Rethinking RAG in Long Videos: What to Retrieve and How to Use It?
Pith reviewed 2026-06-27 06:29 UTC · model grok-4.3
The pith
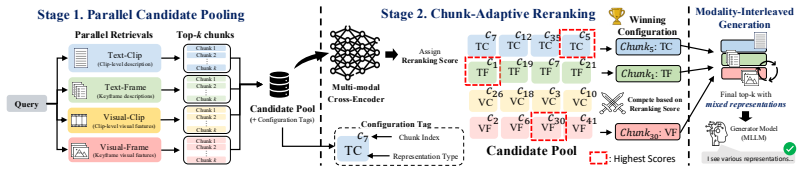
CARVE retrieves and supplies video chunks under individually chosen modality-granularity settings rather than one fixed setting per query.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
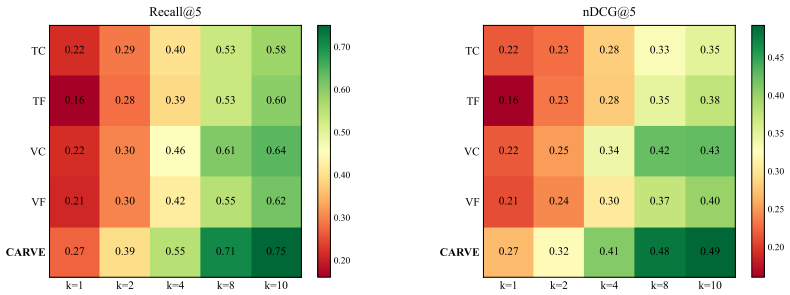
CARVE outperforms eight recent VideoRAG baselines by running parallel retrievers across modality-granularity configurations and applying chunk-adaptive reranking to select a winning configuration for each chunk, so that the generator receives evidence interleaving multiple configurations instead of a single one shared across the query.
What carries the argument
Chunk-adaptive reranking that selects a per-chunk winning configuration from parallel retrievers across different modality and granularity settings.
If this is right
- Retrieval and generation can be evaluated independently because each triplet explicitly links query, required chunks, and answer.
- Evidence reaching the generator can interleave chunks retrieved under different modality-granularity pairs.
- Performance gains arise specifically from allowing configuration decisions to vary at the chunk level rather than the query level.
- A simple parallel-retrieval plus reranking pipeline suffices to beat prior single-configuration VideoRAG methods.
Where Pith is reading between the lines
- Video retrieval systems may gain by treating each chunk as its own retrieval problem instead of making one decision for the entire query.
- The same chunk-level selection idea could be applied after retrieval, for example by letting the generator request alternative configurations for weak chunks.
- V-RAGBench could be extended to measure how often real user queries actually need multiple configurations within one answer.
Load-bearing premise
The benchmark queries are built so the supplied evidence chunks are both necessary and sufficient for the answer, and the chunk-level configuration choices made at retrieval stay optimal once the same chunks reach the generator.
What would settle it
An experiment that forces every chunk in CARVE's output to use the single best query-level configuration and measures whether answer quality drops compared with the original interleaved version.
Figures












read the original abstract
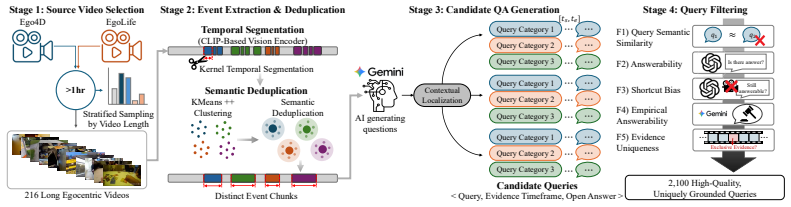
Retrieval-augmented generation is moving beyond text into long, egocentric video, where systems must select query-relevant chunks across multiple modalities and temporal granularities. Yet progress in VideoRAG is limited by two gaps: existing benchmarks allow queries to be answered without the video, obscuring retrieval errors, and prior methods apply a single modality-granularity configuration per query, ignoring chunk-level variability. We address both by introducing V-RAGBench, a benchmark of $\langle$query, evidence chunk, answer$\rangle$ triplets that enables faithful, decoupled evaluation of retrieval and generation, and CARVE, a simple method that runs parallel retrievers across configurations and employs chunk-adaptive reranking to identify the winning configuration for each chunk. Each chunk then enters the generator under its winning configuration selected during retrieval, yielding an interleaved evidence form where the chunk-level decision propagates across both stages. CARVE outperforms eight recent VideoRAG baselines, with the chunks supplied to the generator interleaving multiple configurations rather than sharing a single one, a behavior unattainable by query-level methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies two limitations in VideoRAG for long egocentric videos: benchmarks that permit answers without video content, and methods that apply a single modality-granularity configuration per query. It introduces V-RAGBench, a dataset of query-evidence chunk-answer triplets designed for decoupled retrieval and generation evaluation, and proposes CARVE, which runs parallel retrievers over multiple configurations and applies chunk-adaptive reranking to select a winning configuration per chunk. Each chunk is then passed to the generator under its retrieval-selected configuration, producing an interleaved evidence set. The authors report that CARVE outperforms eight recent VideoRAG baselines and that the resulting interleaved configurations cannot be achieved by query-level approaches.
Significance. If the empirical claims hold under rigorous evaluation, the work would be significant for VideoRAG by demonstrating the value of chunk-level rather than query-level adaptation across modalities and granularities. The introduction of V-RAGBench directly targets a known evaluation flaw and enables more faithful assessment. The CARVE approach is conceptually simple and leverages existing retrievers, which strengthens its potential impact if the chunk-adaptive propagation is shown to be the source of gains rather than an ensemble effect.
major comments (2)
- The central claim that CARVE's advantage stems from propagating chunk-specific configuration decisions from retrieval to generation rests on the assumption that the reranking objective used at retrieval time aligns with the needs of the downstream generator. The provided abstract and description contain no ablation or analysis (e.g., comparing retrieval-selected vs. generator-optimal configurations per chunk) that would confirm this alignment; without such evidence the reported outperformance could arise simply from running eight parallel retrievers rather than from the adaptive mechanism.
- The soundness assessment notes that the abstract supplies no quantitative results, error bars, or dataset statistics. The full manuscript must include these (with held-out test splits and statistical significance) in the experimental section to substantiate the claim of outperforming eight baselines; otherwise the central empirical result cannot be verified as load-bearing.
minor comments (1)
- The abstract would benefit from a brief quantitative statement of the performance gains (e.g., average improvement across metrics and datasets) to allow readers to gauge the magnitude of the reported outperformance.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments highlight important aspects of our central claim and evaluation rigor. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: The central claim that CARVE's advantage stems from propagating chunk-specific configuration decisions from retrieval to generation rests on the assumption that the reranking objective used at retrieval time aligns with the needs of the downstream generator. The provided abstract and description contain no ablation or analysis (e.g., comparing retrieval-selected vs. generator-optimal configurations per chunk) that would confirm this alignment; without such evidence the reported outperformance could arise simply from running eight parallel retrievers rather than from the adaptive mechanism.
Authors: We agree that an explicit ablation demonstrating alignment between the retrieval-time reranking objective and downstream generator performance would strengthen the central claim regarding chunk-level propagation. The current results show overall gains and interleaved configurations, but do not isolate the adaptive mechanism from potential ensemble effects. In the revised manuscript we will add a targeted analysis on held-out data that compares CARVE-selected configurations per chunk against generator-optimal configurations (measured by downstream answer quality), to quantify the degree of alignment and rule out pure ensemble explanations. revision: yes
-
Referee: The soundness assessment notes that the abstract supplies no quantitative results, error bars, or dataset statistics. The full manuscript must include these (with held-out test splits and statistical significance) in the experimental section to substantiate the claim of outperforming eight baselines; otherwise the central empirical result cannot be verified as load-bearing.
Authors: The full manuscript already reports quantitative results with error bars, dataset statistics, held-out test splits, and statistical significance tests in the experimental section. We will revise the presentation to make these elements more prominent and ensure all baseline comparisons are accompanied by the requested statistical details. revision: partial
Circularity Check
No circularity; method design and empirical claims are independent
full rationale
The paper describes CARVE as running parallel retrievers across configurations followed by chunk-adaptive reranking, with each chunk then supplied under its selected configuration. This interleaved behavior is a direct, explicit consequence of the method definition rather than a derived prediction or fitted result. No equations, parameter fitting, self-citations, or uniqueness theorems appear in the provided text. The outperformance claim is presented as an empirical observation on V-RAGBench; the benchmark and method are introduced as new contributions without reducing to prior self-referential inputs. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multiple modality-granularity configurations can be run in parallel and compared per chunk without prohibitive compute cost.
Reference graph
Works this paper leans on
-
[1]
Rankarena: A unified platform for evaluating retrieval, reranking and rag with human and llm feedback
Abdelrahman Abdallah, Mahmoud Abdalla, Bhawna Piryani, Jamshid Mozafari, Mohammed Ali, and Adam Jatowt. Rankarena: A unified platform for evaluating retrieval, reranking and rag with human and llm feedback. InCIKM, 2025
2025
-
[2]
A survey on rag with llms.Procedia Computer Science, 246:3781–3790, 2024
Muhammad Arslan, Hussam Ghanem, Saba Munawar, and Christophe Cruz. A survey on rag with llms.Procedia Computer Science, 246:3781–3790, 2024
2024
-
[3]
k-means++: The advantages of careful seeding
David Arthur, Sergei Vassilvitskii, et al. k-means++: The advantages of careful seeding. In Soda, volume 7, pages 1027–1035, 2007
2007
-
[4]
Query expansion techniques for information retrieval: a survey.Information Processing & Management, 56(5):1698–1735, 2019
Hiteshwar Kumar Azad and Akshay Deepak. Query expansion techniques for information retrieval: a survey.Information Processing & Management, 56(5):1698–1735, 2019
2019
-
[5]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[6]
Wear: An outdoor sports dataset for wearable and egocentric activity recognition.IMWUT, 2024
Marius Bock, Hilde Kuehne, Kristof Van Laerhoven, and Michael Moeller. Wear: An outdoor sports dataset for wearable and egocentric activity recognition.IMWUT, 2024
2024
-
[7]
Moment sampling in video llms for long-form video qa.arXiv preprint arXiv:2507.00033, 2025
Mustafa Chasmai, Gauri Jagatap, Gouthaman KV , Grant Van Horn, Subhransu Maji, and Andrea Fanelli. Moment sampling in video llms for long-form video qa.arXiv preprint arXiv:2507.00033, 2025
arXiv 2025
-
[8]
Lvagent: Long video understanding by multi-round dynamical collaboration of mllm agents
Boyu Chen, Zhengrong Yue, Siran Chen, Zikang Wang, Yang Liu, Peng Li, and Yali Wang. Lvagent: Long video understanding by multi-round dynamical collaboration of mllm agents. In ICCV, 2025
2025
-
[9]
Guo Chen, Yicheng Liu, Yifei Huang, Yuping He, Baoqi Pei, Jilan Xu, Yali Wang, Tong Lu, and Limin Wang. Cg-bench: Clue-grounded question answering benchmark for long video understanding.arXiv preprint arXiv:2412.12075, 2024
arXiv 2024
-
[10]
Guo Chen, Lidong Lu, Yicheng Liu, Liangrui Dong, Lidong Zou, Jixin Lv, Zhenquan Li, Xinyi Mao, Baoqi Pei, Shihao Wang, et al. Towards multimodal lifelong understanding: A dataset and agentic baseline.arXiv preprint arXiv:2603.05484, 2026
arXiv 2026
-
[11]
Sharegpt4video: Improving video understanding and generation with better captions
Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Bin Lin, Zhenyu Tang, et al. Sharegpt4video: Improving video understanding and generation with better captions. InNeurIPS, 2024
2024
-
[12]
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms.arXiv preprint arXiv:2406.07476, 2024
Pith/arXiv arXiv 2024
-
[13]
Word2passage: Word-level importance re-weighting for query expansion
Jeonghwan Choi, Minjeong Ban, Minseok Kim, and Hwanjun Song. Word2passage: Word-level importance re-weighting for query expansion. InACL, 2025
2025
-
[14]
A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20(1):37–46, 1960
Jacob Cohen. A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20(1):37–46, 1960
1960
-
[15]
Grounded question-answering in long egocentric videos
Shangzhe Di and Weidi Xie. Grounded question-answering in long egocentric videos. InCVPR, 2024
2024
-
[16]
Semantic event graphs for long-form video question answering
Aradhya Dixit and Tianxi Liang. Semantic event graphs for long-form video question answering. arXiv preprint arXiv:2601.06097, 2026
arXiv 2026
-
[17]
Splade: Sparse lexical and expansion model for first stage ranking
Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. Splade: Sparse lexical and expansion model for first stage ranking. InSIGIR, 2021
2021
-
[18]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InCVPR, 2025. 10
2025
-
[19]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. InCVPR, 2022
2022
-
[20]
Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding
Yongxin Guo, Jingyu Liu, Mingda Li, Dingxin Cheng, Xiaoying Tang, Dianbo Sui, Qingbin Liu, Xi Chen, and Kevin Zhao. Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding. InAAAI, 2025
2025
-
[21]
Gyuwon Han, Young Kyun Jang, and Chanho Eom. Cova: Text-guided composed video retrieval for audio-visual content.arXiv preprint arXiv:2601.22508, 2026
arXiv 2026
-
[22]
Hsin-Ling Hsu and Jengnan Tzeng. Dat: Dynamic alpha tuning for hybrid retrieval in retrieval- augmented generation.arXiv preprint arXiv:2503.23013, 2025
arXiv 2025
-
[23]
M-llm based video frame selection for efficient video understanding
Kai Hu, Feng Gao, Xiaohan Nie, Peng Zhou, Son Tran, Tal Neiman, Lingyun Wang, Mubarak Shah, Raffay Hamid, Bing Yin, and Trishul Chilimbi. M-llm based video frame selection for efficient video understanding. InCVPR, 2025
2025
-
[24]
Prunevid: Visual token pruning for efficient video large language models
Xiaohu Huang, Hao Zhou, and Kai Han. Prunevid: Visual token pruning for efficient video large language models. InACL, 2025
2025
-
[25]
Video recap: Recursive captioning of hour-long videos.arXiv preprint arXiv:2402.13250, 2024
Md Mohaiminul Islam, Ngan Ho, Xitong Yang, Tushar Nagarajan, Lorenzo Torresani, and Gedas Bertasius. Video recap: Recursive captioning of hour-long videos.arXiv preprint arXiv:2402.13250, 2024
arXiv 2024
-
[26]
Md Mohaiminul Islam, Ngan Ho, Xitong Yang, Tushar Nagarajan, Lorenzo Torresani, and Gedas Bertasius. Ravu: Retrieval augmented video understanding with compositional reasoning over graph.arXiv preprint arXiv:2505.03173, 2025
arXiv 2025
-
[27]
Tgif-qa: Toward spatio-temporal reasoning in visual question answering
Yunseok Jang, Yale Song, Youngjae Yu, Youngjin Kim, and Gunhee Kim. Tgif-qa: Toward spatio-temporal reasoning in visual question answering. InCVPR, 2017
2017
-
[28]
Videorag: Retrieval- augmented generation over video corpus
Soyeong Jeong, Kangsan Kim, Jinheon Baek, and Sung Ju Hwang. Videorag: Retrieval- augmented generation over video corpus. InACL, 2025
2025
-
[29]
Active retrieval augmented generation
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. InEMNLP, 2023
2023
-
[30]
Language repository for long video understanding
Kumara Kahatapitiya, Kanchana Ranasinghe, Jongwoo Park, and Michael S Ryoo. Language repository for long video understanding. InACL, 2025
2025
-
[31]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InEMNLP, 2020
2020
-
[32]
Video summarization with large language models
Min Jung Lee, Dayoung Gong, and Minsu Cho. Video summarization with large language models. InCVPR, 2025
2025
-
[33]
Tvqa: Localized, compositional video question answering
Jie Lei, Licheng Yu, Mohit Bansal, and Tamara Berg. Tvqa: Localized, compositional video question answering. InEMNLP, 2018
2018
-
[34]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. InNeurIPS, 2020
2020
-
[35]
Videochat: Chat-centric video understanding.Science China Information Sciences, 2025
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding.Science China Information Sciences, 2025
2025
-
[36]
Lla- trieval: Llm-verified retrieval for verifiable generation
Xiaonan Li, Changtai Zhu, Linyang Li, Zhangyue Yin, Tianxiang Sun, and Xipeng Qiu. Lla- trieval: Llm-verified retrieval for verifiable generation. InNAACL, 2024. 11
2024
-
[37]
Video-oasis: Rethinking evaluation of video understanding.arXiv preprint arXiv:2603.29616, 2026
Geuntaek Lim, Minho Shim, Sungjune Park, Jaeyun Lee, Inwoong Lee, Taeoh Kim, Dongyoon Wee, and Yukyung Choi. Video-oasis: Rethinking evaluation of video understanding.arXiv preprint arXiv:2603.29616, 2026
arXiv 2026
-
[38]
Video-llava: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. InEMNLP, 2024
2024
-
[39]
Mm-embed: Universal multimodal retrieval with multimodal llms.arXiv preprint arXiv:2411.02571, 2024
Sheng-Chieh Lin, Chankyu Lee, Mohammad Shoeybi, Jimmy Lin, Bryan Catanzaro, and Wei Ping. Mm-embed: Universal multimodal retrieval with multimodal llms.arXiv preprint arXiv:2411.02571, 2024
arXiv 2024
-
[40]
Multi-granularity correspondence learning from long-term noisy videos
Yijie Lin, Jie Zhang, Zhenyu Huang, Jia Liu, Zujie Wen, and Xi Peng. Multi-granularity correspondence learning from long-term noisy videos. InICLR, 2024
2024
-
[41]
Video paragraph captioning as a text summarization task
Hui Liu and Xiaojun Wan. Video paragraph captioning as a text summarization task. InACL, 2021
2021
-
[42]
Video-rag: Visually-aligned retrieval-augmented long video comprehension
Yongdong Luo, Xiawu Zheng, Guilin Li, Shukang Yin, Haojia Lin, Chaoyou Fu, Jinfa Huang, Jiayi Ji, Fei Chao, Jiebo Luo, et al. Video-rag: Visually-aligned retrieval-augmented long video comprehension. InNeurIPS, 2025
2025
-
[43]
Query rewriting in retrieval- augmented large language models
Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. Query rewriting in retrieval- augmented large language models. InEMNLP, 2023
2023
-
[44]
Drvideo: Document retrieval based long video understanding
Ziyu Ma, Chenhui Gou, Hengcan Shi, Bin Sun, Shutao Li, Hamid Rezatofighi, and Jianfei Cai. Drvideo: Document retrieval based long video understanding. InCVPR, 2025
2025
-
[45]
Video-chatgpt: Towards detailed video understanding via large vision and language models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. InACL, 2024
2024
-
[46]
Priyanka Mandikal and Raymond Mooney. Sparse meets dense: A hybrid approach to enhance scientific document retrieval.arXiv preprint arXiv:2401.04055, 2024
arXiv 2024
-
[47]
Egoschema: A diagnostic benchmark for very long-form video language understanding
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding. InNeurIPS, 2023
2023
-
[48]
Alkesh Patel, Vibhav Chitalia, and Yinfei Yang. Advancing egocentric video question answering with multimodal large language models.arXiv preprint arXiv:2504.04550, 2025
arXiv 2025
-
[49]
Category-specific video summarization
Danila Potapov, Matthijs Douze, Zaid Harchaoui, and Cordelia Schmid. Category-specific video summarization. InECCV, 2014
2014
-
[50]
Rag-fusion: a new take on retrieval-augmented generation.arXiv preprint arXiv:2402.03367, 2024
Zackary Rackauckas. Rag-fusion: a new take on retrieval-augmented generation.arXiv preprint arXiv:2402.03367, 2024
arXiv 2024
-
[51]
Agentic very long video understanding.arXiv preprint arXiv:2601.18157, 2026
Aniket Rege, Arka Sadhu, Yuliang Li, Kejie Li, Ramya Korlakai Vinayak, Yuning Chai, Yong Jae Lee, and Hyo Jin Kim. Agentic very long video understanding.arXiv preprint arXiv:2601.18157, 2026
arXiv 2026
-
[52]
Timechat: A time-sensitive multimodal large language model for long video understanding
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. Timechat: A time-sensitive multimodal large language model for long video understanding. InCVPR, 2024
2024
-
[53]
Videorag: Retrieval-augmented generation with extreme long-context videos
Xubin Ren, Lingrui Xu, Long Xia, Shuaiqiang Wang, Dawei Yin, and Chao Huang. Videorag: Retrieval-augmented generation with extreme long-context videos. InKDD, 2026
2026
-
[54]
Blended rag: Improving rag (retriever-augmented generation) accuracy with semantic search and hybrid query-based retriev- ers
Kunal Sawarkar, Abhilasha Mangal, and Shivam Raj Solanki. Blended rag: Improving rag (retriever-augmented generation) accuracy with semantic search and hybrid query-based retriev- ers. InMIPR, 2024
2024
-
[55]
Vgent: Graph-based retrieval-reasoning-augmented generation for long video understanding
Xiaoqian Shen, Wenxuan Zhang, Jun Chen, and Mohamed Elhoseiny. Vgent: Graph-based retrieval-reasoning-augmented generation for long video understanding. InNeurIPS, 2025
2025
-
[56]
Aditi Singh, Abul Ehtesham, Saket Kumar, and Tala Talaei Khoei. Agentic retrieval-augmented generation: A survey on agentic rag.arXiv preprint arXiv:2501.09136, 2025. 12
Pith/arXiv arXiv 2025
-
[57]
Eva-clip: Improved training techniques for clip at scale.arXiv preprint arXiv:2303.15389, 2023
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale.arXiv preprint arXiv:2303.15389, 2023
Pith/arXiv arXiv 2023
-
[58]
Shitong Sun, Ke Han, Yukai Huang, Weitong Cai, and Jifei Song. Egograph: Temporal knowl- edge graph for egocentric video understanding.arXiv preprint arXiv:2602.23709, 2026
arXiv 2026
-
[59]
Guided query refinement: Multimodal hybrid retrieval with test-time optimization
Omri Uzan, Asaf Yehudai, Eyal Shnarch, Ariel Gera, et al. Guided query refinement: Multimodal hybrid retrieval with test-time optimization. 2026
2026
-
[60]
Dynamic-vlm: Simple dynamic visual token compression for videollm
Han Wang, Yuxiang Nie, Yongjie Ye, Yanjie Wang, Shuai Li, Haiyang Yu, Jinghui Lu, and Can Huang. Dynamic-vlm: Simple dynamic visual token compression for videollm. InICCV, 2025
2025
-
[61]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
Pith/arXiv arXiv 2024
-
[62]
Videoagent: Long-form video understanding with large language model as agent
Xiaohan Wang, Yuhui Zhang, Orr Zohar, and Serena Yeung-Levy. Videoagent: Long-form video understanding with large language model as agent. InECCV, 2024
2024
-
[63]
Maferw: Query rewriting with multi-aspect feedbacks for retrieval-augmented large language models
Yujing Wang, Hainan Zhang, Liang Pang, Binghui Guo, Hongwei Zheng, and Zhiming Zheng. Maferw: Query rewriting with multi-aspect feedbacks for retrieval-augmented large language models. InAAAI, 2025
2025
-
[64]
Infogain-rag: Boosting retrieval-augmented generation through document information gain-based reranking and filtering
Zihan Wang, Zihan Liang, Zhou Shao, Yufei Ma, Huangyu Dai, Ben Chen, Lingtao Mao, Chenyi Lei, Yuqing Ding, and Han Li. Infogain-rag: Boosting retrieval-augmented generation through document information gain-based reranking and filtering. InEMNLP, 2025
2025
-
[65]
Videotree: Adaptive tree-based video representation for llm reasoning on long videos
Ziyang Wang, Shoubin Yu, Elias Stengel-Eskin, Jaehong Yoon, Feng Cheng, Gedas Bertasius, and Mohit Bansal. Videotree: Adaptive tree-based video representation for llm reasoning on long videos. InCVPR, 2025
2025
-
[66]
Ziyang Wang, Honglu Zhou, Shijie Wang, Junnan Li, Caiming Xiong, Silvio Savarese, Mohit Bansal, Michael S Ryoo, and Juan Carlos Niebles. Active video perception: Iterative evidence seeking for agentic long video understanding.arXiv preprint arXiv:2512.05774, 2025
Pith/arXiv arXiv 2025
-
[67]
Longvideobench: A benchmark for long-context interleaved video-language understanding
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding. InNeurIPS, 2024
2024
-
[68]
C-pack: Packaged resources to advance general chinese embedding, 2023
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-pack: Packaged resources to advance general chinese embedding, 2023
2023
-
[69]
Video question answering via gradually refined attention over appearance and motion
Dejing Xu, Zhou Zhao, Jun Xiao, Fei Wu, Hanwang Zhang, Xiangnan He, and Yueting Zhuang. Video question answering via gradually refined attention over appearance and motion. InMM, 2017
2017
-
[70]
Zeyu Xu, Junkang Zhang, Qiang Wang, and Yi Liu. E-vrag: Enhancing long video understanding with resource-efficient retrieval augmented generation.arXiv preprint arXiv:2508.01546, 2025
arXiv 2025
-
[71]
Zhucun Xue, Jiangning Zhang, Xurong Xie, Yuxuan Cai, Yong Liu, Xiangtai Li, and Dacheng Tao. Adavideorag: Omni-contextual adaptive retrieval-augmented efficient long video under- standing.arXiv preprint arXiv:2506.13589, 2025
arXiv 2025
-
[72]
Corrective retrieval augmented generation.arXiv preprint arXiv:2401.15884, 2024
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. Corrective retrieval augmented generation.arXiv preprint arXiv:2401.15884, 2024
Pith/arXiv arXiv 2024
-
[73]
Egolife: Towards egocentric life assistant
Jingkang Yang, Shuai Liu, Hongming Guo, Yuhao Dong, Xiamengwei Zhang, Sicheng Zhang, Pengyun Wang, Zitang Zhou, Binzhu Xie, Ziyue Wang, et al. Egolife: Towards egocentric life assistant. InCVPR, 2025
2025
-
[74]
Songyuan Yang, Weijiang Yu, Ziyu Liu, Guijian Tang, Wenjing Yang, Huibin Tan, and Nong Xiao. Graph-to-frame rag: Visual-space knowledge fusion for training-free and auditable video reasoning.arXiv preprint arXiv:2604.04372, 2026
Pith/arXiv arXiv 2026
-
[75]
Generative frame sampler for long video understanding
Linli Yao, Haoning Wu, Kun Ouyang, Yuanxing Zhang, Caiming Xiong, Bei Chen, Xu Sun, and Junnan Li. Generative frame sampler for long video understanding. InACL, 2025. 13
2025
-
[76]
Univer- salrag: Retrieval-augmented generation over corpora of diverse modalities and granularities
Woongyeong Yeo, Kangsan Kim, Soyeong Jeong, Jinheon Baek, and Sung Ju Hwang. Univer- salrag: Retrieval-augmented generation over corpora of diverse modalities and granularities. 2026
2026
-
[77]
Worldmm: Dynamic multimodal memory agent for long video reasoning
Woongyeong Yeo, Kangsan Kim, Jaehong Yoon, and Sung Ju Hwang. Worldmm: Dynamic multimodal memory agent for long video reasoning. InCVPR, 2026
2026
-
[78]
Rankrag: Unifying context ranking with retrieval-augmented generation in llms
Yue Yu, Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Chao Zhang, Mohammad Shoeybi, and Bryan Catanzaro. Rankrag: Unifying context ranking with retrieval-augmented generation in llms. InNeurIPS, 2024
2024
-
[79]
Activitynet-qa: A dataset for understanding complex web videos via question answering
Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yueting Zhuang, and Dacheng Tao. Activitynet-qa: A dataset for understanding complex web videos via question answering. In AAAI, 2019
2019
-
[80]
T5gemma 2: Seeing, reading, and understanding longer.arXiv preprint arXiv:2512.14856, 2025
Biao Zhang, Paul Suganthan, Gaël Liu, Ilya Philippov, Sahil Dua, Ben Hora, Kat Black, Gus Martins, Omar Sanseviero, Shreya Pathak, et al. T5gemma 2: Seeing, reading, and understanding longer.arXiv preprint arXiv:2512.14856, 2025
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.