FAM-Bench: A Multimodal Benchmark for Condition-Aware Food-as-Medicine Reasoning
Pith reviewed 2026-06-28 22:10 UTC · model grok-4.3
The pith
FAM-Bench supplies 2500 expert-verified cases to test whether models can decide if a dish suits a given health condition from its image and ingredients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
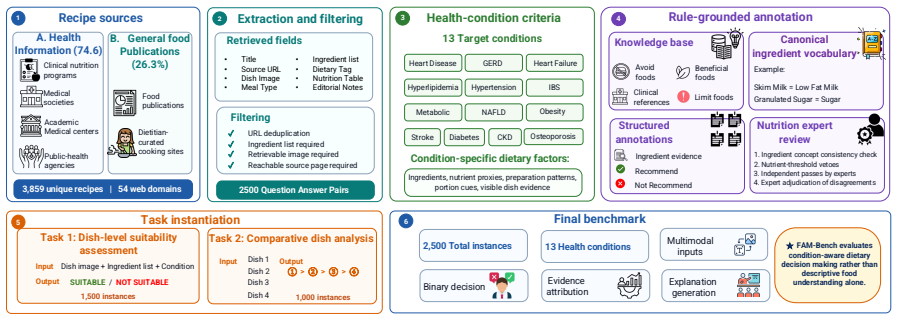
FAM-Bench is a multimodal benchmark with 2500 nutrition-expert-verified instances across 13 diet-related health conditions. It contains two tasks: dish-level suitability assessment, in which a model judges whether a single dish is appropriate for a condition given its image and ingredient list, and comparative dish analysis, in which the model ranks four candidate dishes by condition-specific suitability. Both tasks require the model to integrate ingredient evidence, visual preparation cues, and clinical nutrition constraints.
What carries the argument
The FAM-Bench dataset and its two tasks that combine image input, ingredient lists, and condition-specific clinical constraints to produce suitability judgments.
If this is right
- Models can be evaluated on health-aware food decisions rather than identification or nutrient estimation alone.
- Progress on the benchmark would show better integration of visual, textual, and domain-specific clinical knowledge.
- The benchmark supplies a common testbed for comparing language models and vision-language models on condition-aware reasoning.
- The two tasks allow separate measurement of single-dish judgment and relative ranking under the same clinical constraints.
- Coverage of 13 conditions permits evaluation across varied clinical scenarios within one resource.
Where Pith is reading between the lines
- The dataset could be used as a source of training labels for fine-tuning models on dietary suitability if the expert annotations are treated as ground truth.
- Similar construction methods could be applied to create benchmarks for other recommendation domains such as exercise or medication choices.
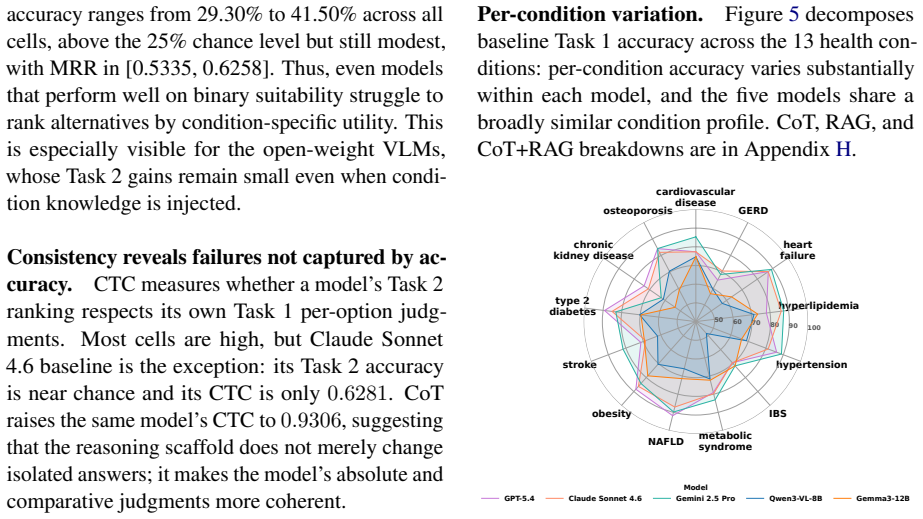
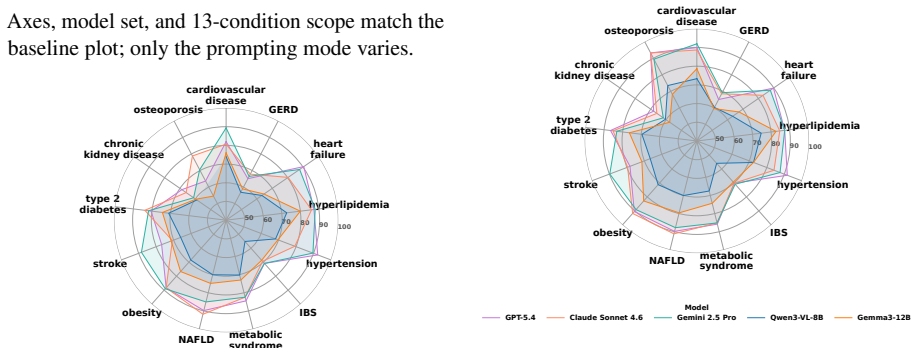
- Large performance gaps between models on this benchmark would point to specific weaknesses in chaining visual evidence with clinical rules.
- Periodic re-verification of a subset of instances by new experts would provide an ongoing check on label stability.
Load-bearing premise
The 2500 instances were accurately and consistently verified by nutrition experts so that the suitability labels match real clinical constraints.
What would settle it
A re-evaluation of a random sample of the instances by an independent group of nutrition experts that yields substantially different suitability labels for more than a small fraction of cases.
Figures




read the original abstract
Food-as-Medicine requires models to reason beyond what a dish is or what nutrition it contains: they must decide whether a concrete food choice is appropriate for a specific health condition. Existing food AI benchmarks primarily evaluate dish recognition, recipe understanding, nutrient estimation, or general nutrition question answering, leaving this health-aware decision layer largely untested. We introduce FAM-Bench, a multi-modal Food-as-Medicine benchmark with 2500 nutrition-expert-verified instances across 13 diet-related health conditions. The benchmark contains two complementary tasks: dish-level suitability assessment, where models judge whether a dish is suitable for a condition from its image and ingredient list, and comparative dish analysis, where models rank four candidate dishes by condition-specific suitability. Both tasks require integrating ingredient evidence, visual preparation cues, and clinical nutrition constraints, providing a standardized testbed for grounded health-aware reasoning in language and vision-language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FAM-Bench, a multimodal benchmark with 2500 nutrition-expert-verified instances spanning 13 diet-related health conditions. It defines two tasks—dish-level suitability assessment (judging a dish from image and ingredients) and comparative dish analysis (ranking four candidates)—both requiring models to integrate ingredient lists, visual preparation cues, and clinical nutrition constraints for health-aware reasoning in language and vision-language models.
Significance. If the expert verification is robust, the benchmark would address a clear gap in existing food AI evaluations (which focus on recognition, recipes, or general nutrition QA) by providing a standardized testbed for condition-specific suitability reasoning. The dual-task design and multimodal inputs are well-motivated for testing grounded integration of evidence.
major comments (1)
- [Abstract] Abstract: The central claim that instances are 'nutrition-expert-verified' and encode 'clinical nutrition constraints' is load-bearing for the benchmark's utility, yet the text supplies no details on expert credentials, annotation guidelines, number of reviewers per instance, conflict resolution, or inter-rater agreement statistics. Without these, it is impossible to assess whether suitability labels reflect reliable clinical constraints or subjective judgments.
minor comments (2)
- [Abstract] The abstract would benefit from a brief parenthetical on the 13 conditions or example instances to help readers immediately grasp the scope.
- Consider adding a dedicated 'Annotation Protocol' subsection (or appendix) with the missing verification metrics; this is standard for benchmark papers and would strengthen reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for transparency on the expert verification process. This is a valid concern for establishing the benchmark's reliability. We address the point below and commit to a major revision that incorporates the requested details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that instances are 'nutrition-expert-verified' and encode 'clinical nutrition constraints' is load-bearing for the benchmark's utility, yet the text supplies no details on expert credentials, annotation guidelines, number of reviewers per instance, conflict resolution, or inter-rater agreement statistics. Without these, it is impossible to assess whether suitability labels reflect reliable clinical constraints or subjective judgments.
Authors: We agree that the manuscript currently lacks these methodological details, which are necessary for readers to evaluate the robustness of the 'nutrition-expert-verified' claims. The abstract and main text do not report expert credentials, guidelines, reviewer counts, conflict resolution procedures, or agreement statistics. In the revised manuscript we will add a dedicated 'Annotation and Verification Process' subsection (expanding the existing Benchmark Construction section) that specifies: (1) expert credentials (e.g., registered dietitians with minimum years of clinical experience in the relevant conditions), (2) the annotation guidelines provided to experts, (3) the number of reviewers per instance, (4) the conflict-resolution protocol, and (5) inter-rater agreement metrics (e.g., Cohen's kappa or percentage agreement). This addition will directly address the load-bearing nature of the verification claim. revision: yes
Circularity Check
Benchmark construction paper exhibits no circularity
full rationale
This paper introduces FAM-Bench as a new multimodal dataset and evaluation tasks for health-aware food reasoning. It contains no equations, fitted parameters, predictions, uniqueness theorems, or derivation chains of any kind. The 2500 instances and suitability labels are constructed and expert-verified by definition of the benchmark effort itself; there are no self-referential reductions where an output is forced by prior fitted inputs or self-citations. The work is self-contained as dataset creation rather than any claimed derivation from prior results.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
LADBench: A Benchmark for Logical Fault Detection in Images
LADBench is a new benchmark showing leading VLMs reach at most 70.11% accuracy on logical fault detection even after explicit hints.
Reference graph
Works this paper leans on
-
[1]
InEuropean conference on computer vision, pages 446–461
Food-101–mining discriminative components with random forests. InEuropean conference on computer vision, pages 446–461. Springer. Frank L Bryan, World Health Organization, and 1 others. 1992.Hazard analysis critical control point evalua- tions: a guide to identifying hazards and assessing risks associated with food preparation and storage. World Health Or...
1992
-
[2]
Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261. Steven Y Feng, Vivek Khetan, Bogdan Sacaleanu, Ana- tole Gershman, and Eduard Hovy. 2023. Chard: clini- cal health-aware reasoning across dimensions for text generation models. InProceedings of ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Andong Hua, Mehak Preet Dhaliwal, Laya Pullela, Ryan Burke, and Yao Qin
January food benchmark (jfb): A public bench- mark dataset and evaluation suite for multimodal food analysis.arXiv preprint arXiv:2508.09966. Andong Hua, Mehak Preet Dhaliwal, Laya Pullela, Ryan Burke, and Yao Qin. 2024. Nutribench: a dataset for evaluating large language models on nu- trition estimation from meal descriptions.arXiv preprint arXiv:2407.12...
-
[4]
Gemma 3 technical report.arXiv preprint arXiv:2503.19786. Saman Khamesian, Asiful Arefeen, Stephanie M Car- penter, and Hassan Ghasemzadeh. 2025. Nutrigen: Personalized meal plan generator leveraging large language models to enhance dietary and nutritional adherence. In2025 47th Annual International Con- ference of the IEEE Engineering in Medicine and Bio...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
arXiv preprint arXiv:2311.16452
Can generalist foundation models outcom- pete special-purpose tuning? case study in medicine. arXiv preprint arXiv:2311.16452. OpenAI. 2025. Introducing GPT-5.4. OpenAI Release Announcement. https://openai.com/ index/introducing-gpt-5-4/. Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. 2023. Med-halt: Medical domain hallucination test for ...
-
[6]
Hangyu Sha, Fan Gong, Bo Liu, Runfeng Liu, Haofen Wang, and Tianxing Wu
Health risk assessment of dietary chemi- cal exposures: A comprehensive review.F oods, 14(23):4133. Hangyu Sha, Fan Gong, Bo Liu, Runfeng Liu, Haofen Wang, and Tianxing Wu. 2025. Leverag- ing retrieval-augmented large language models for dietary recommendations with traditional chinese medicine’s medicine food homology: algorithm de- velopment and validat...
2025
-
[7]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8903–8911
Nutrition5k: Towards automatic nutritional understanding of generic food. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8903–8911. Madhumita Veeramreddy, Ashok Kumar Pradhan, Swetha Ghanta, Laavanya Rachakonda, and Saraju P Mohanty. 2024. Nutrivision: a system for automatic diet management in smart healthcare.a...
-
[8]
one root of medicine and food
Springer. Zheyuan Zhang, Yiyang Li, Nhi Ha Lan Le, Zehong Wang, Tianyi Ma, Vincent Galassi, Keerthiram Mu- rugesan, Nuno Moniz, Werner Geyer, Nitesh V Chawla, and 1 others. 2025. Ngqa: a nutritional graph question answering benchmark for personal- ized health-aware nutritional reasoning. InProceed- ings of the 63rd Annual Meeting of the Association for Co...
2025
-
[9]
Identify each health condition implied by the question
-
[10]
For each condition, scan the recipe ingredients and nutrition for factors that clearly support or conflict with that condition
-
[11]
conflicting evidence
Weigh supporting vs. conflicting evidence
-
[12]
recommend
Decide "recommend" only when the overall evidence supports suitability; otherwise "not recommend". Use only information from the provided recipe/question context. Return ONLY valid JSON in this exact shape: { "reasoning_steps": ["<step 1>", "<step 2>", "..."], "decision": "recommend|not recommend", "rationale_ingredients": [ { "condition": "<condition nam...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.