valid coverage guarantee is rigorously established, the work offers a practical contribution to interactive CIR by demonstrating that direct visual signals can outperform text clarification for certain ambiguities while extending conformal validity beyond the first turn. The reported empirical results on standard benchmarks provide evidence of reduced interaction rounds without sacrificing retrieval accuracy.
major comments (1)
- [Abstract] Abstract: the central turn-valid coverage claim rests on likelihood-ratio reweighting preserving stochastic validity of p-values after each round. The description does not specify how the derivation accounts for dependence induced by successive candidate-set updates (e.g., exclusion of previously selected images or shared parameters between the ratio model and retrieval scorer). This is load-bearing for the multi-turn guarantee and requires an explicit theorem or proof addressing the updated conditional distributions.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the focus on the multi-turn coverage guarantee. We address the single major comment below and will revise the manuscript to improve clarity on this point.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central turn-valid coverage claim rests on likelihood-ratio reweighting preserving stochastic validity of p-values after each round. The description does not specify how the derivation accounts for dependence induced by successive candidate-set updates (e.g., exclusion of previously selected images or shared parameters between the ratio model and retrieval scorer). This is load-bearing for the multi-turn guarantee and requires an explicit theorem or proof addressing the updated conditional distributions.
Authors: We agree that the abstract is high-level and does not detail the handling of dependence. The full manuscript presents a formal theorem (Section 3.3) establishing that the likelihood-ratio reweighting preserves stochastic validity of the p-values conditionally on the sequence of candidate-set updates. The proof proceeds by induction on the number of turns: at each round the calibration scores are reweighted by the ratio of the selection probability under the current candidate set versus the marginal, which conditions out the effect of prior exclusions. Shared parameters are avoided by training the ratio model on a held-out calibration split independent of the retrieval scorer. We will revise the abstract to include a one-sentence reference to this theorem and its conditioning argument. revision: yes
Circularity Check
No circularity; coverage claim rests on standard conformal reweighting
full rationale
The paper claims turn-valid coverage by reweighting calibration scores with the likelihood ratio induced by prototype selection. This is presented as an application of known conformal prediction techniques for conditional validity under selection-induced shifts, with additional constraints (snapping to corpus images, representing current candidate set) to avoid artificial inflation. No equations reduce a derived quantity to a fitted parameter defined by the paper itself, no self-citation is invoked as the sole justification for a uniqueness or validity theorem, and the central guarantee is not shown to be equivalent to its inputs by construction. The derivation is therefore treated as self-contained against external conformal prediction results.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Conformal prediction supplies valid coverage under exchangeability of calibration and test points.
Reference graph
Works this paper leans on
-
[1]
Zhang, S
D. Zhang, S. Liang, T. He, J. Shao, and K. Qin. CVIformer: Cross-view interactive transformer for efficient stereoscopic image super-resolution.IEEE Transactions on Emerging Topics in Computational Intelligence, 9(2), 2024
2024
-
[2]
Vaswaniet al
A. Vaswaniet al. Attention is all you need. InNeurIPS, 2017
2017
-
[3]
Guoet al
X. Guoet al. Dialog-based interactive image retrieval. In NeurIPS, 2018
2018
-
[4]
T. He, L. Gao, J. Song, and Y .-F. Li. Toward a unified transformer-based framework for scene graph generation and human-object interaction detection.IEEE Transactions on Image Processing, 32:6274–6288, 2023
2023
-
[5]
G. Guet al. CompoDiff: Versatile composed image retrieval with latent diffusion.TMLR, 2024
2024
-
[6]
Chenet al
Y . Chenet al. Image search with text feedback by visiolin- guistic attention learning. InCVPR, 2020
2020
-
[7]
Q. Dong, R. Dai, G. Duan, K. Qin, Y . Zhang, and T. He. Unbiased multimodal intent recognition with auxiliary ra- tionale generation.Neurocomputing, 131197, 2025
2025
-
[8]
T. He, X. Hu, T. Wu, D. Zhang, M. Li, Y .-F. Li, and F. R. Yu. Lifelong scene graph generation.Pattern Recognition, 113132, 2026
2026
-
[9]
Brooks, A
T. Brooks, A. Holynski, A. Efros. InstructPix2Pix: Learning to follow image editing instructions. InCVPR, 2023
2023
-
[10]
R. Dai, H. Meng, Z. Yuan, L. Mo, W. Zhu, and T. He. A unified cross-source context enhancement model for multi-source fake news detection.Knowledge-Based Sys- tems, 324:113867, 2025
2025
-
[11]
J. Liet al. BLIP-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. InICML, 2023
2023
-
[12]
D. Lindley. On a measure of the information provided by an experiment.Annals of Mathematical Statistics, 1956
1956
-
[13]
T. He, L. Gao, J. Song, X. Wang, K. Huang, and Y . Li. SNEQ: Semi-supervised attributed network embedding with attention-based quantisation. InAAAI, 2020
2020
-
[14]
Santoroet al
A. Santoroet al. A simple neural network module for rela- tional reasoning. InNeurIPS, 2017
2017
-
[15]
Isola, J
P. Isola, J. Lim, E. Adelson. Discovering states and transfor- mations in image collections. InCVPR, 2015
2015
-
[16]
V ovket al
V . V ovket al. Mondrian conformal predictors. InArtificial Intelligence Applications and Innovations, 2003
2003
-
[17]
T. He, L. Gao, J. Song, and Y .-F. Li. Semisupervised network embedding with differentiable deep quantization. IEEE Transactions on Neural Networks and Learning Sys- tems, 34(8):4791–4802, 2021
2021
-
[18]
M. Li, H. Gou, Y . Ma, R. Wang, K. Qin, and T. He. Fixed anchors are not enough: Dynamic retrieval and persistent homology for dataset distillation.arXiv:2602.24144, 2026
arXiv 2026
-
[19]
Romano, M
Y . Romano, M. Sesia, E. Cand‘es. Classification with valid and adaptive coverage. InNeurIPS, 2020
2020
-
[20]
Tibshiraniet al
R. Tibshiraniet al. Conformal prediction under covariate shift. InNeurIPS, 2019
2019
-
[21]
V ovk, A
V . V ovk, A. Gammerman, G. Shafer.Algorithmic Learning in a Random World. Springer, 2005
2005
-
[22]
Gibbs, E
I. Gibbs, E. Cand‘es. Adaptive conformal inference under distribution shift. InNeurIPS, 2021
2021
-
[23]
S. Wei, K. Zhang, L. Chen, T. He, and G. Duan. Unbiased dynamic multimodal fusion.arXiv:2603.19681, 2026
arXiv 2026
-
[24]
Caoet al
Y . Caoet al. A comparative study of text-based image re- trieval.IEEE, 2011
2011
-
[25]
Nemhauser, L
G. Nemhauser, L. Wolsey, M. Fisher. An analysis of approx- imations for maximizing submodular set functions.Mathe- matical Programming, 1978
1978
-
[26]
Y . Dong, T. He, Q. Dong, and K. Qin. KMG-LL: Knowledge-enhanced multimodal graph for dialogue gen- eration. InICASSP, 2025
2025
-
[27]
Krizhevskyet al
A. Krizhevskyet al. ImageNet classification with deep con- volutional neural networks. InNeurIPS, 2012
2012
-
[28]
R. Dai, Y . Tan, L. Mo, T. He, K. Qin, and S. Liang. Ro- bustPT: Dynamic disentanglement prompt tuning in vision- language models with missing modalities. InICMR, 2025
2025
-
[29]
Guoet al
C. Guoet al. On calibration of modern neural networks. In ICML, 2017
2017
-
[30]
Suhret al
A. Suhret al. A corpus for reasoning about natural language grounded in photographs (NLVR2). InACL, 2019
2019
-
[31]
Z. Liu, C. Rodriguez-Opazo, D. Teney, S. Gould. Image retrieval on real-life images with pre-trained vision-and- language models. InICCV, 2021
2021
-
[32]
T. He, L. Gao, J. Song, J. Cai, and Y .-F. Li. Learning from the scene and borrowing from the rich: Tackling the long tail in scene graph generation. InIJCAI, 2020
2020
-
[33]
T. Berg, A. Berg, J. Shih. Automatic attribute discovery and characterization from noisy web data. InECCV, 2010
2010
-
[34]
A. Angelopoulos, S. Bates. A gentle introduction to confor- mal prediction and distribution-free uncertainty quantifica- tion.arXiv:2107.07511, 2021
Pith/arXiv arXiv 2021
-
[35]
Kulesza, B
A. Kulesza, B. Taskar. Determinantal point processes for machine learning.Foundations and Trends in ML, 2012
2012
-
[36]
T. He, L. Gao, J. Song, and Y .-F. Li. Towards open- vocabulary scene graph generation with prompt-based fine- tuning. InECCV, 2022
2022
-
[37]
V oet al
N. V oet al. Composing text and image for image retrieval — an empirical odyssey. InCVPR, 2019
2019
-
[38]
R. Dai, C. Li, Y . Yan, L. Mo, K. Qin, and T. He. Unbiased missing-modality multimodal learning. InICCV, 2025
2025
-
[39]
Smeulderset al
A. Smeulderset al. Content-based image retrieval at the end of the early years.IEEE TPAMI, 2000
2000
-
[40]
Johnsonet al
J. Johnsonet al. CLEVR: A diagnostic dataset for composi- tional language and elementary visual reasoning. InCVPR, 2017
2017
-
[41]
K. Heet al. Deep residual learning for image recognition. In CVPR, 2016
2016
-
[42]
Rombachet al
R. Rombachet al. High-resolution image synthesis with la- tent diffusion models. InCVPR, 2022
2022
-
[43]
Radfordet al
A. Radfordet al. Learning transferable visual models from natural language supervision. InICML, 2021
2021
-
[44]
Zhang, A
L. Zhang, A. Rao, M. Agrawala. Adding conditional control to text-to-image diffusion models. InICCV, 2023
2023
-
[45]
X. Liet al. OSCAR: Object-semantics aligned pre-training for vision-language tasks. InECCV, 2020
2020
-
[46]
T. He, L. Gao, J. Song, and Y .-F. Li. State-aware composi- tional learning toward unbiased training for scene graph gen- eration.IEEE Transactions on Image Processing, 32:43–56, 2022
2022
-
[47]
H. Wuet al. Fashion IQ: A new dataset towards retrieving images by natural language feedback. InCVPR, 2021
2021
-
[48]
X. Hu, K. Qin, G. Duan, M. Li, Y .-F. Li, and T. He. SPADE: Spatial-aware denoising network for open- vocabulary panoptic scene graph generation with long- and local-range context reasoning. InICCV, 2025
2025
-
[49]
R. Dai, Y . Tan, L. Mo, T. He, K. Qin, and S. Liang. MUAP: Multi-step adaptive prompt learning for vision-language model with missing modality.arXiv:2409.04693, 2024
arXiv 2024
-
[50]
H. Xuet al. Multilevel language and vision integration for text-to-clip retrieval. InAAAI, 2019
2019
-
[51]
He, Y .-F
T. He, Y .-F. Li, L. Gao, D. Zhang, and J. Song. One network for multi-domains: Domain adaptive hashing with intersec- tant generative adversarial network. InIJCAI, 2019
2019
-
[52]
Loshchilov, F
I. Loshchilov, F. Hutter. Decoupled weight decay regulariza- tion (AdamW). InICLR, 2019
2019
-
[53]
Saitoet al
K. Saitoet al. Pic2Word: Mapping pictures to words for zero-shot composed image retrieval. InCVPR, 2023
2023
-
[54]
Hosseinzadeh, Y
M. Hosseinzadeh, Y . Wang. Composed query image re- trieval using locally bounded features. InCVPR, 2020
2020
-
[55]
Z. Yang, X. Liu, D. Ouyang, G. Duan, D. Zhang, T. He, and Y .-F. Li. Towards open-vocabulary HOI detection with cal- ibrated vision-language models and locality-aware queries. InACM MM, 2024
2024
-
[56]
Tanget al
Y . Tanget al. Reason before retrieve: One-stage reflective MLLM for composed image retrieval. InCVPR, 2025
2025
-
[57]
Fannjianget al
C. Fannjianget al. Conformal prediction under feedback co- variate shift for biomolecular design.PNAS, 2022
2022
-
[58]
Baldratiet al
A. Baldratiet al. Zero-shot composed image retrieval with textual inversion (SEARLE). InICCV, 2023
2023
-
[59]
Baldratiet al
A. Baldratiet al. Zero-shot composed image retrieval with textual inversion (CIRCO). InICCV, 2023
2023
-
[60]
R. Dai, Z. Cai, L. Mo, G. Duan, K. Shi, and T. He. An- chor drift no more: Hierarchical consistency-guided prompt distillation for incomplete multimodal learning. InWWW, 2026
2026
-
[61]
Janget al
S. Janget al. Pseudo-target generation for composed image retrieval. InCVPR, 2024
2024
-
[62]
E. Doddset al. Modality-agnostic attention fusion for visual search with text feedback.arXiv:2007.00145, 2020
arXiv 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.