Clinical Reasoning in the Age of AI: Longitudinal Cognition and Human-AI Collaboration
Pith reviewed 2026-06-27 18:06 UTC · model grok-4.3
The pith
Physicians reason across multiple encounters using temporal structures that current AI largely omits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
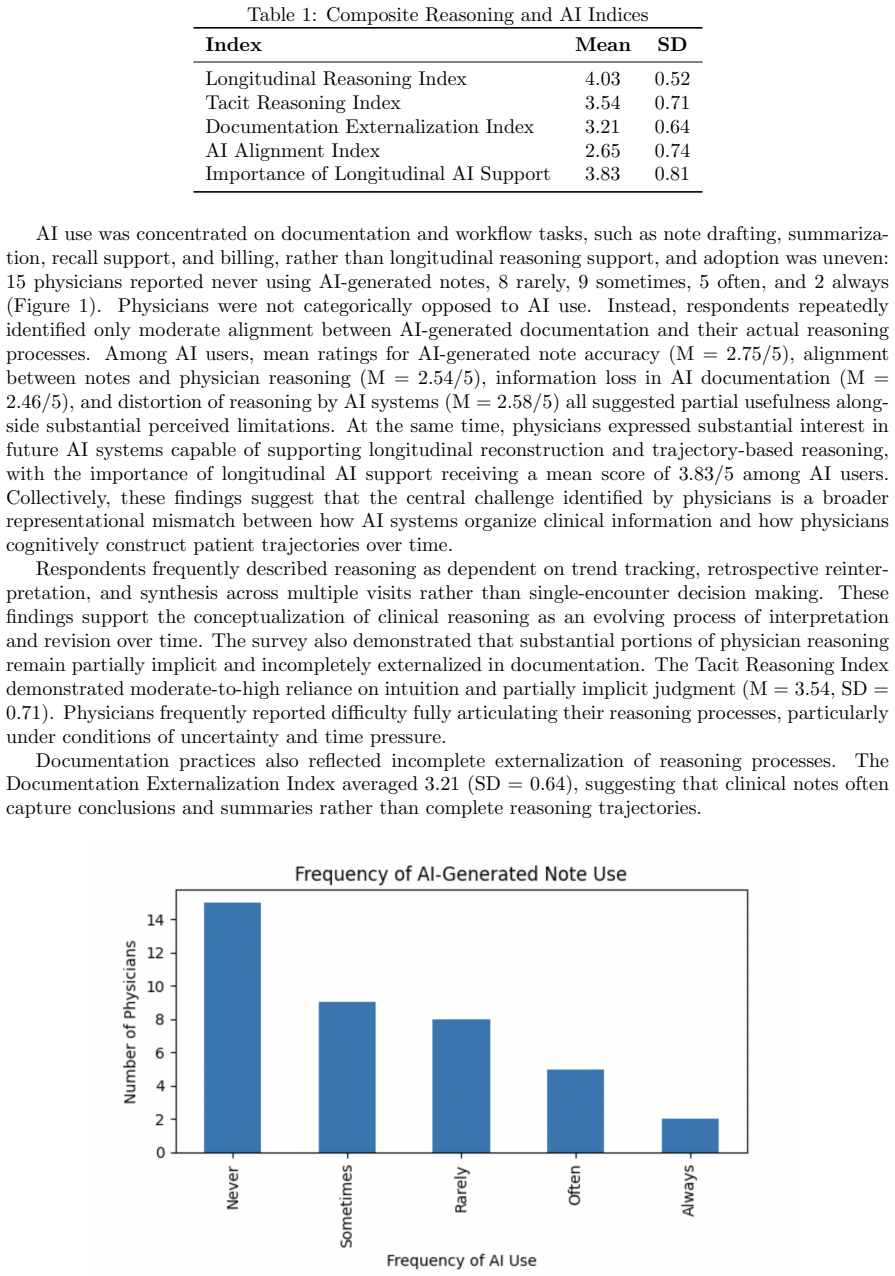
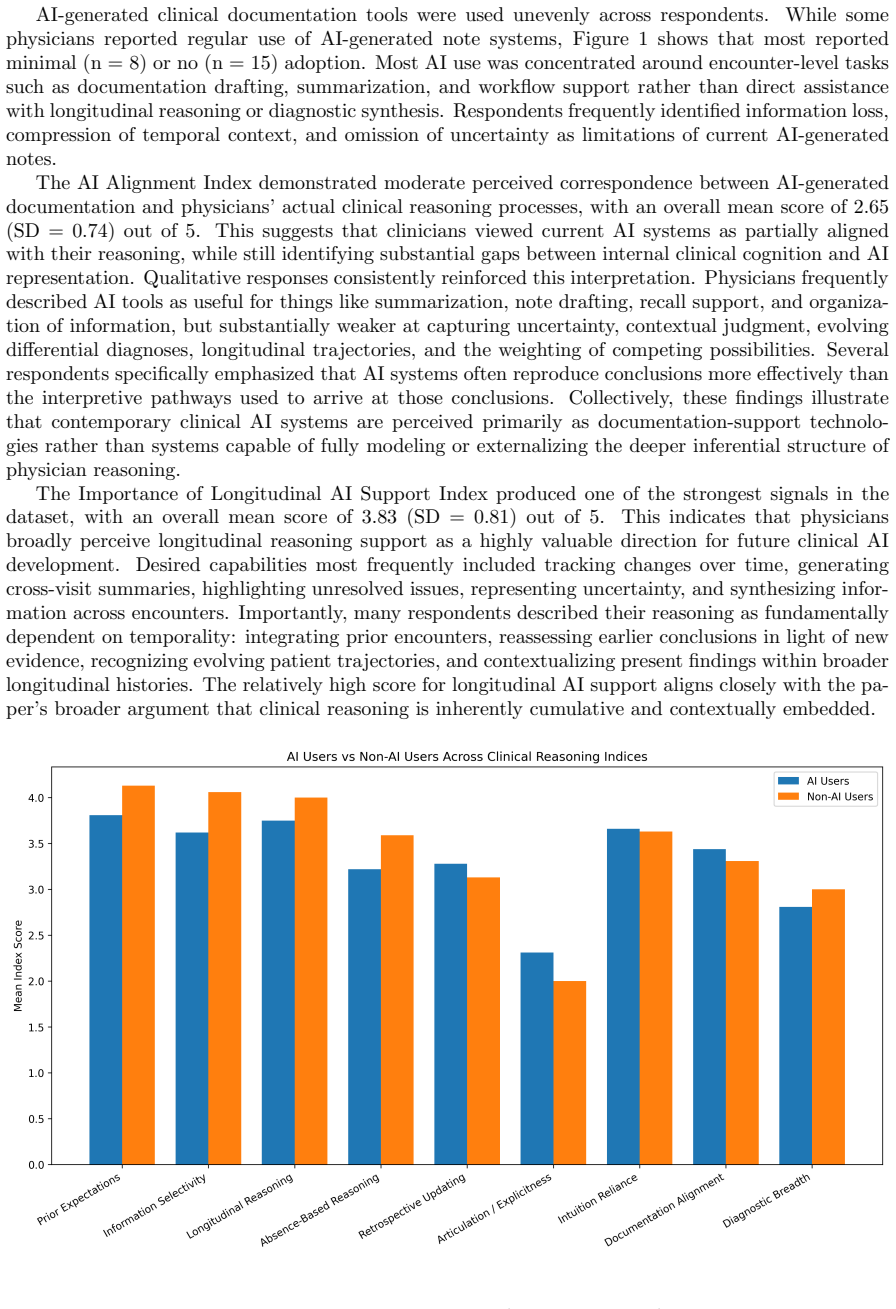
Findings indicate that current AI systems are primarily deployed for encounter-level tasks such as documentation and summarization, and only partially align with physicians' underlying reasoning processes. In particular, AI-generated representations often omit temporal or interpretive structures central to clinical decision-making, while core aspects of reasoning, especially those spanning multiple encounters, remain largely implicit and physician-driven. By integrating fine-grained qualitative insights with broader quantitative patterns, this study offers a unified framework for understanding clinical reasoning as a context-sensitive, temporally extended process and identifies key mismatche
What carries the argument
The mixed-methods account of clinical reasoning as a context-sensitive, temporally extended process that reveals mismatches with encounter-level AI applications.
If this is right
- AI systems should be redesigned to incorporate temporal structures that span multiple encounters rather than remaining limited to single-visit documentation.
- Development efforts must address the implicit, physician-driven aspects of reasoning that occur under conditions of uncertainty and constraint.
- A unified framework for context-sensitive reasoning can supply concrete directions for building AI that augments rather than replaces clinical workflows.
- Better alignment would help meet the dual demands of speed and care quality while reducing hallucinations and sycophancy.
Where Pith is reading between the lines
- Training datasets for medical AI would need to shift from isolated encounters to full patient timelines to close the observed gap.
- EHR interfaces could be restructured to surface the longitudinal links that physicians currently maintain mentally.
- Regulatory or design standards for clinical AI might eventually require evidence of support for multi-encounter reasoning.
Load-bearing premise
That interviews combined with structured survey data can produce a comprehensive picture of how clinical reasoning unfolds over multiple encounters.
What would settle it
A direct comparison showing that AI summaries already preserve the same temporal and interpretive structures physicians use across encounters would falsify the claim of partial alignment.
Figures
read the original abstract
As physicians turn to AI-powered systems to help meet the dual demands of speed and care quality, they are met with hallucinations and sycophancy. Understanding how doctors reason through clinical problems in real-world settings is critical for design of effective AI reasoning systems. While recent advances in medical AI have emphasized performance benchmarks and diagnostic accuracy, comparatively little attention has been paid to the structure of clinicians' reasoning processes as they unfold over time, e.g., how they interact with electronic health records and operate under conditions of uncertainty and constraint. This study provides a comprehensive, empirically-grounded account of clinical reasoning and its relationship to current AI-mediated workflows through a mixed-methods design that combines qualitative interviews with structured survey data. Findings indicate that current AI systems are primarily deployed for encounter-level tasks such as documentation and summarization, and only partially align with physicians' underlying reasoning processes. In particular, AI-generated representations often omit temporal or interpretive structures central to clinical decision-making, while core aspects of reasoning, especially those spanning multiple encounters, remain largely implicit and physician-driven. By integrating fine-grained qualitative insights with broader quantitative patterns, this study offers a unified framework for understanding clinical reasoning as a context-sensitive, temporally extended process and identifies key mismatches between clinician cognition and current AI design. These results provide concrete directions for the development of AI systems that more effectively align with and augment real-world clinical reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents findings from a mixed-methods study combining qualitative interviews with structured survey data to characterize physicians' clinical reasoning as a temporally extended, context-sensitive process and to assess its alignment with current AI systems. The central claims are that AI tools are deployed mainly for encounter-level tasks such as documentation and summarization, that AI-generated outputs frequently omit temporal and interpretive structures essential to multi-encounter decision-making, and that core longitudinal reasoning remains implicit and physician-driven. The work offers a unified framework for these processes and identifies design directions for better human-AI alignment in clinical workflows.
Significance. If the empirical distinctions between encounter-level and longitudinal reasoning hold under scrutiny, the results would usefully direct AI development away from isolated-task automation toward systems that better support multi-encounter cognition and uncertainty management. The topic addresses a recognized gap between benchmark-driven medical AI and real-world clinical practice; a well-supported account could inform both system design and policy on AI integration.
major comments (2)
- [Methods] Methods section: the mixed-methods protocol is described at a high level but supplies no information on sample size, recruitment, exclusion criteria, interview guides for surfacing multi-encounter cases, coding schemes that tag temporal or interpretive elements, inter-rater reliability, or any triangulation against observed decisions or EHR data. These omissions are load-bearing for the claim that the data reliably distinguish AI-supported encounter tasks from physician-driven longitudinal reasoning.
- [Results] Results/Findings: the assertions that AI representations 'often omit temporal or interpretive structures' and that 'core aspects of reasoning... remain largely implicit and physician-driven' are presented as direct outcomes of the interviews and surveys, yet no quantitative frequencies, example coded excerpts, or validation steps are referenced to ground the distinction between 'often' and 'largely.'
minor comments (1)
- [Abstract] The abstract states headline findings without any methodological parameters (N, response rate, analysis approach), which weakens the reader's ability to assess the scope of the empirical claims even before reaching the full Methods section.
Simulated Author's Rebuttal
We appreciate the referee's constructive feedback, which highlights important areas for improving methodological transparency and empirical grounding. We address each major comment below and will make substantial revisions to the manuscript.
read point-by-point responses
-
Referee: [Methods] Methods section: the mixed-methods protocol is described at a high level but supplies no information on sample size, recruitment, exclusion criteria, interview guides for surfacing multi-encounter cases, coding schemes that tag temporal or interpretive elements, inter-rater reliability, or any triangulation against observed decisions or EHR data. These omissions are load-bearing for the claim that the data reliably distinguish AI-supported encounter tasks from physician-driven longitudinal reasoning.
Authors: We agree that the current Methods section provides only a high-level description and lacks these critical details. In the revised manuscript, we will expand the section to report the sample sizes for interviews and surveys, recruitment strategies and exclusion criteria, the interview guide with specific prompts for multi-encounter cases, the coding scheme including tags for temporal and interpretive elements, inter-rater reliability metrics, and any triangulation with EHR data or observed decisions. These additions will directly address the load-bearing concerns for our claims. revision: yes
-
Referee: [Results] Results/Findings: the assertions that AI representations 'often omit temporal or interpretive structures' and that 'core aspects of reasoning... remain largely implicit and physician-driven' are presented as direct outcomes of the interviews and surveys, yet no quantitative frequencies, example coded excerpts, or validation steps are referenced to ground the distinction between 'often' and 'largely.'
Authors: We acknowledge that the Results section would be strengthened by more explicit quantitative and qualitative grounding. We will revise to include survey-based frequencies (e.g., proportions indicating omission of temporal structures), representative coded interview excerpts illustrating the themes, and details on validation or triangulation steps. This will better substantiate the characterizations and the distinction between encounter-level and longitudinal reasoning. revision: yes
Circularity Check
No circularity: purely empirical mixed-methods study with no derivations or self-referential reductions
full rationale
The paper presents findings from qualitative interviews and structured surveys on clinical reasoning and AI alignment. No equations, parameter fitting, predictive models, or derivation chains appear in the abstract or described methods. Claims rest on collected data rather than any self-definitional loop, fitted input renamed as prediction, or load-bearing self-citation. The mixed-methods design is presented as the source of the account, with no reduction of outputs to prior fitted values or ansatzes imported via citation. This matches the default case of an empirical study whose central claims do not reduce by construction to their inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mixed-methods design combining qualitative interviews with structured survey data can provide a comprehensive account of clinical reasoning and its relationship to AI workflows.
Reference graph
Works this paper leans on
-
[1]
Medical Education , year =
Norman, Geoffrey , title =. Medical Education , year =
-
[2]
and Shulman, Lee S
Elstein, Arthur S. and Shulman, Lee S. and Sprafka, Sarah A. , title =
-
[3]
Polanyi, Michael , title =
-
[4]
and Dreyfus, Stuart E
Dreyfus, Hubert L. and Dreyfus, Stuart E. , title =
-
[5]
and Gorry, G
Kassirer, Jerome P. and Gorry, G. Anthony , title =. Annals of Internal Medicine , year =
-
[6]
, title =
Norman, Geoffrey and Eva, Kevin W. , title =. Medical Education , year =
-
[7]
British Journal of Educational Psychology , year =
Eraut, Michael , title =. British Journal of Educational Psychology , year =
-
[8]
Trent and Denny, Joshua C
Rosenbloom, S. Trent and Denny, Joshua C. and Xu, Hua and Lorenzi, Nancy M. and Stead, William W. and Johnson, Kevin B. , title =. Journal of the American Medical Informatics Association , year =
-
[9]
and Savage, Elizabeth and Will, Allison and Arnold, Ryan and Khairat, Saif and Miller, Kevin and others , title =
Ratwani, Raj M. and Savage, Elizabeth and Will, Allison and Arnold, Ryan and Khairat, Saif and Miller, Kevin and others , title =. Health Affairs , year =
-
[10]
and Bice, Thomas and Carson, Shannon S
Khairat, Saif and Coleman, Cynthia and Ottmar, Paul and Jayachander, Dinesh I. and Bice, Thomas and Carson, Shannon S. and Koppel, Ross , title =. JAMA Network Open , year =
-
[11]
and Ko, Justin and Swetter, Susan M
Esteva, Andre and Kuprel, Brett and Novoa, Roberto A. and Ko, Justin and Swetter, Susan M. and Blau, Helen M. and Thrun, Sebastian , title =. Nature , year =
-
[12]
Rajpurkar, Pranav and Irvin, Jeremy and Zhu, Kaylie and Yang, Brandon and Mehta, Hershel and Duan, Tony and Ding, Daisy and Bagul, Aarti and Langlotz, Curtis and Shpanskaya, Katie and Lungren, Matthew P. and Ng, Andrew Y. , title =. arXiv preprint arXiv:1711.05225 , year =
-
[13]
and D'Arcy, John and Kashyap, Sandeep and Gao, Michael and Nichols, Matthew and Corey, Karen and Ratliff, William and Balu, Sridhar , title =
Sendak, Mark P. and D'Arcy, John and Kashyap, Sandeep and Gao, Michael and Nichols, Matthew and Corey, Karen and Ratliff, William and Balu, Sridhar , title =. EMJ Innovations , year =
-
[14]
2015 International Conference on Healthcare Informatics , year =
Bussone, Adrian and Stumpf, Simone and O'Sullivan, Dympna , title =. 2015 International Conference on Healthcare Informatics , year =
2015
-
[15]
and Goldenberg, Anna , title =
Tonekaboni, Sana and Joshi, Shalmali and McCradden, Melissa D. and Goldenberg, Anna , title =. Proceedings of Machine Learning for Healthcare , series =. 2019 , pages =
2019
-
[16]
and Weld, Daniel S
Bansal, Gagan and Nushi, Besmira and Kamar, Ece and Lasecki, Walter S. and Weld, Daniel S. and Horvitz, Eric , title =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[17]
and de Vreede, Gert-Jan and de Vreede, Triparna and Elkins, Aaron and Maier, Ronald and Merz, Alexander B
Seeber, Isabella and Bittner, Eva and Briggs, Robert O. and de Vreede, Gert-Jan and de Vreede, Triparna and Elkins, Aaron and Maier, Ronald and Merz, Alexander B. and Oeste-Reiss, Sarah and Randrup, Niels and Schwabe, Gerhard and Sollner, Matthias , title =. Business & Information Systems Engineering , year =
-
[18]
Academic Medicine , year =
Croskerry, Pat , title =. Academic Medicine , year =
-
[19]
, title =
Eva, Kevin W. , title =. Medical Education , year =
-
[20]
The Reflective Practitioner: How Professionals Think in Action , publisher =
Sch. The Reflective Practitioner: How Professionals Think in Action , publisher =
-
[21]
and Kohane, Isaac S
Beam, Andrew L. and Kohane, Isaac S. , title =. JAMA , year =
-
[22]
Nature Medicine , year =
Topol, Eric , title =. Nature Medicine , year =
-
[23]
and Berg, Marc and Coiera, Enrico , title =
Ash, Joan S. and Berg, Marc and Coiera, Enrico , title =. Journal of the American Medical Informatics Association , year =
-
[24]
arXiv preprint arXiv:1702.08608 , year =
Doshi-Velez, Finale and Kim, Been , title =. arXiv preprint arXiv:1702.08608 , year =. 1702.08608 , archivePrefix =
-
[25]
and Norman, Geoffrey R
Schmidt, Henk G. and Norman, Geoffrey R. and Boshuizen, Henny P. A. , title =. Academic Medicine , year =
-
[26]
Nature Machine Intelligence , year =
Rudin, Cynthia , title =. Nature Machine Intelligence , year =
-
[27]
and Resnikoff, Pamela M
Yi, Irene and Brown, Grace and Aldogom, Sufian and Roll, Nathan and Basile, Eric J. and Resnikoff, Pamela M. and Gutterman, Isaac and Schiff, Oscar and Salata, Keira and Mujkic, Benjamin and Ahmed, Ammar , title =. 2026 , note =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.