Code Isn't Memory: A Structural Codebase Index Inside a Coding Agent
Pith reviewed 2026-06-26 10:57 UTC · model grok-4.3
The pith
Adding a structural codebase index improves localization and task resolution in a fixed coding-agent harness without raising cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
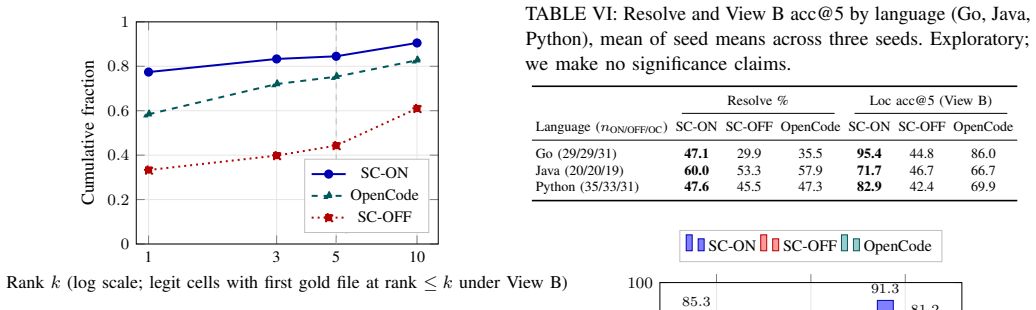
Within a fixed coding-agent harness on a fixed model, the structural codebase index produces a large localization gain and a statistically separated resolve gain, with no cost penalty per cell and lower cost per solve; it also matches or exceeds an agentic-grep comparator on resolve and localization at no cost penalty.
What carries the argument
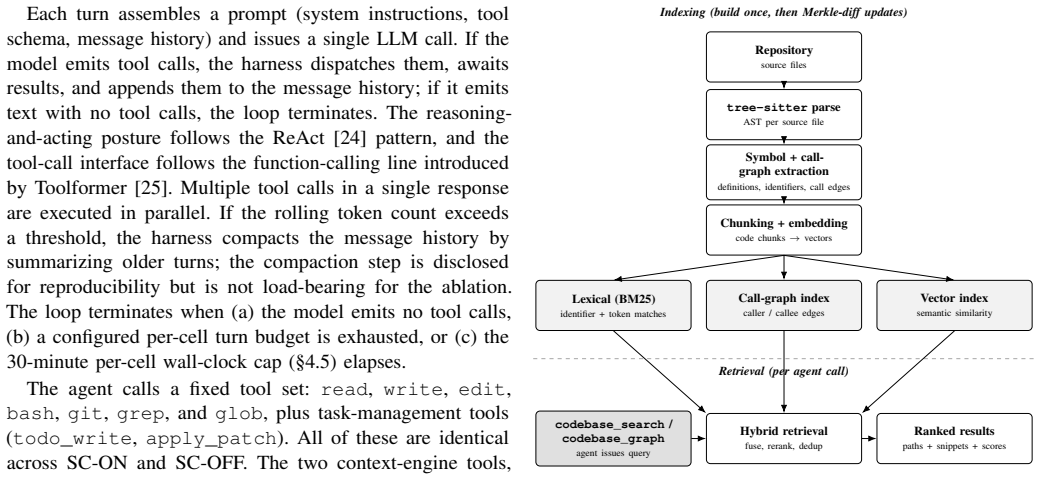
structural codebase index, which supplies ranked retrieval over the repository using code structure rather than surface text or simple search.
If this is right
- The index yields large localization gains inside the fixed harness.
- Resolve gains reach statistical separation from the no-index arm.
- Cost per cell stays flat while cost per solved task drops.
- Performance does not regress against an agentic-grep baseline on resolve or localization.
- The index becomes relevant precisely when workloads include multi-file changes that benefit from structural ranking.
Where Pith is reading between the lines
- If gains concentrate on multi-file tasks, then agents handling large refactors or cross-module edits would capture most of the benefit.
- Releasing the per-cell exclusion ledger and leak-audit script lets other groups test the same isolation on their own harnesses.
- Repeating the three-arm comparison on different models or larger repositories would reveal how stable the cost and resolve advantages remain.
Load-bearing premise
The structural index is the only causal driver of the observed localization and resolve differences, and the chosen benchmarks plus sandbox controls isolate its effect from other harness variables.
What would settle it
An ablation that achieves the same localization and resolve rates as the index version by adjusting only non-structural retrieval parameters while keeping every other harness component identical would show the structural ranking is not required for the gains.
Figures


read the original abstract
Coding agents now interleave LLMs with retrieval over the working repository, and retrieval implementations vary widely across deployed harnesses. Inside a fixed coding-agent harness on a fixed model, does adding a structural codebase index actually change cost or resolve? We ran three arms (the harness with the index, the same harness without it, and an agentic-grep comparator) on SWE-PolyBench Verified and SWE-bench Pro with Claude Opus 4.7 held fixed throughout, across three seeds, inside a leak-audited per-task sandbox. The within-harness ablation produces a large localization gain and a statistically separated resolve gain, with no cost penalty per cell and lower cost per solve. The cross-harness check shows that the index does not regress against an agentic-grep baseline on resolve or localization, again at no cost penalty. We release the per-cell exclusion ledger, the leak-audit script, the localization extractor, and the results database. The deployment question for a structural codebase index is thus not whether it is too expensive to run (across seeds, the index lands at a lower $/solved than agentic grep) but whether the workload includes multi-file changes where structural ranking pays off.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates whether adding a structural codebase index to a fixed coding-agent harness changes cost or resolve rates. It runs three arms (harness with index, same harness without index, and agentic-grep comparator) on SWE-PolyBench Verified and SWE-bench Pro using Claude Opus 4.7 across three seeds in a leak-audited sandbox. The central claim is that the within-harness ablation yields large localization gains and statistically separated resolve gains with no per-cell cost penalty and lower cost per solve; the cross-harness check shows no regression versus agentic-grep. The paper releases the per-cell exclusion ledger, leak-audit script, localization extractor, and results database.
Significance. If the ablation results hold under the stated controls, the work would supply direct empirical evidence that structural indices can improve localization and resolution on multi-file tasks without raising per-cell cost, thereby reframing the deployment question around workload characteristics rather than raw expense. The open release of the exclusion ledger, audit script, and results database is a concrete strength that supports reproducibility and independent verification.
major comments (3)
- [Methods (ablation design)] Methods (ablation design): The description of the 'same harness without it' arm asserts that the harness and sandbox are fixed but does not explicitly confirm that retrieval logic, context assembly, prompting, and ranking remain bitwise identical when the index is disabled; any incidental difference would undermine the claim that the structural index is the sole causal driver of the reported localization and resolve gains.
- [Results (statistical claims)] Results (statistical claims): The abstract states a 'statistically separated resolve gain' without naming the test statistic, sample sizes per arm, exact p-value threshold, or correction for multiple comparisons across benchmarks and seeds; this detail is load-bearing for the central claim of separation.
- [Data handling] Data handling: Although the per-cell exclusion ledger is released, the methods section must specify whether exclusion criteria were pre-registered or determined after inspecting outcomes, because post-hoc choices could affect the measured gains on localization and resolve.
minor comments (2)
- [Abstract] Abstract: 'Claude Opus 4.7' should be replaced by the precise model identifier used in the experiments.
- [Figures and tables] Figures and tables: Captions should explicitly list the benchmark names, number of tasks, and seed count so that each display is self-contained.
Simulated Author's Rebuttal
Thank you for the referee's detailed and constructive comments. We address each major comment point by point below, with commitments to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: The description of the 'same harness without it' arm asserts that the harness and sandbox are fixed but does not explicitly confirm that retrieval logic, context assembly, prompting, and ranking remain bitwise identical when the index is disabled; any incidental difference would undermine the claim that the structural index is the sole causal driver of the reported localization and resolve gains.
Authors: We agree that explicit confirmation is required to support the causal attribution. The harness code implements the structural index as a self-contained optional module; toggling it off leaves every other component (retrieval logic, context assembly, prompting templates, and ranking) unchanged at the source level. In the revised manuscript we will add a dedicated sentence in the Methods section stating this bitwise identity explicitly. revision: yes
-
Referee: The abstract states a 'statistically separated resolve gain' without naming the test statistic, sample sizes per arm, exact p-value threshold, or correction for multiple comparisons across benchmarks and seeds; this detail is load-bearing for the central claim of separation.
Authors: The statistical details are already present in the Results section and the released database, but the abstract should be self-contained. We will revise the abstract to name the test statistic, state the per-arm sample sizes (three seeds), report the p-value threshold, and describe the multiple-comparison approach. revision: yes
-
Referee: Although the per-cell exclusion ledger is released, the methods section must specify whether exclusion criteria were pre-registered or determined after inspecting outcomes, because post-hoc choices could affect the measured gains on localization and resolve.
Authors: We will add an explicit statement to the Methods section indicating whether the exclusion criteria were pre-registered or determined post-inspection, together with the rationale and a pointer to the released ledger. revision: yes
Circularity Check
No circularity: direct empirical ablation on external benchmarks
full rationale
The paper reports measured outcomes from three fixed-harness arms (with-index, without-index, agentic-grep) run on SWE-PolyBench Verified and SWE-bench Pro using a held-fixed model and sandbox. All claims rest on observed localization, resolve, and cost differences across seeds; no equations, fitted parameters, self-citations, or derivations are invoked to produce the results. The within-harness comparison is presented as a controlled measurement rather than a reduction to prior inputs or self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption SWE-PolyBench Verified and SWE-bench Pro are representative of the multi-file coding tasks where structural ranking would matter.
- domain assumption The structural index implementation and the within-harness comparison isolate the index effect from other variables.
Reference graph
Works this paper leans on
-
[1]
Introducing Claude Opus 4.7
Anthropic. Introducing Claude Opus 4.7. Anthropic blog post, https://www.anthropic.com/news/claude-opus-4-7, 2026
2026
-
[2]
Sahil Sen, Akhil Kasturi, Elias Lumer, Anmol Gulati, and Vamse Kumar Subbiah. Is grep all you need? how agent harnesses reshape agentic search.arXiv preprint arXiv:2605.15184, 2026. URL https://arxiv.org/abs/2605. 15184
Pith/arXiv arXiv 2026
-
[3]
SWE- Bench+: Enhanced coding benchmark for LLMs.arXiv preprint arXiv:2410.06992, 2024
Reem Aleithan, Haoran Xue, Mohammad Mahdi Mohajer, Elijah Nnorom, Gias Uddin, and Song Wang. SWE- Bench+: Enhanced coding benchmark for LLMs.arXiv preprint arXiv:2410.06992, 2024. URL https://arxiv.org/ abs/2410.06992
arXiv 2024
-
[4]
Shanchao Liang, Spandan Garg, and Roshanak Zilouch- ian Moghaddam. The SWE-Bench illusion: When state-of- the-art LLMs remember instead of reason.arXiv preprint arXiv:2506.12286, 2025. URL https://arxiv.org/abs/2506. 12286
arXiv 2025
-
[5]
Spandan Garg, Benjamin Steenhoek, and Yufan Huang. Saving SWE-Bench: A benchmark mutation ap- proach for realistic agent evaluation.arXiv preprint arXiv:2510.08996, 2025. URL https://arxiv.org/abs/2510. 08996
arXiv 2025
-
[6]
SuperCoder: An autonomous AI coding-agent harness
SuperAGI Research and SuperCoder Con- tributors. SuperCoder: An autonomous AI coding-agent harness. GitHub repository, https://github.com/TransformerOptimus/SuperCoder, 2024
2024
-
[7]
opencode: The AI coding agent built for the terminal
SST and opencode Contributors. opencode: The AI coding agent built for the terminal. GitHub repository, https: //github.com/sst/opencode, 2025
2025
-
[8]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. URL https://arxiv. org/abs/2405.15793
Pith/arXiv arXiv 2024
-
[9]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, et al
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, et al. OpenHands: An open platform for AI software developers as generalist agents. InInternational Conference on Learning Representations (ICLR), 2025. URL https://arxiv.org/abs/2407.16741
Pith/arXiv arXiv 2025
-
[10]
Aider: AI pair programming in your terminal
Paul Gauthier and Aider Contributors. Aider: AI pair programming in your terminal. GitHub repository, https: //github.com/Aider-AI/aider, 2026
2026
-
[11]
AutoCodeRover: Autonomous program improvement
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. AutoCodeRover: Autonomous program improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA), 2024. URL https://arxiv.org/abs/2404.05427
arXiv 2024
-
[12]
RepoCoder: Repository-level code completion through iterative retrieval and generation
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. RepoCoder: Repository-level code completion through iterative retrieval and generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023. URL https://arxiv. org/abs/2303.12570
arXiv 2023
-
[13]
Ramakrishna Bairi, Atharv Sonwane, Aditya Kanade, D. C. Vageesh, Arun Iyer, Suresh Parthasarathy, Sriram Rajamani, B. Ashok, and Shashank Shet. CodePlan: Repository-level coding using LLMs and planning.arXiv preprint arXiv:2309.12499, 2023. URL https://arxiv.org/ abs/2309.12499. Published in FSE 2024
arXiv 2023
-
[14]
LocAgent: Graph-guided LLM agents for code localization
Zhaoling Chen, Robert Tang, Gangda Deng, Fang Wu, Jialong Wu, Zhiwei Jiang, Viktor Prasanna, Arman Cohan, and Xingyao Wang. LocAgent: Graph-guided LLM agents for code localization. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025. URL https://arxiv.org/abs/2503.09089
arXiv 2025
-
[15]
Siru Ouyang, Wenhao Yu, Kaixin Ma, Zilin Xiao, Zhihan Zhang, Mengzhao Jia, Jiawei Han, Hongming Zhang, and Dong Yu. RepoGraph: Enhancing AI software engineering with repository-level code graph.arXiv preprint arXiv:2410.14684, 2024. URL https://arxiv.org/ abs/2410.14684
arXiv 2024
-
[16]
Hongyuan Tao, Ying Zhang, Zhenhao Tang, Hongen Peng, Xukun Zhu, Bingchang Liu, Yingguang Yang, Ziyin Zhang, Zhaogui Xu, Haipeng Zhang, Linchao Zhu, Rui Wang, Hang Yu, Jianguo Li, and Peng Di. Code graph model (CGM): A graph-integrated large language model for repository-level software engineering tasks. InAdvances in Neural Information Processing Systems ...
arXiv 2025
-
[17]
Agentless: Demystifying LLM- based software engineering agents.arXiv preprint arXiv:2407.01489, 2024
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Agentless: Demystifying LLM- based software engineering agents.arXiv preprint arXiv:2407.01489, 2024. URL https://arxiv.org/abs/2407. 01489
Pith/arXiv arXiv 2024
-
[19]
URL https://arxiv.org/abs/2603.24631
-
[20]
SWE-Explore: Benchmarking how coding agents explore repositories
Shaoqiu Zhang, Yuhang Wang, Jialiang Liang, Yuling Shi, Wenhao Zeng, Maoquan Wang, Shilin He, Ningyuan Xu, Siyu Ye, Kai Cai, and Xiaodong Gu. SWE-Explore: Benchmarking how coding agents explore repositories. arXiv preprint arXiv:2606.07297, 2026. URL https://arxiv. org/abs/2606.07297
Pith/arXiv arXiv 2026
-
[21]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InInternational Conference on Learning Representations (ICLR), 2024. URL https://arxiv.org/abs/ 2310.06770
Pith/arXiv arXiv 2024
-
[22]
Introducing SWE-bench veri- fied
Neil Chowdhury, James Aung, Jun Shern Chan, and Oliver Jaffe. Introducing SWE-bench veri- fied. OpenAI blog post, https://openai.com/index/ introducing-swe-bench-verified/, 2024
2024
-
[23]
Muhammad Shihab Rashid, Christian Bock, Yuan Zhuang, Alexander Buchholz, Tim Esler, Simon Valentin, Luca Franceschi, Martin Wistuba, Prabhu Teja Sivaprasad, Woo Jung Kim, Anoop Deoras, Giovanni Zappella, and Laurent Callot. SWE-PolyBench: A multi-language benchmark for repository level evaluation of coding agents.arXiv preprint arXiv:2504.08703, 2025. URL...
arXiv 2025
-
[25]
URL https://arxiv.org/abs/2509.16941
-
[26]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR), 2023. URL https://arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[27]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Can- cedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URL https://arxiv.org/abs/2302.04761
Pith/arXiv arXiv 2023
-
[28]
On randomness in agentic evals.arXiv preprint arXiv:2602.07150, 2026
Bjarni Haukur Bjarnason, Andre Silva, and Martin Mon- perrus. On randomness in agentic evals.arXiv preprint arXiv:2602.07150, 2026. URL https://arxiv.org/abs/2602. 07150
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.