Decoding in Order-Agnostic Language Models: Chain-Rule Deviation and Uniform Spreading
Pith reviewed 2026-06-28 17:45 UTC · model grok-4.3
The pith
Order-agnostic language models produce inconsistent likelihoods for the same sequence under different reveal orders, motivating variance of log-confidence as a decoding diagnostic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
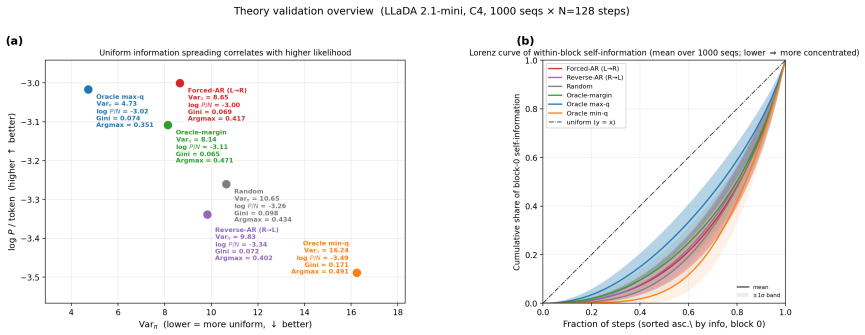
The learned conditionals in order-agnostic language models deviate from exact chain-rule factorizations of a joint distribution, shown by order-dependent shifts in target log-likelihood. The uniform-spreading theorem establishes that target recoverability is maximized when per-step confidence is spread uniformly at fixed total likelihood. The resulting deviation from uniformity motivates Var(log q_t) as a diagnostic for comparing decoding paths. Across C4 and four downstream benchmarks, low variance separates structured paths from random ordering and associates with downstream correctness.
What carries the argument
The uniform-spreading theorem, which shows that even distribution of per-step log-confidences maximizes recoverability for any fixed total likelihood.
If this is right
- Confidence-first decoding produces reveal orders close to left-to-right on content tokens.
- Low variance in log-confidence separates structured decoding paths from random ordering.
- Variance is consistently associated with downstream correctness.
- Mean confidence and confidence variance should be reported jointly when comparing OALM decoding paths.
Where Pith is reading between the lines
- The order-dependence finding suggests training objectives could be modified to enforce greater consistency across reveal orders.
- The diagnostic may extend to other non-autoregressive or flexible-conditioning generation methods.
- If low variance predicts correctness, it could guide early selection of decoding strategies without running full downstream evaluations.
Load-bearing premise
The uniform-spreading theorem applies to the confidence traces produced by trained order-agnostic models.
What would settle it
An experiment in which decoding paths with higher variance in log q_t achieve higher target recoverability or better downstream accuracy than low-variance paths would falsify the diagnostic value of low variance.
Figures

read the original abstract
Order-agnostic language models (OALMs), including discrete diffusion language models (dLLMs), are trained to predict masked tokens under arbitrary conditioning sets, allowing sequences to be generated or scored under arbitrary reveal orders at inference time. In LLaDA-2.1, we report three findings. First, the learned conditionals are not exact factorizations of a coherent joint distribution: changing only the reveal order shifts target log-likelihood by up to 0.49 nats/token, so likelihood alone mixes content difficulty with path-dependent artifacts. Second, although confidence-first (CF) decoding is order-agnostic, its reveal orders are close to left-to-right (L2R) on content tokens. Third, we propose a complementary diagnostic based on the shape of the confidence trace. A uniform-spreading theorem shows that, at fixed total likelihood, target recoverability is maximized when per-step confidence is spread uniformly; the resulting deviation motivates $\mathrm{Var}(\log q_t)$ as a diagnostic for comparing decoding paths. Across C4 and four downstream benchmarks, low variance separates structured paths from random ordering, and variance is consistently associated with downstream correctness. These results support reporting mean confidence and confidence variance jointly when comparing OALM decoding paths.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines decoding in order-agnostic language models (OALMs) such as discrete diffusion LMs. It claims that the learned conditionals in LLaDA-2.1 are not exact factorizations of any coherent joint, since altering only the reveal order changes target log-likelihood by up to 0.49 nats/token. It further reports that confidence-first decoding produces reveal orders close to left-to-right on content tokens. A uniform-spreading theorem is derived asserting that, at fixed total likelihood, target recoverability is maximized when per-step log-confidences are spread uniformly; the deviation from uniformity is proposed as the diagnostic Var(log q_t). Experiments on C4 and four downstream tasks show that low variance distinguishes structured paths from random orderings and correlates with correctness, leading to the recommendation that both mean confidence and variance be reported when comparing OALM decoding paths.
Significance. If the uniform-spreading theorem applies to the approximate conditionals learned by OALMs and the reported likelihood shifts are not training artifacts, the work supplies a theoretically motivated diagnostic that separates path-dependent effects from content difficulty in non-autoregressive models. The theorem itself constitutes a clean, falsifiable contribution, and the empirical association of variance with downstream correctness across multiple benchmarks offers a practical takeaway for model evaluation. The finding that CF decoding remains close to L2R on content tokens also clarifies the behavior of existing heuristics.
major comments (2)
- [uniform-spreading theorem] The uniform-spreading theorem is invoked to motivate Var(log q_t) as a diagnostic, yet the manuscript provides no derivation or verification that the theorem's assumptions (fixed total likelihood and exact conditional factorization) continue to hold for the noisy, approximate conditionals actually produced by trained OALMs; the observed 0.49 nats/token shifts already indicate departure from coherent joints, so the theorem's applicability must be shown explicitly rather than assumed.
- [experimental results on C4 and downstream benchmarks] The empirical claim that variance is associated with downstream correctness does not report controls for mean confidence or path length; without such controls it remains possible that the reported association is driven by these confounders rather than the shape of the confidence trace.
minor comments (2)
- The abstract states the three findings but supplies no information on how reveal orders were sampled, how data points were excluded, or the precise experimental setup, making it impossible for a reader to assess reproducibility from the abstract alone.
- Notation for q_t and the precise definition of 'total likelihood' should be introduced before the theorem statement to avoid forward references.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and limitations of our claims. We address each major comment below and outline revisions that will strengthen the manuscript.
read point-by-point responses
-
Referee: [uniform-spreading theorem] The uniform-spreading theorem is invoked to motivate Var(log q_t) as a diagnostic, yet the manuscript provides no derivation or verification that the theorem's assumptions (fixed total likelihood and exact conditional factorization) continue to hold for the noisy, approximate conditionals actually produced by trained OALMs; the observed 0.49 nats/token shifts already indicate departure from coherent joints, so the theorem's applicability must be shown explicitly rather than assumed.
Authors: We agree that the theorem is stated under exact factorization and fixed total likelihood, while the 0.49 nats/token shifts demonstrate that LLaDA-2.1 conditionals are only approximate. The theorem is offered as a clean theoretical motivation rather than a direct claim about trained models. To address the concern explicitly, the revised manuscript will (i) restate the theorem's assumptions, (ii) add a short discussion of why uniform spreading remains a reasonable target even under small perturbations of the conditionals, and (iii) include a controlled synthetic experiment in which we inject controlled noise into exact factorizations and measure the resulting change in recoverability versus variance. This will make the applicability argument transparent rather than assumed. revision: yes
-
Referee: [experimental results on C4 and downstream benchmarks] The empirical claim that variance is associated with downstream correctness does not report controls for mean confidence or path length; without such controls it remains possible that the reported association is driven by these confounders rather than the shape of the confidence trace.
Authors: The referee is correct that the current experiments do not include explicit controls for mean confidence or path length. In the revision we will add two analyses: (1) linear regressions of correctness on variance while controlling for mean log-confidence and sequence length, and (2) matched-pair comparisons in which paths are binned by mean confidence and length before comparing variance. These controls will be reported for both the C4 perplexity experiments and the four downstream tasks. We expect the association to remain but will report the controlled coefficients so readers can judge the incremental contribution of variance. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's chain consists of an empirical observation (likelihood shifts up to 0.49 nats/token under different reveal orders) plus a general mathematical claim (uniform-spreading theorem maximizing recoverability at fixed total likelihood) used only to motivate reporting Var(log q_t) as a diagnostic. No quoted equations, self-citations, or fitted parameters reduce the theorem or the diagnostic to the model outputs by construction; the theorem is presented as an independent result whose applicability is an external modeling assumption rather than a definitional identity. The derivation therefore remains self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hikaru Asano, Tadashi Kozuno, Kuniaki Saito, and Yukino Baba. Where-to-unmask: Ground- truth-guided unmasking order learning for masked diffusion language models.arXiv preprint arXiv:2602.09501, 2026
arXiv 2026
-
[2]
Log-concave probability and its applications.Economic Theory, 26(2):445–469, 2005
Mark Bagnoli and Ted Bergstrom. Log-concave probability and its applications.Economic Theory, 26(2):445–469, 2005
2005
-
[3]
LLaDA2.1: Speeding up text diffusion via token editing.arXiv preprint arXiv:2602.08676, 2026
Tiwei Bie, Maosong Cao, Xiang Cao, Bingsen Chen, Fuyuan Chen, Kun Chen, Lun Du, Daozhuo Feng, Haibo Feng, Mingliang Gong, Zhuocheng Gong, Yanmei Gu, Jian Guan, Kaiyuan Guan, Hongliang He, Zenan Huang, Juyong Jiang, Zhonghui Jiang, Zhenzhong Lan, Chengxi Li, Jianguo Li, Zehuan Li, Huabin Liu, Lin Liu, Guoshan Lu, Yuan Lu, Yuxin Ma, Xingyu Mou, Zhenxuan Pan...
arXiv 2026
-
[4]
LLaDA2.0: Scaling up diffusion language models to 100B.arXiv preprint arXiv:2512.15745, 2025
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, Chengxi Li, Chongxuan Li, Jianguo Li, Zehuan Li, Huabin Liu, Lin Liu, Guoshan Lu, Xiaocheng Lu, Yuxin Ma, Jianfeng Tan, Lanning Wei, Ji-Rong Wen, Yipeng Xing, Xiaolu Zhang, Junbo Zhao, Da Zheng, Jun Zhou, Junlin Zhou, Zhanchao Zhou, Li...
Pith/arXiv arXiv 2025
-
[5]
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T. Freeman. MaskGIT: Masked generative image transformer. InCVPR, 2022
2022
-
[6]
Ziyu Chen, Xinbei Jiang, Peng Sun, and Tao Lin. Optimizing decoding paths in masked diffusion models by quantifying uncertainty.arXiv preprint arXiv:2512.21336, 2025
arXiv 2025
-
[7]
Mask-predict: Parallel decoding of conditional masked language models
Marjan Ghazvininejad, Omer Levy, Yinhan Liu, and Luke Zettlemoyer. Mask-predict: Parallel decoding of conditional masked language models. InEMNLP, 2019
2019
-
[8]
Li, and Richard Socher
Jiatao Gu, James Bradbury, Caiming Xiong, Victor O.K. Li, and Richard Socher. Non-autoregressive neural machine translation. InICLR, 2018
2018
-
[9]
Autoregressive diffusion models
Emiel Hoogeboom, Didrik Nielsen, Priyank Jaini, Patrick Forré, and Max Welling. Autoregressive diffusion models. InICLR, 2022
2022
-
[10]
Auto-regressive masked diffusion models
Mahdi Karami and Ali Ghodsi. Auto-regressive masked diffusion models. InProceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), 2026
2026
-
[11]
Train for the worst, plan for the best: Understanding token ordering in masked diffusions
Jaeyeon Kim, Kulin Shah, Vasilis Kontonis, Sham Kakade, and Sitan Chen. Train for the worst, plan for the best: Understanding token ordering in masked diffusions. InProceedings of the International Conference on Machine Learning (ICML), 2025. Outstanding Paper Award
2025
-
[12]
Large language models are zero-shot reasoners.NeurIPS, 35:22199–22213, 2022
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.NeurIPS, 35:22199–22213, 2022
2022
-
[13]
A diversity-promoting objective function for neural conversation models
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. A diversity-promoting objective function for neural conversation models. InProceedings of NAACL-HLT, pages 110–119, 2016
2016
-
[14]
Discrete diffusion modeling by estimating the ratios of the data distribution.ICML, 2024
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution.ICML, 2024. 11
2024
-
[15]
Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025
Pith/arXiv arXiv 2025
-
[16]
Opencompass: A universal evaluation platform for foundation models
OpenCompass Contributors. Opencompass: A universal evaluation platform for foundation models. https://github.com/open-compass/opencompass, 2023
2023
-
[17]
On logarithmic concave measures and functions.Acta Scientiarum Mathematicarum, 34:335–343, 1973
András Prékopa. On logarithmic concave measures and functions.Acta Scientiarum Mathematicarum, 34:335–343, 1973
1973
-
[18]
Language models are unsupervised multitask learners.OpenAI Technical Report, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI Technical Report, 2019
2019
-
[19]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
2020
-
[20]
Simple and effective masked diffusion language models
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models. NeurIPS, 2024
2024
-
[21]
Yangyi Shen, Tianjian Feng, Jiaqi Han, Wen Wang, Tianlang Chen, Chunhua Shen, Jure Leskovec, and Stefano Ermon. Improving diffusion language model decoding through joint search in generation order and token space.arXiv preprint arXiv:2601.20339, 2026
arXiv 2026
-
[22]
Deferred commitment decoding for diffusion language models.arXiv preprint arXiv:2601.02076, 2026
Yingte Shu, Yuchuan Tian, Chao Xu, Yunhe Wang, and Hanting Chen. Deferred commitment decoding for diffusion language models.arXiv preprint arXiv:2601.02076, 2026
arXiv 2026
-
[23]
A deep and tractable density model for neural autoregressive distribution estimation
Benigno Uria, Iain Murray, and Hugo Larochelle. A deep and tractable density model for neural autoregressive distribution estimation. InICML, 2014
2014
-
[24]
Guanghan Wang, Yair Schiff, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Remasking discrete diffusion models with inference-time scaling.arXiv preprint arXiv:2503.00307, 2025
arXiv 2025
-
[25]
MMLU-Pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. MMLU-Pro: A more robust and challenging multi-task language understanding benchmark. InNeurIPS Datasets and Benchmarks Track, 2024
2024
-
[26]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.NeurIPS, 35:24824–24837, 2022
2022
-
[27]
Tianwen Wei, Jian Luan, Wei Liu, Shuang Dong, and Bin Wang. CMATH: Can your language model pass Chinese elementary school math test?arXiv preprint arXiv:2306.16636, 2023
arXiv 2023
-
[28]
Kaisen Yang, Jayden Teoh, Kaicheng Yang, Yitong Zhang, and Alex Lamb. Improving sampling for masked diffusion models via information gain.arXiv preprint arXiv:2602.18176, 2026
Pith/arXiv arXiv 2026
-
[29]
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V . Le. XLNet: Generalized autoregressive pretraining for language understanding.NeurIPS, 2019
2019
-
[30]
HellaSwag: Can a ma- chine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a ma- chine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019. 12
2019
-
[31]
Shaorong Zhang, Longxuan Yu, Rob Brekelmans, Luhan Tang, Salman Asif, and Greg Ver Steeg. Generation order and parallel decoding in masked diffusion models: An information-theoretic perspective. arXiv preprint arXiv:2602.00286, 2026
arXiv 2026
-
[32]
Yangyang Zhong, Yanmei Gu, Zhengqing Zang, Xiaomeng Li, Yuqi Ding, Xibei Jia, Yuting Shen, Zhenzhong Lan, Liwang Zhu, Weiping Liu, Junlin Zhou, Haisheng Liu, Zhong Xin Yu, Pengxin Luo, Donglian Qi, Yunfeng Yan, and Junbo Zhao. Parallelism and generation order in masked diffusion language models: Limits today, potential tomorrow.arXiv preprint arXiv:2601.1...
Pith/arXiv arXiv 2026
-
[33]
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023. 13 A Proofs and Derivations A.1 Setup: Chain Rule and Distortion Decomposition Notation.The prompt or context is denoted by c, the target sequence by x∗...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.